书接上文,咱们在第一天中学习了Lambda表达式、方法引用、函数式接口等诸多JDK8的新特性,今天呢,让我们在这些新特性的基础上学习强大的Steam流操作。

首先呢,我们还是延用之前的购物车的例子,分别使用原始的集合处理方式和Stream流处理方式,这两种数据处理方式来完成这一场景的数据处理,进而直观的感受流操作给我们带来的便捷性。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.concurrent.atomic.AtomicReference;
import java.util.stream.Collectors;
/**
* 对比:原始集合操作与Stream集合操作
*/
public class StreamVs {
/**
* 1 想看看购物车中都有什么商品
* 2 图书类商品都给买
* 3 其余的商品中买两件最贵的
* 4 只需要两件商品的名称和总价
*/
/**
* 以原始集合操作实现需求
*/
@Test
public void oldCartHandle() {
List<Sku> cartSkuList = CartService.getCartSkuList();
/**
* 1 打印所有商品
*/
for (Sku sku: cartSkuList) {
System.out.println(JSON.toJSONString(sku, true));
}
/**
* 2 图书类过滤掉
*/
List<Sku> notBooksSkuList = new ArrayList<Sku>();
for (Sku sku: cartSkuList) {
if (!SkuCategoryEnum.BOOKS.equals(sku.getSkuCategory())) {
notBooksSkuList.add(sku);
}
}
/**
* 排序
*/
notBooksSkuList.sort(new Comparator<Sku>() {
@Override
public int compare(Sku sku1, Sku sku2) {
if (sku1.getTotalPrice() > sku2.getTotalPrice()) {
return -1;
} else if (sku1.getTotalPrice() < sku2.getTotalPrice()) {
return 1;
} else {
return 0;
}
}
});
/**
* TOP2
*/
List<Sku> top2SkuList = new ArrayList<Sku>();
for (int i = 0; i < 2; i++) {
top2SkuList.add(notBooksSkuList.get(i));
}
/**
* 4 求两件商品的总价
*/
Double money = 0.0;
for (Sku sku: top2SkuList) {
// money = money + sku.getTotalPrice();
money += sku.getTotalPrice();
}
/**
* 获取两件商品的名称
*/
List<String> resultSkuNameList = new ArrayList<String>();
for (Sku sku: top2SkuList) {
resultSkuNameList.add(sku.getSkuName());
}
/**
* 打印输入结果
*/
System.out.println(
JSON.toJSONString(resultSkuNameList, true));
System.out.println("商品总价:" + money);
}
/**
* 以Stream流方式实现需求
*/
@Test
public void newCartHandle() {
AtomicReference<Double> money =
new AtomicReference<>(Double.valueOf(0.0));
List<String> resultSkuNameList =
CartService.getCartSkuList()
.stream()
/**
* 1 打印商品信息
*/
.peek(sku -> System.out.println(
JSON.toJSONString(sku, true)))
/**
* 2 过滤掉所有图书类商品
*/
.filter(sku -> !SkuCategoryEnum.BOOKS.equals(
sku.getSkuCategory()))
/**
* 排序
*/
.sorted(Comparator.
comparing(Sku::getTotalPrice).reversed())
/**
* TOP2
*/
.limit(2)
/**
* 累加商品总金额
*/
.peek(sku -> money.set(money.get() + sku.getTotalPrice()))
/**
* 获取商品名称
*/
.map(sku -> sku.getSkuName())
/**
* 收集结果
*/
.collect(Collectors.toList());
/**
* 打印输入结果
*/
System.out.println(
JSON.toJSONString(resultSkuNameList, true));
System.out.println("商品总价:" + money.get());
}
}上边就是分别使用传统集合操作和Stream流处理集合的案例。这些就是咱们接下来要学习的重点。使用Stream以及它下面对流的操作,来帮助我们对集合进行一些处理。

通过之前的案例,我们可以明显的感觉到使用Stream流对集合的操作能为我们的开发带来那些便利性,那从现在开始我们来重点介绍一下Stream各方面的知识。
首先,流是什么?流呢它不是我们之前见到的IO流这种流操作,它是JDK1.8引入的新成员,以声明的方式处理集合数据,所谓声明式呢,其实是离不开Lambda表达式的。
第二呢,它是将基础的操作链接起来,完成复杂的数据处理的流水线。
第三呢,流操作为我们提供了一个透明的并行处理能力。

咱们依次来解释一下这三个划红线的词。
第一呢,就是什么是元素序列?与集合一样,流呢也提供一个接口,可以访问特定元素的一组有序值,这组有序值就是元素序列。
那什么是源呢?与现实中的水流类似,源是为流提供数据的源头,比如说集合、数组、输入输出的资源,都可以称之为源。
那什么是数据处理操作呢?流的数据处理操作支持类似数据库的操作,比如上面的map、sort、limit以及一些函数式编程中的常用操作。

