【深度学习】ResNet系列网络结构
ResNet中Residual的功能
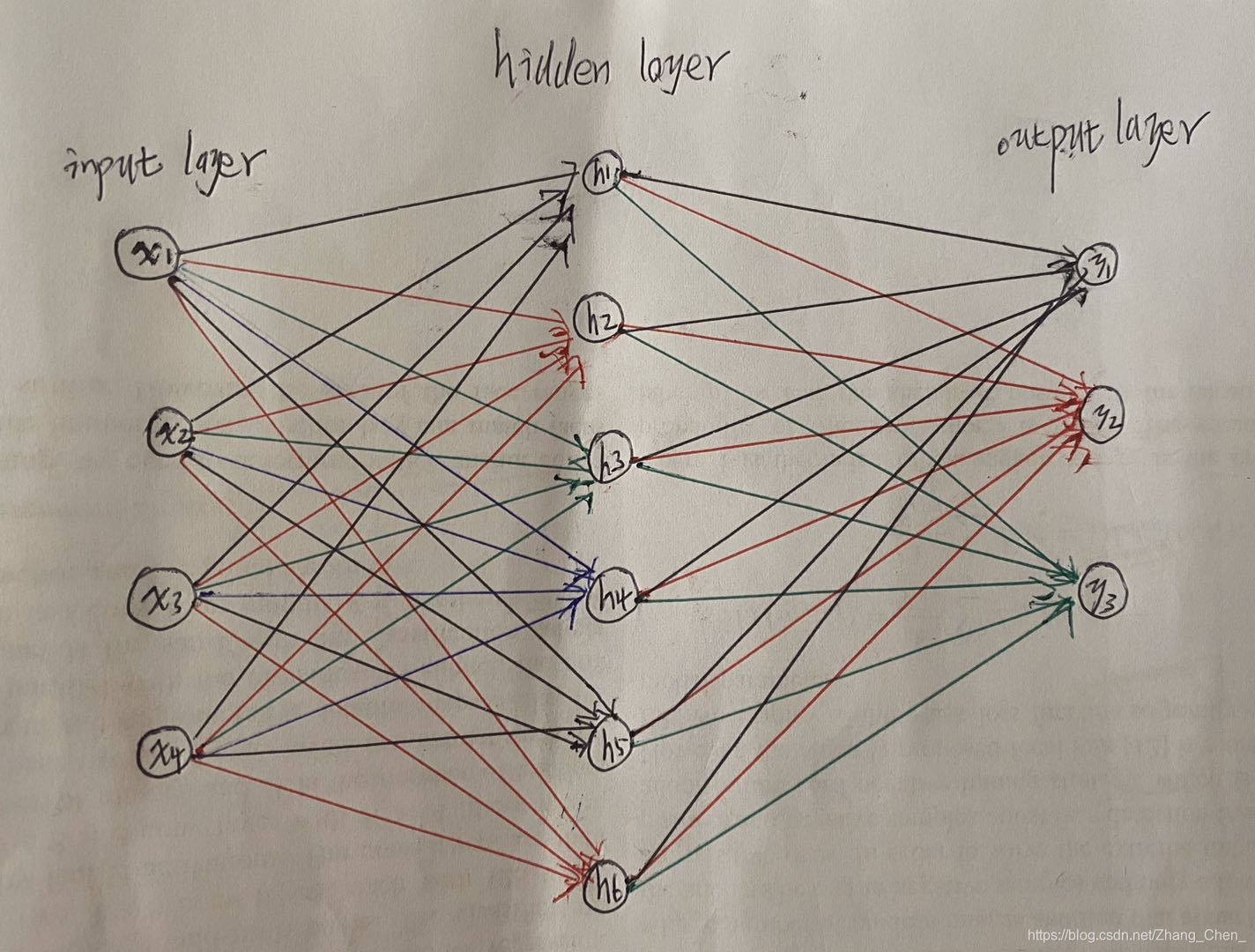
DNN的反向传播算法
-
假设DNN只有一个隐藏层:
-
向前传播得到输出:
-
计算损失函数:
注意当 C C C关于 y j y_j yj求偏导的时候,无论括号中是 y j − z j y_j - z_j yj−zj还是 z j − y j z_j - y_j zj−yj,得到的结果是相同的 -
反向传播更新权重:
为什么是上图中是减法:因为优化的目的是让损失函数最小,也就是 y y y和 z z z最接近。当偏导大于零时,证明损失函数关于权重的函数曲线极小值在 w w w轴左侧,当偏导小于零时,证明损失函数关于权重的函数曲线极小值在 w w w轴右侧。

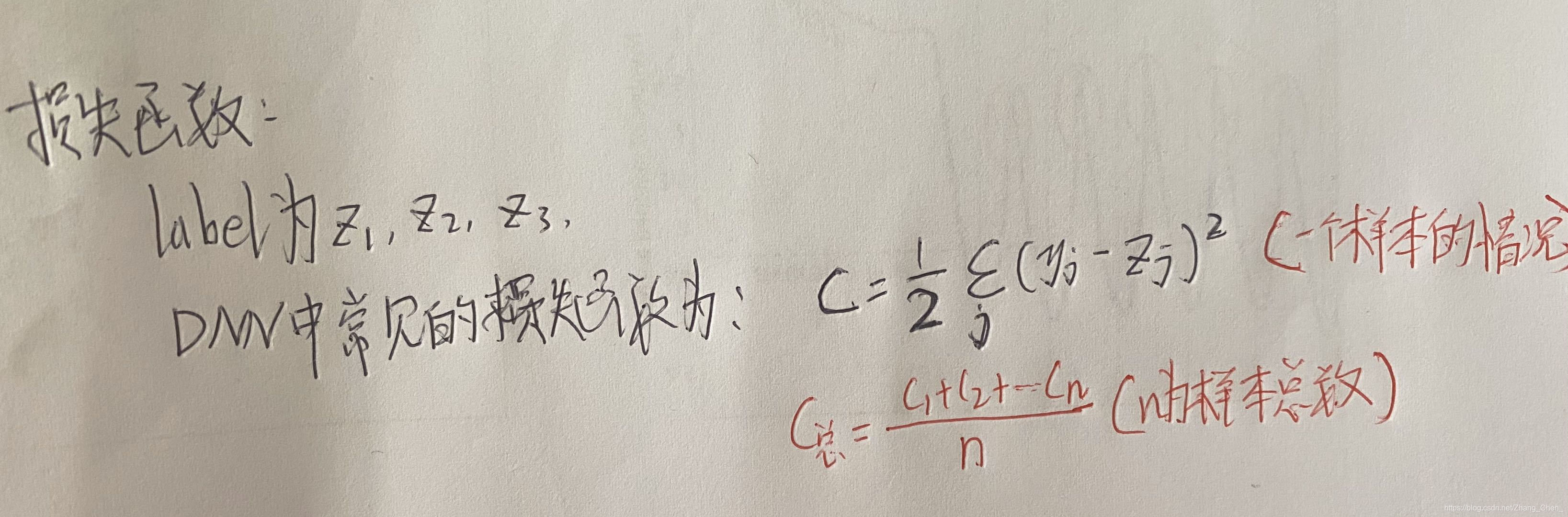

梯度弥散和梯度爆炸
梯度弥散:靠近网络输入端的权重梯度小,得不到更新
梯度爆炸:靠近网络输出端的权重梯度大,更新特别“飞”
