目录
使用PyTorch设计卷积神经网络(CNN)来处理遥感图像Indian Pines数据集,以下是设计和实现这些网络的步骤:
1.2 将数据集转换为PyTorch张量,以便能够使用PyTorch框架进行处理。
使用PyTorch设计卷积神经网络(CNN)来处理遥感图像Indian Pines数据集,以下是设计和实现这些网络的步骤:
1.数据准备:
1.1 首先,需要加载Indian Pines数据集。
data = scipy.io.loadmat("D:/Indian_pines_corrected.mat")['indian_pines_corrected']
gt = scipy.io.loadmat("D:/Indian_pines_gt.mat")['indian_pines_gt'].ravel() # 确保标签是一个一维数组
因为数据集是一个MAT文件,所以使用scipy.io模块来读取它。
1.2 将数据集转换为PyTorch张量,以便能够使用PyTorch框架进行处理。
# 将NumPy数组转换为PyTorch张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)这段代码是在使用PyTorch库将NumPy数组转换为PyTorch张量(tensor),这是进行深度学习训练之前常见的步骤。
2.数据预处理:
2.1 根据需要对数据进行归一化或标准化。
# 数据预处理
num_bands = data.shape[2]
X = data.reshape(-1, num_bands)
# 归一化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)在机器学习和数据科学中,数据预处理是一个非常重要的步骤,它可以帮助提高模型的性能和准确性。首先我们要使用Python语言中的NumPy库进行数据预处理的常见操作。
在这段代码中,data 变量假定是一个多维数组,通常是一个三维数组,其中包含了图像数据或其他类型的多维数据。data.shape[2] 表示这个数组的第三个维度的大小,也就是波段数(例如在遥感图像中)。
X = data.reshape(-1, num_bands) 这行代码的作用是将原始的多维数组 data 重塑为一个二维数组 X。其中 -1 表示让NumPy自动计算这个维度的大小,以确保数组的元素总数保持不变。num_bands 是数组的第三个维度的大小,表示每个样本的特征数或波段数。
具体来说,如果 data 是一个形状为 (a, b, num_bands) 的数组,那么 reshape(-1, num_bands) 操作将把它转换为一个形状为 (a*b, num_bands) 的数组。这样,每一行代表一个样本,每一列代表一个特征。
归一化是数据预处理中的一个关键步骤,特别是当你的数据集包含不同量级的特征时。归一化可以帮助算法更有效地工作,因为它确保了所有特征对模型的影响是均衡的。
在这里的代码片段中,使用了 StandardScaler 来进行数据的归一化处理,这是 scikit-learn 库中的一个常用工具。
scaler = StandardScaler():创建一个 StandardScaler 对象。StandardScaler 是一个预处理器,用于将数据标准化(或归一化)到均值为0,标准差为1的标准正态分布。
X_scaled = scaler.fit_transform(X):对数据集 X 执行 fit_transform 方法。这个方法首先计算数据集 X 的均值和标准差(fit 阶段),然后使用这些统计量来转换数据,使其符合标准化的要求(transform 阶段)。结果 X_scaled 就是归一化后的数据集。
归一化后的数据具有以下特点:
每个特征的均值变为0。
每个特征的标准差变为1。
2.2 将数据集分割为训练集和测试集。
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, gt, test_size=0.2, random_state=42)
划分训练集和测试集是非常重要的,因为:
-
训练集用于训练模型,学习数据的特征和模式。
-
测试集用于评估模型的性能,确保模型没有过拟合,并且能够泛化到未见过的数据上。
X_train, X_test:表示划分后的训练特征集和测试特征集。
y_train, y_test:表示对应的训练目标集和测试目标集。这里的目标变量 gt 应该是一个数组,包含了你想要模型预测的值。
