(本文基本是对Jasen 的《Machine Learning for Algorithmic Trading》第二版的第21章进行翻译、改写和复现,并用于我们的实际情况)
1. 准备阶段
配置介绍
在Anaconda下安装TensorFlow以及在Jupyter Notebook中引用的准备,可以参考以下文档
https://www.tensorflow.org/tutorials/quickstart/beginner
https://blog.csdn.net/qq_37486501/article/details/104579663(sklearn 的安装)
https://zhuanlan.zhihu.com/p/92370075(在pycharm中配置tensorflow)
https://blog.csdn.net/zxpcz/article/details/88864478
https://blog.csdn.net/weixin_41640583/article/details/86534358?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-0&spm=1001.2101.3001.4242
https://www.jianshu.com/p/52c6c9afe33e
https://zhuanlan.zhihu.com/p/84568790
https://blog.csdn.net/hitzijiyingcai/article/details/83342905
GAN介绍
GANs由Goodfellow等人在2014年提出。被誉为“过去十年中AI领域最令人振奋的成果”。一个GAN模型需要训练两个神经网络丝——生成器和判别器。生成器的作用在于在给定样本的情况下生成新的样本,使判别器不能分辨这些新样本和给定样本。因此GAN总的来说是一个生成模型,它能够生成合成样本(synthetic samples),这些合成样本能够体现真实数据背后的目标分布(这个目标分布就是真实数据背后的本质)。由于这些样本是人工生成的,因此不需要从目标分布中抽取,相应的,抽样的成本问题也就得到了解决。
本文主要目的在于探究GAN在生成时间序列数据上的作用,特别是金融时间序列数据。
2. 利用GAN生成合成数据(synthetic data)
如前所述,GAN能够相当精确地模仿一系列输入数据背后的分布。由于在监督学习中,标记数据(labeled data)可能相当匮乏,或者获取标记数据的成本可能很高,因此如果能够利用GAN去生成类标记数据,那对于这些监督学习算法无疑是一个巨大的福音。
对生成模型和判别模型的考察
判别模型,就是在给定输入数据X的情况下,学习如何对输出 y ⃗ \displaystyle\vec{y} y中的元素进行分辨,换句话说,就是学习给定输入数据下,输出y的条件分布 p(y|X)。
生成模型,就是学习输入数据和输出的联合分布p(y,X)。
生成模型通常用于解决预测问题。
GANs由于能够在给定简单输入数据(例如随机数)的情况下,生成复杂的输出(如图片等),因此具有生成模型的性质。GANs之所以具有这样的能力,是因为它能够对所有可能的输出的分布建模。这个概率分布的维数可能是很大的,比如对一张图片而言,一个像素就是一个维度,或者对一个文档而言,一个词语(token)就是一个维度。当然在这里,我们注重时间序列数据,对于时间序列数据而言,一个时间戳上的值,就是一个维度。这种对于输出的分布的建模,是AI迈向更加通用化的一大进步。
对抗训练——一种零和游戏
GANs的主要创新点,在于它的思想内核是新的一种学习输出数据分布的想法——利用两个神经网络(生成器和判别器)的对抗。
在这里,生成器的目标在于将随机噪声转换成一系列合成数据,这些合成数据是某一类真实数据(如真实的股票价格时间序列)的人工复制品。而判别器的作用则是竭力区别这些人工复制品和真实数据。这两个神经网络都必须竭力达到自己的性能极限,但我们搞GANs,最终是希望生成器能够战胜判别器。
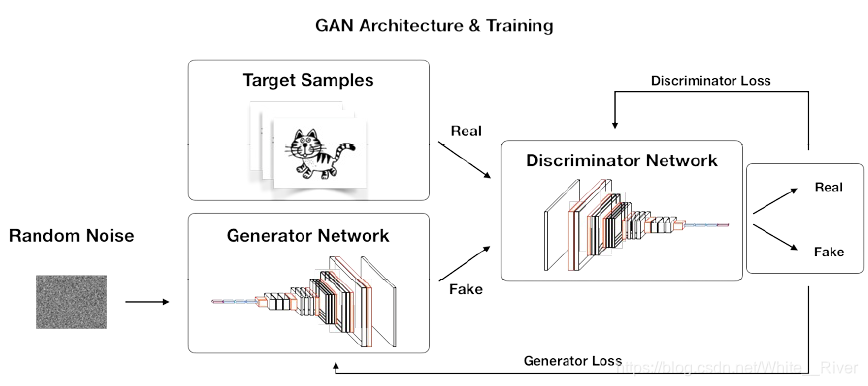
上图是对GAN利用对抗训练生成图片的原理的形象阐述。
这里假定生成器采用反深度卷积神经网络(reversed deep CNN)结构(如同卷积自编码器的解码器部分),生成器的输入是一张图片,此图片每个像素上的值都是随机的。这个随机图片经过反卷积后输出一张合成图片(a fake and synthetic image),这张合成图片会作为判别器的输入。判别器采用的是和生成器网络互为镜像的CNN网络结构,它同时也接收真实的样本图片(图片就是目标分布的样本)作为输入。判别器的输出是一个概率的概念——这张图片来自真实数据源的概率。
两个网络都采用反向传播网络的损失函数梯度作为学习参数的方法。
GAN家族的蓬勃发展
GAN的想法引人注目,引发了大量的研究,这些研究又反过来改进了原始的GAN架构,使得新的GAN能够适应不同的领域和任务。
用于表示学习(representation learning)的深度卷积GAN
