知识点
基本流程
- 确定基本流程和假设,确认做这个功能是为了提升/降低什么指标。
- 开发相关功能
- 设计分层实验,进行流量分配。通过PowerAnalysis计算最小样本量。
- 实验达到最小样本量后,进行SRM检验,检验分流是否符合预期,若不符合预期,则回去检查分流系统正确性。
- 若通过SRM检验,进行效果分析,得出实验结论。
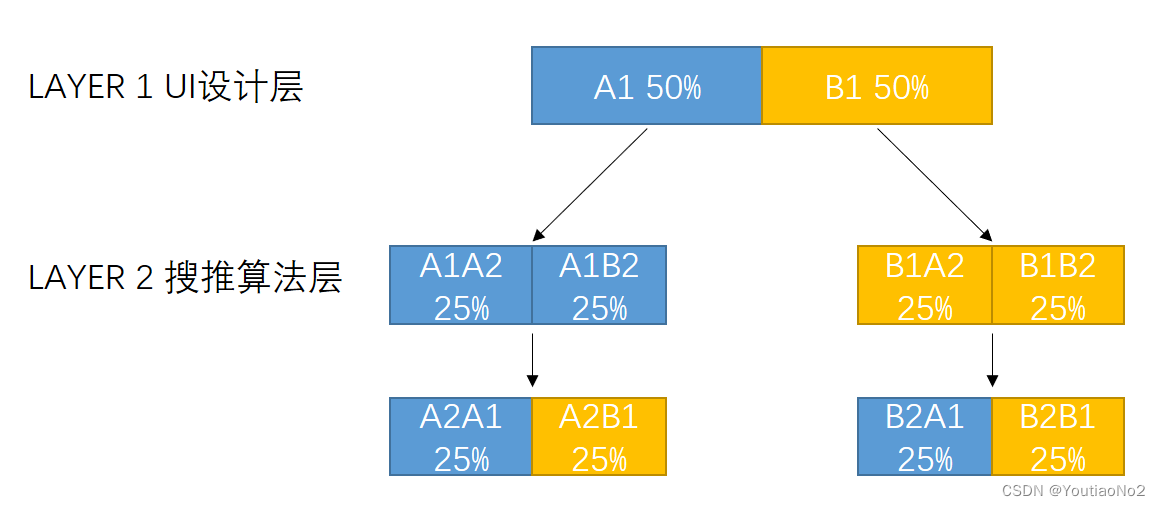
实验分层问题
- 流量正交要求层与层之间必须相互独立。
- 同一层可以有多个实验,但流量不能有交集。
- 一般采用MD5哈希算法来进行ID的分流。
最小样本量计算
均值类
- 实验采用双边检验,原假设如下:
H 0 : μ A − μ B = 0 H 1 : μ A − μ B ≠ 0 \begin{align*} H_0: \mu_{A}-\mu_{B}=0 \\ H_1: \mu_{A}-\mu_{B}\neq0 \end{align*} H0:μA−μB=0H1:μA−μB=0 - 样本计算公式如下:
n A = k n B n B = ( 1 + 1 k ) ( σ z 1 − α 2 + z 1 − β μ A − μ B ) 2 n_{A} = kn_{B} \ \ n_{B} = (1+\frac{1}{k})(\sigma\frac{z_{1-\frac{\alpha}{2}}+z_{1-\beta}}{\mu_{A}-\mu_{B}})^2 nA=knB nB=(1+k1)(σμA−μBz1−2α+z1−β)2
其中, μ B \mu_{B} μB是当前的数据, μ A \mu_{A} μA是预期改进后的数据值。k为 n A n_{A} nA和 n B n_{B} nB的比值,这个值一般情况下,我们都默认为1,即AB两组样本量相等,方便做严谨的实验对比, σ \sigma σ需要根据历史数据估计。 - 因此,计算均值类指标的最小样本量需要如下变量
- α \alpha α,显著性水平
- β \beta β,第二类错误
- δ \delta δ,预期提升值( μ A − μ B \mu_{A}-\mu_{B} μA−μB)
- σ , μ B \sigma, \mu_{B} σ,μB,历史均值和标准差
同样的,根据已有的参数,我们也可以估计统计的功效
β
\beta
β是多少,若功效不足,也无法得到实验结论:
1
−
β
=
Φ
(
z
−
z
1
−
α
2
)
+
Φ
(
−
z
−
z
1
−
α
2
)
,
z
=
μ
A
−
μ
B
σ
1
n
A
+
1
n
B
1-\beta = \Phi(z-z_{1-\frac{\alpha}{2}}) + \Phi(-z-z_{1-\frac{\alpha}{2}}) , z = \frac{\mu_{A}-\mu_{B}}{\sigma \sqrt {\frac{1}{n_{A}}+\frac{1}{n_{B}}}}
1−β=Φ(z−z1−2α)+Φ(−z−z1−2α),z=σnA1+nB1μA−μB
比值类
- 实验采用双边检验,原假设如下:
H 0 : p A − p B = 0 H 1 : p A − p B ≠ 0 \begin{align*} H_0: p_{A}-p_{B}=0 \\ H_1: p_{A}-p_{B}\neq0 \end{align*} H0:pA−pB=0H1:pA−pB=0 - 样本计算公式如下:
