文章目录
- 1. ClickHouse 背景与使用场景
- 2. 从 MySQL 到 ClickHouse 的迁移
- 3.MySQL 与 ClickHouse 的 SQL 优化区别
- 4.MySQL 与 ClickHouse 的排序优化对比
- 5. 改造原因与效果
- 6. 总结
1. ClickHouse 背景与使用场景

1.1 ClickHouse 简介
ClickHouse 是一个开源的列式数据库管理系统(DBMS),由俄罗斯 Yandex 公司开发,专为在线分析处理(OLAP)设计。它以极高的查询速度和高效的数据压缩能力著称,特别适合处理大规模数据集的实时分析。
1.2 ClickHouse 的特点
- 列式存储:数据按列存储,适合聚合查询,减少 I/O 操作。
- 高压缩比:列式存储天然适合数据压缩,节省存储空间。
- 向量化执行:利用 CPU 的 SIMD 指令集,加速数据处理。
- 实时数据插入:支持实时数据插入和查询,适合实时分析场景。
- 分布式架构:支持分布式查询和存储,易于扩展。
1.3 ClickHouse 的使用场景
- 大数据分析:处理 PB 级别的数据,适合数据仓库、BI 报表等场景。
- 实时日志分析:实时处理日志数据,生成实时报表。
- 用户行为分析:分析用户行为数据,生成用户画像。
- 时序数据处理:处理时间序列数据,如 IoT 设备数据、监控数据等。
2. 从 MySQL 到 ClickHouse 的迁移
2.1 MySQL 与 ClickHouse 的对比
| 特性 | MySQL | ClickHouse |
|---|---|---|
| 存储引擎 | 行式存储 | 列式存储 |
| 适用场景 | OLTP(在线事务处理) | OLAP(在线分析处理) |
| 数据压缩 | 压缩效果一般 | 高压缩比 |
| 查询性能 | 适合小规模数据,复杂查询较慢 | 适合大规模数据,聚合查询极快 |
| 事务支持 | 支持 ACID 事务 | 不支持事务 |
| 实时插入 | 支持实时插入 | 支持实时插入,但批量插入更高效 |
| 分布式支持 | 需要额外工具(如 MySQL Cluster) | 原生支持分布式查询和存储 |
2.2 迁移背景
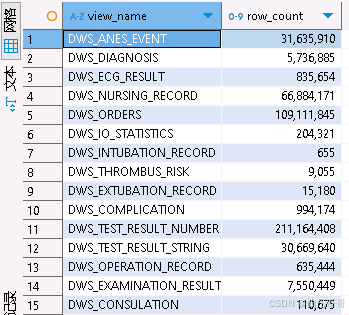
在手术记录相关的业务场景中,原先数据量最大的表只有 2 千万条数据,其他表在百万级别。新版本中,这些表的数据量增加了 10 倍,导致 MySQL 在处理这些表的关联查询时性能急剧下降。为了支撑大规模数据的关联查询,决定将部分业务迁移到 ClickHouse。
2.3 迁移注意事项
2.3.1 数据模型设计
- 宽表设计:ClickHouse 更适合宽表设计,避免多表 JOIN。可以将手术记录相关的多个表合并为一个宽表,减少查询时的 JOIN 操作。
- 分区设计:根据时间字段(如手术日期)进行分区,提升查询性能。例如,按天或按月分区。
- 数据类型选择:ClickHouse 的数据类型与 MySQL 有所不同,迁移时需要注意数据类型的转换。例如,ClickHouse 的
DateTime类型与 MySQL 的DATETIME类型类似,但精度更高。
2.3.2 数据迁移
- 数据导入:使用
clickhouse-client或clickhouse-copier工具将 MySQL 中的数据批量导入 ClickHouse。 - 数据同步:如果需要实时同步 MySQL 和 ClickHouse 的数据,可以使用
Debezium或Maxwell等工具。
2.3.3 SpringBoot 项目改造
-
连接池配置:在 SpringBoot 项目中,使用
druid连接池连接 ClickHouse。需要在pom.xml中添加 ClickHouse 的依赖:<!-- ClickHouse JDBC driver --> <dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.3.2</version> </dependency> -
MyBatisPlus 配置:MyBatisPlus 支持多种数据库,但需要手动配置 ClickHouse 的方言。可以通过自定义 SQL 解析器来实现 ClickHouse 的支持。
-
配置文件引入多数据源:
spring: application: name: @artifactId@ datasource: dynamic: primary: master # 设置默认的数据源 strict: false # 是否严格匹配数据源,不严格匹配时,找不到对应数据源会使用默认数据源 datasource: master: url: jdbc:mysql://127.0.0.1/XXX_prod?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true&connectTimeout=300000&socketTimeout=300000 username: root password: 123123 driver-class-name: com.mysql.cj.jdbc.Driver dw: url: jdbc:clickhouse://127.0.0.1:8123/default?timezone=Asia/Shanghai&socket_timeout=600000&connect_timeout=300000 username: default password: driver-class-name: ru.yandex.clickhouse.ClickHouseDriver druid: # 初始化大小,最小,最大 initialSize: 15 # 最小连接池数量 minIdle: 10 # 最大连接池数量 maxActive: 50 # 配置获取连接等待超时的时间 maxWait: 800000 # 配置连接池最大生存时间,单位毫秒 30分钟 maxLifetime: 1800000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 每60秒检查一次 timeBetweenEvictionRunsMillis: 60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 最小空闲时间为5分钟 minEvictableIdleTimeMillis: 300000 # 配置一个连接在池中最大生存的时间,单位是毫秒 maxEvictableIdletimeMillis: 900000 validationQuery: SELECT 1 # 用来检测连接是否有效的sql,要求是一个查询语句 validationQueryTimeout: 600000 testWhileIdle: true testOnBorrow: false testOnReturn: false # 打开PSCache,并且指定每个连接上PSCache的大小 poolPreparedStatements: true # 配置监控统计拦截的filters maxPoolPreparedStatementPerConnectionSize: 30 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 filters: stat,wall,slf4j keep-alive: true stat: merge-sql: true log-slow-sql: true slow-sql-millis: 2000 # 超过2秒的查询视为慢查询 # 配置 SQL 执行超时时间,单位为毫秒 queryTimeout: 600000 type: com.alibaba.druid.pool.DruidDataSource
2.3.4 查询改造
- SQL 语法差异:ClickHouse 的 SQL 语法与 MySQL 有所不同,迁移时需要注意语法差异。例如,ClickHouse 不支持
UPDATE和DELETE操作,查询时需要使用ALTER TABLE来更新数据。 - 关联查询优化:ClickHouse 的 JOIN 操作性能较差,建议将多个表合并为宽表,或者使用
IN子查询代替 JOIN。
3.MySQL 与 ClickHouse 的 SQL 优化区别
3.1. 存储引擎与数据模型
MySQL
- 行式存储:MySQL 默认使用行式存储(如 InnoDB),适合频繁的单行读写操作。
- 索引优化:依赖 B+ 树索引,优化重点是单行查询和范围查询。
- 事务支持:支持 ACID 事务,优化时需要兼顾事务的一致性和性能。
ClickHouse
- 列式存储:数据按列存储,适合大规模数据的聚合查询。
- 稀疏索引:ClickHouse 使用稀疏索引(如 MergeTree 的主键索引),优化重点是减少数据扫描范围。
- 无事务:不支持事务,优化时无需考虑事务开销。
优化区别:
- MySQL 优化重点在于单行查询和事务性能,而 ClickHouse 优化重点在于减少数据扫描和提升聚合查询性能。
我这里创建了一张标签表,便于给手术记录提前打上标签
CREATE TABLE tag
(
`surgical_id` String COMMENT '手术记录id',
`patientid` String COMMENT '病案号',
`operation_name` String COMMENT '手术名称',
`start_date_time` DateTime COMMENT '手术开始时间',
`direction_id` Int64 COMMENT '科研项目id',
`cutting_time` DateTime COMMENT '切皮时间',
`sewing_time` DateTime COMMENT '缝皮时间',
`chest_insertion_time` DateTime COMMENT '进胸时间',
`chest_closing_time` DateTime COMMENT '关胸时间',
