Tesseract介绍和Python的搭配使用
今天之所以写这篇文章,算是对pyautogui工具使用的补充,pyautogui只能通过图片像素来判断图片是否存在,如果我们想要自动化的识别图片并将它转换为文字呢?我们应该怎么做?此时tesseract可以帮助我们解决这个问题。下面我就来介绍它的环境搭建和安装方式。
一、Tesseract介绍、下载指南
1、了解Tesseract工具
Tesseract是一个 由HP实验室开发 由Google维护的开源的光学字符识别(OCR)引擎,可以在 Apache 2.0 许可下获得。它可以直接使用,或者(对于程序员)使用 API 从图像中提取输入,包括手写的或打印的文本。与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练语言,提高图像转换文本的能力。
2、下载地址
tesseract官方下载地址
tesseract语言包下载
注意在语言包下载语言包时页面会崩溃,大家想用中文包的,可以进入我下面的网盘链接,想要下载其他语言包的同学,建议将链接复制到迅雷进行下载,下载速度还挺快的。
3、请注意!!!
为了更好的体验,建议下载稳定版,即如下版本,
64位电脑下载:
32位电脑下载:
由于官方的网站速度比较慢,在此贴上我的百度网盘链接,包含中文语言包、tesseract软件、jTessBoxEditor训练软件以及使用该软件的教程指导(jdk包)。链接如下:
百度网盘提取码:rhp6


二 、环境搭建
好了,相信聪明的你们已经下载好了吧,下面我们开始进行安装了。
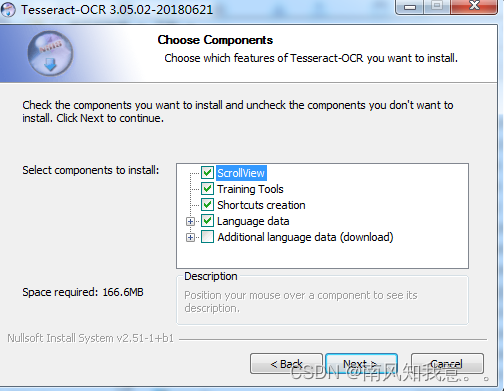
2.1 版本3.05安装
3.05版本:这个注意不要勾选Additional language,勾选了无法下载会报错,建议在官网找语言包链接,通过迅雷下载。后面都是无脑操作,选择好路径就行。
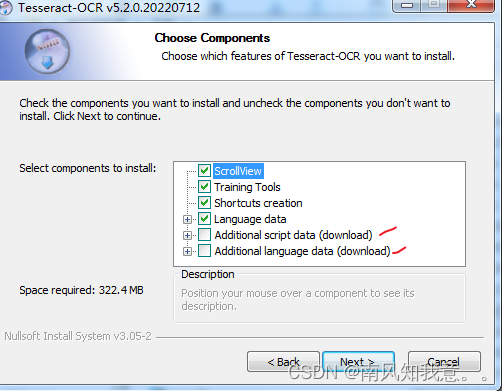
2.2 最新版本安装
最新版5.2.0版本:这个多了个组件,里面可以勾选你想要的组件(建议下载),在这里都选择中文。
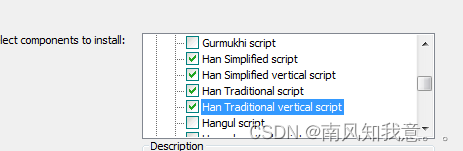
Additional script勾选中文包如下:
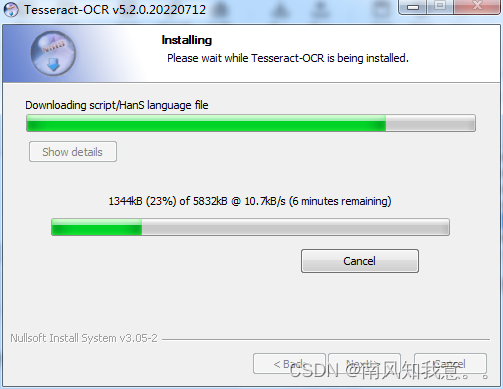
安装,这时会下载组件,就是速度很慢。
Additional language:在这里我选择不勾选,下的很慢。语言包也可以到网站获取链接通过迅雷下载。
2.3 环境搭建
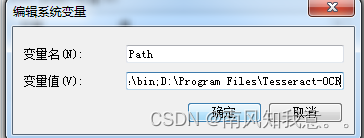
接下来我们开始进行环境变量配置①在path中添加你的安装路径:D:\Program Files\Tesseract-OCR
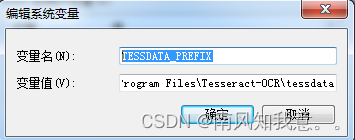
②:变量名:TESSDATA_PREFIX,变量值:D:\Program Files\Tesseract-OCR\tessdata,这两个路径都需要配置到环境变量里面去。如下:
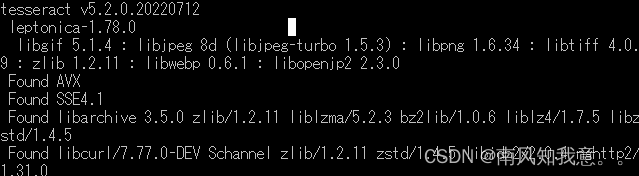
分别保存,打开cmd验证,输入tesseract -v验证,出现如下说明你配置好了
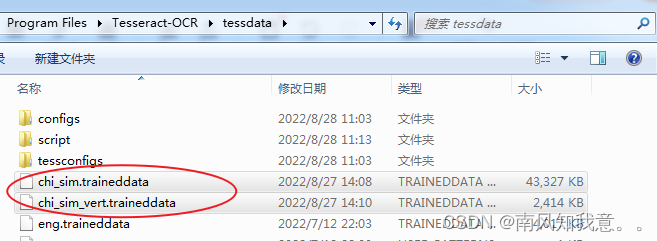
语言包配置:将下载好的语言包放入:D:\Program Files\Tesseract-OCR\tessdata
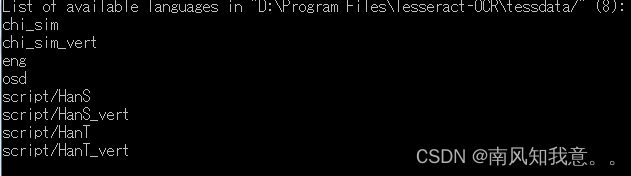
验证方式,在cmd输入tesseract --list-langs 运行如下说明成功:
到这里基本上配置好了。
2.4 举个栗子
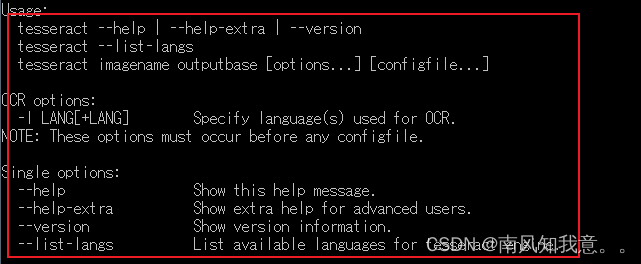
在cmd中输入:**tesseract/? 可以查看帮助,在这里我们使用命令来进行简单的图片识别并提取文字: tesseract imagename outputbase [options…] [configfile…]
即:tesseract 输入文件名 输出文件 配置选项
在这里我们使用如图的图片eng.PNG来验证:
进入图片的路径,在路径栏输入cmd, 或者自己先进入cmd慢慢cd过去;输入命令:
tesseract eng.PNG eng -l eng,其中(eng是语言,可以换成其他语言)回车后在路径会生成一个txt文件,打开显示:
“There are two reasons why
people don’t talk about things;
either it doesn’t mean anything
to them, or it means everything.”
到这里则所有验证通过,恭喜你一次性到位,安装成功!


