TextRNN文本分类
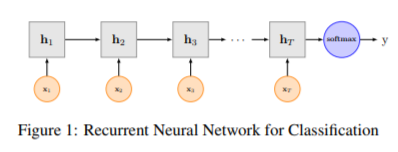
- RNN是在自然语言处理领域非常标配的一个网络,在序列标注/命名体识别/seq2seq模型等很多场景都有应用,Recurrent Neural Network for Text Classification with Multi-Task Learning文中介绍了RNN用于分类问题的设计,下图LSTM用于网络结构原理示意图,最后一步的隐层代表着对整个句子的编码,直接接全连接层softmax输出。
数据预处理
使用torchtext库来进行文本处理,包括以下几个部分: - 分词:torchtext使用jieba分词器作为tokenizer
- 去停用词:加载去停用词表,并在data.Field中设置 text = data.Field(sequential=True, lower=True, tokenize=tokenizer, stop_words=stop_words)
- 文本长度padding:如果需要设置文本的长度,则在data.Field中设置fix_length,否则torchtext自动将文本长度处理为最大样本长度
- 词向量转换:torchtext能自动建立word2id和id2word两个索引,并将index转换为对应词向量,如果要加载预训练词向量,在build_vocab中设置即可。
import jieba
from torchtext import data
import re
from torchtext.vocab import Vectors
def tokenizer(text): # create a tokenizer function
regex = re.compile(r'[^\u4e00-\u9fa5aA-Za-z0-9]')
text = regex.sub(' ', text)
return [word for word in jieba.cut(text) if word.strip()]
# 去停用词
def get_stop_words():
file_object = open('data/stopwords.txt')
stop_words = []
for line in file_object.readlines():
line = line[:-1]
line = line.strip()
stop_words.append(line)
return stop_words
def load_data(args):
print('加载数据中...')
stop_words = get_stop_words() # 加载停用词表
'''
如果需要设置文本的长度,则设置fix_length,否则torchtext自动将文本长度处理为最大样本长度
text = data.Field(sequential=True, tokenize=tokenizer, fix_length=args.max_len, stop_words=stop_words)
'''
text = data.Field(sequential=True, lower=True, tokenize=tokenizer, stop_words=stop_words)
label = data.Field(sequential=False)
text.tokenize = tokenizer
train, val = data.TabularDataset.splits(
path='data/',
skip_header=True,
train='train.tsv',
validation='validation.tsv',
format='tsv',
fields=[('index', None), ('label', label), ('text', text)],
)
if args.static:
text.build_vocab(train, val, vectors=Vectors(name="data/eco_article.vector")) # 此处改为你自己的词向量
args.embedding_dim = text.vocab.vectors.size()[-1]
args.vectors = text.vocab.vectors
else: text.build_vocab(train, val)
label.build_vocab(train, val)
train_iter, val_iter = data.Iterator.splits(
(train, val),
sort_key=lambda x: len(x.text),
batch_sizes=(args.batch_size, len(val)), # 训练集设置batch_size,验证集整个集合用于测试
device=-1
)
args.vocab_size = len(text.vocab)
args.label_num = len(label.vocab)
return train_iter, val_iter
训练
- 如果要使用预训练词向量,则data文件夹下要存放你自己的词向量
- 随机初始化Embedding进行训练
python train.py
- 随机初始化Embedding并设置是否为双向LSTM以及stack的层数
python train.py -bidirectional=True -layer-num=2
- 使用预训练词向量进行训练(词向量静态,不可调)
python train.py -static=true
- 微调预训练词向量进行训练(词向量动态,可调)
python train.py -static=true -fine-tune=true
模型代码:
import torch
import torch.nn as nn
# 循环神经网络 (many-to-one)
class TextRNN(nn.Module):
def __init__(self, args):
super(TextRNN, self).__init__()
embedding_dim = args.embedding_dim