`extracorporeal_start_time` DateTime COMMENT '体外循环开始时间',
`extracorporeal_end_time` DateTime COMMENT '体外循环结束时间',
`blocking_ascending_artery_time` DateTime COMMENT '阻断升动脉时间',
`open_ascending_artery_time` DateTime COMMENT '开放升动脉时间',
`cardiac_arrest_time` DateTime COMMENT '心脏停搏时间',
`cooling_time` DateTime COMMENT '降温时间',
`end_cooling_time` DateTime COMMENT '复温结束时间'
)
ENGINE = MergeTree
PARTITION BY direction_id
ORDER BY (direction_id,
start_date_time)
SETTINGS index_granularity = 8192;
通过创建科研项目时,预先给对应的人群打上标签,避免查询时实时执行复杂的人群检索逻辑
/**
* 绑定研究方向
*
* @param directionId
* @return
*/
@Override
public Boolean bindTag(Long directionId) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ScientificResearchDirections direction = directoryService.getById(directionId);
if (Objects.isNull(direction)) {
DataSyncLogUtil.warning("科研项目不存在");
throw new GlobalException(ResultCode.NOT_FOUND_DATA, "科研项目不存在");
}
LocalDateTime startTime = LocalDateTime.now();
// 创建同步日志
DataSynchronization log = DataSynchronization.builder()
.projectId(directionId)
.logId(DataSyncLogUtil.getMsgId())
.startTime(startTime)
.progress(String.format("%.2f", 0.00) + "%")
.type(DataSynchronizationEnum.UNDER_WAY.getCode())
.event(DataSynchronizationEnum.EVENT_1.getType())
.build();
dataSynchronizationService.save(log);
ScientificResearchDirectionsExt directionsExt = dictionaryExtService.lambdaQuery().eq(ScientificResearchDirectionsExt::getDirectionId, direction.getId()).one();
List<ScientificResearchDictionary> matchTypeList = dictionaryService.getDictionaries("match_type");
List<ScientificResearchDirectionsStandard> standardList = directionsStandardService.lambdaQuery().eq(ScientificResearchDirectionsStandard::getDelFlag, 0).list();
JSONObject conditionJson = JSON.parseObject(directionsExt.getConditionJson());
findQueryRule("include", conditionJson, standardList, matchTypeList);
findQueryRule("exclude", conditionJson, standardList, matchTypeList);
try {
List<DwTag> data = getDirectionIdByCondition(conditionJson, directionId);
updateLog(30.00, log);
// TODO 数据转换
AnnotationProcessor.processList(data);
updateLog(40.00, log);
if (CollUtil.isEmpty(data)) {
DataSyncLogUtil.warning("科研项目[" + direction.getName() + "]未找到患者信息");
return true;
}
// 清除历史标签,使用分区删除,优先删除整个分区,而不是逐条删除数据。
partitionDeletion(directionId);
updateLog(50.00, log);
batchInsert(data, batchSize);
updateLog(70.00, log);
} catch (Exception ex) {
log.setType(DataSynchronizationEnum.FAIL.getCode());
String message = ex.getMessage();
if (message.length() > 3000) {
message = message.substring(0, 3000);
}
log.setFailLog(message);
DataSyncLogUtil.error("科研项目[" + direction.getName() + "]数仓查询异常,异常信息:" + message);
return false;
}
// TODO 同步辅助时间
getTheAuxiliaryQueryTime(directionId);
log.setType(DataSynchronizationEnum.SUCCEED.getCode());
LocalDateTime endTime = LocalDateTime.now();
log.setEndTime(endTime);
// 计算耗时
log.setTimeConsuming(Duration.between(startTime, endTime).getSeconds());
updateLog(100.00, log);
return true;
}
/**
* 查询规则解析
*
* @param type
* @param conditionJson
* @param standardList
* @param matchTypeList
*/
private void findQueryRule(String type, JSONObject conditionJson, List<ScientificResearchDirectionsStandard> standardList, List<ScientificResearchDictionary> matchTypeList) {
String splitStr = " ";
if (conditionJson.containsKey(type)) {
JSONArray includes = conditionJson.getJSONArray(type);
for (Object obj : includes) {
JSONObject include = (JSONObject) obj;
include.put("last", false);
JSONArray firstConditions = include.getJSONArray("condition");
for (Object obj1 : firstConditions) {
JSONObject first = (JSONObject) obj1;
if (first.containsKey("condition")) {
first.put("last", false);
JSONArray secondConditions = first.getJSONArray("condition");
for (Object obj2 : secondConditions) {
JSONObject second = (JSONObject) obj2;
ScientificResearchDirectionsStandard standard = standardList.stream().filter(f -> f.getId().equals(second.getLongValue("standard_id"))).findFirst().orElse(null);
if (Objects.nonNull(standard)) {
if (matchType.equals(second.getString("match_type"))) {
second.put("query_type", standard.getQueryType());
second.put("query_rule", standard.getQueryRuleExtTwo());
second.put("query_last", null);
second.put("bind_table", standard.getBindTable());
second.put("bind_field", null);
} else {
second.put("query_type", standard.getQueryType());