三、Python中的环境搭建
3.1 安装pytesseract
由于这个软件可以和python结合起来使用,因此这里我们需要在cmd中安装包:
①python版本:3.7.9
②这里我用的是pycharm工作台,不会安装的自己百度
③安装命令:pip install pytesseract
3.2 修改配置文件
进入python安装包的路径:D:\Program Files\Python37\Lib\site-packages\pytesseract
编辑文件:pytesseract.py
修改tesseract_cmd = ‘D:\Program Files\Tesseract-OCR/tesseract.exe’,修改后在python中运行就不会报错了。
3.3 在python中验证
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @time :2022/8/28 12:11
# @Author :root
# @FileName :example
import pytesseract
img_path = "../chi.PNG"
result = pytesseract.image_to_string(image=img_path,lang="chi_sim",config="--psm 1") #路径;语言;配置
print(result)
识别的图片为:
识别效果,对于汉字还是有点问题,但是对于英文识别度很高,所以我们对于识别度不高的可以自己训练,哈哈哈。

tesseract 的 安 英 使 用 及 配 置 问 题 解 火
一 、 安 装 tesseract
二 、 配 置 环 境 变 量 “
三 、cmd “ 方 式 中 出 现 的 问 题 及 解 决 方 法
四 、 pycharm 方 式 中 出 现 的 闰 题 及 解 决 办 法
五 、 验 证 结 果
四、持续学习
今天的分享就到这里了,我后面还会分享opencv处理图片的学习。后面我也会讲tesseract在python中的基本用法,如何生成自己的验证码、二值化,模糊处理,有兴趣的同学们点个赞吧!!!