test_size=0.2:指定测试集占整个数据集的比例,这里是20%。这意味着80%的数据将用于训练,20%的数据将用于测试。
random_state=42:指定随机数生成器的种子,以确保每次运行代码时,数据的划分是一致的。这有助于实验的可重复性。
3.定义网络结构:
根据选择,设计一个一维卷积网络或全连接网络。对于一维卷积,可使用torch.nn.Conv1d,而对于全连接网络,可使用torch.nn.Linear。
# 为Conv1d增加通道维度
X_train_tensor = X_train_tensor.unsqueeze(1)
X_test_tensor = X_test_tensor.unsqueeze(1)
# 定义网络
class SpectralCNN(nn.Module):
def __init__(self, num_bands, num_classes):
super(SpectralCNN, self).__init__()
self.conv1 = nn.Conv1d(in_channels=1, out_channels=64, kernel_size=3, padding=1)
self.pool = nn.MaxPool1d(kernel_size=2)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
# 计算经过两次卷积和池化后的输出大小
# 卷积后,宽度保持不变;池化后,宽度减半
conv_output_size = num_bands
pool_output_size = int(np.ceil(conv_output_size / 2)) # 第一次池化后的大小
pool_output_size = int(np.ceil(pool_output_size / 2)) # 第二次池化后的大小
# 更新全连接层的输入大小
self.fc1 = nn.Linear(128 * pool_output_size, num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = x.view(x.size(0), -1) # 扁平化特征向量
x = self.fc1(x)
return x这段代码定义了一个使用PyTorch框架的卷积神经网络(CNN)类 SpectralCNN,它继承自 nn.Module。这个网络专门设计用于处理光谱数据,其中 num_bands 表示输入数据的波段数,num_classes 表示输出的类别数。下面是对这段代码的详细解释:
-
初始化方法 (
__init__):-
首先,它调用父类
nn.Module的初始化方法。
-
-
卷积层 (
self.conv1和self.conv2):-
self.conv1是第一个一维卷积层,具有1个输入通道(对应于波段数),64个输出通道,卷积核大小为3,填充为1。填充为1意味着在输入的两侧各添加一个零填充,以保持输出的宽度不变。 -
self.conv2是第二个一维卷积层,具有64个输入通道(第一个卷积层的输出通道数),128个输出通道,卷积核和填充与第一个卷积层相同。
-
-
池化层 (
self.pool):-
使用最大池化 (
MaxPool1d),池化窗口大小为2。这将减少特征图的宽度,但保持高度不变。
-
-
计算输出大小:
-
通过两次卷积和池化操作后,需要计算全连接层的输入大小。这里使用了
np.ceil函数来向上取整,以确保即使在池化后,输出大小也能正确计算。
-
-
全连接层 (
self.fc1):-
根据经过两次卷积和池化后的特征图大小,创建一个全连接层,将特征图展平后连接到
num_classes个输出节点。
-
4.定义损失函数和优化器:
4.1 选择一个适合分类任务的损失函数,例如交叉熵损失。
4.2 选择一个优化器,如Adam或SGD。
# 初始化模型
num_classes = len(np.unique(gt))
model = SpectralCNN(num_bands=X_train.shape[1], num_classes=num_classes)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)损失函数 (criterion):