second.put("query_rule", standard.getQueryRule());
second.put("query_last", standard.getQueryLast());
second.put("bind_table", standard.getBindTable());
second.put("bind_field", standard.getBindField());
}
}
ScientificResearchDictionary dictionary = matchTypeList.stream().filter(f -> f.getName().equals(second.getString("match_type"))).findFirst().orElse(null);
if (Objects.nonNull(dictionary)) {
if (standard.getQueryType().equals(1)) {
if ("exclude".equals(type)) {
second.put("match_type", dictionary.getExtValue());
} else {
second.put("match_type", dictionary.getValue());
}
} else {
second.put("match_type", dictionary.getValue());
}
}
String matchType = second.getString("match_type");
if (Objects.nonNull(matchType) && matchType.contains("like")) {
String matchValue = second.getString("match_value");
second.put("match_value_list", matchValue.split(splitStr));
}
if (matchType.equals(second.getString("match_type"))) {
second.put("last", false);
} else {
second.put("last", true);
}
}
} else {
first.put("last", true);
ScientificResearchDirectionsStandard standard = standardList.stream().filter(f -> f.getId().equals(first.getLongValue("standard_id"))).findFirst().orElse(null);
if (Objects.nonNull(standard)) {
first.put("query_type", standard.getQueryType());
first.put("query_rule", standard.getQueryRule());
first.put("query_last", standard.getQueryLast());
}
ScientificResearchDictionary dictionary = matchTypeList.stream().filter(f -> f.getName().equals(first.getString("match_type"))).findFirst().orElse(null);
if (Objects.nonNull(dictionary)) {
if ("exclude".equals(type)) {
first.put("match_type", dictionary.getExtValue());
} else {
first.put("match_type", dictionary.getValue());
}
}
String matchType = first.getString("match_type");
if (matchType.contains("like")) {
String matchValue = first.getString("match_value");
first.put("match_value_list", matchValue.split(splitStr));
}
}
}
}
}
}
人群筛选sql:
<select id="getDirectionIdByCondition" resultType="com.anesthesia.server.entity.dw.DwTag">
select
concat(patientid, '_', operation_name, '_', toString(start_date_time)) AS surgical_id,
patientid,
operation_name,
start_date_time,
#{directionId} AS direction_id
from DWS_OPERATION_RECORD
where 1=1
<if test="conditionJson.include != null and conditionJson.include.size()>0">
and
<foreach collection="conditionJson.include" item="first" separator="and" open="(" close=")">
<if test='first.field_condition_type == "and"'>
<foreach collection="first.condition" item="second" separator="and" open="(" close=")">
<if test="second.last">
<if test='second.match_type.contains("like")'>
<if test='second.query_type == 1'>
<foreach collection="second.match_value_list" item="value" separator="or" open="(" close=")">
${second.bind_table}.${second.bind_field} ${second.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!second.match_type.contains("like")'>
<if test='second.query_type == 1'>
${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value}
</if>
<if test="second.query_type == 3">
<choose>
<when test="second.match_type == 'multiply'">
patientid IN (${second.query_rule})
</when>
<otherwise>
patientid IN (${second.query_rule} and ${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value} ${second.query_last})
</otherwise>
</choose>
</if>
</if>
</if>
<if test="!second.last">
<if test='second.field_condition_type == "and"'>
<foreach collection="second.condition" item="three" separator="and" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="or" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid IN (${three.query_rule})
</when>
<otherwise>
patientid IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
<if test='second.field_condition_type != "and"'>
<foreach collection="second.condition" item="three" separator="or" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="or" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid IN (${three.query_rule})
</when>
<otherwise>
patientid IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
</if>
</foreach>
</if>
<if test='first.field_condition_type != "and"'>
<foreach collection="first.condition" item="second" separator="or" open="(" close=")">
<if test="second.last">
<if test='second.match_type.contains("like")'>
<if test='second.query_type == 1'>
<foreach collection="second.match_value_list" item="value" separator="or" open="(" close=")">