下面我们来说一说流和集合的区别,首先是时间和空间上的区别。在这里可以举个例子,集合就相当于我们之前看的DVD光碟,你只有把这个光碟放到DVD机里才能观看整部电影;流呢,相当于现在的融媒体播放,你不用获取到一部电影的所有数据帧,只需要获取到当前正在观看的一定时间范围内的数据帧就可以。从这个角度来看,集合更像是空间上的元素的存储,流更像是时间维度上的数据的生成。所以一般对流和集合的定位是集合面向的是存储,而流面向的是计算。再举一个简单的例子,比如说让你构建一个质数集合,理论上说是构建不出来的,因为质数是无限大的,不可穷举;但是如果让你构建一个质数流,那是可以做到的,你只需要在使用到一个质数的时候实时地计算出这个质数就可以了。从这个角度上来说它们还是时间与空间上的区别。
那第二个不同是集合可以遍历多次,但是流呢因为是空间的概念,所以它只能遍历一次,再次遍历就会出现异常。
第三呢,是集合需要做外部迭代,类似于一开始咱们的那个例子,咱们需要对集合不停的做foreach迭代。那流呢,它是内部迭代,咱们只需要定义需要对流中的每一个元素做什么操作,然后呢,流就会帮我们做内部的迭代,去处理这些操作。这是流与集合的一些区别。
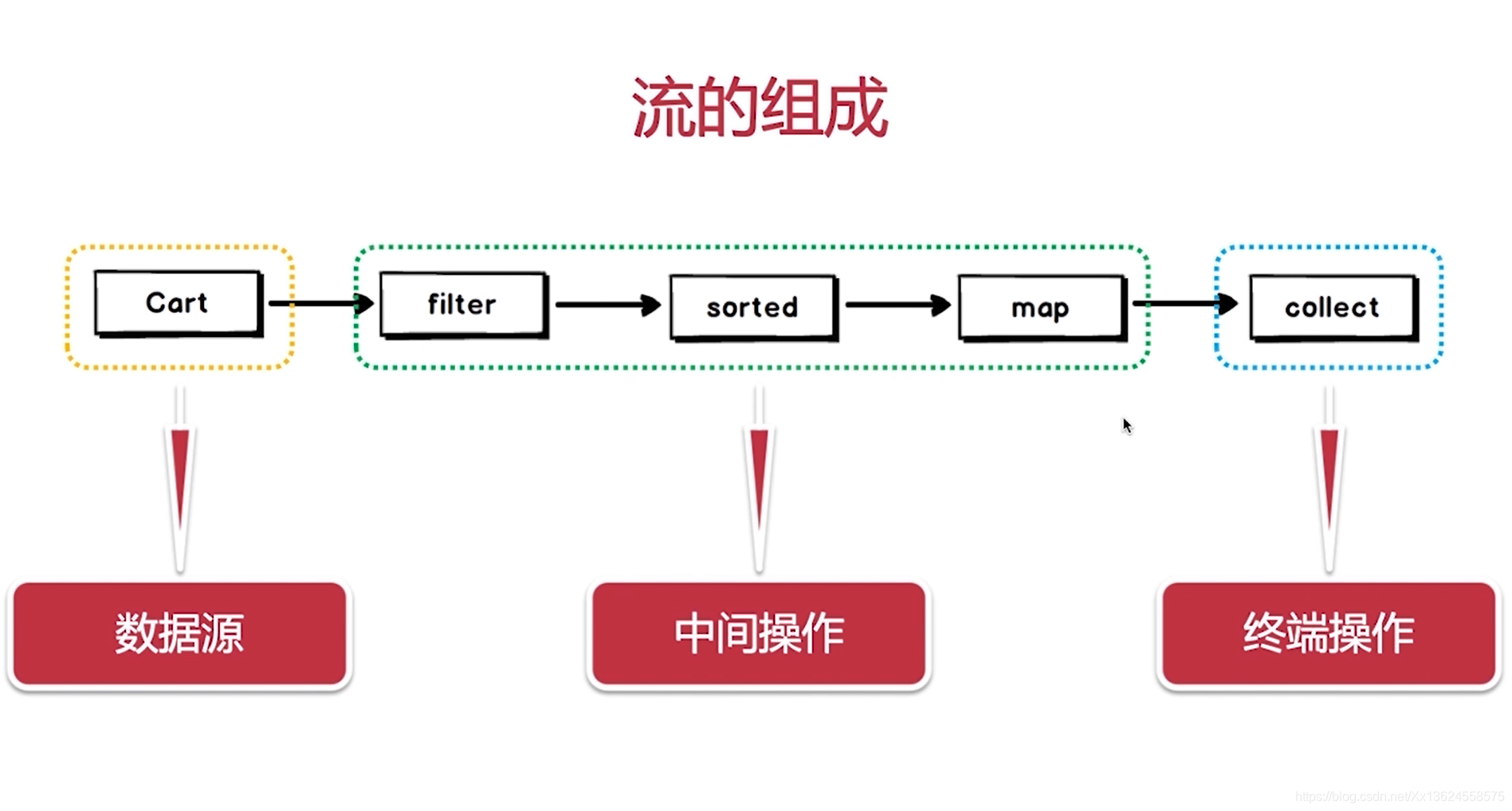
然后呢,再看一看流的组成, 流分三部分组成,第一部分是 数据源。第二部分是 中间操作。第三部分是 终端操作。中间操作主要是我们做自己的业务处理。就像上面最开始的例子一样,咱们对它进行过滤、排序、解析。然后呢,终端操作是对流的收集。咱们可以将数据源产生的数据在这里做一个收集,形成咱们的数据结构。
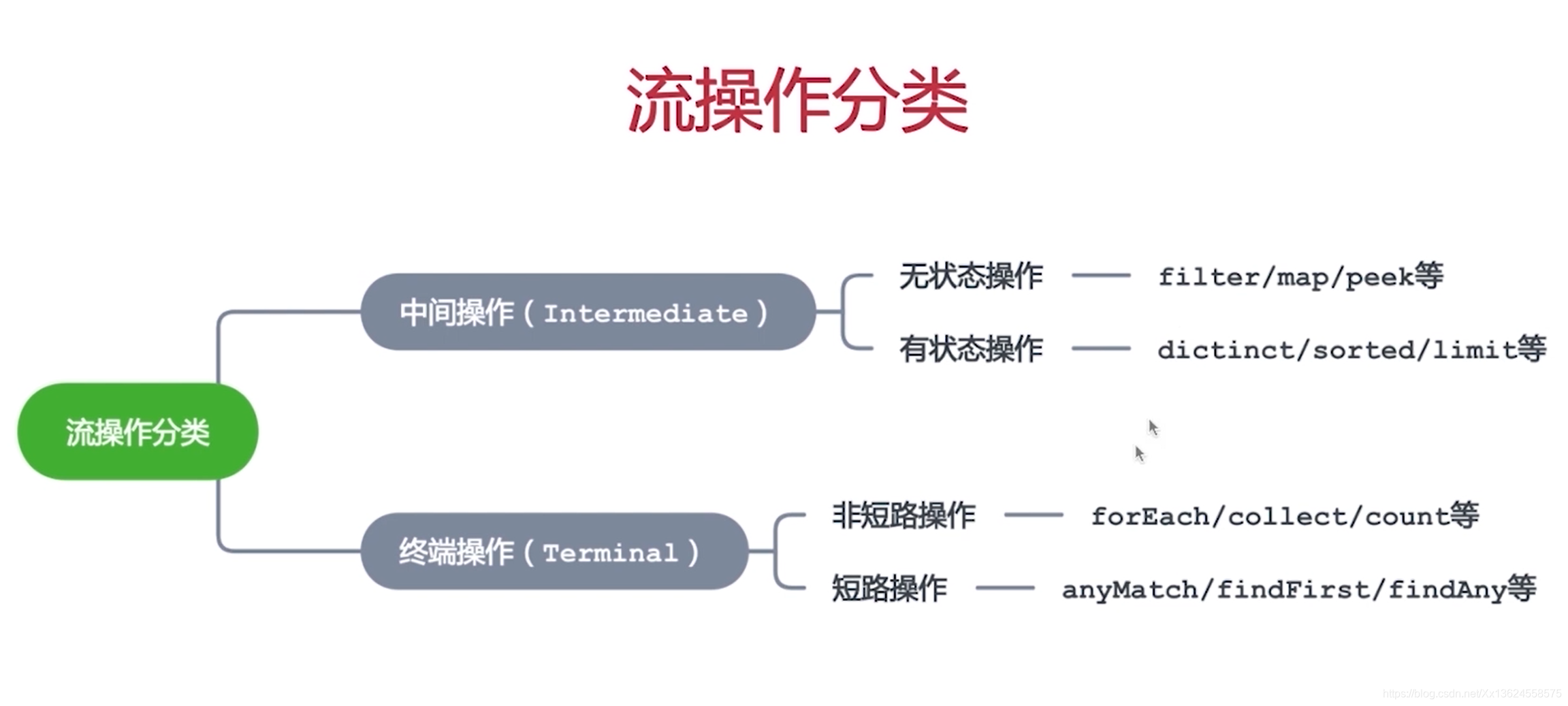
我们对流的操作可以大致分一下类,我们可以看一下上面的思维导图。上面说的流的组成有一个 中间操作 和一个 终端操作。而流的操作也是按 中间操作 和 终端操作 分的两大类。
在中间操作中呢,有 无状态操作 和 有状态操作 两大类。那怎么理解这个呢?咱们可以想像一下,有过SQL经验的肯定会知道,比如说这个distinct去重它一定是在所有数据的基础上才能把重复的去掉;在比如说sorted排序也是肯定在所有的数据基础上进行一个排序。那这种呢我们就称之为有状态的操作。
而还有一些呢,比如说filter过滤,过滤很简单,就是当前这个数据它的某些字段是否符合咱们的要求,那就是过滤,它并不需要建立在所有数据的基础上来实现,它只需要对单个的数据进行实现,进行判断就好了。这个称为无状态的操作。
再来看终端操作,分为两类,一种是 非短路操作,另一种是 短路操作。
那什么是 非短路操作?就是数据集有多个数据,每个数据都要执行一遍forEach,这个就是非短路操作。
那短路操作就是比如说你要找到第一个元素,那不管我这个数据集有多少,只要找到第一个元素,后面的元素就都不会执行了。那这就是短路操作。

这里对流所支持的所有操作进行了一些罗列, 并且已经分好类了。各位小伙伴在使用流的时候可以参考这个分类,选择合适的方式来使用流的各种操作。之后的实战案例也将演示流的每种使用方式。
下面通过实际应用场景,介绍流的使用。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}首先使用list创建一个stream流,接着调用filter,因为它是一个中间操作,流的构成中说了,最后还要有一个终端操作,咱们的终端操作先统一使用
item ->
System.out.println(
JSON.toJSONString(
item, true))将结果打印出来,不管它是什么。那咱们接下来重点看一下filter如何使用。

