目录
利用AgglomerativeClustering对凝聚层次聚类剪枝
轮廓系数(silhouette coefficient)编辑
机器算法分类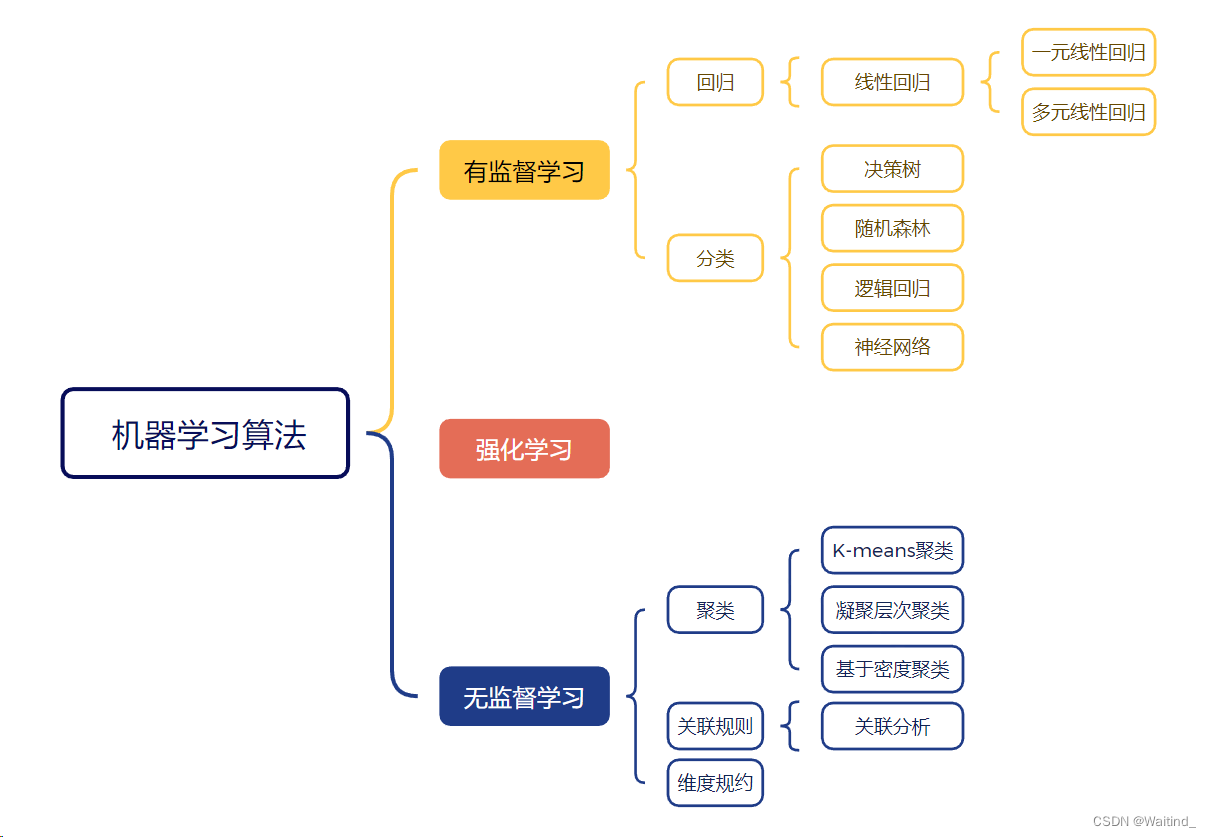
K-means均值聚类
相关概念
K均值聚类是一种常见的无监督学习算法,用于将一组数据点分组,使得每个组内的数据点尽可能相似,而组间的数据点尽可能不同。
-
数据点(Data Points):这些是我们要聚类的基本单位,通常在二维或三维空间中表示为点。每个数据点都有多个特征,这些特征决定了它在空间中的位置。
-
聚类(Clusters):聚类是数据点的集合,这些数据点在某些特征上相似。一个聚类中的数据点彼此之间差别不大,而与其它聚类中的数据点差别较大。
-
簇(Cluster):指一组由相似数据点组成的对象。簇内的数据点之间相互之间比较相似,而与簇外的数据点相比较不相似。聚类分析的目的之一就是识别出这样的簇。
-
K值(K):这是我们要将数据点划分的聚类数目。在K均值算法中,我们需要事先指定K的值,然后算法会试图找到最佳的K个聚类中心。
-
聚类中心(Cluster Centers):每个聚类都有一个中心点,这个中心点是该聚类中所有数据点的平均值。在K均值算法中,聚类中心是不断更新的,以便最小化每个数据点到其中心点的距离之和。
-
初始质心(Initial Centroid):指在开始迭代之前随机选择的K个数据点,它们被用作每个簇的初始中心。质心代表了簇的平均位置,它是簇内所有数据点的中心点。
-
距离(Distance):用来衡量两个数据点或数据点与聚类中心之间的相似度。在K均值中,通常使用欧几里得距离(直线距离)来计算这种相似度。
-
K均值算法步骤:
- 随机选择K个数据点作为初始聚类中心。
- 将每个数据点分配到最近的聚类中心所在的聚类。
- 更新每个聚类的中心点(即每个聚类中所有数据点的特征的平均值)。
- 重复第2步和第3步,直到聚类中心的变化小于某个阈值或达到迭代次数上限。
-
肘部方法(Elbow Method):这是一种确定最佳K值的方法。通过绘制不同K值下的聚类总误差(通常是簇内误差平方和SSE)的图表,我们可以找到一个“肘部”区域,在这个区域,增加聚类数目不会再显著减少误差。
应用场景
-
市场细分:通过分析消费者的购买行为、偏好和特征,将市场划分为几个不同的群体,以便于 targeted marketing 和产品定位。
-
客户分群:在金融服务行业中,根据客户的行为、财富状况和需求将客户分为不同的群体,以便提供个性化的服务和产品。
-
社交网络分析:在社交网络中,对用户进行聚类,可以发现社区结构、兴趣小组或者有影响力的用户群体。
-
图像和视频处理:在图像识别和视频分析中,K均值可以用来对图像像素或视频帧进行聚类,从而进行图像分割、对象识别和视频压缩等。
-
基因数据分析:在生物信息学中,K均值聚类可以用来对基因表达数据进行聚类分析,帮助科学家发现基因群体的模式和关联。
-
城市规划:在城市规划和交通管理中,K均值聚类可以用来对人口、建筑或者交通流量进行分类,以便更好地规划城市基础设施。
-
推荐系统:在推荐系统中,通过用户和物品的聚类,可以发现用户之间的相似性或者物品之间的关联性,从而提供个性化的推荐。
-
异常检测:在网络安全和金融领域,K均值聚类可以用来检测异常行为或欺诈行为,通过识别不符合正常模式的数据点来预警潜在的风险。
-
文本挖掘:在自然语言处理中,K均值聚类可以用来对文本数据进行分类,从而进行主题建模、情感分析等。
-
教育数据分析:在教育领域,通过对学生的成绩、行为和兴趣进行聚类,可以为学生提供个性化的学习计划和资源。
-
医疗健康:在医疗数据分析中,K均值聚类可以用来对病人的症状、治疗方案或者医疗费用进行分类,以便于疾病管理和资源分配。
K均值的Python实现
from sklearn.cluster import KMeans
KMeans(n_clusters=8, init=’k-means++’, max_iter=300, random_state=None)n_clusters:int类型,簇的个数。- 这个参数指定了要形成的簇的数量。也就是说,算法将尝试将数据集划分为8个簇。
init:初始质心的方法,可以选择k-means++或random- 这个参数指定了初始化质心的方法。'k-means++'是一种特殊的初始化方法,它倾向于选择那些已经有较高概率属于某个簇的数据点作为初始质心。这种方法可以提高算法收敛到全局最优解的概率,避免陷入局部最优。
max_iter:最大迭代次数- 这个参数指定了算法最大迭代的次数。在每次迭代中,算法会尝试优化聚类结果,直到达到最大迭代次数或聚类中心的变化小于某个阈值。
random_state:初始质心的随机生成种子- 这个参数用于设置随机状态,以确保算法的结果可重复。如果设置为整数,那么算法将使用固定随机数生成器种子,从而在每次运行时产生相同的随机结果。如果设置为None,则算法将使用默认的随机数生成器,每次运行时结果可能不同。
建立K均值聚类模型
读取iris数据
irisdf = pd.read_csv('./data/visualization/iris.csv',header=0)
irisdf.head()
irisdf.shape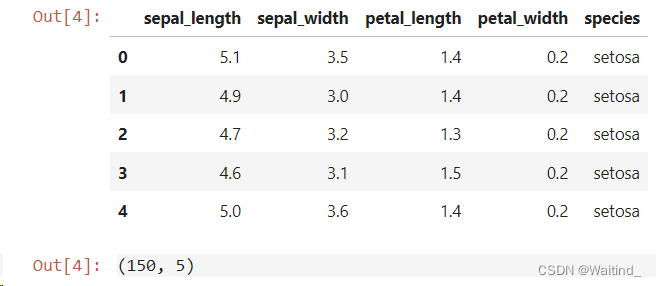
绘制属性箱型图,检查属性取值范围
irisdf.plot(y=['sepal_length','sepal_width','petal_length','petal_width'],
kind='box',figsize=(12,6))建立聚类模型
irisKmeans = KMeans(n_clusters=3,random_state=0)
irisKmeans训练K均值聚类模型
#X:需要聚类的数据集
kmeans.fit(X)irisX = irisdf.iloc[:,:-1]
irisX.head()
irisKmeans.fit(irisX)训练好的聚类模型的属性
irisKmeans.labels_labels_:每个数据点(样本)的标签,即所属的簇
irisKmeans.inertia_inertia_:簇内误差平方和
预测样本所属的距离最近的簇
kmean.predict(X)- 返回值:每个样本属于的簇的标签,是一个数组结构,形状为
[n_samples]
irisLabel = irisKmeans.predict(irisX)
irisLabel选择K值
随着K值的增大,簇内误差平方和(SSE)会降低
SSE:在给定的聚类划分下,簇内数据点与它们的簇中心之间的平均差异。
SSE的值越小,说明簇内的数据点与它们的簇中心越接近,聚类的质量越好
肘部(elbow)法则:识别SSE开始快速增大处的K值
sse = [] ###记录每个k值对应的SSE
for each in range(1,11):
km = KMeans(n_clusters=each,random_state=0)
km.fit(irisX)
sse.append(km.inertia_)
ax = pd.Series(sse).plot(kind='line',figsize=(12,6),
marker='o',grid=True,xticks=range(0,10)) #xticks:在哪些位置显示x轴刻度标签
_ = ax.set(xticklabels=range(1,11)) # 改变x轴标签显示,默认是从0开始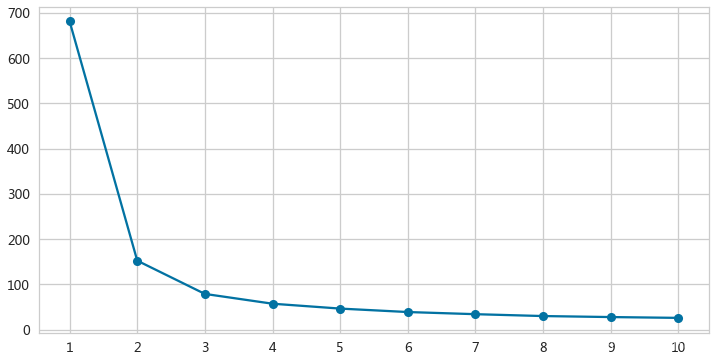
- 当K=3的时候,SSE开始快速增大,所以选择3个簇
scikit-learn可视化软件包
pip install -U yellowbrick
conda install -c districtdatalabs yellowbrickYellowbrick:基于scikit-learn与matplotlib
绘制肘部图
from yellowbrick.cluster import KElbowVisualizer
kviz = KElbowVisualizer(KMeans(), k=(1,11), metric='distortion',
timings=True, locate_elbow=True)
