目前,绝大部分的爬虫教程都是基于Python和Node.js。其实,只要有Chrome浏览器,使用Chrome F12打开的的Devtools就能随时随地轻轻松松写一个爬虫,完全不用装其它语言环境。今天就介绍一下只使用Chrome Devtools来爬取网站www.biqudu.com/31_31729/小说并保存为文本文件的爬虫。
如何在Chrome Devtools里面写爬虫代码
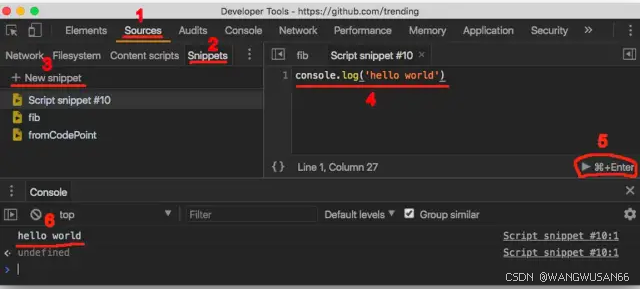
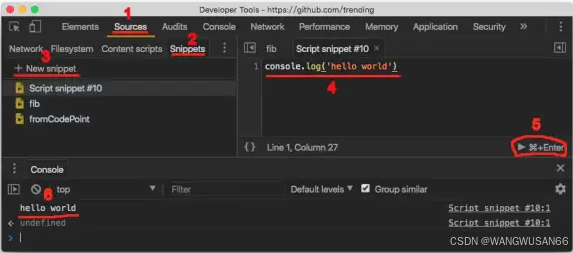
Devtools提供了Snippets功能让我们可以在这里写JavaScript代码,步骤参考下图:
步骤说明
-
打开source标签
-
左侧选择Snippets标签
-
点击New Snippets新建一个Snippets
-
开始写代码
-
点击运行代码
-
查看控制台输出
准备爬虫工具函数
1.加载第三方库
根据Url加载一个第三方库,可以用这个函数加载jquery,underscore等工具库,加载完成后就可以在代码中使用这些库了,本例中使用这个函数加载async异步并发控制库。
async function loadLibrary(url) {
return new Promise((resolve, reject) => {
let script = document.createElement('script');
script.onload = resolve;
script.onerror = reject;
script.src = url;
document.body.appendChild(script);
});
}2.下载文件到本地
将string下载到文本文件
function saveFile(string, fileName) {
var a = document.createElement('a');
a.download = fileName;
var blob = new Blob([string], {
type: 'text/plain'
});
a.href = window.URL.createObjectURL(blob);
a.click();
}3.下载HTML
使用了Fetch api,根据url下载一个html文本文件并转换成DOM元素后返回,返回的元素具有DOM api,例如 querySelector,方便对节点的提取和分析。
async function getHtml(url) {
let response = await fetch(url);
let htmlText = await response.text();
let html = document.createElement('html');
html.innerHTML = htmlText;
return html;
}准备爬虫业务函数
1.获取小说的所有章节信息
分析小说主页www.biqudu.com/31_31729/,
通过document.querySelectorAll('#list dd a') 可以获取包含所有章节名称和链接的a标签元素。
async function getDirectory(url) {
let page = await getHtml(url);
let directory = Array.from(page.querySelectorAll('#list dd a'));
//去除顶部最新12个章节
return directory.slice(12);
}2.获取一个章节的内容
分析小说章节 www.biqudu.com/31_31729/21…,章节内容位于ID为content的DIV元素中
async function getSection({ href, innerText: title }) {
console.log(`开始获取 ${title}`);
let html = await getHtml(href);
let content = html.querySelector('#content');
Array.from(content.querySelectorAll('script')).forEach(scriptTag => content.removeChild(scriptTag));
var text = title + '\r\n' + content.innerText + '\r\n';
return text;
}完整代码
因为小说有几百几千章节,不可能一个一个章节下载,那样速度太慢了。也不能一下子全下载。所以
爬取时使用了async异步并发控制库(这个async和async function里面的async只是名字一样而已),并发数量为6,设置大了也没用因为Chrome浏览器对同一域名下的同时请求数量是6。
完整代码运行步骤
-
Chrome浏览器打开小说主页如:www.biqudu.com/31_31729/
-
在小说主页页面打开Devtools 新建snippets并将下面的完整代码粘贴进去
-
点击运行代码开始爬取小说
(async function () {
// https://www.biqudu.com/31_31729/
async function loadLibrary(url) {
return new Promise((resolve, reject) => {
let script = document.createElement('script');
script.onload = resolve;
script.onerror = reject;
script.src = url;
document.body.appendChild(script);
});
}
function saveFile(string, fileName) {
var a = document.createElement('a');
a.download = fileName;
var blob = new Blob([string], {
type: 'text/plain'
});
a.href = window.URL.createObjectURL(blob);
a.click();
}
async function getHtml(url) {
let response = await fetch(url);
let htmlText = await response.text();
let html = document.createElement('html');
html.innerHTML = htmlText;
return html;
}
async function getDirectory(url) {
let page = await getHtml(url);
let directory = Array.from(page.querySelectorAll('#list dd a'));
//去除顶部最新12个章节
return directory.slice(12);
}
async function getSection({ href, innerText: title }) {
console.log(`开始获取 ${title}`);
let html = await getHtml(href);
let content = html.querySelector('#content');
Array.from(content.querySelectorAll('script')).forEach(scriptTag => content.removeChild(scriptTag));
var text = title + '\r\n' + content.innerText + '\r\n';
return text;
}
async function run() {
let asyncLibUrl = 'https://cdn.bootcss.com/async/2.1.4/async.js';
await loadLibrary(asyncLibUrl);
let directory = await getDirectory(location.href);
let q = window.async.queue(async function (section, taskDone) {
try {
section.text = await getSection(section);
} catch (e) {
console.error(e);
section.text = "章节下载失败:" + e;
} finally {
taskDone();
}
}, 6);//并发送设成6
q.drain = function () {
let name = document.querySelector('#maininfo h1').innerText + '.txt';
console.log(`小说《${name}》下载完成`);
let content = "";
directory.forEach(function ({ text }) {
content += text;
});
saveFile(content, name);
}
q.push(directory);
}
await run();
}());