n A = k n B n B = ( p B ( 1 − p B ) + p A ( 1 − p A ) k ) ( z 1 − α 2 + z 1 − β p A − p B ) 2 n_{A} = kn_{B} \ \ n_{B} = (p_{B}(1-p_{B})+\frac{p_{A}(1-p_{A})}{k})(\frac{z_{1-\frac{\alpha}{2}}+z_{1-\beta}}{p_{A}-p_{B}})^2 nA=knB nB=(pB(1−pB)+kpA(1−pA))(pA−pBz1−2α+z1−β)2
其中, p B p_{B} pB是当前的数据, p A p_{A} pA是预期改进后的数据值。k为 n A n_{A} nA和 n B n_{B} nB的比值,这个值一般情况下,我们都默认为1,即AB两组样本量相等,方便做严谨的实验对比,跟均值有所不同的是,比值类无需计算方差。 - 因此,计算均值类指标的最小样本量需要如下变量
- α \alpha α,显著性水平
- β \beta β,第二类错误
- δ \delta δ,预期提升值( p A − p B p_{A}-p_{B} pA−pB)
- p B p_{B} pB,历史均值
同样的,根据已有的参数,我们也可以估计统计的功效
β
\beta
β是多少,若功效不足,也无法得到实验结论:
1
−
β
=
Φ
(
z
−
z
1
−
α
2
)
+
Φ
(
−
z
−
z
1
−
α
2
)
,
z
=
p
A
−
p
B
p
A
(
1
−
p
A
)
n
A
+
p
B
(
1
−
p
B
)
n
B
1-\beta = \Phi(z-z_{1-\frac{\alpha}{2}}) + \Phi(-z-z_{1-\frac{\alpha}{2}}) , z = \frac{p_{A}-p_{B}}{\sqrt {\frac{p_{A}(1-p_{A})}{n_{A}}+\frac{p_{B}(1-p_{B})}{n_{B}}}}
1−β=Φ(z−z1−2α)+Φ(−z−z1−2α),z=nApA(1−pA)+nBpB(1−pB)pA−pB
- 在计算得到最小样本量公式后,根据流量的分配及每日流入的用户数,估算需要天数。理论上需要涵盖完整行为周期(视情况而定,有一定的时间成本)。
SRM检验
- Sample Ratio Mismatch Test,简称样本分流不一致检验。主要检验实验人数分流是否符合预期。
- 卡方检验:
- 卡方检验,主要有两种用途。1. 推断总体分布与期望分布是否一致。 (test of goodness-of-fit) 2. 推断两个分类变量是否相关或独立。(test of independence/homogenetity) 实验中,主要用来做第一种检验。
- 其原假设为:观察频数与期望频数没有差别。
- 计算公式:
χ 2 = ∑ ( f o − f e ) 2 f e \chi^2 = \sum\frac{(f_{o}-f_{e})^2}{f_{e}} χ2=∑fe(fo−fe)2
其中 f o f_{o} fo为实际观测值, f e f_{e} fe为期望值。df 为number of groups - 1。
指标检验
比值类
z = p 1 − p 2 p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 z = \frac{p_1-p_2}{\sqrt{\frac{p_1(1-p_1)}{n_1}+\frac{p_2(1-p_2)}{n_2}}} z=n1p1(1−p1)+n2p2(1−p2)p1−p2
均值类
- 首先要进行方差齐性检验:
H 0 H_0 H0:对照组和实验组方差一致
H 1 H_1 H1:对照组和实验组方差不一致
F = s 1 2 s 2 2 F = \frac{s_1^2}{s_2^2} F=s22s12
