数据库系统概论(第6版)王珊,杜小勇,陈红编著
目录
一、SQL概述
1974年IBM为关系DBMS设计一种查询语言,先在IBM公司的关系数据库系统System R上实现,当时称为SEQUEL,后简称为结构化查询语言SQL(StructuredQuery Language)。
SQL 是用户操作关系数据库的通用语言。
SQL已经成为关系数据库的标准语言, 现在所有的关系数据库管理系统都支持SQL。
1.1 SQL 的产生与发展
| 标准 | 篇幅(约)/页 | 发布日期/年 | 标准 | 大致页数 | 发布日期/年 |
| SQL 86 | 1986年 | SQL 2003 | 3 600 | 2003 | |
| SQL 89(FIPS 127-1) | 120页 | 1989年 | SQL 2008 | 3 777 | 2008 |
| SQL 92 | 622页 | 1992年 | SQL 2011 | 3817 | 2011 |
| SQL 99(SQL 3) | 1700页 | 1999年 | SQL2016 | 4035 | 2016 |
SQL 86和SQL 89是单个文档。
SQL 92和SQL 99扩展为一系列开放的部分。例如,SQL 92增加了SQL调用接口、SQL永久存储模块;
SQL 99扩展为框架、SQL基础部分、SQL调用接口、SQL永久存储模块、SQL宿主语言绑定、SQL外部数据的管理和SQL对象语言绑定等
SQL2016扩展到了12个部分,引入XML类型、Window函数、TRUNCATE操作、时序数据以及JSON(JavaScript Object Notation)类型等
目前,没有一个关系数据库管理系统能够支持SQL标准的所有概念和特性
1.2 SQL的特点
1.功能综合且风格统一
集数据定义语言(DDL),数据操纵语言(DML),数据控制语言(DCL)功能于一体。
2. 数据操纵高度非过程化
SQL只要提出“做什么”,无须了解存取路径 存取路径的选择以及SQL的操作过程由系统自动完成
层次、网状模型的数据操纵语言面向过程,必须指定存取路
3. 面向集合的操作方式
SQL采用集合操作方式
操作对象、查找结果可以是元组的集合
一次插入、删除、更新操作的对象也可以是元组的集合
层次、网状模型采用面向记录的操作方式,操作对象是一条记录
4. 以统一的语法结构提供多种使用方式
SQL是独立的语言,能够独立地用于联机交互的使用方式
SQL能够嵌入到高级语言(例如C、C++、Java、Python)程序中,供程序员设计程序时使用
5.语言简洁且易学易用
SQL功能极强,完成核心功能只用9个动词
| SQL 功能 | 动词 |
| 数据定义 | CREATE,DROP,ALTER |
| 数据查询 | SELECT |
| 数据操纵 | INSERT,UPDATE,DELETE |
| 数据控制 | GRANT,REVOKE |
缺点:缺少流程控制能力
1.3 SQL的基本概念
SQL支持关系数据库三级模式

外模式是用户能够看见和 使用的数据结构——视图,部分基本表
模式——基本表
内模式——存储文件
(1)基本表
基本表是数据库中直接存储数据的表,用于保存原始数据,是数据的基本存储单元。
- 关系数据库管理系统中一个关系就对应一个基本表
- 本身独立存在的表 【独立存在】
- 一个或多个基本表对应一个存储文件 【物理存储数据】
- 一个表可以带若干索引 【索引查询】
(2)存储文件
存储文件是数据库的物理结构,包含了数据的实际存储形式。
存储文件的逻辑结构与物理结构组成了关系数据库的内模式
物理文件结构是由数据库管理系统(DBMS)设计确定的
(3)视图
- 从基本表或其他视图中导出的表,是一个虚表;
- 数据库中只存放视图的定义而不存放视图对应的数据 【虚拟存储】
- 用户可以在视图上再定义视图
用户可以对基本表和视图进行查询和其他操作
基本表和视图都是关系
二、数据定义
SQL的数据定义功能:
课本:
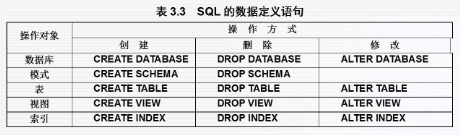
| 操作对象 | 操作方式 | ||
| 创建 | 删除 | 修改 | |
| 数据库模式 | CREATE SCHEMA | DROP SCHEMA | *SQL标准无修改语句 |
| 表 | CREATE TABLE | DROP TABLE | ALTER TABLE |
| 视图 | CREATE VIEW | DROP VIEW | |
| 索引 | *CREATE INDEX | *DROP INDEX | *ALTER INDEX |