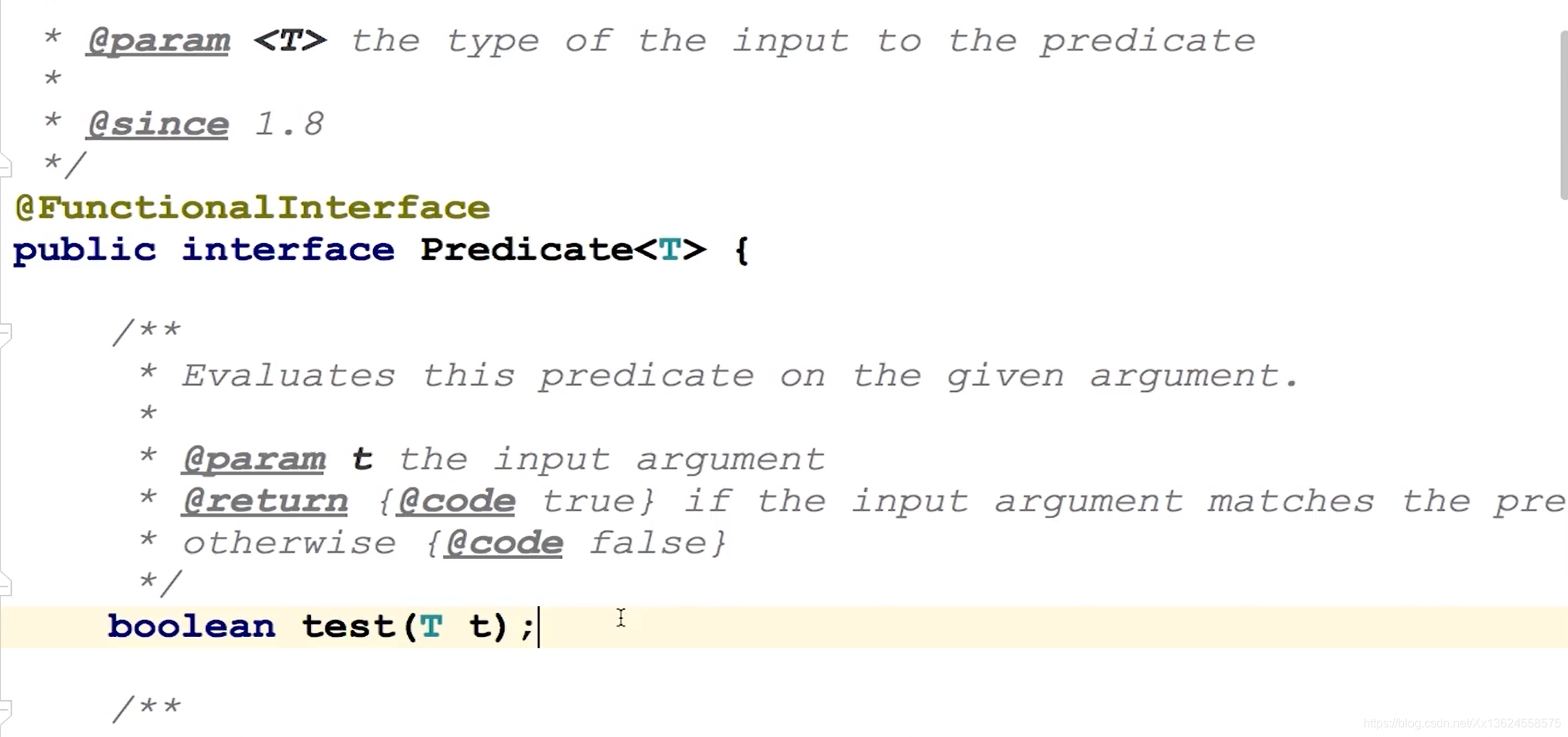
咱们点进去看到,filter接收一个Predicate函数式接口, 那咱们在学Lambda表达式时也说过了,Predicate呢它里面只有一个test,只要你把参数传进来,然后它根据业务规则来判断,返回一个True或者False。filter也比较简单,需要传入的是一个集合元素,那就是sku,那咱们根据某些规则来判断sku是不是符合这个断言。如果符合filter就不会过滤这个元素,如果不符合filter就会将这个元素过滤掉。咱们先判断sku是不是书籍类?如果等于书籍类,就将它保留,如果不等于就将它过滤。
以上是filter的一个简单的使用。
接下来咱们看map。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}map方法呢,看看它的传入参数是什么?

是一个Function的函数接口。

那Function做什么的呢?Function是将一个T型的输入参数转换为一个R型的输出参数。
那很明显,map的作用就是将一个集合元素转换为另一种形式的集合元素。咱们就可以将sku对象转换为String对象。
接下来咱们看一个与map类似,但又有一点差异的方法,叫做flatMap。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}翻译过来叫做 扁平化Map,这个操作是做什么用的呢?咱们看看它接收哪些参数?
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);它还是接收一个Function函数式接口,但是它返回的R咱们注意观察,这个R是一个Stream类型的流。那说明flatMap接收一个元素,返回一个新的流,这个流将会与其他元素产生的流进行一个合并,最后统一的由forEach来进行输出。咱们这里将商品的名称进行切分,返回一个切分后的字符流。
下面咱们来看peek。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}这个操作呢其实与forEach操作是一样的,但是它与forEach操作本质的区别是它是一个中间操作,而forEach是一个终端操作,forEach操作之后这个流就不可用了。peek操作之后的流是可以被后续环节继续使用的,咱们来看看它的接收参数。
Stream<T> peek(Consumer<? super T> action);是一个Consumer的函数式接口,Consumer里面就有一个accept,对数据进行一些操作,它没有返回值。它只是单纯的数据操作。
import java.util.Objects;
/**
* Represents an operation that accepts a single input argument and returns no
* result. Unlike most other functional interfaces, {@code Consumer} is expected
* to operate via side-effects.
*
* <p>This is a <a href="package-summary.html">functional interface</a>
* whose functional method is {@link #accept(Object)}.
*
* @param <T> the type of the input to the operation
*
* @since 1.8
*/
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
/**
* Returns a composed {@code Consumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code Consumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}那咱们对sku的名称进行打印吧。