kviz.fit(X)
kviz.show()k:需要检验的k值序列k=(1,11)表示要评估的聚类中心数量的范围,从1到11。这个范围可以通过调整来查看不同聚类数目下的效果。
metric:检验的标准,默认是“距离误差平方和”,还可以是'silhouette`metric='distortion'指定了使用distortion(误差平方和,也称为簇内误差平方和SSE)作为评估聚类质量的指标。
timeings:是否绘制计算每个k值对应的聚类时间timings=True表示开启计算每个聚类中心所需时间的计时。
locate_elbow:是否显示肘部位置locate_elbow=True表示开启寻找“肘部”点,即聚类质量开始下降的点,这个点通常被认为是最优聚类数目的一个良好估计。
kmodel = KMeans(random_state=10)
elbowViz = KElbowVisualizer(kmodel, k=(1,11))
elbowViz.fit(irisX)
elbowViz.show()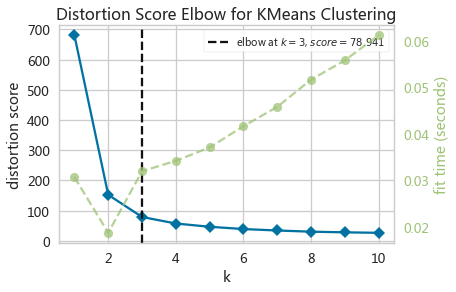
凝聚层次聚类
相关概念
凝聚层次聚类(Agglomerative Hierarchical Clustering)是一种自底向上的聚类方法,它通过逐步合并相似度高的聚类来构建一个嵌套的聚类层次结构。
-
层次结构(Hierarchy):凝聚层次聚类建立了一个从简单到复杂的层次结构,其中较低层次的聚类合并形成较高层次的聚类。这种结构可以表示为树状图,也称为dendrogram。
-
聚类(Clusters):在凝聚层次聚类中,聚类可以看作是由数据点组成的集合,这些数据点在某些特征上相似。聚类可以是任意形状和大小的,不一定是紧凑的。
-
合并(Merging):凝聚层次聚类通过合并相似的聚类来构建层次结构。合并是指将两个或多个聚类组合成一个更大的聚类,这个更大的聚类包含了原来聚类的所有数据点。
-
相似度(Similarity):相似度是一个度量标准,用于评估两个聚类之间的接近程度。在凝聚层次聚类中,常用的相似度度量是距离,比如欧几里得距离或者曼哈顿距离。
-
距离矩阵(Distance Matrix):距离矩阵是一个二维数组,用于存储每个聚类对之间的相似度(距离)。在凝聚层次聚类中,距离矩阵随着聚类的合并而更新。
-
链接(Linkage):链接是指决定如何合并聚类的方法。凝聚层次聚类有几种不同的链接方式,如单链接(single linkage)、完全链接(complete linkage)和平均链接(average linkage)。
-
单链接(Single Linkage):单链接是最常用的链接方法之一,它会选择两个聚类中最近的数据点对来合并聚类。
-
完全链接(Complete Linkage):完全链接是另一种链接方法,它会选择两个聚类中最远的 data point 对来合并聚类。
-
平均链接(Average Linkage):平均链接方法会计算两个聚类中所有数据点对之间的平均距离,以此作为合并聚类的依据。
-
距离阈值(Distance Threshold):在凝聚层次聚类中,可以设置一个距离阈值,只有当两个聚类的平均距离小于这个阈值时,它们才会被合并。
凝聚层次聚类和K均值聚类的区别
-
聚类原理:
- 凝聚层次聚类:是一种自底向上的聚类方法,它从每个数据点作为单独的簇开始,然后逐步合并相似度高的簇。这个过程是通过计算簇之间的距离或相似度来确定的。簇之间的合并直到满足某个终止条件,例如达到预设的簇数或簇之间的相似度不再显著增加。
- k 均值聚类:是一种迭代优化的方法,它随机选择 k 个中心点,然后将这些中心点与数据点分配到最近的簇中。随后,它根据簇内点的平均位置更新簇的中心点,并重复这个过程直到收敛,即中心点的变化小于某个阈值或达到迭代次数上限。
-
适用场景:
- 凝聚层次聚类:适合于层次结构明显的数据集,可以用来探索数据的自然结构,适用于数据量较大且结构复杂的情况。
- k 均值聚类:适合于数据点可以明确分配到少数几个簇的情况,适用于数据量较小到中等,且数据特征明显的情况。
-
结果表示:
- 凝聚层次聚类:结果通常以树状图(dendrogram)的形式表示,可以直观地展示簇的合并过程和层次结构。
- k 均值聚类:结果是一组簇,每个簇包含一组数据点,且这些簇没有层次关系。
-
簇的数量:
- 凝聚层次聚类:不需要事先指定簇的数量,算法会根据数据自动确定簇的数量。
- k 均值聚类:需要事先指定簇的数量 k,算法会尝试找到最佳的 k 个中心点。
-
算法复杂度:
- 凝聚层次聚类:在计算距离矩阵和合并簇时,时间复杂度较高,特别是对于大型数据集。
- k 均值聚类:算法相对简单,计算效率较高,但在确定 k 值时可能需要多次迭代。
-
硬聚类与软聚类:
- 凝聚层次聚类通常被认为是硬聚类方法,因为它将数据点明确地分配到少数几个簇中。
- k 均值聚类被认为是软聚类方法,因为它为每个数据点分配一个概率,表明它属于各个簇的程度。
凝聚层次聚类的Python实现
from scipy.cluster import hierarchy
hierarchy.linkage(y, method='single', metric='euclidean') 这行代码告诉scikit-learn使用single链接方法和euclidean距离度量来对数据进行层次聚类分析。执行后,它会返回一个聚类树(dendrogram),表示数据点随着聚类合并的层次结构。
y:利用pdist()函数得到的两两样本之间的距离数组,或者是原始数据-
y是一个二维数组或距离矩阵,表示数据点之间的相似度或距离。每个元素y[i][j]表示数据点i和j之间的距离或相似度。
-
method:簇之间的近邻性度量方法,可取的值包括single,complete,average等-
method='single'是链接方法(Linkage Method)的参数。在层次聚类中,链接方法决定了如何合并两个聚类。single链接方法是指在合并两个聚类时,只考虑两个聚类中最近的数据点对之间的距离。换句话说,它会选择两个聚类中距离最近的两个点,并将它们作为新的聚类中心。
-
metric:选用的距离-
metric='euclidean'是距离度量(Distance Metric)的参数。它定义了计算数据点之间距离的方法。euclidean距离是指欧几里得距离,它是两点之间的直线距离,适用于各维度具有同等重要性的情况。
-
- 返回值:
linkage矩阵,层次聚类的结果
读取数据并预处理
cityDf = pd.read_csv('./data/clustering/cities_10.csv',header=0)
cityDf.head()
cityDf.set_index(cityDf.pop('AREA'),inplace=True)
cityDf绘制属性的箱型图,展示各个属性的取值范围
cityDf.plot(y=[f'X{i}' for i in range(1,10)],kind='box',figsize=(12,6))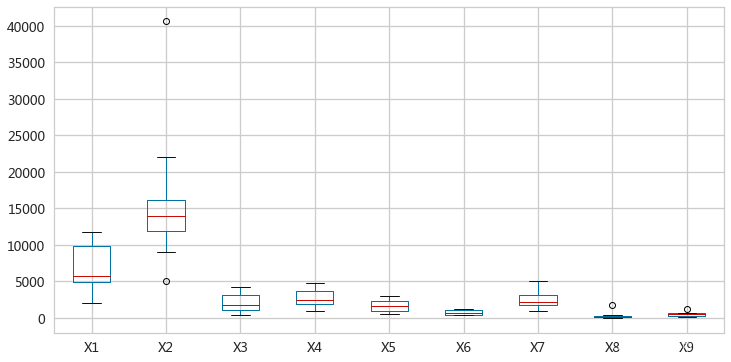
- 各个属性取值范围差异较大,需要对数据进行标准化
from sklearn.preprocessing import StandardScaler cityScaler = StandardScaler() cityX = cityScaler.fit_transform(cityDf) cityX建立凝聚层次模型
from scipy.cluster import hierarchy
cityAve = hierarchy.linkage(cityX,method='average',metric='euclidean')
cityAvepd.DataFrame(squareform(pdist(cityX,metric='euclidean')),
columns=cityDf.index,index=cityDf.index)这段代码是使用Python的pandas和scipy库来生成一个DataFrame,其中包含了城市之间的欧几里得距离矩阵。目的是计算城市之间的欧几里得距离,并将这些距离存储在一个DataFrame中,以便进一步分析或可视化城市之间的空间关系。
