传统推荐模型——协同过滤
协同过滤(附代码)
一、概述
基本思想:
物以类聚,人以群分
目标场景:
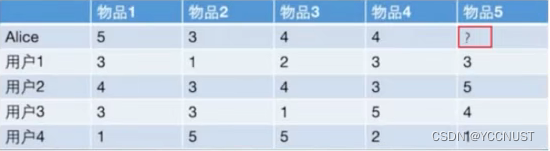
用户对物品打分的情况,其中Alice未打分
通过其他的信息,来预测打分情况
方法:
1、基于User的协同过滤(UserCF)
找到跟Alice相似的用户A,根据用户A对物品5的打分,Alice与之相同
2、基于Item的协同过滤(ItemCF)
找到跟物品5相似的其他的物品B,根据Alice对物品B的打分,对物品5的打分与之相同
二、相似度计算公式
1、杰卡德相似度
衡量两个集合之间的相似度一种指标,A和B集合的相似度
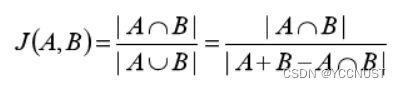
2、余弦相似度
衡量用户向量
i
,
j
i,j
i,j之间的向量夹角大小,夹角越小,余弦值越大,相似度越大
推广到多个样本的相似度度量公式:
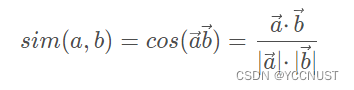
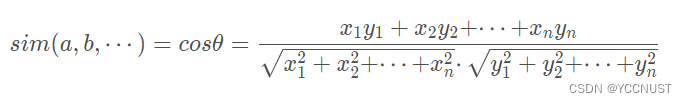
局限性:针对评分数据不规范时,例如有的用户习惯打高分或者低分,结果不准确
API:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
vec1 = np.array([1, 2, 3, 4])
vec2 = np.array([5, 6, 7, 8])
cos_sim = cosine_similarity(vec1.reshape(1, -1), vec2.reshape(1, -1))
print(cos_sim[0][0])
3、皮尔逊相关系数
皮尔逊相关系数是一种度量两个变量间相关程度的方法。它是一个介于 1 和 -1 之间的值,其中,1 表示变量完全正相关, 0 表示无关,-1 表示完全负相关
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
API:`
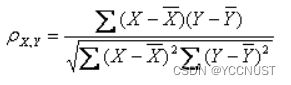
i=[1,0,0,0]
j=[1,0.5,0.5,0]
a=pearsonr(i,j)
4、欧式距离
是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
那距离是如何反映出相似度的呢,很简单,我们总是希望相似度越大返回的值越大。所以我们取距离的倒数即可(因为距离越大相似度越小),又因为分母不能为0,所以我们往往取函数值加1的倒数。
三、基于User的协同过滤
一、
每一行的值都是用户各自的向量表示
二、
计算Alice与其他用户的相似度:

三、
通过预测函数公式来计算最终评分:
四、
代码:

import numpy as np
from math import sqrt
'''
用户/物品 | 物品a | 物品b | 物品c | 物品d
用户A | √ | | √ |
用户B | √ | √ | | √
用户C | √ | √ | √ | √
'''
def consine(ls_1,ls_2,m):
fenzi = 0
fenmu1 = 0
fenmu2 = 0
for i in range(m):
fenzi += ls_1[i] * ls_2[i]
fenmu1 += ls_1[i] * ls_1[i]
fenmu2 += ls_2[i] * ls_2[i]
# print("\n")
fenmu = sqrt(fenmu1) * sqrt(fenmu2)
return fenzi/fenmu
#预测函数
def predict(w,r=1):
p=w*r
return p
if __name__ == "__main__":
user_item=np.array([[1,0,1,0],
[1,1,0,1],
[1,1,1,1]])
print("用户矩阵")
print(user_item)
user = ['用户A', '用户B', '用户C']
item = ['物品a', '物品b', '物品c', '物品d']
n = len(user) # n 个用户
m = len(item) # m 个物品
#利用余弦相似度构建用户相似度矩阵
sim=np.zeros((n,n))#初始化n行n列,默认为0
for i in range(n):
for j in range(n):