- 深度卷积GAN(DCGANs)。卷积神经网路(CNN)在关于类网格数据(grid-like data)的监督学习的应用中大获成功,这促进了对深度卷积GAN的研究。深度卷积GAN架构引领了GANs在无监督学习中的应用,这种架构是基于对抗训练发展出一个特征提取器。这种架构易于训练并生成高质量的图片,在今天,它也是作为各种GAN的baseline。DCGANs采用均匀分布随机数作为输入,并输出分辨率为64×64的彩色图片。输入维度变化会导致输出图片的变化。这种架构由标准CNN组件组成,包括解卷积层(就是把卷积层反过来)或者是全连接层。
用于图片到图片转换的条件GANs
- 条件GANs(cGANs)。这种结构将额外的标记信息(additional label information)引入了训练过程,这种做法让输入质量更高,更加可控。
用于图片和时间序列数据的GAN
伴随着大量对于原始GAN架构的拓展和修正,大量关于图片,还有序列数据(sequential data,like speech,music etc.)的应用也异军突起。关于图片的应用尤其多,从图片的混合和超分辨率到生成视频和人类动作识别,许多方面都能见到GAN。同时GANs也被用于提升监督学习算法的表现。
循环条件GANs(recurrent conditional GANs)和合成的时间序列
Recurrent GANs(RGANs)和Recurrent conditional GANs(RCGANs)这两种模型架构用于生成“真实的”、实值、多变量时间序列。这种方法的提出最初来自医疗领域,但它对于金融市场的价值不可谓不珍贵。
RGANs是基于循环神经网络(recurrent neural networks,RNNs)构建其生成器和判别器的。RCGANs则是利用cGANs的想法,在RGANs的基础上引入额外信息。
这种架构在生成相关数据上取得巨大成功,而且,架构的作者通过将生成的数据和真实数据分别对同一模型训练进行对比,发现合成数据的训练表现相较于真实数据的训练表现仅仅存在非常小的劣势(only minor degradation)。因此,在本文中我们就将利用这个方法生成金融市场数据。
3. 代码——深度卷积对抗生成网络
初始阶段
import warnings
warnings.filterwarnings('ignore')
from pathlib import Path #导入路径处理库
######https://blog.csdn.net/itanders/article/details/88754606
##### 关于path的解答
import imageio # 导入图片输入输出库
import matplotlib.pyplot as plt
## python 进度条
from tqdm import tqdm
from time import time
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
# 数据集
from tensorflow.keras.layers import (Dense, Reshape, Flatten, Dropout,
BatchNormalization, LeakyReLU,
Conv2D, Conv2DTranspose)
# 循序数据函数
from tensorflow.keras.models import Sequential
# 交叉熵损失函数
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.optimizers import Adam
# 用于可视化模型的函数
from tensorflow.keras.utils import plot_model
from IPython import display
gpu_devices = tf.config.experimental.list_physical_devices('GPU')
if gpu_devices:
print('Using GPU')
tf.config.experimental.set_memory_growth(gpu_devices[0], True)
else:
print('Using CPU')
dcgan_path = Path('dcgan')
## dcgan(深度卷积对抗神经网络的路径)
img_path = dcgan_path / 'synthetic_images'
## 图片路径
if not img_path.exists():
img_path.mkdir(parents=True)
样本图片保存器
def generate_and_save_images(model, epoch, test_input):
# Training set to false so that every layer runs in inference mode
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(5, 5.2))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
fig.suptitle(f'Epoch {epoch:03d}', fontsize=14)
fig.tight_layout()
fig.subplots_adjust(top=.93)
fig.savefig(img_path / f'epoch_{epoch:03d}.png', dpi=300)
plt.show()
载入数据和准备数据
获取训练用的图片