-
cityX是一个包含城市数据的列表或数组,假设每个城市是一个数据点,城市之间的数据可以是一个二维数组,其中行代表城市,列代表不同的特征。 -
pdist(cityX, metric='euclidean')是scipy.spatial.distance.pdist函数的调用,用于计算城市之间的成对距离。metric='euclidean'参数指定使用欧几里得距离作为距离度量。欧几里得距离是指在多维空间中两点之间的直线距离。 -
squareform(pdist(cityX, metric='euclidean'))是scipy.spatial.distance.squareform函数的调用,用于将成对距离转换成方阵形式。在方阵中,行和列都代表城市,对角线上的元素是城市与自己之间的距离,非对角线上的元素是城市之间的距离。 -
pd.DataFrame()是pandas库中的DataFrame构造函数,用于将上述生成的距离方阵转换成pandas的DataFrame对象。DataFrame是一个二维标签化数据结构,可以方便地进行数据操作和分析。 -
columns=cityDf.index, index=cityDf.index是DataFrame构造函数的参数,它们分别指定了DataFrame的列名和行名。这里假设cityDf是另一个包含城市信息的DataFrame,cityDf.index包含了城市的名称或标识符。

[(each,idx) for idx,each in enumerate(cityDf.index)] 这行代码 [(each, idx) for idx, each in enumerate(cityDf.index)] 是一个Python列表推导式,它的作用是创建一个包含元组的列表,每个元组包含两个元素:each 和 idx。
cityDf.index是 pandas DataFrame 的一个属性,它包含了 DataFrame 中所有行的标签。例如,如果 DataFrame 有三行,标签可能是['A', 'B', 'C']。enumerate(cityDf.index)函数会遍历cityDf.index中的每个元素,并返回一个包含索引和元素值的元组。例如,对于上面的标签,enumerate(cityDf.index)会返回[(0, 'A'), (1, 'B'), (2, 'C')]。- 列表推导式中的
for idx, each in enumerate(cityDf.index)部分遍历由enumerate(cityDf.index)生成的每个元组,idx是每个元素的索引,each是每个元素的值。
所以,这个列表推导式生成的列表是一个包含所有城市及其索引的元组列表。例如,如果 cityDf.index 是 ['纽约', '洛杉矶', '芝加哥'],那么列表推导式生成的列表将是 [('纽约', 0), ('洛杉矶', 1), ('芝加哥', 2)]。

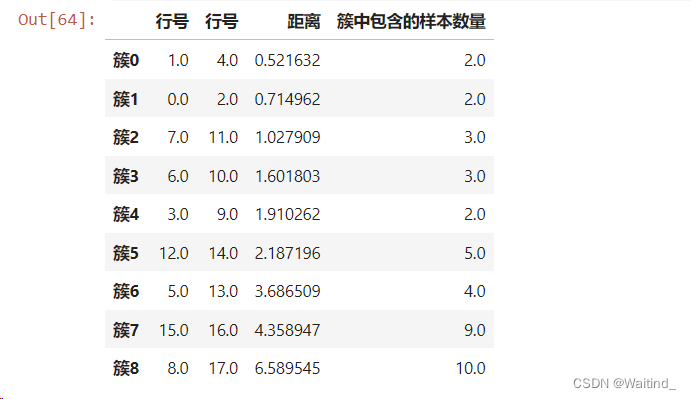
pd.DataFrame(cityAve,columns=['行号','行号','距离','簇中包含的样本数量'],
index=[f'簇{i}' for i in range(cityAve.shape[0])])cityAve是一个 NumPy 数组,可能包含了每个城市的一些平均值或者聚类结果。columns=['行号','行号','距离','簇中包含的样本数量']指定了新创建的 DataFrame 的列名。这里有四列,两列名为 ‘行号’,可能是因为 DataFrame 是对称的,每行和每列代表同一个城市的不同信息。'距离’和’簇中包含的样本数量’是其他两列的名称。cityAve.shape[0]:这是 NumPy 数组cityAve的第一个维度的大小,即数组中的元素或行数。这个值通常代表了聚类的簇数,因为在聚类分析中,每个簇通常会有一个对应的行。for i in range(cityAve.shape[0]):这个循环会遍历从0到cityAve.shape[0] - 1的整数,即从0到cityAve.shape[0] - 1。f'簇{i}':这是一个格式化字符串,其中{i}会被循环变量i的值替换。所以,当i为0时,字符串是'簇0';当i为1时,字符串是'簇1',以此类推。index=[f'簇{i}' for i in range(cityAve.shape[0])]:列表推导式创建了一个新的列表,其中包含了上述生成的所有字符串。这个列表最终被用作 DataFrame 的行索引。
树状图展示
from scipy.cluster import hierarchy
hierarchy.dendrogram(Z, orientation='top', labels=None, ax=None)Z:linkage矩阵,层次聚类结果orientation:根结点的位置,可选`{"top", "bottom","left","right"}- 这个参数指定了谱系图的布局方向。‘top’ 表示从上到下绘制谱系图,这是最常见的布局方式。还可以使用 ‘bottom’、‘left’ 或 ‘right’ 来分别表示从下到上、从左到右、从右到左的布局。
labels:原始数据点的标签,默认为None,即原始数据样本默认的行标签ax:matplotlib Axes对象,- 这是可选参数,指定了一个
matplotlib.axes._subplots.Axes实例,用于绘制谱系图。如果提供了这个参数,谱系图将在指定的轴上绘制,而不是创建一个新的图形。
- 这是可选参数,指定了一个
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12,6))
cityDn = hierarchy.dendrogram(cityAve,ax=ax,labels=cityDf.index)
plt.show()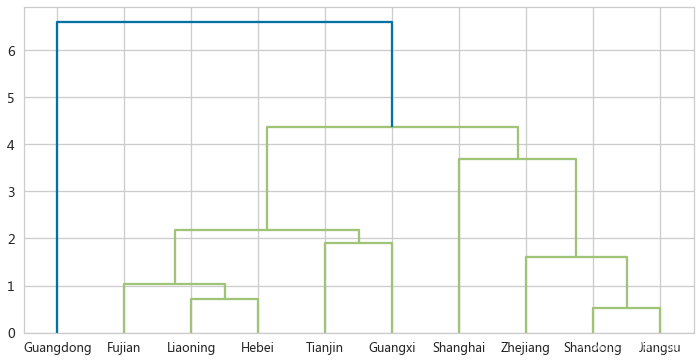
三种近邻性度量比较
-
‘single’(单链接):这是最简单的链接度量方法之一。在单链接聚类中,两个聚类之间的链接距离是两个聚类中最接近的两个点的距离。换句话说,它选择了两个聚类中最近的点对作为聚类间的距离。这种方法倾向于形成较大的聚类。
-
‘complete’(完全链接):与单链接方法相反,完全链接聚类中,两个聚类之间的链接距离是两个聚类中最远的两个点的距离。这种方法倾向于形成较小的聚类。
-
‘average’(平均链接):平均链接聚类中,两个聚类之间的链接距离是所有成对点的距离的平均值。这种方法试图找到一个中间点的距离,作为两个聚类间的平均距离。
# 初始化一个空列表来存储链接矩阵
cityLinkages = []
# 创建一个图形和一个轴的集合,用于绘制三个谱系图
# 3行1列,每个轴用于绘制一种不同的链接方法
fig, axes = plt.subplots(3, 1, figsize=(12, 12))
# 遍历三种不同的链接方法
for idx, linkage in enumerate(['single', 'complete', 'average']):
# 使用scipy的hierarchy模块中的linkage函数进行层次聚类
# cityX是一个距离矩阵,metric='euclidean'指定使用欧几里得距离作为相似度度量
lnk = hierarchy.linkage(cityX, method=linkage, metric='euclidean')
# 使用hierarchy模块中的dendrogram函数绘制谱系图
# lnk是上一步计算的链接矩阵,ax=axes[idx]指定在哪个轴上绘制,labels=cityDf.index提供了每个簇的标签
dn = hierarchy.dendrogram(lnk, ax=axes[idx], labels=cityDf.index)
# 显示图形
plt.show()
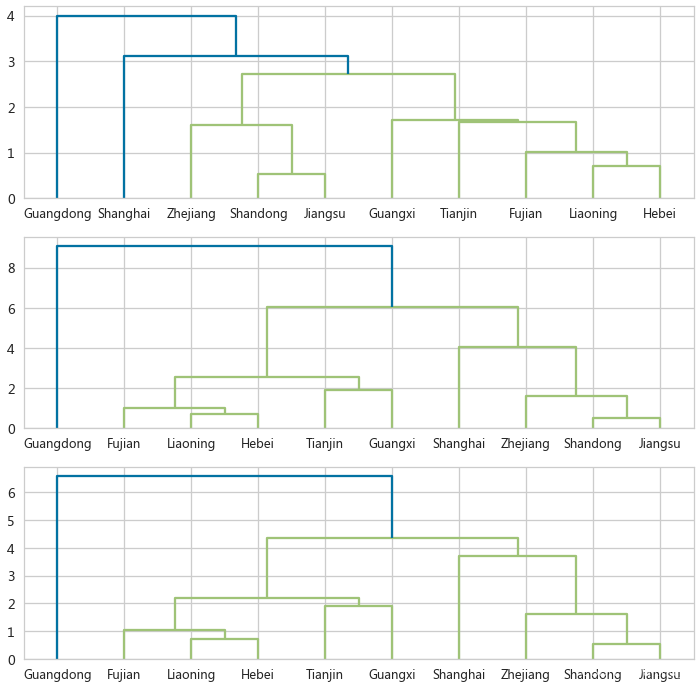
sklearn中的凝聚层次聚类
from sklearn.cluster import AgglomerativeClustering