${second.bind_table}.${second.bind_field} ${second.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!second.match_type.contains("like")'>
<if test='second.query_type == 1'>
${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value}
</if>
<if test="second.query_type == 3">
<choose>
<when test="second.match_type == 'multiply'">
patientid IN (${second.query_rule})
</when>
<otherwise>
patientid IN (${second.query_rule} and ${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value} ${second.query_last})
</otherwise>
</choose>
</if>
</if>
</if>
<if test="!second.last">
<if test='second.field_condition_type == "and"'>
<foreach collection="second.condition" item="three" separator="and" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="or" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid IN (${three.query_rule})
</when>
<otherwise>
patientid IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
<if test='second.field_condition_type != "and"'>
<foreach collection="second.condition" item="three" separator="or" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="or" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid IN (${three.query_rule})
</when>
<otherwise>
patientid IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
</if>
</foreach>
</if>
</foreach>
</if>
<if test="conditionJson.exclude != null and conditionJson.exclude.size()>0">
and
<foreach collection="conditionJson.exclude" item="first" separator="and" open="(" close=")">
<if test='first.field_condition_type == "and"'>
<foreach collection="first.condition" item="second" separator="and" open="(" close=")">
<if test="second.last">
<if test='second.match_type.contains("like")'>
<if test='second.query_type == 1'>
<foreach collection="second.match_value_list" item="value" separator="and" open="(" close=")">
${second.bind_table}.${second.bind_field} ${second.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!second.match_type.contains("like")'>
<if test='second.query_type == 1'>
${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value}
</if>
<if test="second.query_type == 3">
<choose>
<when test="second.match_type == 'multiply'">
patientid NOT IN (${second.query_rule})
</when>
<otherwise>
patientid NOT IN (${second.query_rule} and ${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value} ${second.query_last})
</otherwise>
</choose>
</if>
</if>
</if>
<if test="!second.last">
<if test='second.field_condition_type == "and"'>
<foreach collection="second.condition" item="three" separator="and" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="and" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid NOT IN (${three.query_rule})
</when>
<otherwise>
patientid NOT IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
<if test='second.field_condition_type != "and"'>
<foreach collection="second.condition" item="three" separator="or" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="and" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid NOT IN (${three.query_rule})
</when>
<otherwise>
patientid NOT IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
</if>
</foreach>
</if>
<if test='first.field_condition_type != "and"'>
<foreach collection="first.condition" item="second" separator="or" open="(" close=")">
<if test="second.last">
<if test='second.match_type.contains("like")'>
<if test='second.query_type == 1'>
<foreach collection="second.match_value_list" item="value" separator="and" open="(" close=")">
${second.bind_table}.${second.bind_field} ${second.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!second.match_type.contains("like")'>
<if test='second.query_type == 1'>
${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value}
</if>
<if test="second.query_type == 3">
<choose>
<when test="second.match_type == 'multiply'">
patientid NOT IN (${second.query_rule})
</when>
<otherwise>
patientid NOT IN (${second.query_rule} and ${second.bind_table}.${second.bind_field} ${second.match_type} #{second.match_value} ${second.query_last})
</otherwise>
</choose>
</if>
</if>
</if>
<if test="!second.last">
<if test='second.field_condition_type == "and"'>
<foreach collection="second.condition" item="three" separator="and" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="and" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid NOT IN (${three.query_rule})
</when>