这里可以看到一个现象,就是forEach和peek是交替执行的。,并不是peek完全执行完,forEach才执行,而是一条数据先经过peek,然后再经过forEach,那这也是流执行的一个特点。流是惰性执行,只有遇到forEach这种终端操作,流的元素才会由上到下依次执行,恰好peek这种中间操作呢又是无状态的中间操作,也是就说先执行谁并没有很大的区别,对结果不会有影响,所以
它就会先执行peek中间操作,紧跟着执行forEach终端操作。
下面我们要讲的是有状态的中间操作,此时结果就会不一样。
咱们先来看一个sorted操作。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}sorted操作呢,无参的是按照默认的自然排序策略来排。那咱们加一个有参数的。根据sku的总价来排。
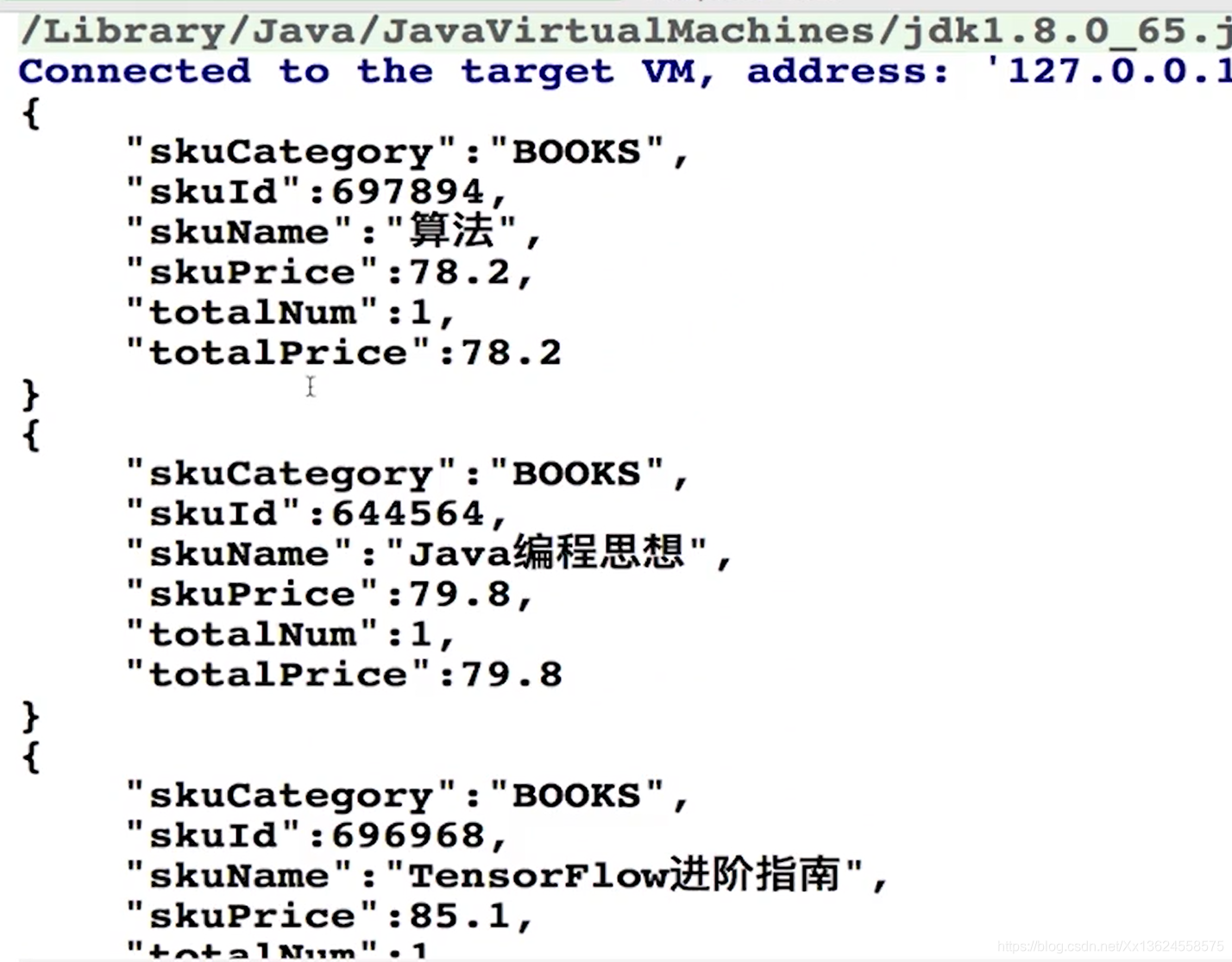
咱们先看排序之后的效果是总价是按照从小到大的顺序排列的。
所以说sorted操作起到了它应有的作用。咱们这里呢再加一个peek操作。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}peek操作还是在打印这个商品名称。这里咱们注意观察,通过中间添加sorted操作之后,peek操作还会和forEach操作一起打印吗?
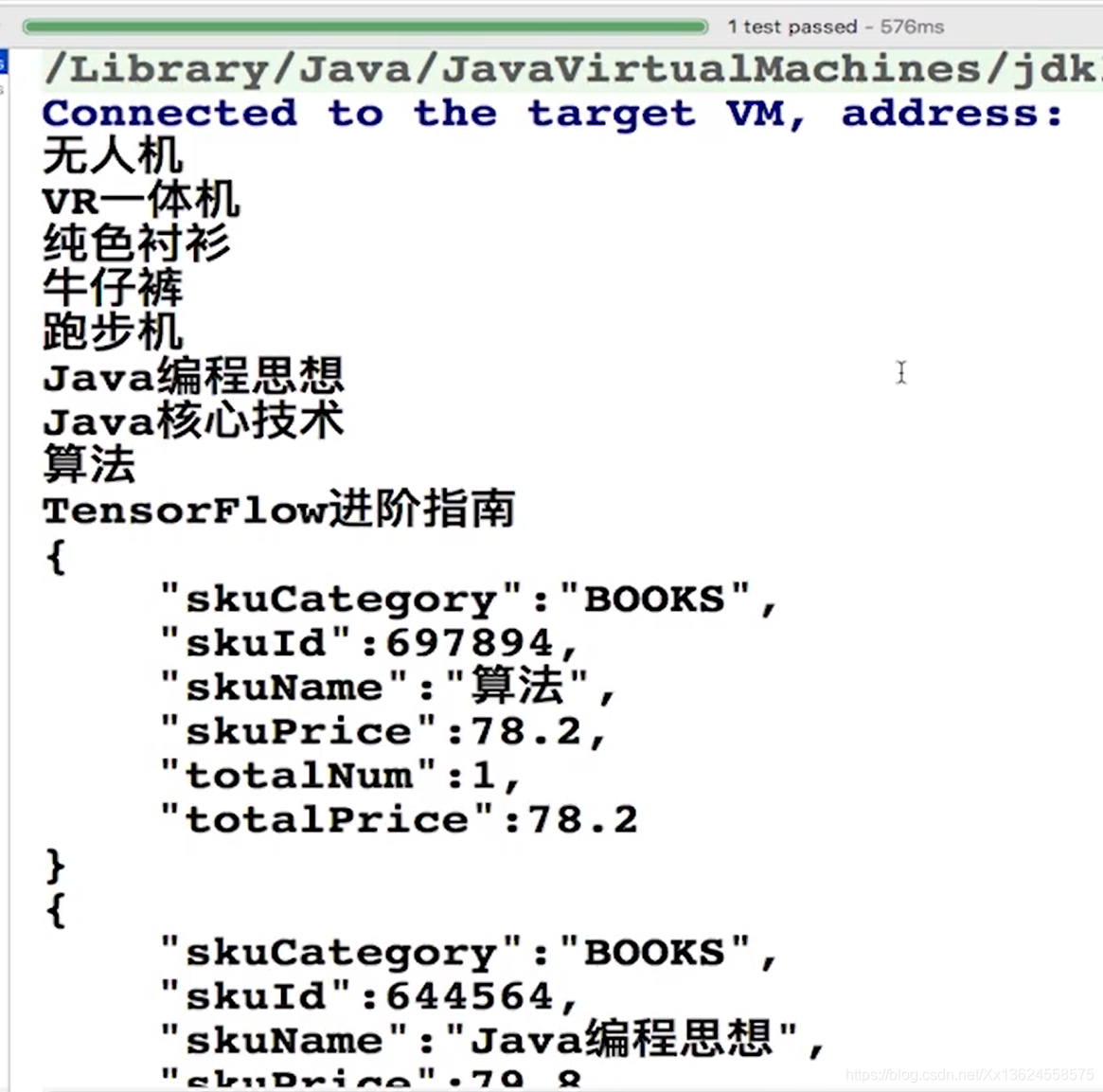
可以看到很明显,这个商品名称的是peek操作来打印出来的。而后面的呢是forEach操作来打印出来的。它们已经有了一个很明显的先后顺序。所有数据在执行完peek操作之后才会执行forEach操作。这个原因就是咱们在中间加了一个有状态的sorted操作,所有经过peek的数据都要先在sorted这里做一个汇总,由sorted进行统一排序之后再交由下一个环节进行处理。
这个就是有状态操作和无状态操作的区别,会对数据执行的先后有影响。
接下来我们来演示distinct去重。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}我们的目的是把sku的所有分类打印出来,然后将他们去重看看有几种分类。首先咱们通过map将sku转换成它的类别对象,紧接着通过类别对象对它去重,接着打印去重之后剩下的sku的分类。
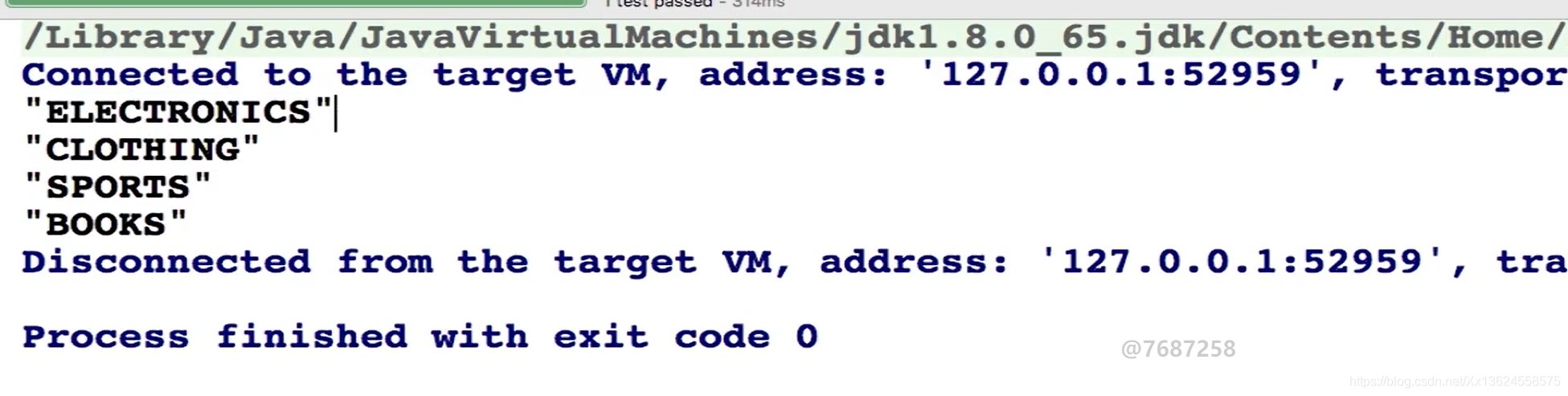
可以看到咱们的购物车中的sku一共涉及到了四个分类。这四个分类都是经过去重之后留下的。这是distinct的一个用途。
接下来咱们继续看skip。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}skip的作用是跳过前几条元素,在跳过之前咱们先给它排个序,我们还是根据总价进行排序,接着咱们调用skip过滤掉前三条数据,然后咱们进行数据的打印。