AgglomerativeClustering(n_clusters=2, affinity=’euclidean’, linkage=’ward’)这行代码创建了一个层次聚类器,指定要生成两个簇,使用欧几里得距离作为相似性度量,使用ward方法作为链接方式。
AgglomerativeClustering是scikit-learn库中的一种聚类算法,它是一种层次聚类算法。n_clusters:int类型,簇的个数,指定要生成的簇的数量affinity:近邻度的度量,指定用于计算相似性的度量,可以选择'euclidean', 'manhattan', 'cosine'等- 在这个例子中,
affinity='euclidean'表示使用欧几里得距离作为度量。欧几里得距离是一种衡量两点之间直线距离的方法,适用于空间中点的距离计算。
- 在这个例子中,
linkage:str类型,簇之间的链接类型,指定用于合并相似性度的链接方法,可以选择'ward', 'complete', 'average', 'single'- 在这个例子中,
linkage='ward'表示使用ward方法。Ward方法是一种优化类间距离的方法,目的是减少类内的平方误差和最大化类间的平方误差。这种方法通常用于聚类分析,特别是在处理数据点数量较多且维度较高时。
- 在这个例子中,
利用AgglomerativeClustering对凝聚层次聚类剪枝
建立凝聚层次模型
from sklearn.cluster import AgglomerativeClustering
cityAc = AgglomerativeClustering(n_clusters=4,affinity='euclidean',linkage='average')
cityAc训练模型并预测样本所属的簇
cityLabels = cityAc.fit_predict(cityX)
cityLabels
cityDf['cluster']=cityLabels
cityDf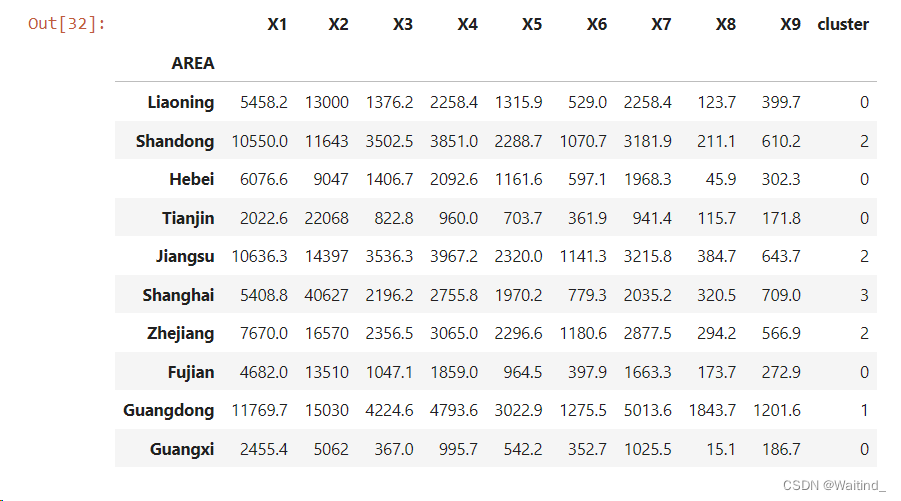
基于密度的聚类
基于密度的聚类(Density-Based Clustering)是一种聚类算法,它主要根据数据点的密度来划分簇。与传统的聚类方法(如K-Means)相比,基于密度的聚类方法在处理复杂数据结构时能更好地发现簇的形状和大小。
关键概念
-
密度:密度反映了数据点在空间中的分布。在基于密度的聚类中,密度高的区域表示数据点较为集中,而密度低的区域则表示数据点较为稀疏。
-
核心点(Core Points):核心点是指在一个簇中,至少要有足够的邻居(根据预设的邻域半径)来满足某个密度阈值的数据点。核心点是构成簇的基础。
-
边界点(Border Points):边界点是指那些邻居不足以满足密度阈值的数据点,它们可能属于某个簇,但也可能接近另一个簇的边界。
-
邻域(Neighborhood):邻域是指在数据空间中,一个数据点周围的一定范围内的点。邻域的大小通常由一个距离阈值来决定。
基于密度的聚类算法通常包括以下步骤:
- 计算所有核心点。
- 对于每个核心点,找到它的邻域。
- 将邻域中的每个点标记为属于某个簇(如果它们之前没有被标记)。
- 更新簇的边界。
- 重复步骤2-4,直到没有新的簇可以创建。
一些著名的基于密度的聚类算法包括:
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise):这是一种非常流行的基于密度的聚类算法,它可以发现任何形状的簇,并且能够处理噪声和异常值。
- OPTICS(Ordering Points To Identify the Clustering Structure):这是DBSCAN的一种改进版本,它使用一种新的方式来确定邻域,并且能够更好地识别簇的结构。
- HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise):这是DBSCAN的层次版本,它可以创建簇的层次结构,并且能够处理大规模数据集。
区别
-
基于密度的聚类(Density-Based Clustering):
- 基于密度的聚类算法,如DBSCAN,通过密度来定义簇。它将密度高的区域划分为簇,并且可以发现任何形状的簇。
- DBSCAN等算法可以识别出噪声点和边界点,这对于包含异常值或噪声的数据集来说非常有用。
- 这类算法不需要预先指定簇的数量,但最终的结果可能会受到初始点选择的影响。
-
凝聚层次聚类(Agglomerative Hierarchical Clustering):
- 凝聚层次聚类是一种自底向上的聚类方法,它开始于每个数据点作为单独的簇,然后逐渐合并相似的簇。
- 合并的过程基于数据点之间的距离或相似度,使用不同的链接方法(如ward、complete、single等)。
- 凝聚层次聚类不需要预先指定簇的数量,但最终的结果可能会受到数据点初始排列的影响。
-
K均值聚类(K-Means Clustering):
- K均值聚类是一种迭代算法,它试图找到K个簇,使得每个簇的内部点之间的距离最小,而簇之间的距离最大。
- K均值算法需要预先指定簇的数量K,并且假设簇是圆形的。
- K均值聚类对于异常值比较敏感,并且在执行过程中可能会陷入局部最小值。
总结:
- 基于密度的聚类适用于发现任何形状的簇,对噪声(与目标无关或者不包含有用信息的随机数据)和异常值比较鲁棒(聚类效果坚韧),不需要预先指定簇的数量。
- 凝聚层次聚类可以发现簇的结构,不需要预先指定簇的数量,但受初始点排列的影响。
- K均值聚类适用于发现圆形的簇,对噪声敏感,需要预先指定簇的数量。
DBSCAN的Python实现
from sklearn.cluster import DBSCAN
DBSCAN(eps=0.5, min_samples=5, metric='euclidean', n_jobs=None)eps:float类型,半径,两个数据点被认为属于同一个邻域的最大距离- 这个参数定义了邻域的大小,即在给定距离范围内,一个点被视为核心点。如果两个核心点之间的距离小于
eps,它们被视为邻近点。eps的选择取决于数据集的特性,通常需要通过实验来确定一个合适的值。
- 这个参数定义了邻域的大小,即在给定距离范围内,一个点被视为核心点。如果两个核心点之间的距离小于
min_samples:int类型,核心点所在邻域所要包含的数据点的最小数量,核心点包括在内- 这个参数定义了一个核心点需要有多少个邻近点来满足核心点的条件。在一个核心点的邻域中,至少要有
min_samples个点,这样才能被认定为核心点。这个值也需要根据具体的数据集来确定。
- 这个参数定义了一个核心点需要有多少个邻近点来满足核心点的条件。在一个核心点的邻域中,至少要有
metric:距离的度量,可以选择'minkowski','euclidean'等- 这个参数指定了距离度量的方式,
euclidean表示使用欧几里得距离。还有其他距离度量方法,如曼哈顿距离(manhattan)、切比雪夫距离(chebyshev)等。
- 这个参数指定了距离度量的方式,
-
n_jobs=None:这个参数用于并行计算,如果设置为-1,则表示使用所有可用的处理器来进行并行计算。这可以加快算法的执行速度,特别是对于大规模数据集。如果设置为其他值,表示使用指定数量的处理器。
建立DBSCAN模型
from sklearn.cluster import DBSCAN
irisDB = DBSCAN(eps=1,min_samples=30,metric='euclidean',n_jobs=-1)训练模型并预测样本所属簇
irisLabelsDB = irisDB.fit_predict(irisX)
irisLabelsDB
确定min_samples
min_samples过小,簇数量过多min_samples过大,簇数量过少
- 经验值min_samples=2×属性数量,或者min_samples=属性数量+1
- 数据样本点非常多或者噪声非常多的数据,
min_samples应当增大
确定eps半径
- 利用k最邻近距离判断数据点之间的聚类大小
- 令k=min_samples
- 绘制k最邻近距离图像,图像的肘部(elbow)位置对应的距离即为
eps
