目录
布隆过滤器是啥?
布隆过滤器是一种判断某个元素是否存在于某个大量集合的算法。
比如:比如现在有一个集合,保存了10亿个手机号码,现在我要判断某个手机号码是否存在于这个集合中。要怎么判断呢?
- 最简单的方法,就是遍历集合,挨个判断。这种方式对于少量数据可行,但是对于这种海量数据,首先要保存10亿个号码,本身就会浪费大量的空间。更不要说查找效率了,极低。
- 使用Map,通过hash值来进行查找。类似java的HashMap,但是仍然需要将10亿条数据保存起来,很浪费空间。而且,这大量的数据会产生大量的hash冲突,结果就是产生hash冲突的数据,仍然会进行遍历进行挨个比对,这样对内存空间和查询效率的提升,仍然是有限的。
既然上面2种方式对于海量数据不太可行,那么有没有什么更好的方式能解决呢?
布隆过滤器就是为了解决这种问题而产生的。
布隆过滤器底层基于bitmap和若干个hash算法来实现的。所以在了解布隆过滤器之前,首先要了解以下bitmap。
bitmap
bitmap也叫做位图,是一种数据结构。可以理解为是一个很长的数组,每一个数组元素是一个二进制值,非0即1,也就是说bitmap本质上是一个数组,每个数组元素是一个位的值。而每一位的值只能是0或1。
现在我们假设,如果我们将这10亿条数据,通过某种hash算法,判断出每一条数据在该bitmap中的索引,并将该位标记为1。后续如果判断某个数据是否存在时,只需要将该数据也通过同样的方式获得索引位置,然后判断该位的值是否为1,如果为1则存在,如果不为1则不存在。

因为bitmap每一位是一个bit,那么如果通过bitmap来存在10亿个int类型,bitmap的大小为10亿/8/1024/1024 = 0.12G,可以发现通过为位图来表示10亿个整数值仅仅只需要120M大小的空间就可以表示,占用的内存大小大大减少。
但是很遗憾的是,我们上面的假设,是不会产生hash冲突的情况,真实情况是,目前没有一种hash算法可以为每条数据都算出一个唯一的索引并保证不会产生hash冲突。
那么要怎么解决呢?
布隆过滤器的实现方式
布隆过滤器的解决方式就是,通过多个hash算法,为数据算出多个在bitmap中的索引位置,并将这多个索引位置的值都置为1。后续如果判断数据是否存在时,也判断这多个索引位的值是否都为1。如果都为1,则存在,有一个不为1,就说明不存在。这种方式可以大大的降低hash冲突的概率。
不过值得注意的是,布隆过滤器仍然存在一些误判的情况:
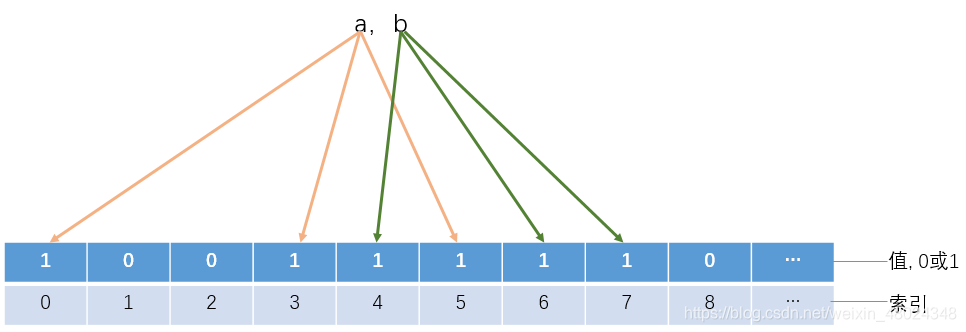
- 虽然使用多个hash算法,可以大大降低hash冲突的概率,但是在海量数据面前,仍然会存在一些极端情况,所以还是会存在hash冲突的可能性。造成误判。
- 还有一种情况,比如上图,加入我现在需要判断数据c是否存在于上面的bitmap中,如果我计算出c在bitmap中的索引位置为: 3、4、5, 但是因为a所计算出的索引位置为0、3、5, b计算出的索引位置是4、6、7。 a和b加起来正好将3、4、5索引位都置为了1,那么c将会被判定为存在于集合中。但是事实是c并不存在这个bitmap中。 这也造成了误判。
这也是布隆过滤器的特点: 存在误判的行为。如果布隆过滤器判断存在,则很有可能存在,有极低的可能不存在。
降低布隆过滤器误判率的方式
- 增加hash算法的数量。
作用:减少hash碰撞的概率(上面第一种情况)。 - 增加bitmap的长度。
作用: 减少hash碰撞的概率(上面第一种情况),减少索引占位重复的概率(上面第二种情况)。
不过需要注意的是:误判率越低,计算效率就会越差,耗费时间就越长。这个需要在实际应用中进行权衡。
总结
- 布隆过滤器是计算一个元素是否在一个超大集合中的算法
- 布隆过滤器如果判断数据存在,则很有可能存在;如果判断数据不存在,则一定不存在
- 降低误判率的方式可以通过增加hash算法或者增加bitmap长度来实现,但是会对计算的效率有影响
- 布隆过滤器不能删除数据, 因为bitmap中的索引位是公用的,删除了一个可能导致连带删除了别的数据的hash索引位,结果就是:这个数据后续判断不存在,但其实是存在的。
布隆过滤器的实现方式
布隆过滤器目前有3种实现方式
- google的 guava
- redisson
- redis的 reBloom.so插件
谷歌Guava实现的布隆过滤器
- 引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
- 代码实现(模拟)
public class BloomFilterService{
private static int size = 10000000;//预计要插入多少数据
private static double fpp = 0.01;//期望的误判率