if i<j:
sim[i][j]=consine(user_item[i],user_item[j],m)
sim[j][i] = sim[i][j] #这里顺序不能改变 赋值的关系
print(sim[i][j])
print("用户相似度矩阵")
print(sim)
#预测用户评分
max_sim = [0, 0, 0] # 存放每个用户的相似用户
r_list = [[], [], []] # 存放推荐给每个用户的物品
p = [[], [], []] # 每个用户被推荐物品的预测值列表
for i in range(n): # n 个用户循环 n 次
# 找到与用户 i 最相似的用户
for j in range(len(sim[i])): # range () 里面写 n 也可以,二者等同
if max(sim[i]) != 0 and sim[i][j] == max(sim[i]):#max代表最大值
max_sim[i] = user[j] # 此时的 j 就是相似用户的编号
break # break 目的:一是结束当前循环,二是当前的 j 后面有用
if max_sim[i] == 0:
continue # 等于 0,表明当前用户无相似用户,无需推荐,继续下个用户
# 找出应该推荐的物品,并计算预测值
K=1
for k in range(K): # 为了更契合预测值计算公式,因为这里 K=1,所以也可以省去这个 for
for x in range(m): # m 个物品循环 m 次
if user_item[i][x] == 0 and user_item[j][x] == 1: # 目标用户不知道,而相似用户知道
r_list[i].append(item[x])
p[i].append(predict(sim[i][j]))
# 打印结果
for i in range(n): # n 个用户循环 n 次
if len(r_list[i]) > 0: # 当前用户有被推荐的物品
print("向{:}推荐的物品有:".format(user[i]), end='')#end的作用是防止光标移动到下一行
print(r_list[i])
print("该用户对以上物品该兴趣的预测值为:", end='')
print(p[i])
print()#输出一行,即换行
向用户A推荐的物品有:['物品b', '物品d']
##结果:
用户矩阵
[[1 0 1 0]
[1 1 0 1]
[1 1 1 1]]
用户相似度矩阵
[[0. 0.40824829 0.70710678]
[0.40824829 0. 0.8660254 ]
[0.70710678 0.8660254 0. ]]
向用户A推荐的物品有:['物品b', '物品d']
该用户对以上物品该兴趣的预测值为:[0.7071067811865475, 0.7071067811865475]
向用户B推荐的物品有:['物品c']
该用户对以上物品该兴趣的预测值为:[0.8660254037844387]
五、
适用场景:用户少,物品多,时效性强
四、基于Item的协同过滤
图解
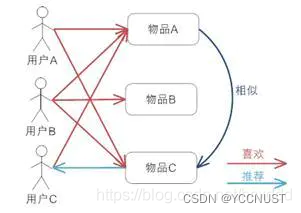
每一列的值都是物品各自的向量表示
算法过程实现
一、
依旧建立用户—物品矩阵:
用户A:物品A、物品C(1,0,1)
用户B:物品A、物品C(1,0,1)
用户C:物品A、物品B(1,1,0)
二、
建立物品—用户倒排表
物品 a:用户 A、用户 B、用户 C(1,1,1)
物品 b:用户 C (0,0,1)
物品 c:用户 A、用户 B(1,1,0)
三、
计算物品之间相似度(利用余弦相似定理):
简而言之:预测值=最相似的物品的相似度*用户对其最相似物品的打分
三、
代码:



import numpy as np
from math import sqrt
'''
用户/物品 | 物品a | 物品b | 物品c
用户A | √ | | √
用户B | √ | | √
用户C | √ | √ |
'''
#余弦相似度求相似
def consine(ls_1,ls_2,m):
fenzi = 0
fenmu1 = 0
fenmu2 = 0
for i in range(m):
fenzi += ls_1[i] * ls_2[i]
fenmu1 += ls_1[i] * ls_1[i]
fenmu2 += ls_2[i] * ls_2[i]