from sklearn.neighbors import NearestNeighbors
NearestNeighbors(n_neighbors=5, n_jobs=None)n_neighbors:邻近点数量n_jobs:用多少个核并行计算,-1为所有核
nbrsIris = NearestNeighbors(n_neighbors=5) # 建立近邻模型
nbrsIris.fit(irisX)
distancesIris, indicesIris = nbrsIris.kneighbors(irisX)
distancesIris # 与最邻近点之间的距离
indicesIris # 最邻近点的索引绘制最邻近距离图像
-
将最邻近距离排序
distancesIris = np.sort(distancesIris[:,-1], axis=0)
axDistIris = pd.Series(distancesIris).plot(kind='line')
axDistIris.set(ylabel='Distance')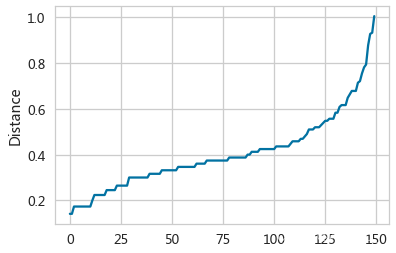
-
找到拐点
pip install kneed[plot]
from kneed import KneeLocator
KneeLocator(x,y,S=1,curve='convex',direction='increasing')x:待检测数据对应的横轴数据序列,一系列的值,通常是对应于聚类数量的 x 轴数据。y:待检测数据序列,一系列的值,通常是对应于某种性能指标的 y 轴数据。这个性能指标可以是聚类质量、轮廓系数、内部凝聚度等S:敏感度参数,越小对应拐点被检测出得越快,建议值1,这个参数是用来平滑曲线的。S越小,曲线越尖锐,拐点越容易识别。默认值为 1,通常不需要调整。curve:曲线类型,可以是concave(凹函数),也可以是convex(凸函数),指定曲线的形状。'convex'表示凸曲线,'concave'表示凹曲线。默认值为'convex'。direction:曲线趋势,指定寻找拐点的方式。可以是increasing或decreasing'increasing'表示随着 x 增加,y 也增加;'decreasing'表示随着 x 增加,y 减少。默认值为'increasing'。
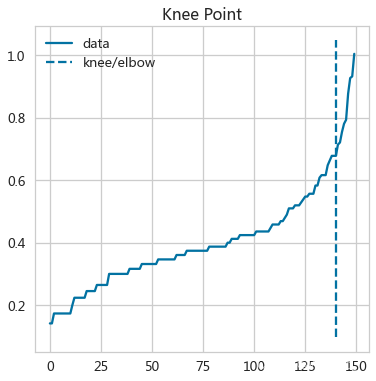
kneeIris = KneeLocator(range(len(distancesIris)),distancesIris,S=1,
curve='convex',direction='increasing',online=False)
kneeIris.plot_knee() # 绘制曲线与拐点位置(肘部图)
distancesIris[kneeIris.elbow]
重新训练DBSCAN模型
irisDBNew = DBSCAN(eps=0.678,min_samples=5,metric='euclidean',n_jobs=-1)
irisDBNew.fit_predict(irisX)-
eps(epsilon):这是DBSCAN算法中的一个关键参数,它表示邻域的大小。在这个例子中,eps=0.678意味着如果一个点到核心点的距离小于或等于0.678,那么这个点将被视为属于同一个邻域。 -
min_samples:这是另一个重要参数,它表示一个聚类需要的最小样本数。在这个例子中,min_samples=5意味着只有当一个核心点周围至少有5个点时,它才会被用于形成一个聚类。 -
metric='euclidean':这指定了距离度量方法,euclidean表示欧几里得距离,这是一种在多维空间中测量两点之间直线距离的方法。 -
n_jobs=-1:这个参数用于并行计算,-1表示使用所有可用的处理器,以便加快算法的执行速度。这对于拥有多个核心的现代计算机是非常有用的,可以显著减少计算时间。
K-means、凝聚层次聚类、基于密度聚类比较
-
生成月牙形状的数据
from sklearn.datasets import make_moons X,y = make_moons(n_samples=200,noise=0.05,random_state=0) X[:5,:] y[:5] pd.DataFrame(X).plot(kind='scatter',x=0,y=1,figsize=(12,6),c='steelblue')
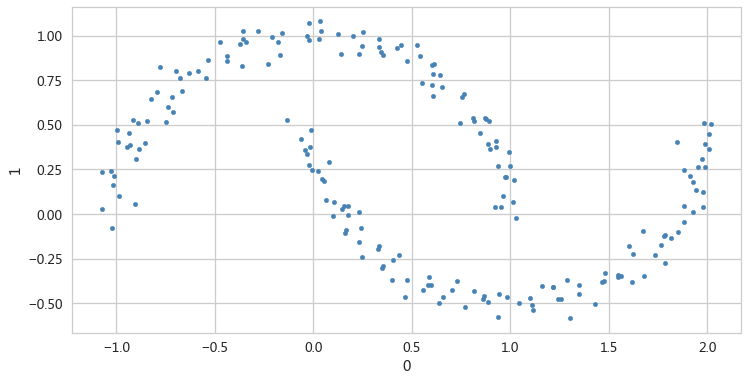
K-means聚类
km = KMeans(n_clusters=2,random_state=0)
y_km = km.fit_predict(X)
ax_km = pd.DataFrame(X[y_km==0,:]).plot(kind='scatter',x=0,y=1,figsize=
(12,6),c='lightblue',edgecolor='black',marker='o',s=40,label='cluster 1')
pd.DataFrame(X[y_km==1,:]).plot(kind='scatter',x=0,y=1,ax=ax_km,
c='red',edgecolor='black',marker='s',s=40,label='cluster 2')
ax_km.set(title='K-means clustering')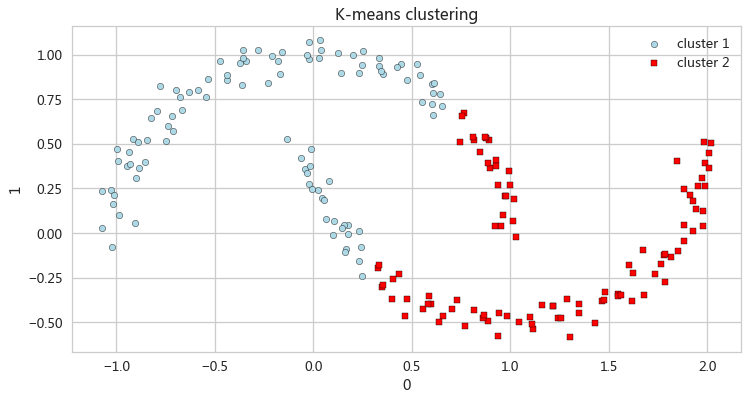
凝聚层次聚类
ac = AgglomerativeClustering(n_clusters=2,affinity='euclidean',linkage='complete')
y_ac = ac.fit_predict(X)
ax_ac = pd.DataFrame(X[y_ac==0,:]).plot(kind='scatter',x=0,y=1,figsize=
(12,6),c='lightblue',edgecolor='black',marker='o',s=40,label='cluster 1')
pd.DataFrame(X[y_ac==1,:]).plot(kind='scatter',x=0,y=1,ax=ax_ac,c='red',edgecolor='black',marker='s',s=40,label='cluster 2')
ax_ac.set(title='Agglomerative clustering')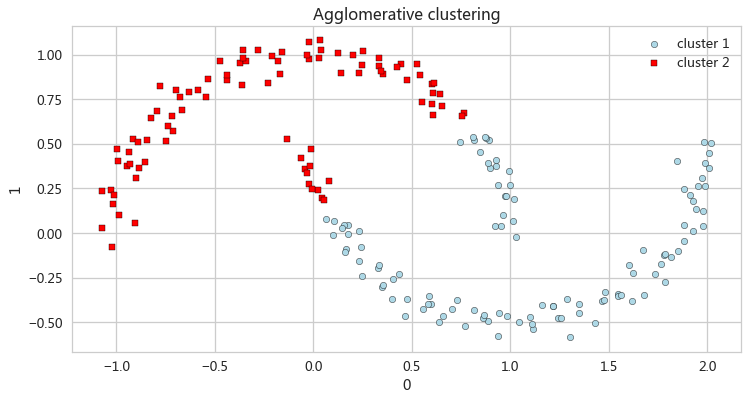
基于密度的聚类
db = DBSCAN(eps=0.2,min_samples=5,metric='euclidean')
y_db = db.fit_predict(X)
ax_db = pd.DataFrame(X[y_db==0,:]).plot(kind='scatter',x=0,y=1,
figsize=(12,6),c='lightblue',edgecolor='black',marker='o',s=40,label='cluster 1')
pd.DataFrame(X[y_db==1,:]).plot(kind='scatter',x=0,y=1,ax=ax_db,
c='red',edgecolor='black',marker='s',s=40,label='cluster 2')
ax_db.set(title='DBSCAN clustering')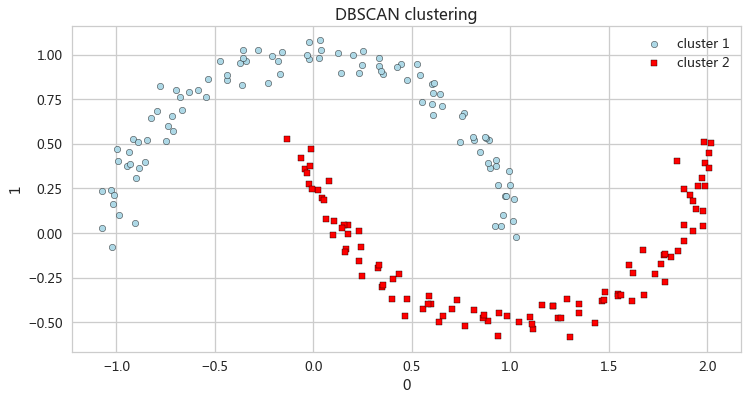
聚类检验
聚类检验:检验聚类效果的优劣
- 评估指标
- 监督评估,利用外部信息(例如类别)来判断聚类效果的优劣
- 非监督评估:利用数据本身的信息来判断
非监督评估
凝聚度(cohesion):簇内数据点之间的密切程度
- 可以是簇内各个数据点之间距离的均值
分离度(separation):某个簇不同于其他簇的程度
- 不同簇的数据点之间的距离的均值

轮廓系数(silhouette coefficient)
- ai是第i个数据对象到所属簇中其他所有数据对象距离的平均值
- 计算第i个数据对象到给定簇(非所属簇)中所有数据对象距离的平均值