<otherwise>
patientid NOT IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
<if test='second.field_condition_type != "and"'>
<foreach collection="second.condition" item="three" separator="or" open="(" close=")">
<if test='three.match_type.contains("like")'>
<if test='three.query_type == 1'>
<foreach collection="three.match_value_list" item="value" separator="and" open="(" close=")">
${three.bind_table}.${three.bind_field} ${three.match_type} concat('%', #{value}, '%')
</foreach>
</if>
</if>
<if test='!three.match_type.contains("like")'>
<if test='three.query_type == 1'>
${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value}
</if>
<if test="three.query_type == 3">
<choose>
<when test="three.match_type == 'multiply'">
patientid NOT IN (${three.query_rule})
</when>
<otherwise>
patientid NOT IN (${three.query_rule} and ${three.bind_table}.${three.bind_field} ${three.match_type} #{three.match_value} ${three.query_last})
</otherwise>
</choose>
</if>
</if>
</foreach>
</if>
</if>
</foreach>
</if>
</foreach>
</if>
</select>
3.2. 索引设计与使用
MySQL
- 索引类型:支持 B+ 树索引、哈希索引、全文索引等。
- 索引优化:
- 为频繁查询的字段创建索引。
- 避免全表扫描,尽量使用索引覆盖查询。
- 注意索引的选择性,避免低选择性字段创建索引。
- 复合索引:根据查询条件设计复合索引,注意最左前缀原则。
ClickHouse
- 索引类型:主要使用稀疏索引(如 MergeTree 的主键索引)。
- 索引优化:
- 主键索引用于加速数据查找和分区裁剪。
- 稀疏索引适合范围查询,但不适合高基数字段的精确查询。
- 不支持传统意义上的二级索引。
- 跳数索引:ClickHouse 提供跳数索引(如
minmax、set),用于加速特定查询。
优化区别:
- MySQL 依赖 B+ 树索引优化单行查询,而 ClickHouse 依赖稀疏索引和跳数索引优化范围查询和聚合查询。
3.3. 查询优化
MySQL
- 查询优化器:MySQL 的查询优化器基于成本模型,优化重点是减少磁盘 I/O 和 CPU 开销。
- 优化技巧:
- 避免
SELECT *,只查询需要的字段。 - 使用
EXPLAIN分析查询计划,优化索引和查询条件。 - 避免子查询和复杂 JOIN,尽量使用简单查询。
- 使用覆盖索引减少回表操作。
- 避免
ClickHouse
- 查询优化器:ClickHouse 的查询优化器针对列式存储和向量化执行优化,重点是减少数据扫描和利用 CPU 并行计算。
- 优化技巧:
- 尽量使用聚合函数和分组查询,发挥列式存储的优势。
- 避免复杂 JOIN,ClickHouse 的 JOIN 性能较差,建议使用宽表或
IN子查询替代。 - 使用分区裁剪和索引减少数据扫描范围。
- 利用物化视图或预聚合表加速频繁查询。
优化区别:
- MySQL 优化重点是减少磁盘 I/O 和单行查询开销,而 ClickHouse 优化重点是减少数据扫描和利用并行计算加速聚合查询。
3.4. JOIN 操作
MySQL
- JOIN 类型:支持多种 JOIN 类型(如 INNER JOIN、LEFT JOIN)。
- 优化技巧:
- 为 JOIN 字段创建索引。
- 避免大表 JOIN,尽量使用小表驱动大表。
- 可以在JOIN时将where中的条件部分提前执行,缩小关联的范围。
- 使用
EXPLAIN分析 JOIN 执行计划,优化查询顺序。
ClickHouse
- JOIN 类型:支持 JOIN,但性能较差,尤其是大表 JOIN。
- 优化技巧:
- 尽量避免 JOIN,使用宽表设计或
IN子查询替代。 - 如果必须使用 JOIN,尽量将小表放在右侧(ClickHouse 的 JOIN 是右表驱动)。
- 不允许在JOIN 时关联其他表的字段提前执行,只能放在where之后。
- 使用
GLOBAL JOIN避免分布式查询中的数据重复。
- 尽量避免 JOIN,使用宽表设计或
优化区别:
- MySQL 的 JOIN 性能较好,优化重点是索引和查询顺序;而 ClickHouse 的 JOIN 性能较差,优化重点是避免 JOIN 或使用替代方案。
我这里手术记录主表DWS_OPERATION_RECORD的数据量是最小的,
- 因此JOIN时,将其放在右侧,将数据量大的附表放在左侧,
- 使用INNER JOIN(只返回两个表中都存在匹配值的行)。
- 我这里通过子查询进行优先过滤。(在 JOIN 之前使用
WHERE子句过滤数据,减少参与 JOIN 的数据量)。
我这里是自定义的复杂逻辑,配置自定义模板时生成自定义sql预先存储在mysql中。
<select id="getTemplateTestNumberBatch" resultType="java.util.LinkedHashMap">
SELECT
g.surgical_id AS surgicalId,
t.requisition_time AS orderTime,
${field.valueField} AS `${field.fieldAlias}`
FROM
(SELECT t.patientid,t.requisition_time,t.testresult FROM DWS_TEST_RESULT_NUMBER t WHERE ${field.fieldName}) t
INNER JOIN
DWS_OPERATION_RECORD d ON t.patientid = d.patientid
INNER JOIN (SELECT * FROM tag WHERE direction_id = #{projectId}) g
ON g.patientid = d.patientid AND g.operation_name = d.operation_name AND g.start_date_time = d.start_date_time
<where>
<if test="field.configurationList != null">
<foreach collection="field.configurationList" item="configuration">
${configuration.queryJson}
</foreach>
</if>
</where>
</select>
动态sql案例1:
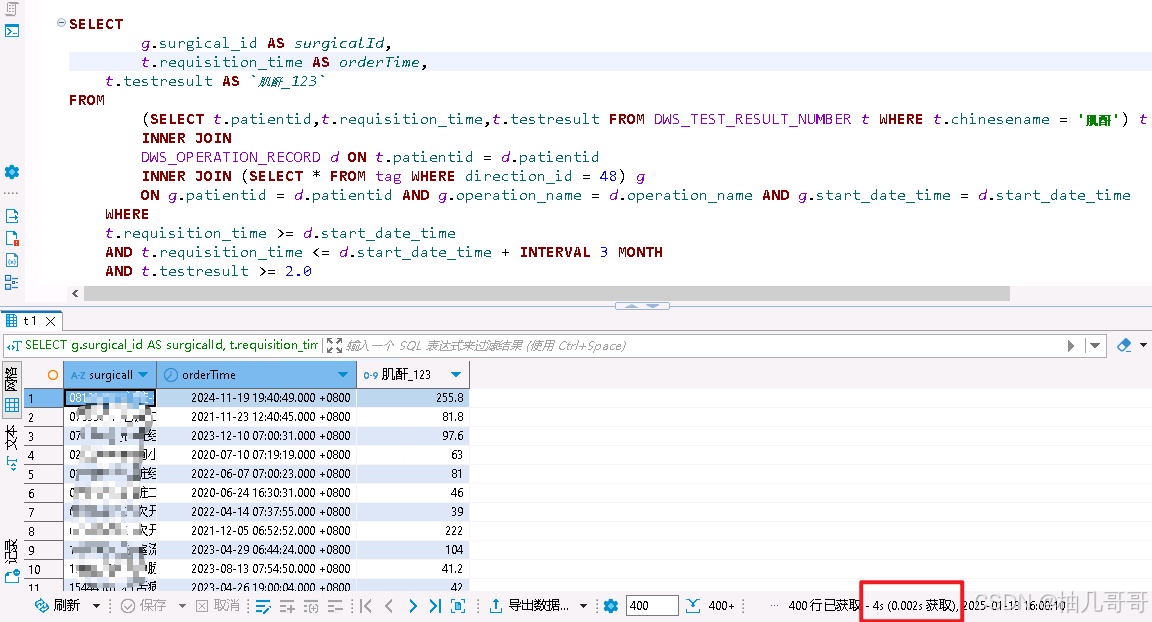
这里是查询出研究方向id为48的所有手术记录的“肌酐”检验数据
检验时间范围:手术开始时间-手术开始时间之后3个月内
值筛选:检验结果大于等于2.0
SELECT
g.surgical_id AS surgicalId,
t.requisition_time AS orderTime,
t.testresult AS `肌酐_123`
FROM
(SELECT t.patientid,t.requisition_time,t.testresult FROM DWS_TEST_RESULT_NUMBER t WHERE t.chinesename = '肌酐'
) t
INNER JOIN
DWS_OPERATION_RECORD d ON t.patientid = d.patientid
INNER JOIN (SELECT * FROM tag WHERE direction_id = 48) g
ON g.patientid = d.patientid AND g.operation_name = d.operation_name AND g.start_date_time = d.start_date_time
WHERE
t.requisition_time >= d.start_date_time
AND t.requisition_time <= d.start_date_time + INTERVAL 3 MONTH
AND t.testresult >= 2.0
其中 DWS_TEST_RESULT_NUMBER 数据量在2亿+,其余表在几十万,执行时间4s。
动态sql案例2:
<select id="getTemplateTestNumberLastTime" resultType="com.anesthesia.server.model.vo.LastTimeVo">
SELECT
concat(d.patientid, '_', d.operation_name, '_', toString(d.start_date_time)) AS id,
argMin(${valueField}, abs(toUInt32(d.${timeCode}) - toUInt32(t.requisition_time))) AS result