# use only train images
# Loads the Fashion-MNIST dataset.
#This is a dataset of 60,000 28x28 grayscale images of 10 fashion categories,
#along with a test set of 10,000 images. This dataset can be used as
#a drop-in replacement for MNIST. The class labels are:
(train_images, train_labels), (_, _) = fashion_mnist.load_data()
##提取照片的维度
# get dimensionality
n_images = train_images.shape[0]
h = w = 28
#将输入转化为四维的格式
train_images = (train_images
.reshape(n_images, h, w, 1)
.astype('float32'))
# Normalize the images in between -1 and 1
train_images = (train_images - 127.5) / 127.5
##创建tf.data.dataset
BUFFER_SIZE = n_images
BATCH_SIZE = 256
train_set = (tf.data.Dataset
.from_tensor_slices(train_images)
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE))
创建DCGAN架构
##编写生成器的代码
##在这里生成器和判别器都是用CNN架构搭建,只是层数比较少。 生成器接受100个一维的随机数,并输出一个28×28分辨率的图片。
def build_generator():
return Sequential([Dense(7 * 7 * 256,
use_bias=False,
#输入为100个一维的随机数
input_shape=(100,),
name='IN'),
BatchNormalization(name='BN1'),
LeakyReLU(name='RELU1'),
Reshape((7, 7, 256), name='SHAPE1'),
Conv2DTranspose(128, (5, 5),
strides=(1, 1),
padding='same',
use_bias=False,
name='CONV1'),
BatchNormalization(name='BN2'),
LeakyReLU(name='RELU2'),
Conv2DTranspose(64, (5, 5),
strides=(2, 2),
padding='same', use_bias=False,
name='CONV2'),
BatchNormalization(name='BN3'),
LeakyReLU(name='RELU3'),
Conv2DTranspose(1, (5, 5),
strides=(2, 2),
padding='same',
use_bias=False,
activation='tanh',
name='CONV3')],
name='Generator')
generator = build_generator()
#判别器
def build_discriminator():
return Sequential([Conv2D(64, (5, 5),
strides=(2, 2),
padding='same',
input_shape=[28, 28, 1],
name='CONV1'),
LeakyReLU(name='RELU1'),
Dropout(0.3, name='DO1'),
Conv2D(128, (5, 5),
strides=(2, 2),
padding='same',
name='CONV2'),
LeakyReLU(name='RELU2'),
Dropout(0.3, name='DO2'),
Flatten(name='FLAT'),
Dense(1, name='OUT')],
name='Discriminator')
discriminator = build_discriminator()
开始对抗训练
生成器判别器构建好,接下来就是设计和执行对抗训练过程。
设计对抗训练过程,需要注意以下
- 必须引入能够反映两个网络交互作用的loss funcion
- 要有一个执行反向传播算法的训练步骤
- 要有一个训练循环(loop)去重复训练步骤以让GAN达到我们所需要的效果
定义生成器和判别器的loss function
生成器的loss反映的是判别器面对假图片输入时的决策能力,如果生成器的loss很小,说明判别器难以分辨真假,侧面说明生成器厉害
## 用交叉熵函数作为损失函数
cross_entropy = BinaryCrossentropy(from_logits=True)
#Creates a tensor of all ones that has the same shape as the input.