可以看到咱们的数据是从149开始,前三条70多的已经被过滤掉了。
最后咱们来看一个有状态的操作limit。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
}那有人会想了,skip是跳过某几条数据,limit又是限制了几条数据,那如果把它们两个结合起来做一个假的分页其实是可以实现的。比如说第三页,咱们以三条数据为一页吧,如果是第三页就是跳过skip(2 * 3),再取后三条数据limit(3)。这样就实现了一个假的分页。
接下来我们对终端操作进行演示。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
}
allMatch用来检测所有的元素是否都满足断言?如果都满足返回True,如果有一个不满足返回false。因为是终端操作,我们可以直接使用,也没有中间操作,我们来判断总价是否大于100,这里的返回类型是Boolean类型的。
刚才我们说了,这个allMatch是一个终端操作,并且是一个短路操作,当它检测到第一个不满足这个条件的,它就会返回这个Boolean返回值,那怎么来看呢,咱们使用peek打印一下。
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}对当前的skuName进行打印,如果peek将所有的集合元素都打印了,那说明所有的元素都经过了allMatch的匹配。那跟我们之前的猜想就不符了,如果只打印了部分sku,那就证明部分sku,当有一个sku不通过allMatch的检测的时候,那后续的sku就不会执行。

可以看到我们打印的sku件数不够,起码图书我们应该打印出四种,而现在只打印出一种。说明allMatch操作是一个短路操作,它会依次消费流中的元素,如果有一个不匹配,将不会消费后面的元素,会直接返回一个结果。
跟它相似的还有anyMatch。它的意思是只要有元素满足它的断言就会返回True,否则的话就会返回False。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* anyMatch使用:任何元素匹配,返回true
*/
@Test
public void anyMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// anyMatch
.anyMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
}

最后一个是noneMatch。
package com.imooc.lvdapiaoliang.stream;
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* anyMatch使用:任何元素匹配,返回true
*/
@Test
public void anyMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// anyMatch
.anyMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* noneMatch使用:任何元素都不匹配,返回true
*/
@Test
public void noneMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// noneMatch
.noneMatch(sku -> sku.getTotalPrice() > 10_000);
System.out.println(match);
}
}
接下来我们来介绍findFirst。它返回的是一个Optional。

import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* anyMatch使用:任何元素匹配,返回true
*/
@Test
public void anyMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// anyMatch
.anyMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* noneMatch使用:任何元素都不匹配,返回true
*/
@Test
public void noneMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// noneMatch
.noneMatch(sku -> sku.getTotalPrice() > 10_000);
System.out.println(match);
}
/**
* 找到第一个
*/
@Test
public void findFirstTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findFirst
.findFirst();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
}
与它相似的还有findAny。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* anyMatch使用:任何元素匹配,返回true
*/
@Test
public void anyMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// anyMatch
.anyMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* noneMatch使用:任何元素都不匹配,返回true
*/
@Test
public void noneMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// noneMatch
.noneMatch(sku -> sku.getTotalPrice() > 10_000);
System.out.println(match);
}
/**
* 找到第一个
*/
@Test
public void findFirstTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findFirst
.findFirst();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
/**
* 找任意一个
*/
@Test
public void findAnyTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findAny
.findAny();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
}
那在使用findFirst和findAny有什么区别呢?其实在并行上是有区别的,因为找到第一个元素在并行上的限制会更多一点;找到任意一个在并行上的限制会少。所以总体上来说,findAny在并行上的速度会比findFirst要快。但是findAny有一个缺点是它可能会随机匹配到一个元素。所以findAny返回的元素可能会不一致。但是如果两个流都是串行操作,那个这两个没什么区别。
接下来我们来看几个非短路的终端操作。
首先是max,求一个集合中某个属性的最大值。
package com.imooc.lvdapiaoliang.stream;
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* anyMatch使用:任何元素匹配,返回true
*/
@Test
public void anyMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// anyMatch
.anyMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* noneMatch使用:任何元素都不匹配,返回true
*/
@Test
public void noneMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// noneMatch
.noneMatch(sku -> sku.getTotalPrice() > 10_000);
System.out.println(match);
}
/**
* 找到第一个
*/
@Test
public void findFirstTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findFirst
.findFirst();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
/**
* 找任意一个
*/
@Test
public void findAnyTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findAny
.findAny();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
/**
* max使用:
*/
@Test
public void maxTest() {
OptionalDouble optionalDouble = list.stream()
// 获取总价
.mapToDouble(Sku::getTotalPrice)
.max();
System.out.println(optionalDouble.getAsDouble());
}
}