- 所有K−1(K为簇的数量)个这样的值中的最小值定义为bi
- 轮廓系数计算公式:si∈[−1,1]

- 轮廓系数越接近1越好
- 0表示两个簇重合
- -1表示数据点被分配到了错误的簇中
轮廓系数的Python实现
计算轮廓系数
from sklearn.metrics import silouette_samples, silhouette_score
silhouette_samples(X, labels, metric=’euclidean’) sklearn.metrics.silhouette_samples这个函数用于计算每个样本的轮廓系数
X:用于聚类的数据,是一个二维数组,其中包含了用于聚类的数据点。每个数据点是一个样本,而每行代表了单个样本的所有特征。labels:用聚类技术计算的每个数据样本所属的簇,是一个一维数组,包含了每个样本的聚类标签。数组的长度应该与X中样本的数量相匹配。-
metric='euclidean':这是一个字符串参数,指定了用于计算距离的度量方法。在这个例子中,'euclidean'表示使用欧几里得距离来计算样本之间的相似度。 - 返回值:由所有样本的轮廓系数构成的数据,形状为
[n_samples]
silhouette_score(X, labels, metric=’euclidean’)这串代码是一个函数调用,用于计算整个数据集的轮廓系数平均值
X:用于聚类的数据labels:用聚类技术计算的每个数据样本所属的簇- 返回值:
float类型,所有数据样本的轮廓系数的平均值
from sklearn.metrics import silhouette_samples, silhouette_score
irisSilhouetteVals = silhouette_samples(irisX,irisKmeans.labels_)
irisSilhouetteVals
irisSilhouetteScore = silhouette_score(irisdf.iloc[:,:-1],irisKmeans.labels_)
irisSilhouetteScore
irisSilhouetteVals.mean()silhouette_score实际上等于silhouette_samples返回值的均值
绘制轮廓系数图
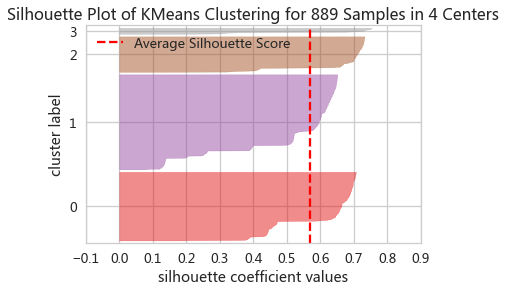
轮廓系数图:将每个簇中的样本的轮廓系数按升序排序,绘制成的水平柱状图
from matplotlib import cm
def silhouette_plot(clusterLabels, X):
"""绘制轮廓系数图,clusterLabels是聚类预测得到的簇标签,X是原始数据集"""
silhouetteVals = silhouette_samples(X,clusterLabels) # 计算所有样本的轮廓系数
fig,ax = plt.subplots(figsize=(12,12))
yLower = 10 # 每个簇纵坐标的下界
yTicks = [] # 记录纵坐标标记的位置
uniqueClusters = np.unique(clusterLabels) #获得独特的簇标签
for k in uniqueClusters:
# 筛选出第k簇样本的所有轮廓系数
kthClusterSilhouetteVals = silhouetteVals[clusterLabels==k]
# 对筛选出的第k簇的轮廓系数排序
kthClusterSilhouetteVals.sort()
# 每个簇纵坐标的上界
yUpper = yLower + len(kthClusterSilhouetteVals)
# 为每个簇设定一个颜色
colors = cm.nipy_spectral(k / len(uniqueClusters))
# 绘制水平柱状图
ax.barh(range(yLower,yUpper),kthClusterSilhouetteVals,height=1.0,edgecolor='b',color=colors)
# 设置纵坐标标记的显示位置
yTicks.append((yLower+yUpper)/2)
# 更新下一个簇的纵坐标的下界
yLower = yUpper + 10
ax.set(xticks=np.linspace(-0.1,1,12), yticks=yTicks,yticklabels=uniqueClusters,xlabel='轮廓系数',ylabel='簇标签',xlim=[-0.1,1])
# 将平均轮廓系数用垂直线绘制在图中
ax.axvline(x=silhouetteVals.mean(), color="red", linestyle="--")
plt.show()
silhouette_plot(irisLabel,irisX)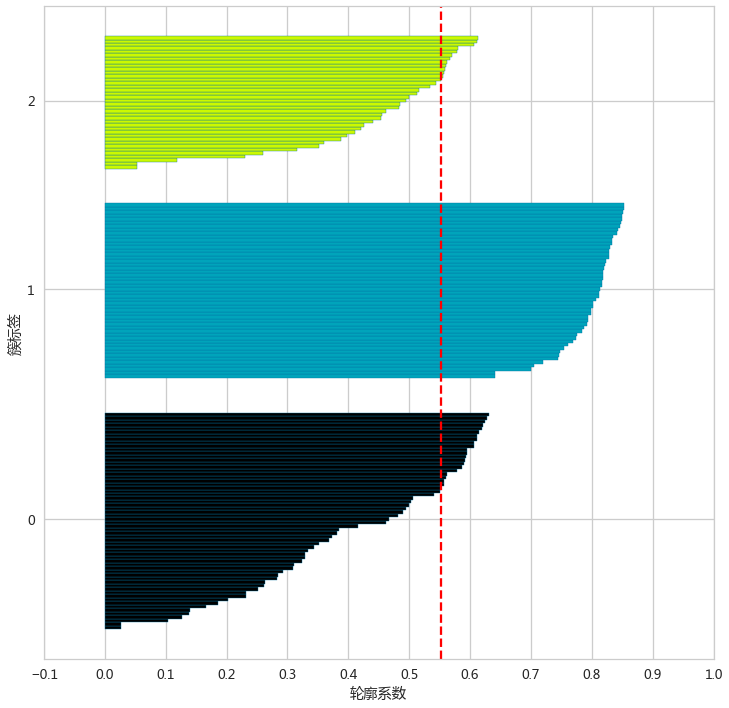
- 好的聚类,轮廓系数图应当满足各个簇的长度和宽度近似相等
Yellowbrick中的轮廓系数图
Yellowbrick 是一个可视化库,它提供了用于数据可视化和模型评估的工具。
from yellowbrick.cluster import SilhouetteVisualizer
silviz = SilhouetteVisualizer(estimator, colors=None)
silviz.fit(X)
silviz.show()estimator:是一个已经训练好的聚类模型,它应该是一个scikit-learn聚类 estimator 对象,例如KMeans、DBSCAN等。这个 estimator 对象用于计算聚类结果和轮廓系数。color:轮廓图颜色,是一个可选参数,用于指定聚类中心的颜色。如果提供,它应该是一个颜色字符串列表或者颜色映射,例如['red', 'blue', 'green']或者plt.cm.Set1。如果未提供,Yellowbrick 会使用默认的颜色映射。可以是Yellowbrick或者matplotlib的颜色地图,例如Yellowbrick的颜色地图参考,Colors and Style — Yellowbrick v1.5 documentation
silViz = SilhouetteVisualizer(i ,color='yellowbrick')
silViz.fit(irisX)
silViz.show()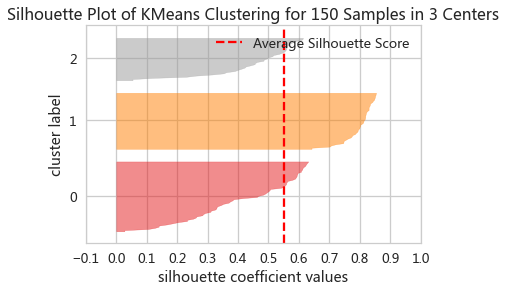
聚类结果可视化
- 将高维空间数据投射到低维(2维或3维)空间
- 核心需要在低维空间保持高维空间中点之间的相似关系
- 两种常用实现方法
- MDS:Multi-Dimensional Scaling
- t-SNE: t-Distributed Stochastic Neighbor Embedding
MDS
- 在低维空间尽可能保持高维空间中点之间的距离(即相似性)。
t-SNE
- 构建高维空间中点之间的概率分布,高斯分布
- 构建低维空间中点之间的概率分布,t分布
- 尽可能使得两个分布接近
将高维空间数据投射到低维(2维或3维)空间,并保持高维空间中点之间的相似关系,实际上是维度规约(Dimensionality Reduction)的一个具体应用。维度规约是指将数据从高维空间转换到较低维空间的过程,旨在通过去除不重要或不显著的变量来简化数据集,同时尽可能保留原始数据中的信息和结构。
在这个背景下,核心概念是:
-
保持相似性:在降低维度的过程中,确保数据点在低维空间中的相对位置和距离与他们在高维空间中的相对位置和距离尽可能相似。这意味着,如果两个点在高维空间中是接近的,它们在低维空间中也应该是接近的。
-
数据结构保留:在降维后的空间中,数据的结构和模式应该仍然明显,这样聚类分析等任务就可以在低维空间中有效地进行,而不会失去重要的信息。
-
可视化:在2维或3维空间中可视化高维数据,使得人类分析师能够直观地理解和解释数据。
因此,将数据投射到低维空间并保持相似关系是维度规约的一部分,特别是在聚类和数据挖掘的上下文中。这个过程对于分析复杂数据集、识别模式和趋势以及进行有效的数据可视化至关重要。选择合适的降维算法对于实现这些目标至关重要,因为不同的算法在保留数据结构方面有不同的效果。