- 一个关系数据库管理系统的实例中可以建立多个数据库
- 一个数据库中可以建立多个模式
- 一个模式下通常包括多个表、视图和索引等数据库对象
2.1 数据库的定义
SSMS 菜单操作将具体在另一篇文章中讲解,本篇重点在SQL 语句
以创建一个名为 "EDUC" 的学籍管理系统数据库为例:
(1)SQL 语句创建数据库
CREATE DATABASE <数据库名>
[ON [PRIMARY] (路径/文件大小)]
CREATE DATABASE:这是用于创建数据库的命令。
<数据库名>:这是要创建的数据库的名称。名称不能与现有数据库的名称重复。
ON:可选,用于指定数据库的数据文件和日志文件的存储位置。
PRIMARY:这是默认的文件组,用于指定主数据文件的位置。在 SQL Server 中,数据文件可以分布在多个文件组中,PRIMARY 是每个数据库必有的文件组。
(路径/文件大小):用于定义主数据文件的具体位置和大小。
示例:
CREATE DATABASE MyDatabase
ON PRIMARY (
NAME = MyDatabase_Data,
FILENAME = 'C:\Data\MyDatabase.mdf',
SIZE = 10MB,
MAXSIZE = 100MB,
FILEGROWTH = 5MB
)
LOG ON (
NAME = MyDatabase_Log,
FILENAME = 'C:\Data\MyDatabase_log.ldf',
SIZE = 5MB,
MAXSIZE = 50MB,
FILEGROWTH = 1MB
);
各参数解释:
NAME:数据文件的逻辑名称
FILENAME:数据文件的物理路径和文件名【存储文件的位置】
SIZE:数据文件的初始大小
MAXSIZE:指定数据文件的最大容量
FILEGROWTH:指定数据文件的增长步长
(2)修改数据库的名称
修改数据库的名称操作的基本语法格式为:
ALTER DATABASE <原数据库名>
MODIFY NAME = <新数据库名>
-
ALTER DATABASE:声明要修改数据库;是 SQL Server 用来修改数据库属性的命令 -
MODIFY NAME:表示要修改数据库的名称。MODIFY:修改现有的数据库属性,NAME:属性中的名称部分
(3)SQL 语句删除数据库
SQL 删除数据库的语法:
DROP DATABASE 数据库名;
如果想一次删除多个数据库,可以在 DROP DATABASE 后面列出多个数据库名称,数据库名称之间用逗号分隔
DROP DATABASE 数据库名1, 数据库名2;
DROP DATABASE 会永久删除数据库及其所有数据,无法通过 SQL Server 自行恢复数据(除非有备份)

DROP DATABASE <数据库名> [CASCADE | RESTRICT] 是一种更高级的数据库删除方式,在某些数据库管理系统中支持。然而,SQL Server 本身并不直接支持这两个选项(CASCADE 和 RESTRICT)
在 SQL Server 中,如果你尝试删除一个仍有连接或活动对象的数据库,会得到一个错误。SQL Server 的默认行为等同于
RESTRICT。没有明确的CASCADE或RESTRICT关键字
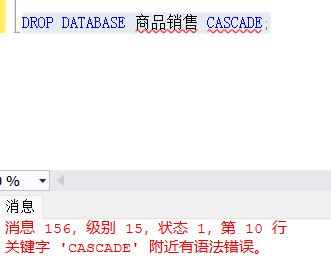
1. CASCADE(级联删除)
CASCADE 选项在删除数据库时,会自动删除与该数据库相关的所有对象,包括表、视图、索引、触发器等。执行此操作后,所有相关的数据库对象会一并删除,不可恢复。
DROP DATABASE 数据库名 CASCADE;
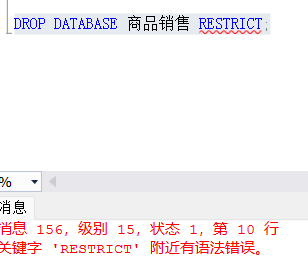
2. RESTRICT(约束式删除)【默认】
RESTRICT 选项会在数据库非空时拒绝删除操作。只有在数据库中没有任何对象(如表、视图、索引等)时,才能删除该数据库。该选项是大多数数据库系统删除操作的默认行为。
DROP DATABASE 数据库名 RESTRICT;
在 SQL Server 中,没有显式的 RESTRICT 选项,默认情况下 SQL Server 也是在非空时禁止删除

2.2 数据表的定义
在创建一个 SQL 数据库后,接下来可以使用 SQL 语言在数据库中创建基本表。创建表时,必须考虑列的名称、数据类型、长度、小数位数、主键、外键等约束,以保证数据的完整性和高效性
CREATE TABLE 表名 (
列名1 数据类型 [列约束],
列名2 数据类型 [列约束],
...