label_num = args.label_num
vocab_size = args.vocab_size
self.hidden_size = args.hidden_size
self.layer_num = args.layer_num
self.bidirectional = args.bidirectional
self.embedding = nn.Embedding(vocab_size, embedding_dim)
if args.static: # 如果使用预训练词向量,则提前加载,当不需要微调时设置freeze为True
self.embedding = self.embedding.from_pretrained(args.vectors, freeze=not args.fine_tune)
self.lstm = nn.LSTM(embedding_dim, # x的特征维度,即embedding_dim
self.hidden_size,# 隐藏层单元数
self.layer_num,# 层数
batch_first=True,# 第一个维度设为 batch, 即:(batch_size, seq_length, embedding_dim)
bidirectional=self.bidirectional) # 是否用双向
self.fc = nn.Linear(self.hidden_size * 2, label_num) if self.bidirectional else nn.Linear(self.hidden_size, label_num)
def forward(self, x):
# 输入x的维度为(batch_size, max_len), max_len可以通过torchtext设置或自动获取为训练样本的最大长度
x = self.embedding(x) # 经过embedding,x的维度为(batch_size, time_step, input_size=embedding_dim)
# 隐层初始化
# h0维度为(num_layers*direction_num, batch_size, hidden_size)
# c0维度为(num_layers*direction_num, batch_size, hidden_size)
h0 = torch.zeros(self.layer_num * 2, x.size(0), self.hidden_size) if self.bidirectional else torch.zeros(self.layer_num, x.size(0), self.hidden_size)
c0 = torch.zeros(self.layer_num * 2, x.size(0), self.hidden_size) if self.bidirectional else torch.zeros(self.layer_num, x.size(0), self.hidden_size)
# LSTM前向传播,此时out维度为(batch_size, seq_length, hidden_size*direction_num)
# hn,cn表示最后一个状态?维度与h0和c0一样
out, (hn, cn) = self.lstm(x, (h0, c0))
# 我们只需要最后一步的输出,即(batch_size, -1, output_size)
out = self.fc(out[:, -1, :])
return out
训练代码:
import argparse
import os
import sys
import torch
import torch.nn.functional as F
import data_processor
from model import TextRNN
parser = argparse.ArgumentParser(description='TextRNN text classifier')
parser.add_argument('-lr', type=float, default=0.01, help='学习率')
parser.add_argument('-batch-size', type=int, default=128)
parser.add_argument('-epoch', type=int, default=20)
parser.add_argument('-embedding-dim', type=int, default=128, help='词向量的维度')
parser.add_argument('-hidden_size', type=int, default=64, help='lstm中神经单元数')
parser.add_argument('-layer-num', type=int, default=1, help='lstm stack的层数')
parser.add_argument('-label-num', type=int, default=2, help='标签个数')
parser.add_argument('-bidirectional', type=bool, default=False, help='是否使用双向lstm')
parser.add_argument('-static', type=bool, default=False, help='是否使用预训练词向量')
parser.add_argument('-fine-tune', type=bool, default=True, help='预训练词向量是否要微调')
parser.add_argument('-cuda', type=bool, default=False)
parser.add_argument('-log-interval', type=int, default=1, help='经过多少iteration记录一次训练状态')
parser.add_argument('-test-interval', type=int, default=100, help='经过多少iteration对验证集进行测试')