无论是梯度弥散还是梯度爆炸,都是靠近网络输出端的梯度大于靠近网络输入端的梯度。因为:
根据上面的反向传播推导可知,从靠近网络输出端向靠近网络输入端,每向后一层,反向传播的偏导计算便多乘一次激活函数的导,以sigmoid函数作为激活函数为例,它的导数是恒小于一的。所以这样反向传播每向后一层,都在累乘小于一的值。所以靠近网络输出端的梯度大于靠近网络输入端的梯度
网络退化
在增加网络层数的过程中,training accuracy 逐渐趋于饱和,继续增加层数,training accuracy 就会出现下降的现象,而这种下降不是由过拟合造成的
ResNet中Residual的功能
残差网络结构的提出,就是解决了随着网络层数的加深,出现的梯度弥散、梯度爆炸、以及网络退化的现象。
换句话说,ResNet的跳接就是为了提高梯度跨block传播的能力
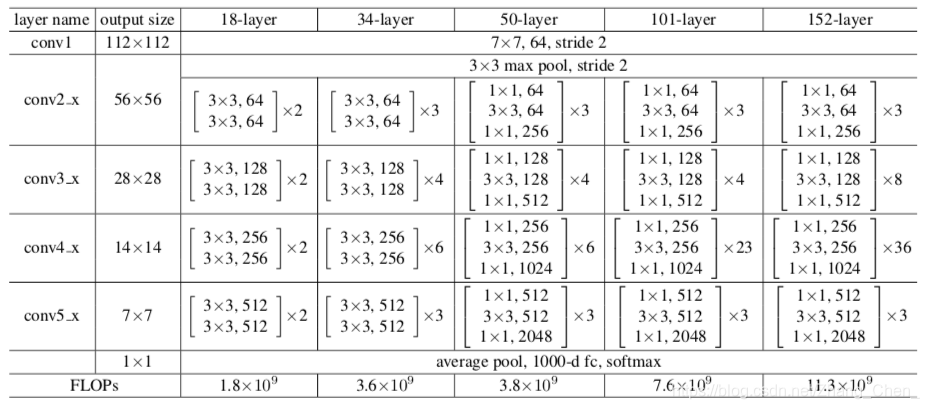
ResNet系列网络结构
注意ResNet的激活函数放在跳接之后
-
上图中输入图片size为(224, 224, 3)
-