这里使用的是 nn.CrossEntropyLoss(),这是一个常用于多分类问题的损失函数。它结合了 LogSoftmax 层和 NLLLoss(负对数似然损失),使得模型在训练时可以优化分类任务的性能。CrossEntropyLoss 会计算模型输出的对数概率和目标类别的负对数似然损失。
优化器 (optimizer):
这里使用的是 torch.optim.Adam 优化器,它是 Adam(自适应矩估计)算法的实现。Adam 优化器是一种流行的算法,因为它结合了动量(Momentum)和 RMSprop 的优点。在你的代码中,model.parameters() 指定了优化器需要更新的模型参数,lr=0.001 设置了学习率为0.001,这是每次参数更新时使用的步长。
5.训练网络:
使用训练数据来训练网络,并通过反向传播更新权重。
# 训练模型
num_epochs = 10000 # 设置训练轮数
# 开始训练模型
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')这段代码展示了一个基本的深度学习模型训练循环,这是一个迭代过程,模型在每个周期(epoch)上学习数据的特征。下面是对代码的解释:
-
训练循环:
for epoch in range(num_epochs):这个循环会执行指定次数的训练周期。num_epochs应该在代码的其他地方定义。 -
训练模式:
model.train()将模型设置为训练模式,这会启用如 Dropout 等特定于训练阶段的层。 -
梯度清零:
optimizer.zero_grad()清除之前的梯度,以防止它们在反向传播时累积。 -
前向传播:
outputs = model(X_train_tensor)执行模型的前向传播,计算给定输入的输出。 -
计算损失:
loss = criterion(outputs, y_train_tensor)计算模型输出和目标标签之间的损失。 -
反向传播:
loss.backward()计算损失相对于模型参数的梯度。 -
参数更新:
optimizer.step()更新模型的参数以减少损失。 -
打印损失:
print语句在每个周期结束时打印当前周期的损失值,这有助于监控训练过程。
6.评估网络:
在测试集上评估网络的性能。
# 测试模型
def evaluate_model(model, X_test_tensor, y_test_tensor):
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 禁用梯度计算
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs.data, 1)
total = y_test_tensor.size(0)
correct = (predicted == y_test_tensor).sum().item()
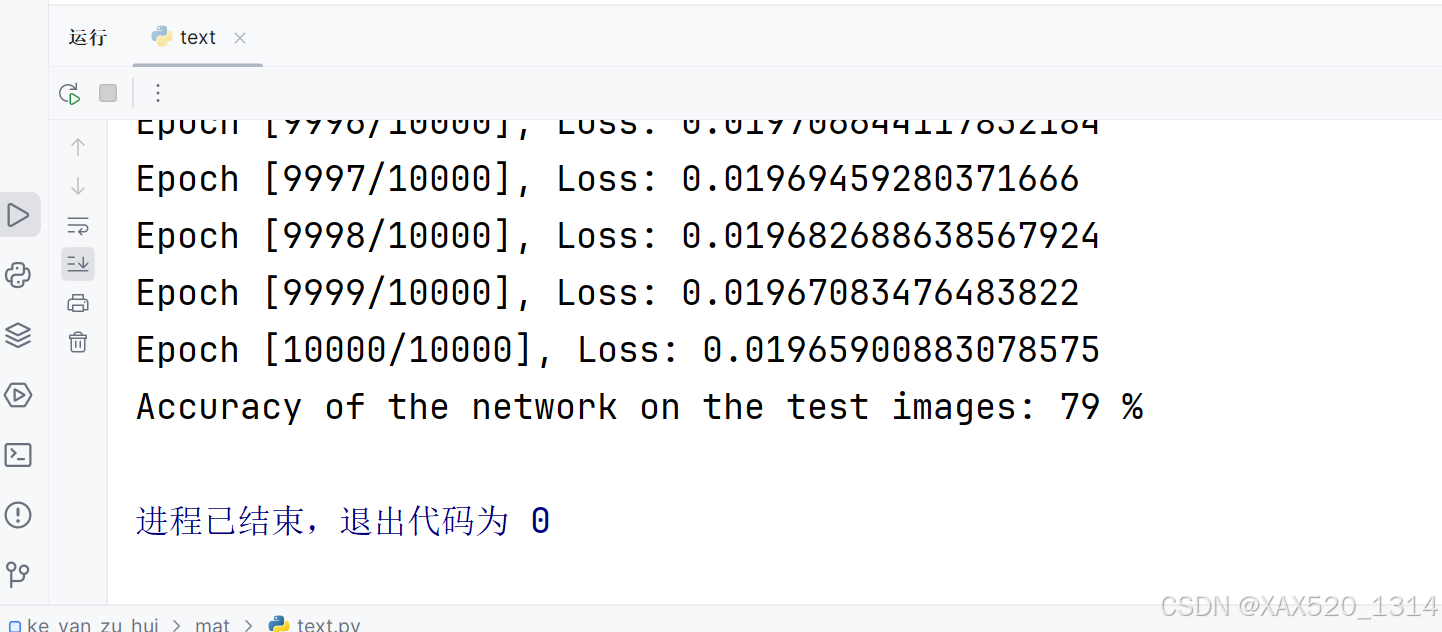
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))
# 在训练结束后评估模型
evaluate_model(model, X_test_tensor, y_test_tensor)这里定义的 evaluate_model 函数是一个用于评估模型性能的实用工具,特别是在分类任务中。下面是这段代码的详细解释:
-
设置评估模式:
-
model.eval()将模型设置为评估模式,这会禁用如 Dropout 等在训练时使用的特定层。
-
-
禁用梯度计算:
-
with torch.no_grad():上下文管理器禁用了梯度计算,这在评估阶段是有用的,因为它减少了内存消耗并加速了计算。
-
-
执行前向传播:
-
outputs = model(X_test_tensor)执行模型的前向传播,得到模型对测试数据的预测输出。
-
-
获取预测结果:
-
_, predicted = torch.max(outputs.data, 1)计算模型输出中概率最高的类别索引,即预测的类别。这里outputs.data是一个二维张量,第一维是批次中的样本,第二维是类别的概率。
-
-
计算正确预测数量:
-
correct = (predicted == y_test_tensor).sum().item()计算预测正确的样本数量。这里使用.sum()来累加所有正确的预测,并通过.item()将其转换为一个标量。
-
-
计算准确率:
-
total = y_test_tensor.size(0)获取测试集的样本总数。 -