parser.add_argument('-early-stopping', type=int, default=1000, help='早停时迭代的次数')
parser.add_argument('-save-best', type=bool, default=True, help='当得到更好的准确度是否要保存')
parser.add_argument('-save-dir', type=str, default='model_dir', help='存储训练模型位置')
args = parser.parse_args()
def train(args):
train_iter, dev_iter = data_processor.load_data(args) # 将数据分为训练集和验证集
print('加载数据完成')
model = TextRNN(args)
if args.cuda: model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
steps = 0
best_acc = 0
last_step = 0
model.train()
for epoch in range(1, args.epoch + 1):
for batch in train_iter:
feature, target = batch.text, batch.label
# t_()函数表示将(max_len, batch_size)转置为(batch_size, max_len)
feature.data.t_(), target.data.sub_(1) # target减去1
if args.cuda:
feature, target = feature.cuda(), target.cuda()
optimizer.zero_grad()
logits = model(feature)
loss = F.cross_entropy(logits, target)
loss.backward()
optimizer.step()
steps += 1
if steps % args.log_interval == 0:
# torch.max(logits, 1)函数:返回每一行中最大值的那个元素,且返回其索引(返回最大元素在这一行的列索引)
corrects = (torch.max(logits, 1)[1] == target).sum()
train_acc = 100.0 * corrects / batch.batch_size
sys.stdout.write(
'\rBatch[{}] - loss: {:.6f} acc: {:.4f}%({}/{})'.format(steps,
loss.item(),
train_acc,
corrects,
batch.batch_size))
if steps % args.test_interval == 0:
dev_acc = eval(dev_iter, model, args)
if dev_acc > best_acc:
best_acc = dev_acc
last_step = steps
if args.save_best:
print('Saving best model, acc: {:.4f}%\n'.format(best_acc))
save(model, args.save_dir, 'best', steps)
else:
if steps - last_step >= args.early_stopping:
print('\nearly stop by {} steps, acc: {:.4f}%'.format(args.early_stopping, best_acc))
raise KeyboardInterrupt
'''
对验证集进行测试
'''
def eval(data_iter, model, args):
corrects, avg_loss = 0, 0
for batch in data_iter:
feature, target = batch.text, batch.label
feature.data.t_(), target.data.sub_(1)
if args.cuda:
feature, target = feature.cuda(), target.cuda()
logits = model(feature)
loss = F.cross_entropy(logits, target)
avg_loss += loss.item()
corrects += (torch.max(logits, 1)
[1].view(target.size()) == target).sum()
size = len(data_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects / size
print('\nEvaluation - loss: {:.6f} acc: {:.4f}%({}/{}) \n'.format(avg_loss,
accuracy,
corrects,
size))
return accuracy
def save(model, save_dir, save_prefix, steps):
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
save_prefix = os.path.join(save_dir, save_prefix)
save_path = '{}_steps_{}.pt'.format(save_prefix, steps)
torch.save(model.state_dict(), save_path)
train(args)
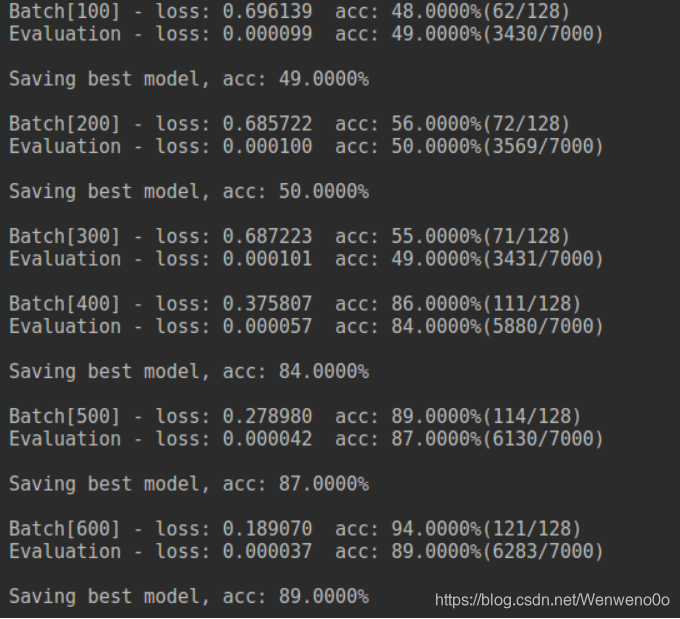
结果:
使用单向LSTM,可以看到,前400次迭代loss几乎没有下降,接着开始快速下降,最后验证集的准确率能到91%左右(经过调参可以更高)
数据获取方式:https://download.csdn.net/download/wenweno0o/11206041