可视化方法
from yellowbrick.cluster import InterclusterDistance
InterclusterDistance(estimator,embedding='mds',scoring='membership',random_state=None)-
estimator:这是一个已经训练好的聚类模型,它应该是一个scikit-learn聚类 estimator 对象,例如KMeans、DBSCAN等。这个 estimator 对象用于计算聚类结果。 -
embedding:高维空间到低维空间的投射方法,这个参数指定了用于将聚类结果映射到低维空间的嵌入方法。在这里,'mds'表示使用多维尺度变换(Multidimensional Scaling,MDS)这种方法。MDS是一种无监督学习算法,用于将高维数据映射到低维空间,同时尽可能地保持数据点之间的相似性。相似性通常指的是数据点之间的接近程度 -
scoring:决定簇在图上展现的大小,‘membership’计算每个簇中样本数量 -
random_state:这是一个可选参数,用于指定随机状态,以保证结果的可重复性。如果提供了整数值,那么算法将使用这个随机状态;如果没有提供,那么算法可能会使用一个默认的随机状态或者不使用随机状态。
idVis = InterclusterDistance(irisKmeans,emdding='tsne',random_state=10)
idVis.fit(irisX)
idVis.show()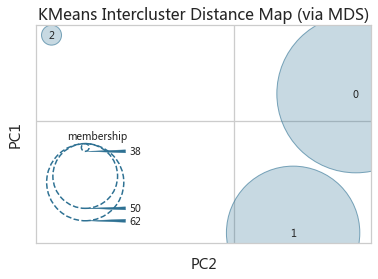
网站运营分析示例
某企业由于投放的广告渠道比较多,需要对其做广告效果分析以实现有针对性的广告效果测量和优化工作。
要求:将广告分类并找出重点特征,为后续的业务讨论提供支持。
读入数据
adRaw = pd.read_csv('./data/clustering/ad_performance.txt',sep='\t')
adRaw.head()
adRaw.shape
adRaw.dtypes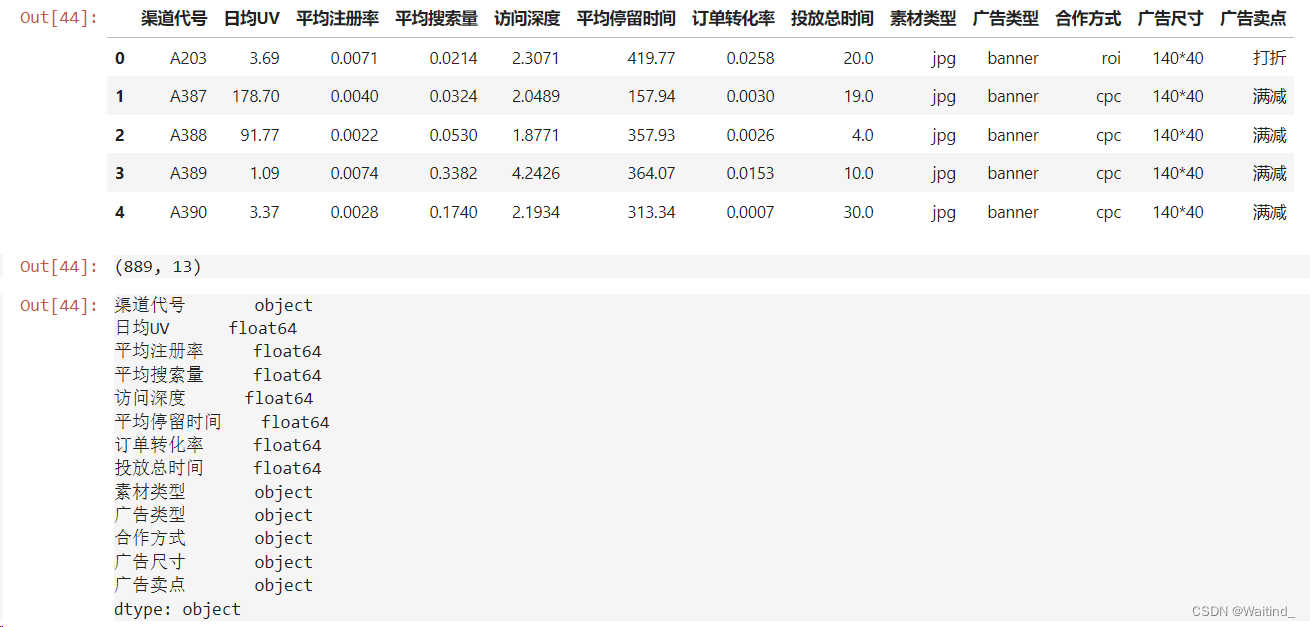
描述性统计
adRaw.describe()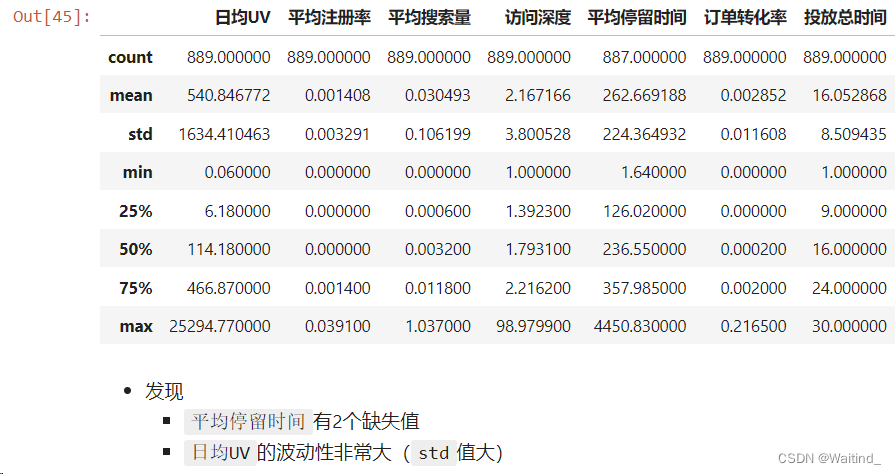
for colName in adRaw.columns[-5:]:
adRaw[colName].value_counts(normalize=True)这段代码的目的是遍历DataFrame中最后五个列,并计算每个列中不同值的出现频率,归一化到概率分布。
-
adRaw:这是一个Pandas DataFrame对象,它包含了数据。 -
adRaw.columns[-5:]:这个表达式获取DataFrame中的列名列表,并且只选择最后五个列。[-5:]是一个切片操作,它从列列表的末尾开始,选择最后一个到倒数第五个元素。 -
for colName in adRaw.columns[-5:]::这是一个for循环,它遍历刚才选择的列名列表。colName是循环中的临时变量,用于存储当前的列名。 -
adRaw[colName].value_counts(normalize=True):在循环体内,对每一列执行value_counts方法。这个方法用于计算列中每个唯一值的出现次数。normalize=True参数表示将计数结果归一化,即转换为概率分布。这意味着每个值的计数将被 normalized 为该列的总值的比例。
数据可视化
属性的分布特征
_ = adRaw.plot(y=['日均UV','平均注册率','平均搜索量','访问深度',
'平均停留时间','订单转化率','投放总时间'],
kind='hist',bins=50,figsize=(12,12),subplots=True,layou-
y=['日均UV','平均注册率','平均搜索量','访问深度','平均停留时间','订单转化率','投放总时间']:这个参数指定了要绘制直方图的列名列表。 -
bins=50:这个参数指定了直方图的柱状数量。bins的数量会影响直方图的分辨率,即每个柱状表示的数据范围。 -
subplots=True:这个参数指示函数创建一个子图网格,每个指定的列将在不同的子图上绘制直方图。 -
layout:这个参数可能是用于指定子图的布局,但是这里的代码片段中没有提供完整的参数值,所以具体布局无法确定。通常,layout参数可以是一个字典,用于指定子图的排列方式,例如layout={'rows': 2, 'cols': 3},表示创建一个2行3列的子图网格。
colNames = ['日均UV','平均注册率','平均搜索量','访问深度',
'平均停留时间','订单转化率','投放总时间']
fig,axes = plt.subplots(len(colNames),1,figsize=(12,36))
for i,colName in enumerate(colNames):
_ = adRaw[colName].plot(y=colName,kind='hist',bins=50,ax=axes[i],
color=cm.gist_earth(i/len(colNames)))
_ = axes[i].set(xlabel=colName)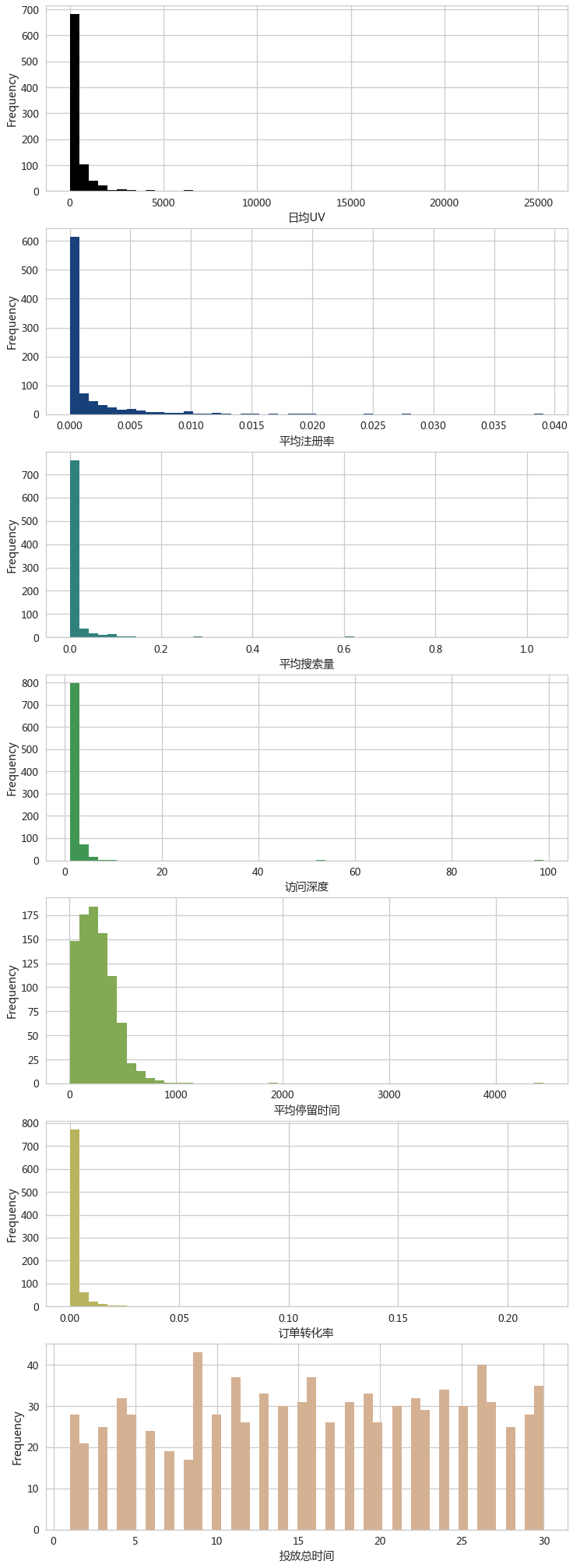
- 发现
日均UV,平均注册率,平均搜索量,访问深度,平均停留时间,订单转化率均呈现偏态分布
属性的波动范围特征
_ = adRaw.plot(y=colNames,kind='box',figsize=(12,6))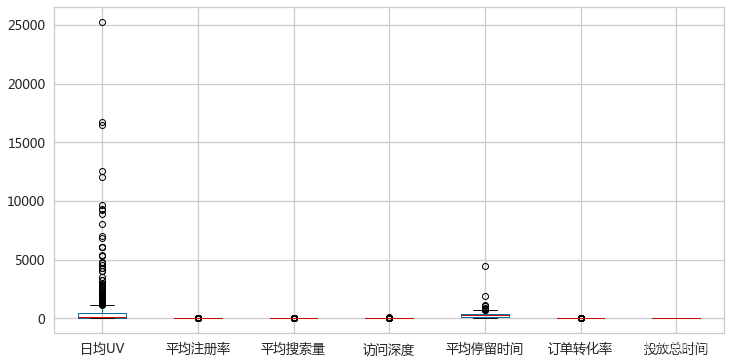
- 发现
- 各个属性的波动范围差异较大
日均UV有较多的异常点
数据预处理
缺失值
adRaw.isna().sum()

筛选含有缺失值的记录
adRaw.loc[adRaw['平均停留时间'].isna(),:]
用均值填充缺失值
adRaw.fillna({'平均停留时间':adRaw['平均停留时间'].mean()},inplace=True)
adRaw.isna().sum()
检查是否存在重复记录
adRaw.duplicated().unique()
标称属性转换为数值型
adX = adRaw.copy()
for colName in adRaw.columns[-5:]:
codes,_ = pd.factorize(adX[colName])
adX[colName] = codes
adX.head()
adX.set_index(keys='渠道代号',inplace=True)
adX.head()
标准化数据
from sklearn.preprocessing import MinMaxScaler
adScale = MinMaxScaler()
scaleDat = adScale.fit_transform(adX.iloc[:,:7])
scaleDf = pd.DataFrame(scaleDat,columns = adX.columns[:7],index=adX.index)
scaleDf.head()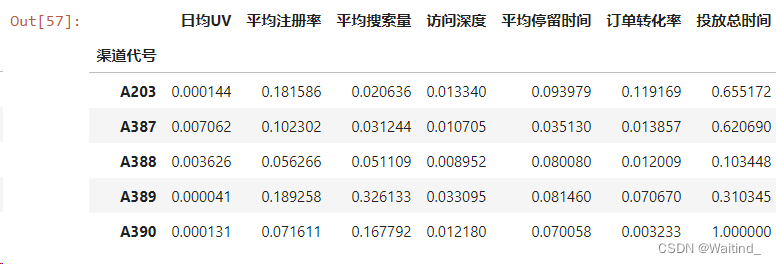
adXScale = scaleDf.merge(right=adX.iloc[:,-5:],left_index=True,right_index=True)
adXScale.head()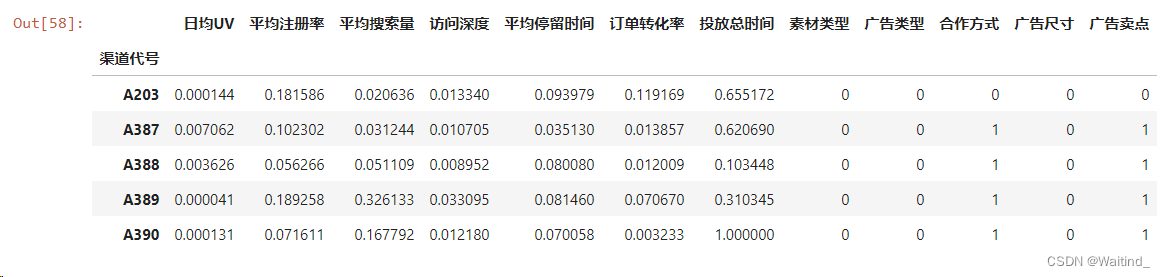
adXScale = scaleDf.merge(right=adX.iloc[:,7:],left_index=True,right_index=True)
adXScale.head()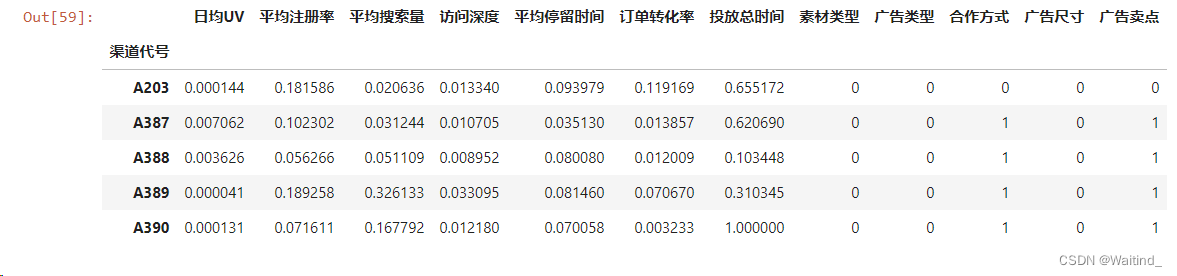
K均值聚类
选择K值
kwebElbowViz = KElbowVisualizer(KMeans(random_state=10),k=(1,21))
kwebElbowViz.fit(adXScale)