首先我们来解释一下mapToDouble是什么意思?我们知道map是将一个元素映射到另一个元素,那mapToDouble是将一个元素映射成Double类型的元素。
下面我们来看min。
package com.imooc.lvdapiaoliang.stream;
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* anyMatch使用:任何元素匹配,返回true
*/
@Test
public void anyMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// anyMatch
.anyMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* noneMatch使用:任何元素都不匹配,返回true
*/
@Test
public void noneMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// noneMatch
.noneMatch(sku -> sku.getTotalPrice() > 10_000);
System.out.println(match);
}
/**
* 找到第一个
*/
@Test
public void findFirstTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findFirst
.findFirst();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
/**
* 找任意一个
*/
@Test
public void findAnyTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findAny
.findAny();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
/**
* max使用:
*/
@Test
public void maxTest() {
OptionalDouble optionalDouble = list.stream()
// 获取总价
.mapToDouble(Sku::getTotalPrice)
.max();
System.out.println(optionalDouble.getAsDouble());
}
/**
* min使用
*/
@Test
public void minTest() {
OptionalDouble optionalDouble = list.stream()
// 获取总价
.mapToDouble(Sku::getTotalPrice)
.min();
System.out.println(optionalDouble.getAsDouble());
}
}
原理也是一样的,换成min就可以了。
下面我们来看cout。count是获取元素总数。
package com.imooc.lvdapiaoliang.stream;
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import com.imooc.lvdapiaoliang.lambda.cart.SkuCategoryEnum;
import org.junit.Before;
import org.junit.Test;
import java.util.*;
/**
* 演示流的各种操作
*/
public class StreamOperator {
List<Sku> list;
@Before
public void init() {
list = CartService.getCartSkuList();
}
/**
* filter使用:过滤掉不符合断言判断的数据
*/
@Test
public void filterTest() {
list.stream()
// filter
.filter(sku ->
SkuCategoryEnum.BOOKS
.equals(sku.getSkuCategory()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* map使用:将一个元素转换成另一个元素
*/
@Test
public void mapTest() {
list.stream()
// map
.map(sku -> sku.getSkuName())
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* flatMap使用:将一个对象转换成流
*/
@Test
public void flatMapTest() {
list.stream()
// flatMap
.flatMap(sku -> Arrays.stream(
sku.getSkuName().split("")))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* peek使用:对流中元素进行遍历操作,与forEach类似,但不会销毁流元素
*/
@Test
public void peek() {
list.stream()
// peek
.peek(sku -> System.out.println(sku.getSkuName()))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* sort使用:对流中元素进行排序,可选则自然排序或指定排序规则。有状态操作
*/
@Test
public void sortTest() {
list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
//sort
.sorted(Comparator.comparing(Sku::getTotalPrice))
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* distinct使用:对流元素进行去重。有状态操作
*/
@Test
public void distinctTest() {
list.stream()
.map(sku -> sku.getSkuCategory())
// distinct
.distinct()
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* skip使用:跳过前N条记录。有状态操作
*/
@Test
public void skipTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
// skip
.skip(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* limit使用:截断前N条记录。有状态操作
*/
@Test
public void limitTest() {
list.stream()
.sorted(Comparator.comparing(Sku::getTotalPrice))
.skip(2 * 3)
// limit
.limit(3)
.forEach(item ->
System.out.println(
JSON.toJSONString(
item, true)));
}
/**
* allMatch使用:终端操作,短路操作。所有元素匹配,返回true
*/
@Test
public void allMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// allMatch
.allMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* anyMatch使用:任何元素匹配,返回true
*/
@Test
public void anyMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// anyMatch
.anyMatch(sku -> sku.getTotalPrice() > 100);
System.out.println(match);
}
/**
* noneMatch使用:任何元素都不匹配,返回true
*/
@Test
public void noneMatchTest() {
boolean match = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// noneMatch
.noneMatch(sku -> sku.getTotalPrice() > 10_000);
System.out.println(match);
}
/**
* 找到第一个
*/
@Test
public void findFirstTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findFirst
.findFirst();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
/**
* 找任意一个
*/
@Test
public void findAnyTest() {
Optional<Sku> optional = list.stream()
.peek(sku -> System.out.println(sku.getSkuName()))
// findAny
.findAny();
System.out.println(
JSON.toJSONString(optional.get(), true));
}
/**
* max使用:
*/
@Test
public void maxTest() {
OptionalDouble optionalDouble = list.stream()
// 获取总价
.mapToDouble(Sku::getTotalPrice)
.max();
System.out.println(optionalDouble.getAsDouble());
}
/**
* min使用
*/
@Test
public void minTest() {
OptionalDouble optionalDouble = list.stream()
// 获取总价
.mapToDouble(Sku::getTotalPrice)
.min();
System.out.println(optionalDouble.getAsDouble());
}
/**
* count使用
*/
@Test
public void countTest() {
long count = list.stream()
.count();
System.out.println(count);
}
}

它会获取到Stream流中的所有元素的个数并且返回。

接下来我们来演示流的四种构建形式。
我们先创建一个StreamConstructor类,来演示流的四种构建形式。
首先我们来看由值直接构建流。
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* 流的四种构建形式
*/
public class StreamConstructor {
/**
* 由数值直接构建流
*/
@Test
public void streamFromValue() {
Stream stream = Stream.of(1, 2, 3, 4, 5);
stream.forEach(System.out::println);
}
}
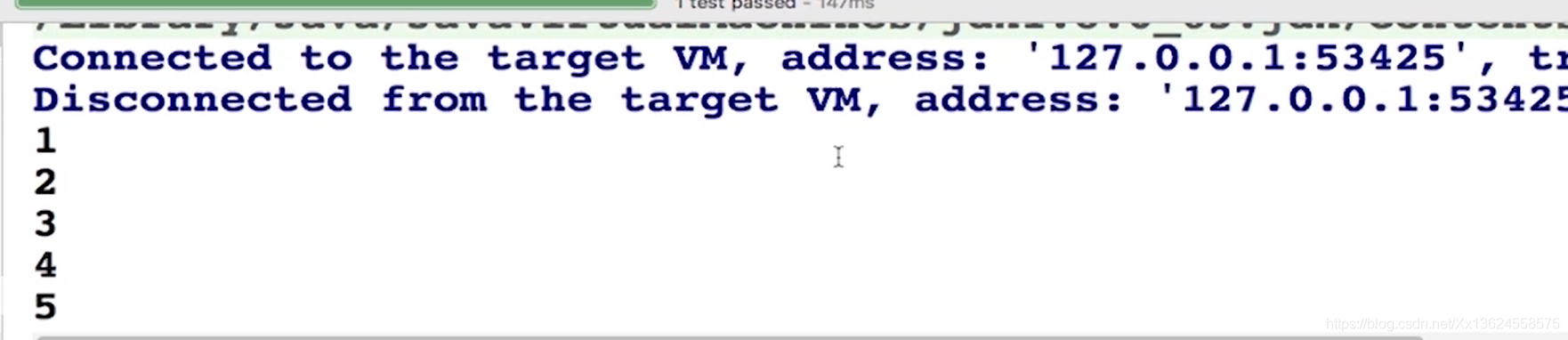
Stream有一个静态的of方法,它可以接收任意数量的参数,通过显示值来创建流。
第二种方式是通过数组构建流。
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* 流的四种构建形式
*/
public class StreamConstructor {
/**
* 由数值直接构建流
*/
@Test
public void streamFromValue() {
Stream stream = Stream.of(1, 2, 3, 4, 5);
stream.forEach(System.out::println);
}
/**
* 通过数组构建流
*/
@Test
public void streamFromArray() {
int[] numbers = {1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(numbers);
stream.forEach(System.out::println);
}
}
接着我们来看通过文件来构建流,Java的NIO呢,为我们提供了一个Files工具类,它里面有很多的静态方法都可以返回一个流。比如说lines方法,它会返回一个由指定文件中的各行构成的字符串流。
package com.imooc.lvdapiaoliang.stream;
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* 流的四种构建形式
*/
public class StreamConstructor {
/**
* 由数值直接构建流
*/
@Test
public void streamFromValue() {
Stream stream = Stream.of(1, 2, 3, 4, 5);
stream.forEach(System.out::println);
}
/**
* 通过数组构建流
*/
@Test
public void streamFromArray() {
int[] numbers = {1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(numbers);
stream.forEach(System.out::println);
}
/**
* 通过文件生成流
* @throws IOException
*/
@Test
public void streamFromFile() throws IOException {
// TODO 此处替换为本地文件的地址全路径
String filePath = "";
Stream<String> stream = Files.lines(
Paths.get(filePath));
stream.forEach(System.out::println);
}
}
接下来我们来看通过函数来生成一个流。
Stream为我们提供了两种根据函数生成流的方法,一种是iterate,利用迭代的方式生成,比如说咱们要生成一个正偶数的流。
package com.imooc.lvdapiaoliang.stream;
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* 流的四种构建形式
*/
public class StreamConstructor {
/**
* 由数值直接构建流
*/
@Test
public void streamFromValue() {
Stream stream = Stream.of(1, 2, 3, 4, 5);
stream.forEach(System.out::println);
}
/**
* 通过数组构建流
*/
@Test
public void streamFromArray() {
int[] numbers = {1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(numbers);
stream.forEach(System.out::println);
}
/**
* 通过文件生成流
* @throws IOException
*/
@Test
public void streamFromFile() throws IOException {
// TODO 此处替换为本地文件的地址全路径
String filePath = "";
Stream<String> stream = Files.lines(
Paths.get(filePath));
stream.forEach(System.out::println);
}
/**
* 通过函数生成流(无限流)
*/
@Test
public void streamFromFunction() {
Stream stream = Stream.iterate(0, n -> n + 2);
stream.forEach(System.out::println);
}
}
它的生成方式就是在原来的值基础上加2生成新的流,而最开始的值是0,也就是从0开始的,2,4,6......一直生成下去。如果我们想创建一个无限的集合那是不可能的,但是我们可以通过流来创建一个无限的流。这就是集合与流的不同。
咱们看完这种生成方式,咱们看下一种生成方式,Stream还为我们提供了一种叫generate的方法,它是通过一个生成器来生成流。跟迭代不同的是后一个流不会基于上一个流生成,而是随机的生成。
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.stream.IntStream;
import java.util.stream.Stream;
/**
* 流的四种构建形式
*/
public class StreamConstructor {
/**
* 由数值直接构建流
*/
@Test
public void streamFromValue() {
Stream stream = Stream.of(1, 2, 3, 4, 5);
stream.forEach(System.out::println);
}
/**
* 通过数组构建流
*/
@Test
public void streamFromArray() {
int[] numbers = {1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(numbers);
stream.forEach(System.out::println);
}
/**
* 通过文件生成流
* @throws IOException
*/
@Test
public void streamFromFile() throws IOException {
// TODO 此处替换为本地文件的地址全路径
String filePath = "";
Stream<String> stream = Files.lines(
Paths.get(filePath));
stream.forEach(System.out::println);
}
/**
* 通过函数生成流(无限流)
*/
@Test
public void streamFromFunction() {
// Stream stream = Stream.iterate(0, n -> n + 2);
Stream stream = Stream.generate(Math::random);
stream.limit(100)
.forEach(System.out::println);
}
}这次咱们给流做一个限制,只要前一百个,否则又无穷无尽的生成下去。
可以看到,生成了100个随机的Double类型的数值的流, 这就是通过函数生成流,流呢是一个无限流,所以需要通过limit来限制生成个数。
以上呢就是流的四种构建形式。
在前面我们讲解完了流的创建和各种操作,接下来我们来讲解流的收集。我们已经处理好的流如何将它收集起来?比如收集成一个List集合或者收集成一个Set集合呢?那这就要看咱们收集器的作用。