private BloomFilter<Integer> bf;
/**
*
* 向布隆过滤器中添加数据
*/
public void addToBloomFilter() {
//创建布隆过滤器, 如果不传 fpp参数,默认误判率为0.03
bf = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
// 模拟向布隆过滤器中添加10亿个数据
for(int i =1; i<= size; i++) {
bf.put(i);
}
}
/**
*
* 判断数据是否存在
*/
public boolean exists(int value){
return bf.mightContain(value);
}
}
这种过滤器的实现方式,是将bitmap存储,hash运算都放在了客户端上,由客户端来实现。
基于Redisson的布隆过滤器
- 引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.10.6</version>
</dependency>
- 代码实现
@Service
public class BloomFilterService{
@Autowired
private RedissonClient redissonClient;
private static long size = 10000000L;//预计要插入多少数据
private static double fpp = 0.03;//期望的误判率
// 自定义布隆过滤器的 key
private String BLOOM_FILTER_KEY = "filter";
/**
*
* 向布隆过滤器中添加数据, 模拟向布隆过滤器中添加10亿个数据
*/
public void addToBloomFilter() {
// 获取布隆过滤器
RBloomFilter<Integer> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_KEY);
// 初始化,容量为10亿, 误判率为0.03
bloomFilter.tryInit(size,fpp);
// 模拟向布隆过滤器中添加10亿个数据
for (int i = 1; i <= size; i++) {
bloomFilter.add(i);
}
}
/**
*
* 判断数据是否存在
*/
public boolean contains(int value) {
// 获取布隆过滤器
RBloomFilter<Integer> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_KEY);
// 判断是否存在
return bloomFilter.contains(value);
}
}
这种过滤器的实现方式,是将hash运算都放在了客户端上,由客户端来实现, 而把 bitmap存储放在了redis上,由redis来负责。
基于rebloom的布隆过滤器
- 下载rebloom
git clone git://github.com/RedisLabsModules/rebloom
cd rebloom
make
- 修改redis配置文件,引入rebloom
在redis.conf配置文件中,加入如下配置:
配置reloom文件下的rebloom.so 路径
loadmodule /path/rebloom.so
- 重启redis
- 向过滤器中添加数据
[root@mysql01 ~]# redis-cli
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> BF.add myBloom 1
127.0.0.1:6379> BF.add myBloom 2
- 判断数据是否存在
[root@mysql01 ~]# redis-cli
127.0.0.1:6379>
127.0.0.1:6379> BF.exists myBloom 1
这种过滤器的实现方式,是将hash运算和 bitmap存储都放在了redis上,由redis来负责。
布隆过滤器的使用场景
- 爬给定网址的时候对已经爬取过的URL去重;
- 邮箱的垃圾邮件过滤;
- 黑名单、白名单的校验;
- 海量数据判重;
- 防止缓存穿透,将存在的数据放到布隆过滤器中,当访问不存在的数据时迅速返回,避免穿透进入数据库查询。
布隆过滤器的其他进阶实现
- Counting Bloom Filter
- Spectral Bloom Filter
- Dynamic Count Filter
以上三种过滤器的实现,参考:Bloom Filter 系列改进实现