根据F值计算P值,理论上只有在方差一致的情况下才能进行配对t检验。方差不一致时,可以对t检验做一些调整来计算。 - 两个总体方差未知但相等:
t = x 1 ˉ − x 2 ˉ s p 2 n 1 + s p 2 n 2 s p 2 = ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2 n 1 + n 2 − 2 t = \frac{\bar{x_1}-\bar{x_2}}{\sqrt{\frac{s_{p}^2}{n_1}+\frac{s_{p}^2}{n_2}}} \ \ \ s_{p}^2 = \frac{(n_1-1)s_1^2+(n_2-1)s_2^2}{n_1+n_2-2} t=n1sp2+n2sp2x1ˉ−x2ˉ sp2=n1+n2−2(n1−1)s12+(n2−1)s22
df 为 n 1 + n 2 − 2 n_1+n_2-2 n1+n2−2。 - 两个总体方差未知且不等:
此时抽样已不服从自由度为 ( n 1 + n 2 − 2 ) (n_1+n_2-2) (n1+n2−2)的t分布,而是近似服从自由度为f的t分布,f的计算公式:
f = ( s 1 2 n 1 + s 2 2 n 2 ) 2 ( s 1 2 n 1 ) 2 n 1 − 1 + ( s 2 2 n 2 ) 2 n 2 − 1 t = x 1 ˉ − x 2 ˉ s 1 2 n 1 + s 2 2 n 2 f = \frac{(\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2})^2}{\frac{(\frac{s_1^2}{n_1})^2}{n_1-1}+\frac{(\frac{s_2^2}{n_2})^2}{n_2-1}} \ \ \ t = \frac{\bar{x_1}-\bar{x_2}}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}} f=n1−1(n1s12)2+n2−1(n2s22)2(n1s12+n2s22)2 t=n1s12+n2s22x1ˉ−x2ˉ
df为f
关于统计检验显著性问题
- 在实际业务中,统计指标显著性是一个重要参考,但并非决定因素,还取决于业务上的判断。
- 关于样本量太大导致实验组和对照组间细微的变化也会显著的解决方案:
- 计算当前样本量/最小样本量= n, 然后将实验指标的检验变的更加严格, 即使用 α n e w = α / n \alpha_{new} = \alpha/n αnew=α/n
- 在样本中随机采样出最小所需样本量,进行统计分析。
- 以上均是可能的解决方案,并没有严格的理论支持。
参考资料
- http://powerandsamplesize.com/Calculators/Compare-2-Proportions/2-Sample-Non-Inferiority-or-Superiority
- https://www.microsoft.com/en-us/research/group/experimentation-platform-exp/articles/diagnosing-sample-ratio-mismatch-in-a-b-testing/
- 统计学习方法,贾俊平
- https://www.evanmiller.org/ab-testing/sample-size.html
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4296634/