# tf.ones_like 函数接受一个tensor作为输入
#并且输出一个shape和输出相同的全一Tensor
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
def discriminator_loss(true_output, fake_output):
true_loss = cross_entropy(tf.ones_like(true_output), true_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
return true_loss + fake_loss
## 使用Adam算法的优化器
## 学习率
gen_optimizer = Adam(1e-1)
dis_optimizer = Adam(1e-1)
## 检查点
#tf.train.Checkpoint函数的作用
#Groups trackable objects, saving and restoring them.
checkpoints_dir = dcgan_path / 'training_chpk'
##检查点的前缀prefix
checkpoint_prefix = checkpoints_dir / 'ckpt'
checkpoint = tf.train.Checkpoint(gen_optimizer=gen_optimizer,
dis_optimizer=dis_optimizer,
generator=generator,
discriminator=discriminator)
训练参数
我们的训练始于对生成器输入随机种子(random seed),然后生成器生成一个图片。判别器则竭力分辨真图片和假图片。两个模型的权重则伴随着loss的梯度下降而更新,随着训练过程的进行,生成器会变得更厉害,能够生成更高质量的假图片,同时判别器也会提高自己的判别能力。
##batch
##深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
##第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新###梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量###开销大,计算速度慢,不支持在线学习,这称为Batch gradient ##descent,批梯度下降。
## 梯度下降的批次数
EPOCHS = 2
noise_dim = 100
# for gif generation
num_ex_to_gen = 16
seed = tf.random.normal([num_ex_to_gen, noise_dim])
核心-设计训练步骤(train step)
每个train-step都完成了一回合的随机梯度下降,一个train step 由五个部分组成
- 为每个模型提供最小批输入
- 在当前的权重中获得模型的输出
- 计算loss
- 计算梯度
- 将梯度应用于优化算法
@tf.function # 将训练过程转化为图执行模式,加快训练过程
def train_step(images):
# generate the random input for the generator
# 制造生成器的输入
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
# get the generator output
## 获取生成器的输出
generated_img = generator(noise, training=True)
# collect discriminator decisions regarding real and fake input
## 对判别器输入真假图片,然后获取输出
true_output = discriminator(images, training=True)
fake_output = discriminator(generated_img, training=True)
# 计算两个模型的loss
# compute the loss for each model
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(true_output, fake_output)
# compute the gradients for each loss with respect to the model variables
# 计算各自的loss对各自模型的变量的梯度
grad_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
grad_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
# 将计算好的梯度用于反向传播这一步骤
# apply the gradient to complete the backpropagation step
gen_optimizer.apply_gradients(zip(grad_generator, generator.trainable_variables))
dis_optimizer.apply_gradients(zip(grad_discriminator, discriminator.trainable_variables))
## 训练循环
def train(dataset, epochs, save_every=10):
for epoch in tqdm(range(epochs)):
start = time()
for img_batch in dataset:
train_step(img_batch)
# produce images for the GIF as we go
display.clear_output(wait=True)
generate_and_save_images(generator, epoch + 1, seed)
# Save the model every 10 EPOCHS
if (epoch + 1) % save_every == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
# Generator after final epoch
display.clear_output(wait=True)
generate_and_save_images(generator, epochs, seed)
train(train_set, EPOCHS)

结果
在这里,由于时间关系,我将训练的批梯度下降定义为2,而且把学习率弄得很大(原文为 1 0 − 4 10^{-4} 10−4,我弄成了0.1),即使如此,由于两个网络的待训练参数数目极大,仍然需要花不少时间。