JAVA开发学习-day08
1. HashMap的putVal方法
//hash:键的哈希值
//key:键 value:值
//onlyIfAbsent:是否仅在键不存在时插入
//evivt:是否在插入后进行驱逐操作
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断存储键值对的数组是否为空
if ((tab = table) == null || (n = tab.length) == 0)
//为空则使用resize()方法初始化
n = (tab = resize()).length;
//判断要存入的索引是否有元素
//因为键的hash值是一个很大值,所以将hash与(n-1)做位与操作,得出的结果在0~(n-1)之间,也就是数组索引的范围
if ((p = tab[i = (n - 1) & hash]) == null)
//如果要存入的索引为空,则将键值对存入数组中
tab[i] = newNode(hash, key, value, null);
else {
//要存入的索引不为空
Node<K,V> e; K k;
//判断当前节点的key值是否与要插入的键值对的key相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//键相同则进行覆盖
e = p;
//判断当前的节点是否一个树节点
else if (p instanceof TreeNode)
//若为树节点,则使用putTreeVal方法添加键值对
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//前面的判断不通过,说明当前节点是一个链表节点
//循环遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//遍历完也没有与要插入的节点的key值相同的节点
//将要插入的节点放入链表的最后
p.next = newNode(hash, key, value, null);
//判断节点个数是否需要树化
if (binCount >= TREEIFY_THRESHOLD - 1)
//节点个数>=7就进行树化
treeifyBin(tab, hash);
break;
}
//找到key值相同的节点,就结束循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//p = p.next
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
//如果存在相同的key的节点就覆盖value
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount; //更新modCount,表明HashMap发生变化
//容量增加,判断是否需要扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
2. 异常
异常就是程序执行过程中不正常的情况,当程序中出现异常,就会中断程序,代码就不再往下运行
在java中异常以类的形式存在,java中所有的异常类都可以声明
ClassCastException classCastException = new ClassCastException("这是类转换异常");
System.out.println(classCastException); //java.lang.ClassCastException: 这是类转换异常
异常继承的结构图
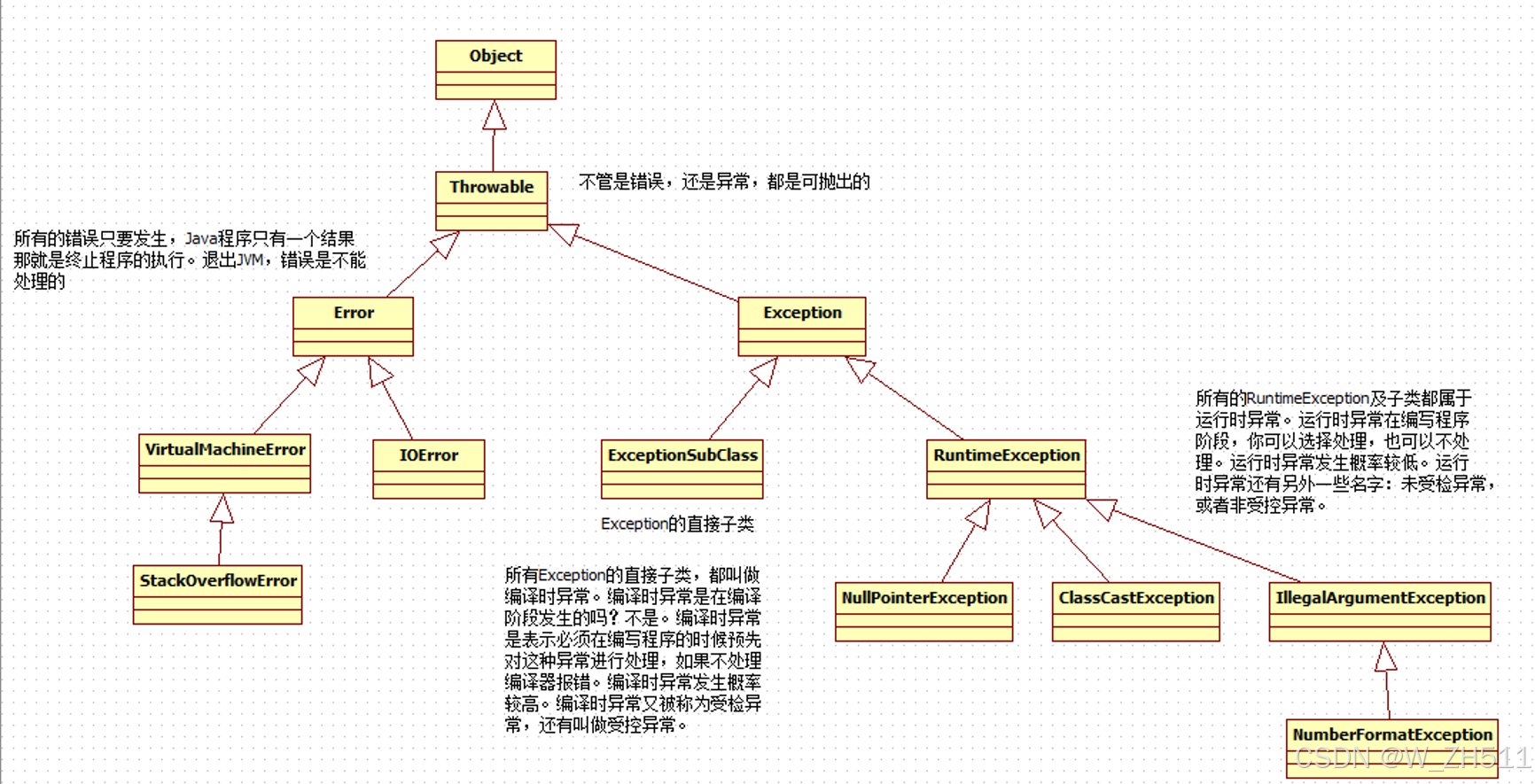
异常的分类:
-
1.检查型异常(编译异常):在编译时就会抛出的异常(编译时报错),需要在代码中编写处理方式
直接继承Exception
-
2.运行时异常:在代码运行阶段,可能会出现的异常,可以不用明文处理异常
继承RuntimeException
运行时异常可以通过代码避免
2.1 检查型异常
在编译时就会出现的异常
//处理文件
File file = new File("D:\\easy.txt");
//检查型异常(编译异常)
//FileInputStream fis = new FileInputStream(file); //FileNotFoundException
//检查型异常会在编译时报错
2.2 运行时异常
在代码运行阶段可能出现的异常
String str = null;
String name = "张三";
bool = str.equals(name); //空指针异常
int i = 12;
int a = 0;
System.out.println(i % a); //ArithmeticException: / by zero 数学运算异常:由0造成
2.3 异常的处理
关于异常的处理的关键字: try,catch,finally,throw,throws
2.3.1 try…catch…finally
1.try
- 用于监听。将要被监听的代码(可能抛出异常的代码)放在try语句块之内,当try语句块内发生异常时,异常就被抛出。