收集器的作用就是将流中的元素累积成一个结果,这个结果可以是数值,可以是集合,包括可以是个分组。
收集器作用于终端操作collect()上。
可能小伙伴有几个概念可能会混淆,就是collect/Collector/Collectors,那collect是作为一个终端操作出现的,它是流收集的最后一个步骤,是一个方法。那Collector是一个接口,collect这个方法需要接收一个实现了一个Collector接口的这么一个收集器才可以收集。那Collectors是一个工具类,它帮我们提前封装好了一些已经预制好的实现了Collector接口的收集器,我们可以直接拿过来用。这就是它们三个的关系。
刚才咱们谈到了Collectors这个工具类为我们预制了一些收集器的实现,都有哪些实现呢?主要分三种。


下面通过一个实战案例来演示 一下预定义的收集器的使用方式。
接下来我们来演示一下三种非常常见的预定义收集器的使用方式。
首先咱们先创建一个StreamCollector类。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import org.junit.Test;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* 常见预定义收集器使用
*/
public class StreamCollector {
/**
* 集合收集器
*/
@Test
public void toList() {
List<Sku> list = CartService.getCartSkuList();
List<Sku> result = list.stream()
.filter(sku -> sku.getTotalPrice() > 100)
.collect(Collectors.toList());
System.out.println(
JSON.toJSONString(result, true));
}
}首先是toList方法,直接将我们处理好的流收集成一个List集合,那细心的小伙伴可能在前面看到过这种用法,这里咱们简单的讲解一下,首先还是先获取咱们的流,然后咱们做一下过滤,将总价大于100的过滤出来,接着咱们调用collect,它接收一个Collector的接口实现类。
<R, A> R collect(Collector<? super T, A, R> collector);那咱们可以调用Collectors.toList()方法,它帮我们预定义了一个Collector的接口实现类。就是将集合中的元素收集为一个List返回。它呢,返回一个List集合。
Connected to the target VM, address: '127.0.0.1:11936', transport: 'socket'
[
{
"skuCategory":"ELECTRONICS",
"skuId":654032,
"skuName":"无人机",
"skuPrice":4999.0,
"totalNum":1,
"totalPrice":4999.0
},
{
"skuCategory":"ELECTRONICS",
"skuId":642934,
"skuName":"VR一体机",
"skuPrice":2299.0,
"totalNum":1,
"totalPrice":2299.0
},
{
"skuCategory":"CLOTHING",
"skuId":645321,
"skuName":"纯色衬衫",
"skuPrice":409.0,
"totalNum":3,
"totalPrice":1227.0
},
{
"skuCategory":"CLOTHING",
"skuId":654327,
"skuName":"牛仔裤",
"skuPrice":528.0,
"totalNum":1,
"totalPrice":528.0
},
{
"skuCategory":"SPORTS",
"skuId":675489,
"skuName":"跑步机",
"skuPrice":2699.0,
"totalNum":1,
"totalPrice":2699.0
},
{
"skuCategory":"BOOKS",
"skuId":678678,
"skuName":"Java核心技术",
"skuPrice":149.0,
"totalNum":1,
"totalPrice":149.0
}
]
Disconnected from the target VM, address: '127.0.0.1:11936', transport: 'socket'
Process finished with exit code 0可以看到返回的是一个集合类型。
接下来我们来看看分组,这个也比较常用。咱们现在要求:将商品根据类别进行分组。借助于Stream流咱们可以很简单的来实现这个功能。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import org.junit.Test;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* 常见预定义收集器使用
*/
public class StreamCollector {
/**
* 集合收集器
*/
@Test
public void toList() {
List<Sku> list = CartService.getCartSkuList();
List<Sku> result = list.stream()
.filter(sku -> sku.getTotalPrice() > 100)
.collect(Collectors.toList());
System.out.println(
JSON.toJSONString(result, true));
}
/**
* 分组
*/
@Test
public void group() {
List<Sku> list = CartService.getCartSkuList();
// Map<分组条件,结果集合>
Map<Object, List<Sku>> group = list.stream()
.collect(
Collectors.groupingBy(
sku -> sku.getSkuCategory()));
System.out.println(
JSON.toJSONString(group, true));
}
}首先咱们来创建Stream流,接着咱们调用collect收集器,Collectors为我们提供了一个groupingBy方法,它就是来做分组用的,groupingBy它接收一个Function,这个Function就是用来作为分组的标识,你需要用哪些属性来做分组。它会返回一个map,map的key就是你作为分组的条件,value呢是一个元素的集合。
Connected to the target VM, address: '127.0.0.1:11916', transport: 'socket'
{"SPORTS":[
{
"skuCategory":"SPORTS",
"skuId":675489,
"skuName":"跑步机",
"skuPrice":2699.0,
"totalNum":1,
"totalPrice":2699.0
}
],"CLOTHING":[
{
"skuCategory":"CLOTHING",
"skuId":645321,
"skuName":"纯色衬衫",
"skuPrice":409.0,
"totalNum":3,
"totalPrice":1227.0
},
{
"skuCategory":"CLOTHING",
"skuId":654327,
"skuName":"牛仔裤",
"skuPrice":528.0,
"totalNum":1,
"totalPrice":528.0
}
],"ELECTRONICS":[
{
"skuCategory":"ELECTRONICS",
"skuId":654032,
"skuName":"无人机",
"skuPrice":4999.0,
"totalNum":1,
"totalPrice":4999.0
},
{
"skuCategory":"ELECTRONICS",
"skuId":642934,
"skuName":"VR一体机",
"skuPrice":2299.0,
"totalNum":1,
"totalPrice":2299.0
}
],"BOOKS":[
{
"skuCategory":"BOOKS",
"skuId":644564,
"skuName":"Java编程思想",
"skuPrice":79.8,
"totalNum":1,
"totalPrice":79.8
},
{
"skuCategory":"BOOKS",
"skuId":678678,
"skuName":"Java核心技术",
"skuPrice":149.0,