FROM
(SELECT t.patientid,t.requisition_time,${valueField} FROM DWS_TEST_RESULT_NUMBER AS t WHERE t.requisition_time IS NOT NULL AND ${fieldName}) t
INNER JOIN
DWS_OPERATION_RECORD AS d ON t.patientid = d.patientid
INNER JOIN (SELECT * FROM tag WHERE direction_id = #{projectId} ) g
ON g.patientid = d.patientid AND g.operation_name = d.operation_name AND g.start_date_time = d.start_date_time
<where>
<if test="conventionalCondition != null">
<foreach collection="conventionalCondition" item="configuration">
${configuration.queryJson}
</foreach>
</if>
</where>
GROUP BY concat(d.patientid, '_', d.operation_name, '_', toString(d.start_date_time))
</select>
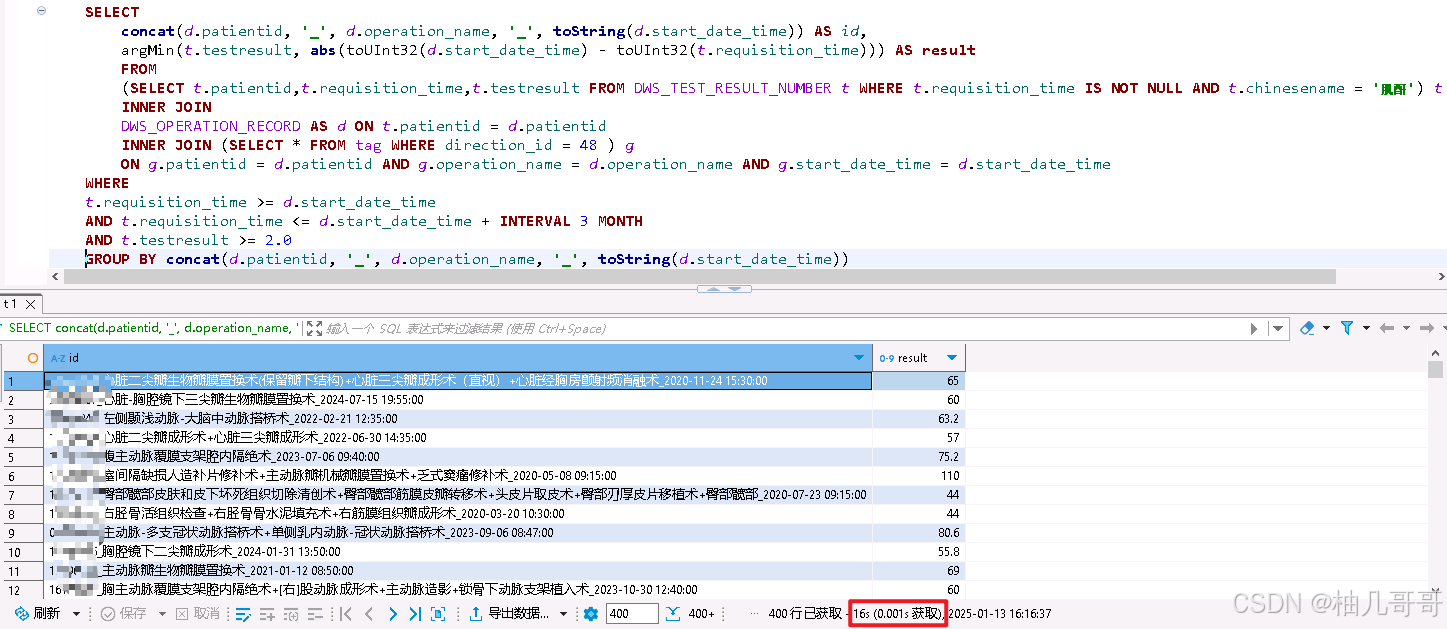
这里是查询出研究方向id为48的所有手术记录的“肌酐”检验数据
检验时间范围:手术开始时间-手术开始时间之后3个月内
值筛选:检验结果大于等于2.0
最近一次:获取以上条件中每个手术记录距离手术开始时间最近的一次
SELECT
concat(d.patientid, '_', d.operation_name, '_', toString(d.start_date_time)) AS id,
argMin(t.testresult, abs(toUInt32(d.start_date_time) - toUInt32(t.requisition_time))) AS result
FROM
(SELECT t.patientid,t.requisition_time,t.testresult FROM DWS_TEST_RESULT_NUMBER t WHERE t.requisition_time IS NOT NULL AND t.chinesename = '肌酐') t
INNER JOIN
DWS_OPERATION_RECORD AS d ON t.patientid = d.patientid
INNER JOIN (SELECT * FROM tag WHERE direction_id = 48 ) g
ON g.patientid = d.patientid AND g.operation_name = d.operation_name AND g.start_date_time = d.start_date_time
WHERE
t.requisition_time >= d.start_date_time
AND t.requisition_time <= d.start_date_time + INTERVAL 3 MONTH
AND t.testresult >= 2.0
GROUP BY concat(d.patientid, '_', d.operation_name, '_', toString(d.start_date_time))
其中 DWS_TEST_RESULT_NUMBER 数据量在2亿+,其余表在几十万,执行时间16s。
这里因为手术记录表没有唯一标识,则通过concat(d.patientid, ‘', d.operation_name, '’, toString(d.start_date_time))手动生成唯一标识
3.5 日期加减
在 MySQL 和 ClickHouse 中,INTERVAL 都用于处理日期和时间的加减操作,但它们的语法和功能有一些区别。以下是对比 MySQL 和 ClickHouse 中 INTERVAL 3 MONTH 的用法和区别。
3.5.1. MySQL 中的 INTERVAL 3 MONTH
基本用法
在 MySQL 中,INTERVAL 用于对日期或时间进行加减操作。INTERVAL 3 MONTH 表示增加或减少 3 个月。
示例 1:日期加减
SELECT NOW() + INTERVAL 3 MONTH;
- 返回当前日期时间加上 3 个月后的结果。
示例 2:在 WHERE 子句中使用
SELECT * FROM orders
WHERE order_date >= NOW() - INTERVAL 3 MONTH;
- 查询过去 3 个月内的订单。
示例 3:在 DATE_ADD 和 DATE_SUB 中使用
SELECT DATE_ADD(NOW(), INTERVAL 3 MONTH);
SELECT DATE_SUB(NOW(), INTERVAL 3 MONTH);
DATE_ADD用于增加时间,DATE_SUB用于减少时间。
3.5.1.2 支持的间隔单位
MySQL 的 INTERVAL 支持多种单位,包括:
YEAR、QUARTER、MONTH、DAY、HOUR、MINUTE、SECOND等。
3.5.2. ClickHouse 中的 INTERVAL 3 MONTH
3.5.2.1 基本用法
在 ClickHouse 中,INTERVAL 也用于对日期或时间进行加减操作,但语法和 MySQL 略有不同。
示例 1:日期加减
SELECT now() + INTERVAL 3 MONTH;
- 返回当前日期时间加上 3 个月后的结果。
示例 2:在 WHERE 子句中使用
SELECT * FROM orders
WHERE order_date >= now() - INTERVAL 3 MONTH;
- 查询过去 3 个月内的订单。
示例 3:使用 addMonths 函数
ClickHouse 还提供了 addMonths 函数来实现相同的功能:
SELECT addMonths(now(), 3);
3.5.2.2 支持的间隔单位
ClickHouse 的 INTERVAL 支持多种单位,包括:
YEAR、QUARTER、MONTH、WEEK、DAY、HOUR、MINUTE、SECOND等。
3.5.3. MySQL 和 ClickHouse 的区别
3.5.3.1 语法兼容性
- MySQL 和 ClickHouse 的
INTERVAL语法基本兼容,可以直接迁移。 - 例如,
NOW() + INTERVAL 3 MONTH在两种数据库中都可以使用。
3.5.3.2 函数支持
- MySQL 提供了
DATE_ADD和DATE_SUB函数,而 ClickHouse 提供了addMonths、subtractMonths等函数。 - 例如:
- MySQL:
DATE_ADD(NOW(), INTERVAL 3 MONTH) - ClickHouse:
addMonths(now(), 3)
- MySQL:
3.5.3.3 性能
- ClickHouse 的日期函数性能通常优于 MySQL,尤其是在处理大规模数据时。
- ClickHouse 的向量化执行引擎可以高效处理日期计算。
3.5.3.4 时区处理
- MySQL 的
NOW()函数返回当前时区的时间。 - ClickHouse 的
now()函数默认返回 UTC 时间,但可以通过设置时区或使用toTimezone函数转换为本地时间。
示例:ClickHouse 时区转换
SELECT now() AS utc_time, toTimezone(now(), 'Asia/Shanghai') AS local_time;
3.5.4. 迁移注意事项
3.5.4.1 语法迁移
- 如果从 MySQL 迁移到 ClickHouse,
INTERVAL语法可以直接迁移。 - 例如:
- MySQL:
NOW() + INTERVAL 3 MONTH - ClickHouse:
now() + INTERVAL 3 MONTH
- MySQL:
3.5.4.2 函数替换
- 如果 MySQL 中使用了
DATE_ADD或DATE_SUB,可以替换为 ClickHouse 的addMonths或subtractMonths。 - 例如:
- MySQL:
DATE_ADD(NOW(), INTERVAL 3 MONTH) - ClickHouse:
addMonths(now(), 3)
- MySQL:
3.5.4.3 时区处理
- 如果 MySQL 中使用了本地时间,迁移到 ClickHouse 时需要注意时区转换。
- 例如:
- MySQL:
NOW() - ClickHouse:
toTimezone(now(), 'Asia/Shanghai')
- MySQL:
3.5.5. 总结
| 特性 | MySQL | ClickHouse |
|---|---|---|
| 语法 | NOW() + INTERVAL 3 MONTH | now() + INTERVAL 3 MONTH |
| 函数支持 | DATE_ADD、DATE_SUB | addMonths、subtractMonths |
| 时区处理 | 返回本地时间 | 默认返回 UTC 时间,需手动转换 |
| 性能 | 适合小规模数据 | 适合大规模数据,性能更优 |
- MySQL 和 ClickHouse 的
INTERVAL语法基本兼容,可以直接迁移。 - ClickHouse 提供了更多日期函数和更高的性能,适合处理大规模数据。
- 在迁移时需要注意时区处理和函数替换。
如果你有更多关于 INTERVAL 的问题,或者需要进一步的迁移建议,请随时告诉我!