2.catch
- 用于捕获异常。catch用来捕获try语句块中发生的异常,负责将异常抛出或打印错误日志。
3.finally
- finally语句块总是会被执行。它主要用于回收在try块里打开的物力资源(如数据库连接、网络连接和磁盘文件)。只有finally块,执行完成之后,才会回来执行try或者catch块中的return或者throw语句,如果finally中使用了return或者throw等终止方法的语句,则就不会跳回执行,直接停止。
//流对象在外部声明
//便于在finally中关闭流
FileInputStream fis = null;
//try块尝试捕捉异常 其中是可能会抛出异常的代码
try{
fis = new FileInputStream(file);
}catch(FileNotFoundException e){
//捕捉到异常后要处理的代码
//打印异常日志
e.printStackTrace();
}finally {
//无论是否出现异常,都会执行的代码块
//一般用在关闭资源
if(fis != null){
try {
fis.close();
} catch (IOException e) {
throw new RuntimeException(e.getMessage());
}
}
}
try…catch处理多种异常的方法
- 1.可以写多个catch,捕捉不同的异常,将子类异常写在上面优先捕捉,父类异常写在下面后置捕捉
- 2.在catch的()中使用|将要捕捉的异常类型分隔开
- 3.直接捕捉异常的父类
//1
//子类异常优先处理 父类异常后置处理
try{
List list = new ArrayList();
list.remove(8); //IndexOutOfBounds
int[] arr = new int[2];
arr[8] = 22; //ArrayIndexOutOfBounds
String strA = "abc";
strA.charAt(8); //StringIndexOutOfBound
} catch (ArrayIndexOutOfBoundsException e){
//子类的异常放在前面
} catch (StringIndexOutOfBoundsException e){
} catch (IndexOutOfBoundsException e){
e.printStackTrace();
}
//2
try{
System.out.println(12/0);
Object objA = "";
System.out.println((Integer)objA);
fis = new FileInputStream(file);
} catch (ArithmeticException | ClassCastException | FileNotFoundException e){
//用|来划分异常类型
}
//3
//catch块声明父类异常,捕捉所有子类异常
try{
System.out.println(12/0);
Object objA = "";
System.out.println((Integer)objA);
fis = new FileInputStream(file);
} catch (Exception e){
//声明父类异常
}
try不能单独编写,必须有其他语句块(catch 或 finally)
try{
int a = 12+2;
System.out.println("");
//后面只跟finally时,不能有检查型异常
} finally {
}
try{
int a = 12+2;
System.out.println("");
//后面只跟finally时,不能有检查型异常
} catch (FileNotFoundException e) {
//报错:Exception 'java.io.FileNotFoundException' is never thrown in the corresponding try block
//try块中没有检查型异常,catch就不能捕捉检查型异常
}
try…catch…finally的执行顺序
简单来说,就是在try和catch中执行return语句后不会返回(finally中没有return语句),而是在执行完finally中的语句后再返回,但返回的值在执行try和catch中的return语句时就确定了,不会收到finally中语句的影响。
如果finally中有return语句就之间返回finally中的return的值
public class ExceptionTest13 {
public static void main(String[] args) {
int result = m();
System.out.println(result); //100
}
public static int m(){
int i = 100;
try {
// 这行代码出现在int i = 100;的下面,所以最终结果必须是返回100