[表级约束]
);
-
列名:每个列的名称【清晰表达,尽量使用小写或驼峰命名法(
firstName)】 -
数据类型:指定每列可以存储的类型【域的概念】
| 数据类型 | 含义 |
| CHAR(n), CHARACTER(n) | 长度为n的定长字符串 |
| VARCHAR(n), CHARACTERVARYING(n) | 最大长度为n的变长字符串 |
| CLOB | 字符串大对象 |
| BLOB | 二进制大对象 |
| INT,INTEGER | 整数(4字节),取值范围是[-2147483648,2147483647] |
| SMALLINT | 短整数(2字节),取值范围是[-32768,32767] |
| BIGINT | 大整数(8字节),取值范围是[-2^63,2^63-1] |
| NUMERIC(p, d) | 定点数,由p位数字(不包括符号、小数点)组成,小数点后面有d位数字 |
| DECIMAL(p,d), DEC(p, d) | 同NUMERIC类似,但数值精度不受p和d的限制 |
| REAL | 取决于机器精度的单精度浮点数 |
| DOUBLE PRECISION | 取决于机器精度的双精度浮点数 |
| FLOAT(n) | 可选精度的浮点数,精度至少为n位数字 |
| BOOLEAN | 逻辑布尔量 |
| DATE | 日期,包含年、月、日,格式为YYYY-MM-DD |
| TIME | 时间,包含一日的时、分、秒,格式为HH:MM:SS |
| TIMESTAMP | 时间戳类型 |
| INTERVAL | 时间间隔类型 |
-
列约束:为列设置特定的规则
-
表级约束:如主键 (
PRIMARY KEY) 和外键 (FOREIGN KEY) 的定义【完整性约束涉及该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级 】
案例 "library" 数据库中,三个数据表的关系模式如下所示,使用 SQL语言建立(定义)三个表: 图书(图书编号。图书名,出版社,作者,价格,出版时间); 售书网站(售书网站编号,名称,所在城市,成立时间) ; 售书(图书编号。售书网站编号,数量)
-- 1. 创建数据库
CREATE DATABASE library;
GO
-- 2. 使用刚创建的库
USE library;
GO
-- 3. 创建图书表 (Books)
CREATE TABLE 图书 (
图书编号 CHAR(5) PRIMARY KEY, -- 图书编号,5个字符,主键
图书名 VARCHAR(50) NOT NULL, -- 图书名,最多50个字符,非空
出版社 VARCHAR(50), -- 出版社,最多50个字符,可空
作者 CHAR(20), -- 作者,最多20个字符,可空
价格 REAL NOT NULL CHECK (价格 > 0 AND 价格 < 100), -- 价格,浮点数,必须在 0 和 100 之间
出版时间 CHAR(10) -- 出版时间,10个字符,可空
);
GO
-- 4. 创建售书网站表 (BookStores)
CREATE TABLE 售书网站 (
售书网站编号 CHAR(6) PRIMARY KEY, -- 售书网站编号,6个字符,主键
名称 VARCHAR(255) NOT NULL, -- 售书网站名称,最多255个字符,非空
所在城市 VARCHAR(100), -- 所在城市,最多100个字符,可空
成立时间 DATE -- 售书网站成立时间
);
GO
-- 5. 创建售书表 (Sales)
CREATE TABLE 售书 (
图书编号 CHAR(5), -- 图书编号,5个字符
售书网站编号 CHAR(6), -- 售书网站编号,6个字符
数量 INT NOT NULL, -- 售书数量,非空
PRIMARY KEY (图书编号, 售书网站编号), -- 联合主键
FOREIGN KEY (图书编号) REFERENCES 图书(图书编号) ON DELETE CASCADE, -- 外键,引用图书表的图书编号,级联删除
FOREIGN KEY (售书网站编号) REFERENCES 售书网站(售书网站编号) ON DELETE CASCADE -- 外键,引用售书网站表的售书网站编号,级联删除
);
GO
在 SQL Server 中,GO 是一个批处理终止符,表示执行该批次的 SQL 语句。