kwebElbowViz.show()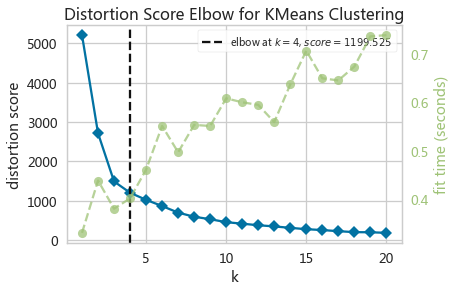
inertias = []
for k in range(2,21):
km = KMeans(n_clusters=k,random_state=20,n_jobs=-1)
_ = km.fit(adXScale)
inertias.append(km.inertia_)
adAx = pd.Series(inertias).plot(kind='line',marker='o',grid=True,figsize=(12,6))
_ = adAx.set(xticks=range(0,20),xticklabels=range(2,21),xlabel='$K$',ylabel='SSE')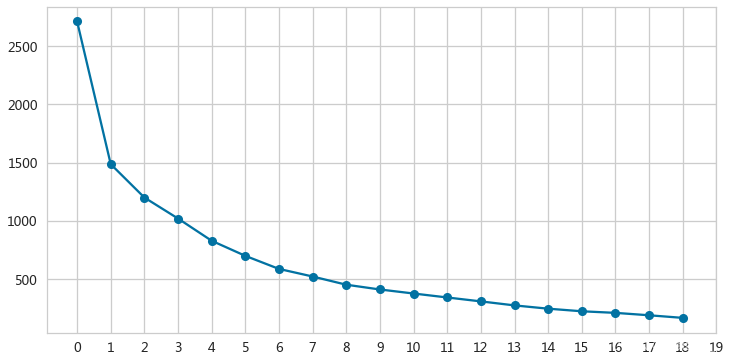
- SSE曲线变化连续,无明显肘部
- 绘制轮廓系数图
kwebElbowVizSil = KElbowVisualizer(KMeans(random_state=10),k=(2,21),metric='silhouette')
kwebElbowVizSil.fit(adXScale)
kwebElbowVizSil.show()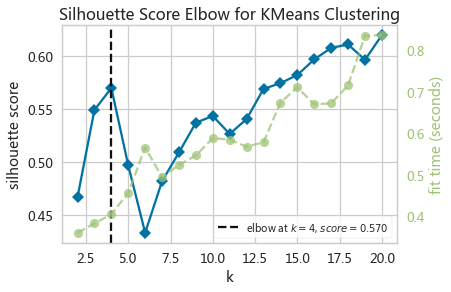
sil = []
K = range(2,21)
for k in K:
km = KMeans(n_clusters=k,random_state=20,n_jobs=-1)
kmPred = km.fit_predict(adXScale)
sil.append(silhouette_score(adXScale,kmPred))
adAx = pd.Series(sil).plot(kind='line',marker='o',grid=True,figsize=(12,6))
_ = adAx.set(xticks=range(0,20),xticklabels=range(2,21),xlabel='$K$',ylabel='轮廓系数')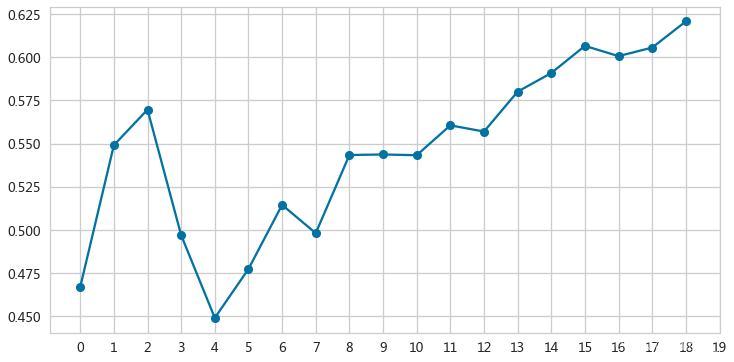
选择K=4
建立并训练K均值模型
adKm = KMeans(n_clusters=4,random_state=20)
adClusters = adKm.fit_predict(adXScale)
pd.Series(adClusters).value_counts()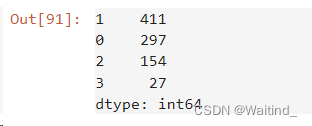
评估聚类效果
轮廓系数均值
silhouette_score(X=adXScale,labels=adClusters)轮廓系数图
webSilViz = SilhouetteVisualizer(adKm,color='yellowbrick')
webSilViz.fit(adXScale)
webSilViz.show()
簇的可视化
adKmIcVis = InterclusterDistance(adKm,embedding='tsne',random_state=10)
adKmIcVis.fit(adXScale)
adKmIcVis.show()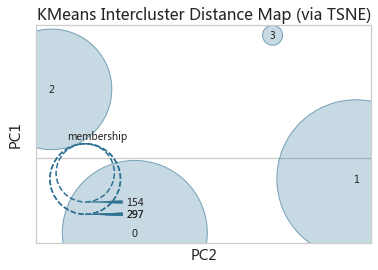
silhouette_plot(adClusters,adXScale)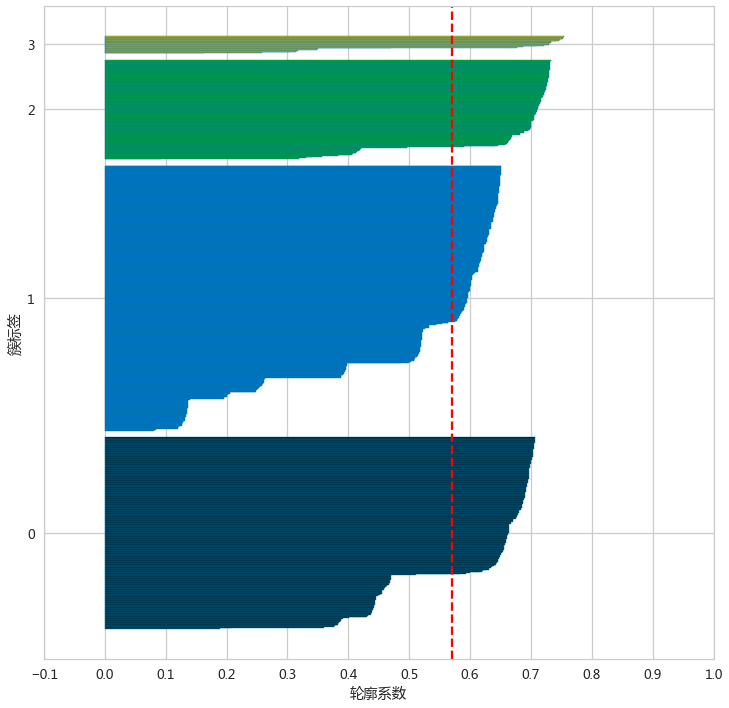
凝聚层次聚类
建立凝聚层次模型
from scipy.cluster import hierarchy
adLinkage = hierarchy.linkage(adXScale,method='average')绘制层次聚类树状图
fig,axe = plt.subplots(figsize=(36,24))
_ = hierarchy.dendrogram(adLinkage,ax=axe,labels=adX.index)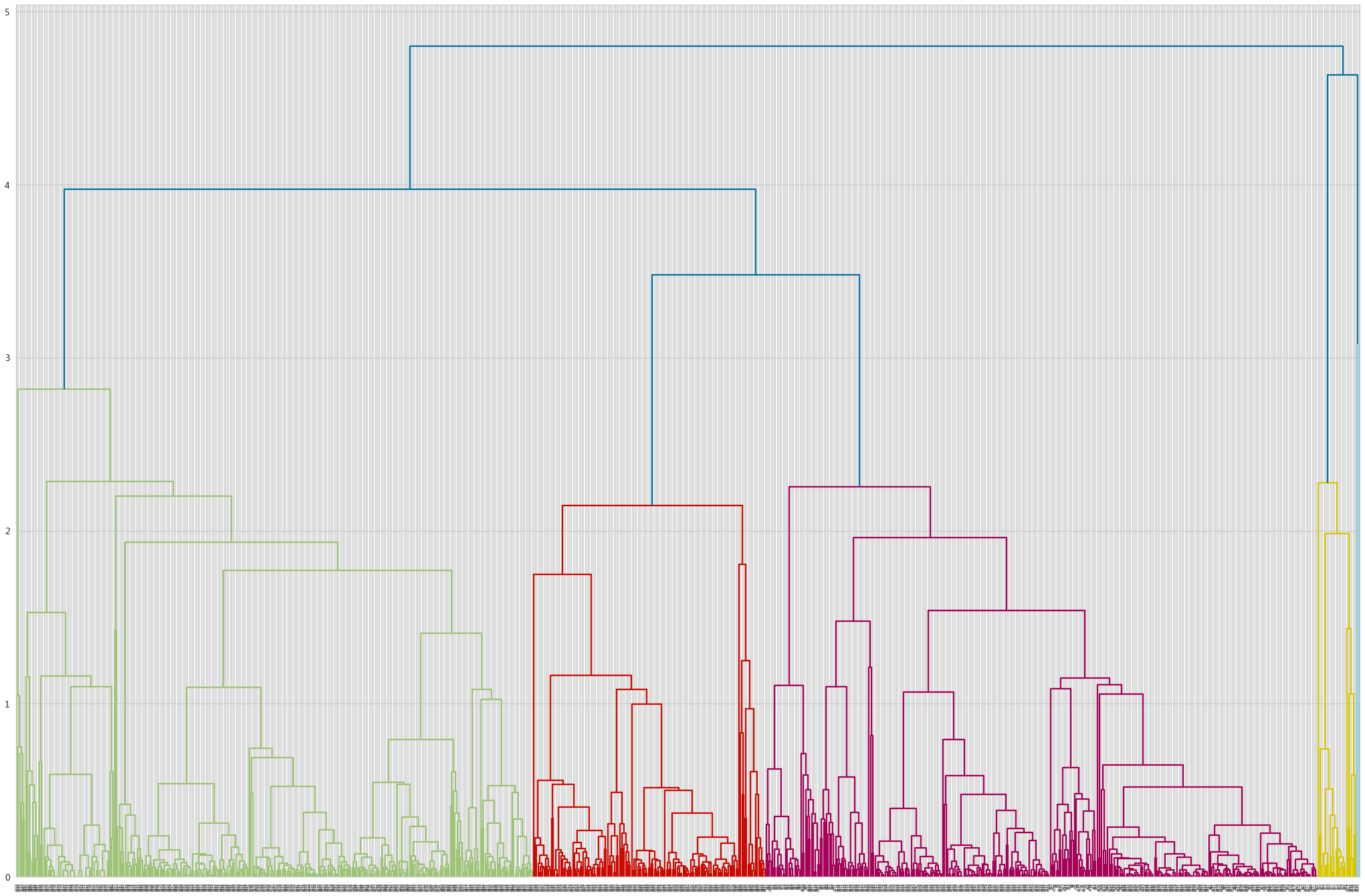
建立指定簇个数的凝聚层次模型
adHierarchy = AgglomerativeClustering(n_clusters=5,linkage='average')
adHierarchyClusters = adHierarchy.fit_predict(adXScale)检验聚类效果
silhouette_score(adXScale,adHierarchyClusters)silhouette_plot(adHierarchyClusters,adXScale)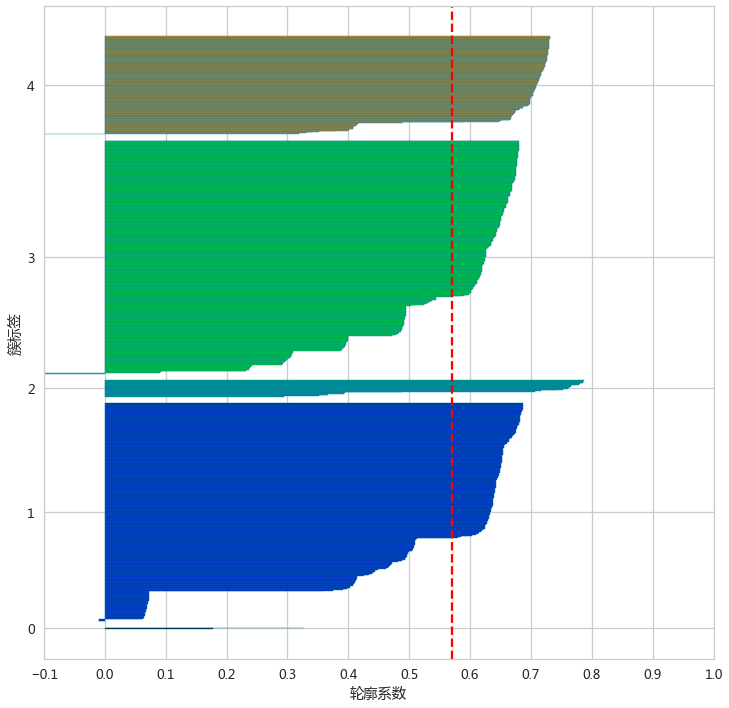
基于密度的聚类
-
确定eps(半径)和minpts(包含的样本点阈值)
nbrs = NearestNeighbors(n_neighbors=13).fit(adXScale) # 有12个属性,所以n_neighbors设置维13 distances, indices = nbrs.kneighbors(adXScale) distances

distances = np.sort(distances[:,-1], axis=0)
knee = KneeLocator(range(len(distances)),distances,S=1,curve='convex',
direction='increasing',online=True) # online=True会遍历每个x,找到最优的拐点
knee.plot_knee()
knearest[knee.elbow]建立DBSCAN模型并预测簇
adDB = DBSCAN(eps=0.413,min_samples=13,metric='euclidean',n_jobs=-1)
adLabels = adDB.fit_predict(adXScale)评估聚类效果
silhouette_score(X=adXScale,labels=adLabels)silhouette_plot(adLabels,adXScale)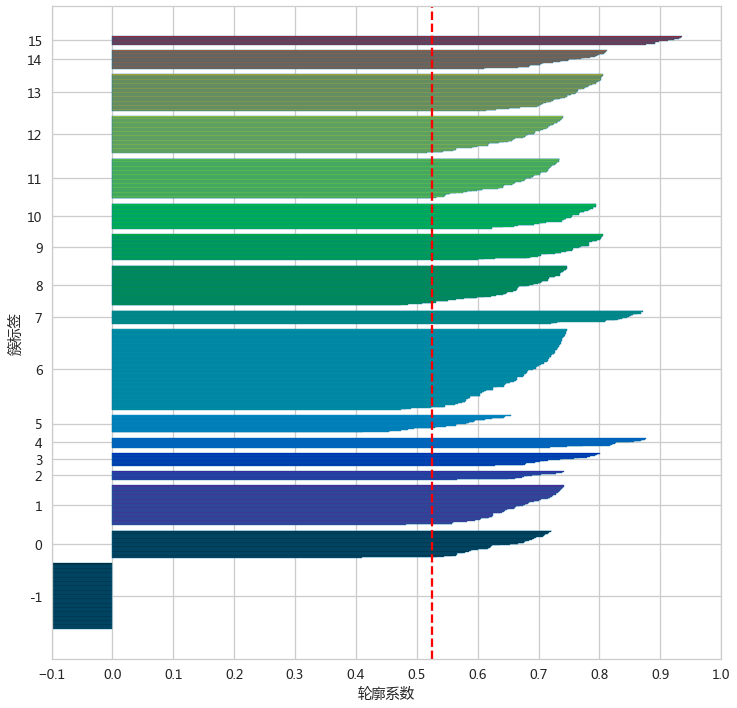
去掉噪声点,重新评估聚类效果
adXSel = adXScale.loc[adLabels>=0,:]
adLabelSel = adLabels[adLabels>=0]
silhouette_score(X=adXSel,labels=adLabelSel)silhouette_plot(adLabelSel,adXSel)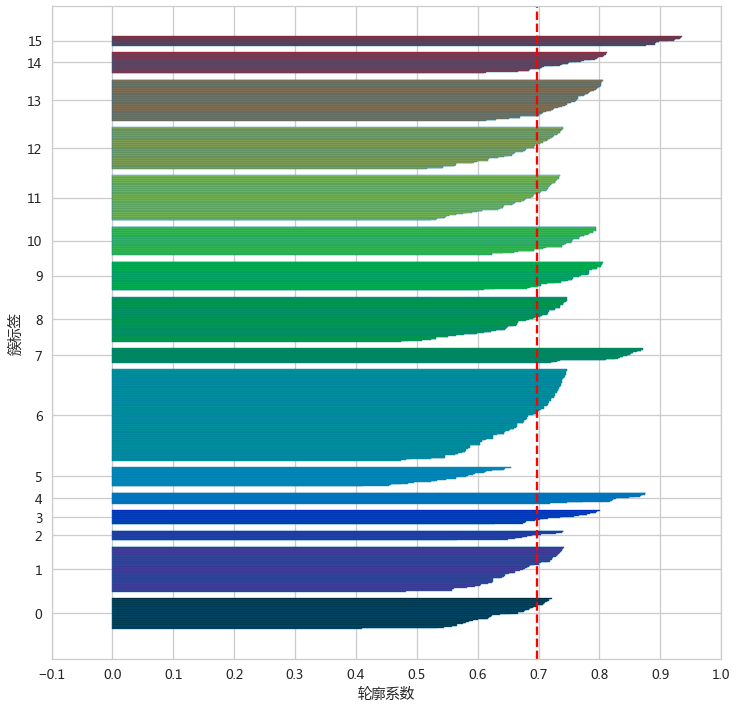
簇特征分析
adDf = adRaw.copy()
adDf.set_index('渠道代号',inplace=True)- 选用K均值聚类得到的4簇
将簇标签增加到原数据集上
adDf['cluster'] = adClusters
adDf.head()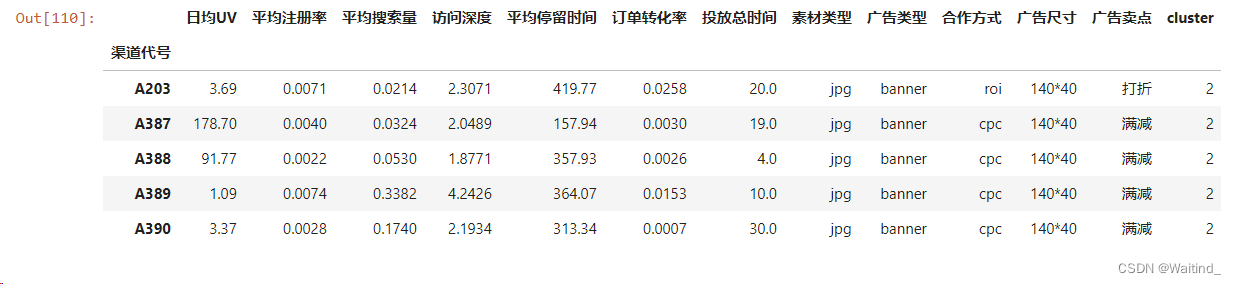
按簇标签分组
adGps = adDf.groupby(by='cluster')
resLst = []
for gp in adGps:
realCol = gp[1].iloc[:,:7].describe() # 得到数值型属性的描述性统计
typeCol = gp[1].iloc[:,-6:-1].describe(include='all') # 得到标称型属性的描述性统计
combCol = pd.concat([realCol.loc['mean',:],typeCol.loc['top',:]])
# 取数值型属性的均值,与标称型属性的频繁类别,并合并为新列
resLst.append(pd.concat([pd.Series(realCol.loc['count','日均UV'],
index=['样本数量']),combCol])) # 把合并后的新列追加到列表中
pd.concat(resLst,axis=1) # 把存有4个簇各个属性特征的series合并成一个dataframe