// 返回的值已经确定为100了,只是执行finally中代码后再返回
return i;
} finally {
i++;
}
}
}
2.3.2 throw throws
throw用于抛出异常
throws用在方法签名上,用于声明该方法抛出的异常,一个方法可以抛出多个异常
当方法中抛出的异常为运行时异常时可以,不在方法签名中声明抛出该异常
public void infoA(){
if(name == null){
//运行时异常可以不强制声明
throw new NullPointerException("Name is null!");
}
}
检查型异常必须在方法签名中声明抛出该异常
public void infoA() throws IOException{
if(name == null){
//运行时异常可以不强制声明
throw new IOException();
}
}
2.4 自定义异常
在实际开发中,许多业务会出现异常,这些异常在JDK中是没有的,所以需要自定义异常
使一个类继承Exception类(编译异常)或RuntimeException类(运行时异常),并实现该类的构造方法,就完成了一个自定义异常类,一般写一个无参的构造方法和有参的构造方法
class Student{
String name;
public void introduce() throws StudentNameIsNullException, NullPointerException{
//name = null是一种特殊情况,不符合业务需求
if(name == null){
//throw抛出异常
throw new StudentNameIsNullException("Student's name is null.");
}
System.out.println("我的名字是" + name);
}
}
//自定义异常
//Exception的直接子类,检查型异常
class StudentNameIsNullException extends Exception{
public StudentNameIsNullException(){}
public StudentNameIsNullException(String message){
super(message);
}
}
子类在重写父类的方法时,方法签名不需要写父类中抛出的异常,在需要声明抛出的时候再抛出即可
class collegeStudent extends Student{
@Override
//子类重写的方法不需要声明父类中方法抛出的异常
public void introduce() {
}
}
//自定义异常
class Student{
public void introduce() throws StudentNameIsNullException, NullPointerException{
if(name == null){
throw new StudentNameIsNullException("Student's name is null.");
}
System.out.println("我的名字是" + name);
}
}
//Exception的直接子类,检查型异常
class StudentNameIsNullException extends Exception{
public StudentNameIsNullException(){}
public StudentNameIsNullException(String message){
super(message);
}
}
3. File
File类属于java.io包。使用java.io包可以通过数据流,序列化和文件系统提供系统的输入和输出。
File类中涉及到关于文件或文件目录的创建、删除、重命名、修改时间、文件大小等方法,并未涉及到写入或读取文件内容的操作。如果需要读取或写入文件内容,必须使用IO流来完成。
File类的初始化,声明一个类,传入的参数是一个字符串,代表文件的地址
File file = new File("D:\\easy.txt");
File类的常用方法
public boolean exists(): 判断文件是否存在
public boolean createNewFile(): 创建文件,若文件不存在则不创建,返回false
public boolean mkdir(): 创建文件夹,如果该文件夹存在则不创建,如果该文件夹的上级目录不存在也不创建
public boolean mkadirs(): 创建文件夹,如果该文件夹的上级目录不存在,则连带上级目录一起创建
public boolean delete(): 删除文件或文件夹,删除文件夹时,文件夹必须为空
public boolean isFile(): 判断是否是文件
public boolean isDirectory(): 判断是否是文件夹
public long length(): 获取文件的长度(字节数),文件目录不能获得长度,一字节等于1B
public static void main(String[] args) {