USE library 命令将数据库上下文切换到 library 数据库,接下来所有的操作都在这个数据库中进行
约束:PRIMARY KEY,意味着这是图书表的主键,保证每本书的编号唯一
约束条件:CHECK (价格 > 0 AND 价格 < 100),使用 CHECK 来限制字段的值范围。
价格 REAL NOT NULL DEFAULT 50,
CHECK约束用于限制表中列的值范围,确保数据符合某些规则或条件。当插入或更新数据时,CHECK约束会验证列的值是否满足指定条件,如果不满足条件,则会阻止操作CHECK (条件表达式) CHECK (LEN(名称) >= 3) --确保 名称 字段的长度不能少于 3 个字符。
DEFAULT关键字用于为表中的列指定默认值。当在插入新记录时,如果没有为该列提供值,数据库将使用指定的默认值列名 数据类型 DEFAULT 默认值
PRIMARY KEY (图书编号, 售书网站编号),这里定义了联合主键
外键和级联删除(ON DELETE CASCADE):FOREIGN KEY 约束用于确保引用完整性。通过 FOREIGN KEY,售书 表中的 图书编号 和 售书网站编号 都引用了其他表的主键。这意味着在添加或更新 售书 表中的数据时,必须确保 图书 和 售书网站 中有对应的记录。ON DELETE CASCADE 的作用是,当 图书 表或 售书网站 表中的某一条记录被删除时,相关联的 售书 表中的记录也会被自动删除。这有助于保持数据的一致性,避免孤立的记录。
(2)修改数据表
使用 ALTER TABLE 语句可以对已有的数据表进行结构上的修改
常见的修改操作包括添加列、删除列、修改列的数据类型或约束等
-- 1. 修改数据表,添加新列
ALTER TABLE 表名
ADD 列名 数据类型 [约束];
-- 2. 修改数据表,删除列
ALTER TABLE 表名
DROP COLUMN 列名;
-- 3. 修改数据表,修改列的数据类型
ALTER TABLE 表名
ALTER COLUMN 列名 数据类型 [约束];
在 SQL Server 中,当您向一个已有数据的表添加一个新列时,如果该列被定义为 NOT NULL,那么数据库系统会要求您提供一个默认值;否则,它会将新列填充为 NULL
新列默认为 NULL:在添加新列时,如果未定义默认值,数据库会将该新列的所有现有行的值设置为
NULL,即使新列被定义为NOT NULL。必须提供默认值:如果希望新列能成功添加且不包含
NULL,您必须指定一个默认值。否则,将会导致添加失败
(3)删除数据表
使用 DROP TABLE 语句可以删除整个数据表及其包含的所有数据。
删除操作是不可恢复的,因此在执行此操作时要谨慎。
DROP TABLE 表名;
2.3 模式的定义
(1)创建模式
在 SQL 中,模式(Schema)是一种用于组织和管理数据库对象(如表、视图、存储过程等)的结构。
使用 CREATE SCHEMA 语句可以创建一个新的模式。创建模式可以指定模式的名称和授权用户
CREATE SCHEMA 模式名 AUTHORIZATION 用户名;
示例:为用户 LQ 创建一个名为 S-T 的学生课程模式
CREATE SCHEMA "S-T" AUTHORIZATION LQ; -- 创建名为 "S-T" 的模式,授权给用户 LQ
双引号用于支持模式名称中包含特殊字符(短横线)
AUTHORIZATION LQ:指定模式的拥有者为用户 LQ。这意味着该用户将拥有对该模式中所有对象的控制权限。
(2)模式与表
通过使用 SET search_path 语句,您可以定义数据库在查找对象时的搜索顺序。第一个匹配的模式将被使用。在设置了搜索路径后,创建表而不必指定模式名。系统将使用搜索路径中第一个可用的模式。
-- 设置搜索路径,优先使用模式 "S-T"
SET search_path TO "S-T", PUBLIC;
-- 在当前搜索路径下创建名为 Student 的基本表
CREATE TABLE Student (
StudentID INT PRIMARY KEY, -- 学生编号,主键
Name VARCHAR(50) NOT NULL, -- 学生姓名,非空
Course VARCHAR(50) -- 课程名称
);
相应的实验练习:【SQL实验】数据库、表、模式的SQL语句操作-CSDN博客