3.6. 数据写入优化
MySQL
- 写入优化:
- 使用批量插入(
INSERT INTO ... VALUES (...), (...))减少事务开销。 - 关闭索引更新(如
ALTER TABLE ... DISABLE KEYS)后再插入数据。 - 使用事务批量提交,减少锁竞争。
- 使用批量插入(
ClickHouse
- 写入优化:
- ClickHouse 的写入性能在批量插入时最佳,建议每次插入至少 1000 行数据。
- 使用
Buffer表引擎缓冲写入,减少小批量写入的开销。 - 避免高频单条插入,ClickHouse 的单条插入性能较差。
优化区别:
- MySQL 的写入优化重点是事务和索引管理,而 ClickHouse 的写入优化重点是批量插入和减少小批量写入。
我这里在Java程序层面采用了分多线程进行插入操作
@Resource
@Qualifier("tagUpdateThreadPool")
private ThreadPoolTaskExecutor taskExecutor; // 注入线程池
@Override
@DS("dw")
@Transactional(rollbackFor = SQLException.class)
public void getTheAuxiliaryQueryTime(Long directionId) {
log.info("<<==开始更新辅助查询时间");
int pageSize = 1000;
int currentPage = 1;
boolean hasMoreData = true;
AtomicInteger totalUpdated = new AtomicInteger(0); // 记录总更新条数
CountDownLatch latch = new CountDownLatch(0); // 用于等待所有任务完成
try {
while (hasMoreData) {
Page<DwTag> page = new Page<>(currentPage, pageSize);
Page<DwTag> resultPage = baseMapper.getTheAuxiliaryQueryTimeForTag(directionId, page);
List<DwTag> theAuxiliaryQueryTime = resultPage.getRecords();
if (CollUtil.isNotEmpty(theAuxiliaryQueryTime)) {
latch = new CountDownLatch(theAuxiliaryQueryTime.size()); // 重置计数器
// 提交任务到线程池
for (DwTag dwTag : theAuxiliaryQueryTime) {
CountDownLatch finalLatch = latch;
taskExecutor.execute(() -> {
try {
update(dwTag, new LambdaQueryWrapper<DwTag>()
.eq(DwTag::getSurgicalId, dwTag.getSurgicalId()));
totalUpdated.incrementAndGet(); // 更新成功计数
} catch (Exception e) {
log.error("<<==更新数据时发生异常, surgicalId: {}", dwTag.getSurgicalId(), e);
} finally {
finalLatch.countDown(); // 任务完成,计数器减一
}
});
}
latch.await(); // 等待当前页的所有任务完成
} else {
hasMoreData = false; // 没有更多数据,退出循环
}
currentPage++;
}
log.info("<<==辅助查询时间更新完成, 共更新了{}条数据", totalUpdated.get());
} catch (Exception e) {
log.error("<<==更新辅助查询时间时发生异常: {}", e.getMessage(), e);
}
}
3.7. 分区与分片
MySQL
- 分区:MySQL 支持表分区(如按范围、哈希分区),但分区功能有限,优化效果不明显。
- 分片:需要借助第三方工具(如 Vitess)实现分片。
ClickHouse
- 分区:ClickHouse 的分区功能强大,支持按时间、日期等字段分区,分区裁剪可以大幅提升查询性能。
- 分片:ClickHouse 原生支持分布式分片,可以通过
Distributed表引擎实现跨节点查询。
优化区别:
- MySQL 的分区和分片功能较弱,优化效果有限;而 ClickHouse 的分区和分片功能强大,是优化大规模数据查询的重要手段。
3.8. 总结
MySQL 和 ClickHouse 在 SQL 优化上的区别主要体现在以下几个方面:
- 存储模型:MySQL 是行式存储,优化重点是单行查询和事务性能;ClickHouse 是列式存储,优化重点是减少数据扫描和提升聚合查询性能。
- 索引设计:MySQL 依赖 B+ 树索引,ClickHouse 使用稀疏索引和跳数索引。
- JOIN 操作:MySQL 的 JOIN 性能较好,ClickHouse 的 JOIN 性能较差,建议避免 JOIN 或使用替代方案。
- 写入优化:MySQL 优化重点是事务和索引管理,ClickHouse 优化重点是批量插入。
- 分区与分片:ClickHouse 的分区和分片功能强大,是优化大规模数据查询的重要手段。
在实际项目中,可以根据业务场景选择合适的数据库,并针对其特点进行 SQL 优化,以充分发挥其性能优势。
4.MySQL 与 ClickHouse 的排序优化对比
排序是数据库查询中常见的操作,尤其在数据分析、报表生成和分页查询等场景中至关重要。MySQL 和 ClickHouse 在排序的实现和优化上有显著差异,主要体现在存储模型、索引设计、查询执行方式等方面。以下从多个维度对比 MySQL 和 ClickHouse 在排序上的优化策略。
4.1. 存储模型对排序的影响
MySQL
- 行式存储:MySQL 默认使用行式存储(如 InnoDB),数据按行存储,排序时需要读取整行数据。
- 排序开销:如果排序字段没有索引,MySQL 需要对查询结果进行全表扫描,并在内存或磁盘中进行排序,开销较大。
- 索引优化:如果排序字段有索引(如 B+ 树索引),MySQL 可以直接利用索引的有序性避免额外排序。
ClickHouse
- 列式存储:ClickHouse 使用列式存储,数据按列存储,排序时只需读取相关列的数据,减少了 I/O 开销。
- 排序开销:ClickHouse 的排序操作通常发生在内存中,且利用向量化执行和并行计算加速排序过程。
- 索引优化:ClickHouse 的稀疏索引不直接用于排序,但可以通过分区和主键索引减少数据扫描范围。
优化区别:
- MySQL 的排序优化依赖索引的有序性,而 ClickHouse 的排序优化依赖列式存储和并行计算。
4.2. 索引对排序的支持
MySQL
- B+ 树索引:MySQL 的 B+ 树索引天然支持排序,如果查询的
ORDER BY字段有索引,MySQL 可以直接利用索引的有序性避免额外排序。 - 复合索引:如果查询的
ORDER BY和WHERE条件匹配复合索引的最左前缀,MySQL 可以避免排序操作。 - 文件排序:如果排序字段没有索引,MySQL 需要使用文件排序(