//在java中声明一个文件 File类 传入字符串当作文件地址
File file = new File("D:\\easy.txt");
//是否存在该文件
boolean bool = file.exists();
System.out.println(bool);
//创建文件
if(!bool){
try{
bool = file.createNewFile();
if(bool){
System.out.println("成功创建文件");
}
} catch (IOException e){
e.printStackTrace();
}
} else{
//删除文件
//删除文件夹时,文件夹必须是空的
file = new File("D:\\123");
file.delete();
System.out.println("成功删除文件");
}
//获取是否是文件
bool = file.isFile();
System.out.println(bool);
//是否是文件夹
bool = file.isDirectory();
System.out.println(bool);
//创建文件夹
file.mkdir();
file = new File("F:\\迅雷下载\\[Nekomoe kissaten][Shikanoko Nokonoko Koshitantan][03][1080p][CHS].mp4");
long length = file.length();
System.out.println(length);
}
4. I/O(输入和输出)
I/O就是输入和输出的简写,指的是数据在计算机内部和外部设备之间的流动。
在java中数据以流的形式来输出和输入,根据数据流动的方向不同,分为输入流和输出流;根据流动的介质不同,又分为字节流和字符流。
字符流只能处理文本文件(.txt .xml .properties .html .yml)
字节流可以处理任何文件
常用的流:
//字节输入流
InputStream is;
//字节输出流
OutputStream os;
//字符输入流
Reader reader;
//字符输出流
Writer writer;
使用字节输入流读取文件
public static void readFile(){
//文件字节输入流
FileInputStream fis = null;
try{
fis = new FileInputStream("D:\\easy.txt");
//byte大小为一字节,适用于字节流
byte[] arr = new byte[1024];
//读取多少数据就转换多少数据
int length = 0;
while ((length = fis.read(arr)) != -1){
//arr 中就是读取到的数据
//在读取到最后时,数组后面没有新数据替换的数据不会变化,所以只将新读取的数据转化为字符串输出
//将数组arr的下标在0~length之间的元素转化为字符串
String str = new String(arr, 0, length);
//String.valueOf(arr);
System.out.print(str);
}
//数据流操作可能会造成IO异常
} catch (IOException e){
e.printStackTrace();
} finally {
if(fis != null){
try{
//数据流开启后必须要关闭
fis.close();
} catch (IOException e){
e.printStackTrace();
}
}
}
}
转换流: 转换流主要用于字符流和字节流之间的转换,当我们想要在字节流中读取字符时,就需要转换流将字节转换为字符。在下面的示例中,InputStreamReader isr = new InputStreamReader(fis); 将FileInputStream(字节流)转换为InputStreamReader(字符流),使得可以从文件中读取字符。
缓冲流: 缓冲流用于为字符流作缓冲作用,缓存流可以一次读取多个字符,存储在内部缓冲区,提高了I/O操作的效率,此外缓冲流中提供了读取字符,行的方法。 在下面的示例中,我们创建了一个BufferedReader对象,并传入了字符流,这样我们就可以使用BufferedReader的readline方法。
public static void readFileBuffer(){
try(
//文件字节输入流
FileInputStream fis = new FileInputStream("d:\\easy.txt");
//转换流
InputStreamReader isr = new InputStreamReader(fis);
//缓冲流
BufferedReader br = new BufferedReader(isr);
){
String line;
//打印流
while((line = br.readLine()) != null){
System.out.println(line);
}
}catch (IOException e){