print语句打印出模型在测试集上的准确率,即正确预测的样本数占总样本数的比例
-
代码汇总:
import scipy.io
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 加载数据和标签
data = scipy.io.loadmat("D:/Indian_pines_corrected.mat")['indian_pines_corrected']
gt = scipy.io.loadmat("D:/Indian_pines_gt.mat")['indian_pines_gt'].ravel() # 确保标签是一个一维数组
# 数据预处理
num_bands = data.shape[2]
X = data.reshape(-1, num_bands)
# 归一化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, gt, test_size=0.2, random_state=42)
# 将NumPy数组转换为PyTorch张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
# 为Conv1d增加通道维度
X_train_tensor = X_train_tensor.unsqueeze(1)
X_test_tensor = X_test_tensor.unsqueeze(1)
# 定义网络
class SpectralCNN(nn.Module):
def __init__(self, num_bands, num_classes):
super(SpectralCNN, self).__init__()
self.conv1 = nn.Conv1d(in_channels=1, out_channels=64, kernel_size=3, padding=1)
self.pool = nn.MaxPool1d(kernel_size=2)
self.conv2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
# 计算经过两次卷积和池化后的输出大小
# 卷积后,宽度保持不变;池化后,宽度减半
conv_output_size = num_bands
pool_output_size = int(np.ceil(conv_output_size / 2)) # 第一次池化后的大小
pool_output_size = int(np.ceil(pool_output_size / 2)) # 第二次池化后的大小
# 更新全连接层的输入大小
self.fc1 = nn.Linear(128 * pool_output_size, num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = x.view(x.size(0), -1) # 扁平化特征向量
x = self.fc1(x)
return x
# 初始化模型
num_classes = len(np.unique(gt))
model = SpectralCNN(num_bands=X_train.shape[1], num_classes=num_classes)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10000 # 设置训练轮数
# 开始训练模型
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 测试模型
def evaluate_model(model, X_test_tensor, y_test_tensor):
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 禁用梯度计算
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs.data, 1)
total = y_test_tensor.size(0)
correct = (predicted == y_test_tensor).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))
# 在训练结束后评估模型
evaluate_model(model, X_test_tensor, y_test_tensor)