filesort),在内存或磁盘中对结果集进行排序。
ClickHouse
- 稀疏索引:ClickHouse 的稀疏索引(如 MergeTree 的主键索引)不直接用于排序,但可以通过分区裁剪减少数据扫描范围。
- 跳数索引:ClickHouse 的跳数索引(如
minmax)可以加速范围查询,但对排序操作帮助有限。 - 排序实现:ClickHouse 的排序操作通常发生在内存中,且利用多核 CPU 并行计算加速排序。
优化区别:
- MySQL 的排序优化依赖索引的有序性,而 ClickHouse 的排序优化依赖列式存储和并行计算。
4.3. 排序的执行方式
MySQL
- 内存排序:如果排序数据量较小,MySQL 会在内存中进行排序。
- 磁盘排序:如果排序数据量较大,MySQL 会使用磁盘临时文件进行排序,开销较大。
- 排序算法:MySQL 使用快速排序或归并排序算法。
ClickHouse
- 内存排序:ClickHouse 的排序操作通常发生在内存中,且利用向量化执行和并行计算加速排序。
- 外部排序:如果数据量非常大,ClickHouse 也会使用磁盘进行外部排序,但由于列式存储的特性,I/O 开销较小。
- 排序算法:ClickHouse 使用快速排序或基数排序算法,且支持多线程并行排序。
优化区别:
- MySQL 的排序可能涉及磁盘 I/O,而 ClickHouse 的排序主要依赖内存和并行计算。
4.4. 排序优化的实践技巧
MySQL
- 利用索引:
- 为排序字段创建索引,避免文件排序。
- 如果查询包含
WHERE条件和ORDER BY,设计复合索引以匹配最左前缀。
- 减少排序数据量:
- 使用
LIMIT限制返回的行数,减少排序开销。 - 在子查询中先过滤数据,再对结果集排序。
- 使用
- 调整排序缓冲区:
- 增加
sort_buffer_size参数,提升内存排序的性能。 - 监控
Sort_merge_passes状态变量,优化磁盘排序。
- 增加
ClickHouse
-
减少数据扫描:
- 使用分区裁剪和主键索引减少数据扫描范围。
- 避免全表扫描,尽量使用过滤条件缩小数据集。
-
利用并行计算:
- ClickHouse 自动利用多核 CPU 并行排序,无需额外配置。
- 确保查询的并发度足够高,以充分利用硬件资源。
-
预排序数据:
- 在数据导入时按常用排序字段预排序,减少查询时的排序开销。
- 使用
ORDER BY子句定义表的排序键,优化查询性能。
我这里因为原始数据量过大,sql中排序容易超时,改成Java程序中进行排序
@Override @Transactional(rollbackFor = SQLException.class) public List<LinkedHashMap<String, Object>> getTemplateTestNumber(List<ScientificResearchTemplateDetailVo> vo, Long projectId) { List<LinkedHashMap<String, Object>> results = new ArrayList<>(); for (ScientificResearchTemplateDetailVo v : vo) { List<LinkedHashMap<String, Object>> templateTestNumberBatch = baseMapper.getTemplateTestNumberBatch(v, projectId); // 排序 orderByTime(templateTestNumberBatch); results.addAll(templateTestNumberBatch); } // 根据病案号合并数据 return mergePatientData(results); } /** * 对数据进行排序 * * @param data */ public static void orderByTime(List<LinkedHashMap<String, Object>> data) { // 直接在原列表上进行排序 data.sort((map1, map2) -> { // 获取 orderTime 字符串并转换为 OffsetDateTime OffsetDateTime orderTime1 = (OffsetDateTime) map1.get(ExportConstant.ORDER_TIME); OffsetDateTime orderTime2 = (OffsetDateTime) map2.get(ExportConstant.ORDER_TIME); // 根据 OffsetDateTime 比较两个时间 return orderTime1.compareTo(orderTime2); }); }
4.5. 典型场景对比
场景:分页查询
- MySQL:
- 如果排序字段有索引,分页查询性能较好。
- 如果排序字段无索引,分页查询可能涉及全表扫描和文件排序,性能较差。
- ClickHouse:
- 分页查询性能较好,因为列式存储和并行计算可以加速排序。
- 但需要注意,ClickHouse 的
OFFSET性能较差,建议使用WHERE条件替代分页。
场景:TOP-N 查询
- MySQL:
- 如果排序字段有索引,TOP-N 查询性能较好。
- 如果排序字段无索引,可能涉及全表扫描和文件排序。
- ClickHouse:
- TOP-N 查询性能极佳,因为列式存储和并行计算可以快速完成排序和过滤。
4.6. 总结
MySQL 和 ClickHouse 在排序优化上的区别主要体现在以下几个方面:
- 存储模型:MySQL 是行式存储,排序时需要读取整行数据;ClickHouse 是列式存储,排序时只需读取相关列的数据。
- 索引支持:MySQL 依赖 B+ 树索引优化排序,ClickHouse 依赖列式存储和并行计算。
- 执行方式:MySQL 的排序可能涉及磁盘 I/O,ClickHouse 的排序主要依赖内存和并行计算。
- 优化技巧:MySQL 的排序优化重点是索引和缓冲区配置,ClickHouse 的排序优化重点是减少数据扫描和利用并行计算。
在实际项目中,可以根据业务场景选择合适的数据库,并针对其特点进行排序优化,以充分发挥其性能优势。
5. 改造原因与效果
5.1 改造原因
手术记录相关的表数据量增加了 10 倍,原先 MySQL 在处理这些表的关联查询时性能急剧下降。为了支撑大规模数据的关联查询,决定将部分业务迁移到 ClickHouse。
5.2 改造效果
- 查询性能提升:ClickHouse 的列式存储和向量化执行大幅提升了查询性能,尤其是聚合查询和复杂查询。
- 存储空间节省:ClickHouse 的高压缩比显著减少了存储空间占用。
- 扩展性增强:ClickHouse 的分布式架构支持水平扩展,能够轻松应对数据量的进一步增长。
6. 总结
通过将手术记录相关的业务从 MySQL 迁移到 ClickHouse,我们成功解决了大规模数据关联查询的性能瓶颈。ClickHouse 的高性能、高压缩比和分布式架构使其成为处理大规模数据分析任务的理想选择。在实际项目中,ClickHouse 可以作为 MySQL 的补充,用于处理大规模数据分析任务,而 MySQL 则继续承担事务处理的任务。通过合理的架构设计,可以充分发挥两者的优势,构建高效的数据处理系统。