e.printStackTrace();
}
}
上面的示例中使用了try-with-resource语句,通过使用try-with-resource语句我们可以简化代码,不在编写繁琐的关闭资源方法,提高了代码的可读性,也保证了资源的释放。
try-with-resource语句的使用方法,在try语句后的()中声明并初始化一个或多个资源,在其中声明并初始化的资源不需要再编写资源释放的代码,并且这些资源都实现了AutoCloseable接口。
使用字节输出流来将数据写入文件中
public static void writeFile(){
String str = "老崔很帅";
byte[] arr = str.getBytes();
//字节输出流
FileOutputStream fos = null;
try{
//第二个参数默认为false,如果不设置,则在写入时,会覆盖文件中的源数据
//若为true则将数据添加在文件的源数据后
fos = new FileOutputStream("d:\\easy.txt",true);
fos.write(arr);
} catch (IOException e){
e.printStackTrace();
} finally {
if(fos != null){
try{
fos.close();
} catch (IOException e){
e.printStackTrace();
}
}
}
}
序列化:将内存对象转化为序列(流)的过程就叫序列化,将对象序列化后就可以对象的数据进行I/O操作
使用对象流将对象序列化,对象流可以将对象写入文件中(序列化),也读取文件中的对象(反序列化)
序列化和反序列化的对象必须实现了Serizalizable接口
public static void writerObject(){
//将内存对象转换成序列(流)的过程叫做序列化
//这个对象必须是可序列化的
Staff staff = new Staff();
staff.name = "张三";
staff.sex = "男";
staff.salary = 35000;
//对象输出流
ObjectOutputStream oos = null;
FileOutputStream fos = null;
try{
fos = new FileOutputStream("D:\\easy.txt");
oos = new ObjectOutputStream(fos);
//对象输出流将对象写入文件 序列化
oos.writeObject(staff);
} catch (IOException e){
e.printStackTrace();
}finally {
if(oos != null){
try{
oos.close();
}catch (IOException e){
e.printStackTrace();
}
}
if(fos != null){
try{
fos.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
}
//序列化和反序列化的对象必须实现了Serizalizable接口
public class Staff implements Serializable {
String name;
String sex;
int salary;
@Override
public String toString() {
return "Staff{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", salary=" + salary +
'}';
}
}
反序列化:读取文件中的对象数据,转化为对象,反序列化会创建新的对象,和序列化的对象不是同一个
public static void readObject(){
//将对象序列读入程序,转换成对象的方式:反序列化
//序列化,反序列化的对象必须实现Serializable接口
//反序列化会创建新的对象,和序列化的对象不是同一个
FileInputStream fis = null;
ObjectInputStream ois = null;
try{
fis = new FileInputStream("d:\\easy.txt");
ois = new ObjectInputStream(fis);
Object obj = ois.readObject();
System.out.println(obj);
} catch (Exception e){
e.printStackTrace();
} finally {
if(ois != null){
try{
ois.close();
} catch (IOException e){
e.printStackTrace();
}
}
if(fis != null){
try{
fis.close();
} catch (IOException e){
e.printStackTrace();
}
}
}
}
创建对象的四种方式:
- 1.new
- 2.克隆
- 3.反序列化
- 4.反射