经过第一个7x7的卷积层,输出channel为64,步长为2,注意pad为3,即在周围填充三圈
-
经过一个3x3的最大池化层,步长为2,注意pad为1
-
与VGGNet不同的是,ResNet除了一个3x3的最大池化层,其他下采样全都是使用卷积层实现
如上图,我们称 c o n v 2 _ x conv2\_x conv2_x、 c o n v 3 _ x conv3\_x conv3_x、 c o n v 4 _ x conv4\_x conv4_x、 c o n v 5 _ x conv5\_x conv5_x为四个卷积组, c o n v 2 _ x conv2\_x conv2_x的下采样由最大池化层实现,其他三个卷积组的下采样,都是由邻接上一个卷积组的残差块实现:
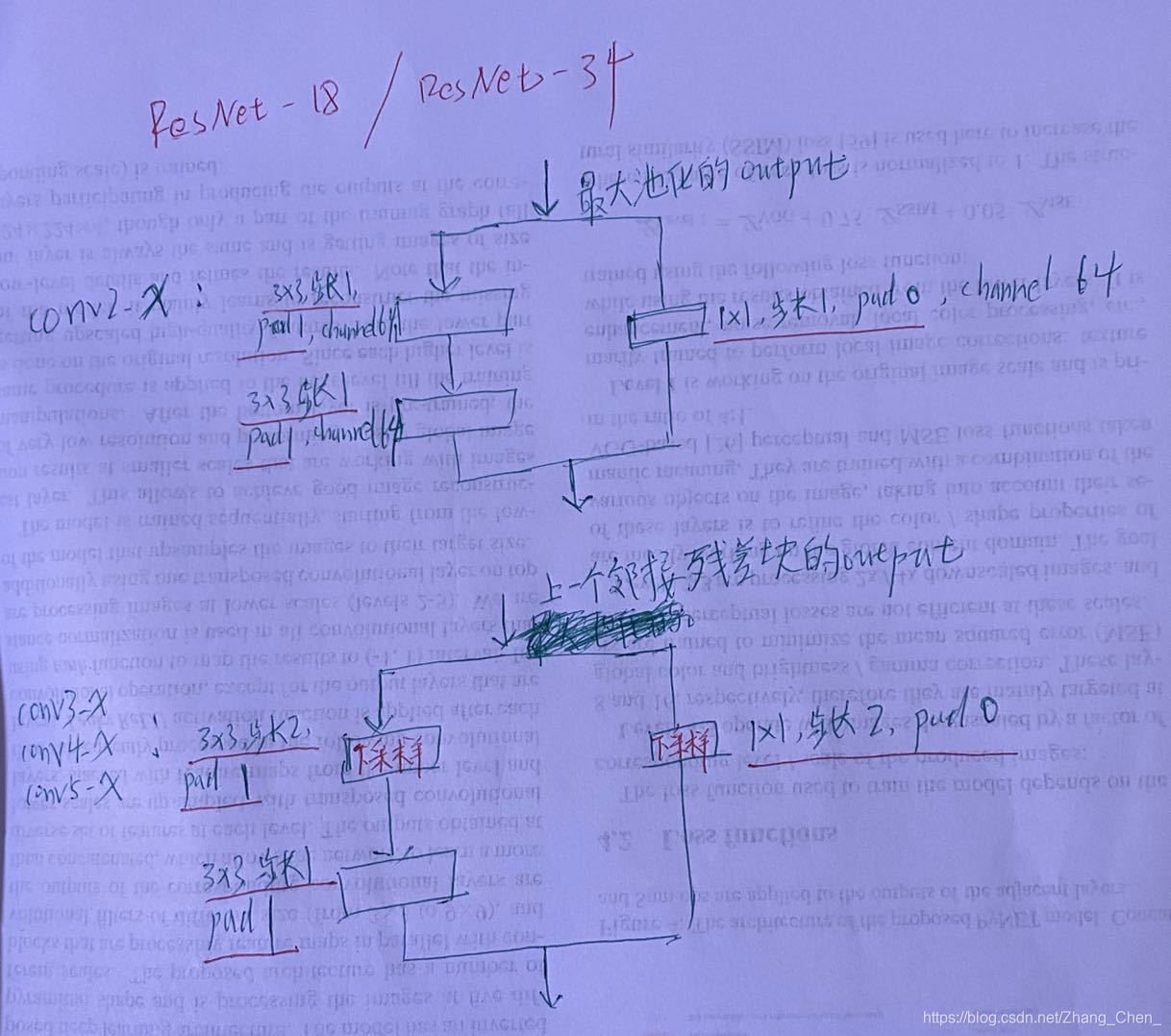
与上一个卷积组邻接的残差块的结构(以ResNet-18/34为例):
其他残差块的结构(以ResNet-18/34为例):

结语
如果您有修改意见或问题,欢迎留言或者通过邮箱和我联系。
手打很辛苦,如果我的文章对您有帮助,转载请注明出处。