"totalNum":1,
"totalPrice":149.0
},
{
"skuCategory":"BOOKS",
"skuId":697894,
"skuName":"算法",
"skuPrice":78.2,
"totalNum":1,
"totalPrice":78.2
},
{
"skuCategory":"BOOKS",
"skuId":696968,
"skuName":"TensorFlow进阶指南",
"skuPrice":85.1,
"totalNum":1,
"totalPrice":85.1
}
]
}
Disconnected from the target VM, address: '127.0.0.1:11916', transport: 'socket'
Process finished with exit code 0
那咱们再来看一看,还有一种是分区。分区是分组的一种特殊情况,它是由一个谓词作为分类的函数,也称它为分区函数,这个分区函数会返回一个Boolean值。这意味着将数据分成两组,一组是Boolean为True的,一组是Boolean为False的。那咱们来看一看演示。
import com.alibaba.fastjson.JSON;
import com.imooc.lvdapiaoliang.lambda.cart.CartService;
import com.imooc.lvdapiaoliang.lambda.cart.Sku;
import org.junit.Test;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* 常见预定义收集器使用
*/
public class StreamCollector {
/**
* 集合收集器
*/
@Test
public void toList() {
List<Sku> list = CartService.getCartSkuList();
List<Sku> result = list.stream()
.filter(sku -> sku.getTotalPrice() > 100)
.collect(Collectors.toList());
System.out.println(
JSON.toJSONString(result, true));
}
/**
* 分组
*/
@Test
public void group() {
List<Sku> list = CartService.getCartSkuList();
// Map<分组条件,结果集合>
Map<Object, List<Sku>> group = list.stream()
.collect(
Collectors.groupingBy(
sku -> sku.getSkuCategory()));
System.out.println(
JSON.toJSONString(group, true));
}
/**
* 分区
*/
@Test
public void partition() {
List<Sku> list = CartService.getCartSkuList();
Map<Boolean, List<Sku>> partition = list.stream()
.collect(Collectors.partitioningBy(
sku -> sku.getTotalPrice() > 100));
System.out.println(
JSON.toJSONString(partition, true));
}
}Connected to the target VM, address: '127.0.0.1:12122', transport: 'socket'
{false:[
{
"skuCategory":"BOOKS",
"skuId":644564,
"skuName":"Java编程思想",
"skuPrice":79.8,
"totalNum":1,
"totalPrice":79.8
},
{
"skuCategory":"BOOKS",
"skuId":697894,
"skuName":"算法",
"skuPrice":78.2,
"totalNum":1,
"totalPrice":78.2
},
{
"skuCategory":"BOOKS",
"skuId":696968,
"skuName":"TensorFlow进阶指南",
"skuPrice":85.1,
"totalNum":1,
"totalPrice":85.1
}
],true:[
{
"skuCategory":"ELECTRONICS",
"skuId":654032,
"skuName":"无人机",
"skuPrice":4999.0,
"totalNum":1,
"totalPrice":4999.0
},
{
"skuCategory":"ELECTRONICS",
"skuId":642934,
"skuName":"VR一体机",
"skuPrice":2299.0,
"totalNum":1,
"totalPrice":2299.0
},
{
"skuCategory":"CLOTHING",
"skuId":645321,
"skuName":"纯色衬衫",
"skuPrice":409.0,
"totalNum":3,
"totalPrice":1227.0
},
{
"skuCategory":"CLOTHING",
"skuId":654327,
"skuName":"牛仔裤",
"skuPrice":528.0,
"totalNum":1,
"totalPrice":528.0
},
{
"skuCategory":"SPORTS",
"skuId":675489,
"skuName":"跑步机",
"skuPrice":2699.0,
"totalNum":1,
"totalPrice":2699.0
},
{
"skuCategory":"BOOKS",
"skuId":678678,
"skuName":"Java核心技术",
"skuPrice":149.0,
"totalNum":1,
"totalPrice":149.0
}
]
}
Disconnected from the target VM, address: '127.0.0.1:12122', transport: 'socket'
Process finished with exit code 0这里咱们根据总价是否大于100进行分区,还是调用咱们的collect,Collectors为我们提供了一个partitioningBy方法,它就是来做分区用的,partitioningBy它接收一个Predicate。
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());
}分区只是分组的一个特例。
还有一些不太常用的收集器,小伙伴可以点进Collectors里面看看。
接下来我们来看看规约与汇总。

以上两句话就概括出了规约和汇总的本质性区别。那好,让我们来看看什么规约?

咱们有一个List的集合,现在我可以根据这个集合求它的最大值,求它的最小值,包括求集合里所有元素的和。但是它们都有一个共同点就是它们只返回一个数据,它们不会返回另一个集合。这个呢就是规约操作。

我们通过一张图来看看规约操作都干了什么? 可以看到上面的绿色的是集合中的每一个元素,那规约呢,我这里以累加来作为例子,那规约操作就会有一个初始值(0),然后累加第一个集合中的元素生成一个值(3),接着再累加第二个元素再生成一个值(12),接着以此类推,一直到这个流结束完生成的这个值(30),就是这个流累加之后返回的一个结果。那这个就是规约操作的一个本质。
那我们再来看看,reduce接口它的一些参数和意义。

我们可以看到,这个是reduce方法最复杂的接口的定义,第一个参数呢,是初始值。我们上一张图看到的最开始的那个0就是一个初始值,当然,如果我最开始不希望它是0,那我也可以给它赋成别的值作为一个初始值,第二个参数就是计算逻辑,那咱们上一张图的加就是它的计算逻辑,初始值加第一个元素,中间运算的这个加法就是它的计算逻辑,我们再来看第三个参数,并行执行时多个部分结果的合并方式,要说到这个就应该会说到一个分治思想的例子,就是说我这个Stream里面的流中的元素我可以进行一部分一部分的计算,最后再把这个计算进行汇总,这个就是分治思想的体现。以上就是reduce中三个参数的意义。
下面我们再结合一张图看看这三个参数都是干嘛用的。

可以看到右下角的0就是我们说的第一个参数初始值,然后加号就是连个元素进行操作的计算逻辑,再来看红框框起来的两部分,这两部分就是分别进行的并行计算,最后会有一个合并的方式,就是第三个参数。相信通过这张图,大家可以清晰得理解到规约操作都会涉及到哪三个步骤。
接下来让我们通过一个实战来看一看,如何根据一批订单信息,计算平均商品价格。我们来使用最难的这种reduce的三个参数的方法来计算。