fenmu = sqrt(fenmu1) * sqrt(fenmu2)
return fenzi/fenmu
#预测函数
def predict(w,r=1):
p=w*r
return p
#主函数
if __name__ == "__main__":
user_item = np.array([[1, 0, 1],
[1, 0, 1],
[1,1, 0]])
print("用户-物品矩阵:")
print(user_item) # 打印用户-物品矩阵
user = ['用户A', '用户B', '用户C']
item = ['物品a', '物品b', '物品c']
n = len(user) # n 个用户
m = len(item) # m 个物品
#建立物品 - 用户倒排表
item_user = user_item.T #求转置即可
print("物品-用户矩阵:")
print(item_user)
#构建物品 - 物品相似度矩阵
sim = np.zeros((n, n)) # 相似度矩阵,默认全为 0
for i in range(n):
for j in range(n):
if i < j:
sim[i][j] = consine(item_user[i], item_user[j], m) # 用到了前面定义的函数
sim[j][i] = sim[i][j] # 代表用户顺序不同但相似度一样
print("得到的物品-物品相似度矩阵:")
print(sim) # 打印物品 - 物品相似度矩阵
# 推荐物品
max_sim = [0, 0, 0] # 存放每个物品的相似物品
r_list = [[], [], []] # 存放推荐给每个用户的物品
p = [[], [], []] # 每个用户被推荐物品的预测值列表
for i in range(m): # m 个物品循环 m 次
# 找到与物品 i 最相似的物品
for j in range(len(sim[i])): # range () 里面写 m 也可以,二者等同
if max(sim[i]) != 0 and sim[i][j] == max(sim[i]): # max代表最大值
max_sim[i] = item[j] # 此时的 j 就是相似物品的编号
break # break 目的:一是结束当前循环,二是当前的 j 后面有用
if max_sim[i] == 0:
continue # 等于 0,表明当前物品无相似物品,继续下个物品
# 找出应该推荐的物品,并计算预测值
K=1
for k in range(K): # 为了更契合预测值计算公式,因为这里 K=1,所以也可以省去这个 for
for x in range(n): # n 个用户循环 n 次
if item_user[i][x] == 1 and item_user[j][x] == 0: # 当前物品用户知道,而相似物品该用户不知道
r_list[x].append(max_sim[i])
p[x].append(predict(sim[i][j]))
# 打印结果
for i in range(n): # n 个用户循环 n 次
if len(r_list[i]) > 0: # 当前用户有被推荐的物品
print("向{:}推荐的物品有:".format(user[i]), end='') # end的作用是防止光标移动到下一行
print(r_list[i])
print("该用户对以上物品该兴趣的预测值为:", end='')
print(p[i])
print() # 输出一行空白,即换行
用户-物品矩阵:
#结果:
[[1 0 1]
[1 0 1]
[1 1 0]]
物品-用户矩阵:
[[1 1 1]
[0 0 1]
[1 1 0]]
得到的物品-物品相似度矩阵:
[[0. 0.57735027 0.81649658]
[0.57735027 0. 0. ]
[0.81649658 0. 0. ]]
向用户C推荐的物品有:['物品c']
该用户对以上物品该兴趣的预测值为:[0.8164965809277259]
三、
所以Item相似矩阵维度小
使用场景:适用于电商平台User数量远远大于Item数量的应用场景,

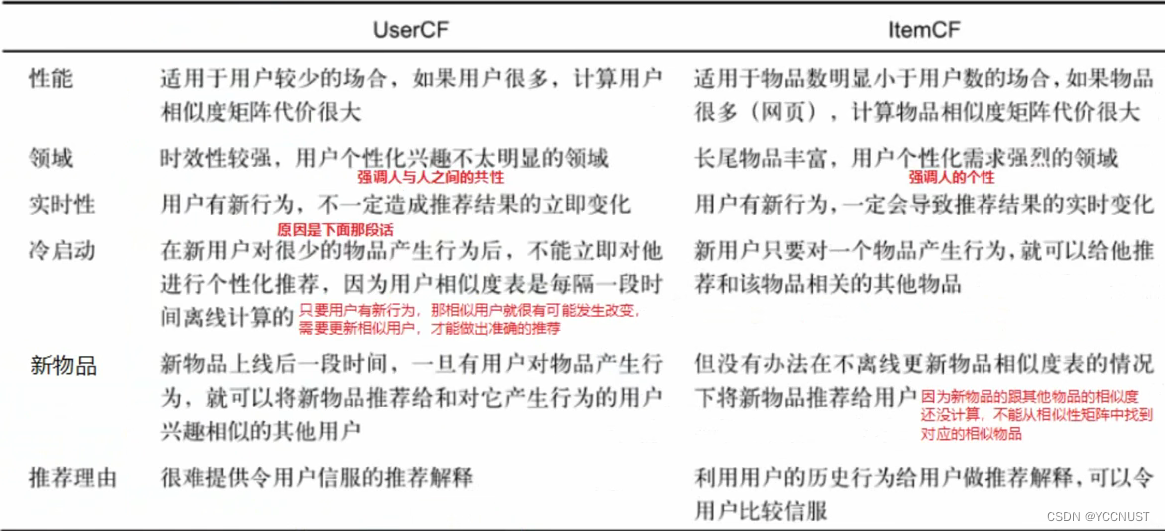
五、UserCF vs ItemCF
区别:
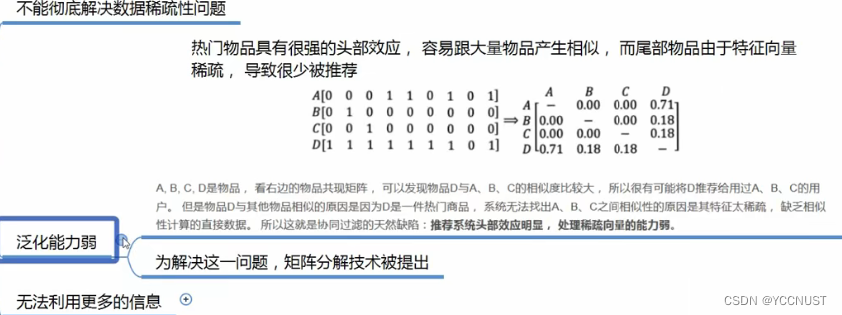
缺点: