想象一下,你是一位超级英雄,要对一个庞大的虚拟城市(Web 应用)进行全面的 “健康检查”。JMeter 就是你的神奇工具包,而其中的前置处理器,就像是这个工具包里的各种超级武器,能帮助你轻松应对各种复杂的测试任务。今天,就让我们一起深入了解这些强大的武器,看看它们如何在实际工作中发挥巨大作用。
HTML 链接解析器(HTML Link Parser)
实际场景引入
假如你在测试一个新闻资讯网站,这个网站上有大量的文章链接,还有用户评论表单。你需要模拟用户浏览文章、点击链接查看详情,以及提交评论的操作。要是手动一个个去添加这些链接和表单到测试计划里,那可太麻烦啦!这时候,HTML 链接解析器就像一个勤劳的小助手,能帮你自动搞定这些繁琐的工作。
工作原理详解
当 JMeter 向服务器请求一个网页后,服务器会返回一堆 HTML 代码。HTML 链接解析器就像是一个精通 HTML 语言的 “侦探”,它会仔细地在这堆代码里寻找链接(也就是那些<a>标签里的href属性)和表单(<form>标签)。一旦找到,就把它们提取出来,整理得井井有条,方便 JMeter 后续使用。
操作步骤与示例
- 打开 JMeter,新建一个测试计划。就像你要搭建一个测试的 “战场”,先把场地准备好。
- 添加一个线程组,假设我们设置 10 个线程,这就好比安排 10 个 “小战士” 同时去执行任务。
- 在线程组下添加一个 HTTP 请求,输入你要测试的新闻网站首页地址。
- 接着,在线程组下添加 “HTML Link Parser” 前置处理器。
- 运行测试,你会发现,在结果树里,所有的文章链接和评论表单都被解析出来了,就像小助手给你整理好了一份清单。
HTTP URL 重写修改器(HTTP URL Re - writing Modifier)
工作场景介绍
你在测试一个在线商城,这个商城为了防止用户信息被窃取,采用了一种特殊的方式来保存用户登录后的会话信息,就是把会话 ID 藏在 URL 里,每次请求的 URL 都会被重写。这时候,JMeter 要想模拟用户在商城里逛来逛去,从一个页面跳到另一个页面,还得保证登录状态不掉线,就需要 HTTP URL 重写修改器来帮忙了。
原理剖析
当 JMeter 从服务器拿到一个被重写过 URL 的页面时,HTTP URL 重写修改器就像一个 “URL 密码破解大师”,它能从这个 URL 里找到藏起来的会话 ID。然后,在后续每个线程组发出的请求里,它都会把这个会话 ID 悄悄地添加进去,让服务器以为这些请求都是同一个登录用户发出的。
配置与使用示例
- 同样先搭建好测试计划和线程组,并添加 HTTP 请求指向商城的某个页面。
- 在线程组下添加 “HTTP URL - Re - writing Modifier” 前置处理器。
- 根据商城的 URL 重写规则,在处理器里进行配置。比如,如果重写规则是在 URL 后面加上一串类似
;session=12345的东西,你就在这里设置好相关参数。 - 运行测试,看看每个请求的 URL 是不是都带上了正确的会话 ID。
用户参数(User Parameters)
多用户测试场景需求
假设你要测试一个在线游戏平台,这个平台有很多玩家同时在线。你得模拟不同玩家的行为,比如有的玩家喜欢玩射击游戏,有的喜欢玩角色扮演游戏,而且每个玩家都有自己的账号和密码。这时候,就需要用到用户参数了,它能让每个线程都代表一个不同的玩家,带着自己的 “身份信息” 去测试游戏平台。
功能原理阐述
用户参数就像是一个 “参数制造工厂”,它可以为每个线程定制不同的参数值。这些参数可以在测试计划里提前设置好,也能从一个外部文件(比如 CSV 文件,就像一个存储着所有玩家信息的大表格)里读取。这样,当 JMeter 以多线程的方式运行测试时,每个线程就像一个真实的玩家,用自己的参数去操作游戏平台。
实际设置与测试示例
- 创建测试计划和线程组。
- 在线程组下添加 “User Parameters” 前置处理器。
- 假如我们要模拟三个玩家,就在这里添加三个用户相关的参数,比如 “username1”“password1”“username2”“password2”“username3”“password3”,并分别设置好对应的账号密码。
- 在后续的 HTTP 请求中,比如登录请求,就可以用
${username1}、${password1}这样的形式来引用这些参数。 - 运行测试,你会看到不同的线程用不同的账号登录游戏平台,就像真的有多个玩家在同时登录一样。
BeanShell 前置处理器(BeanShell PreProcessor)
复杂业务场景下的需求
你在测试一个金融交易系统,这个系统的交易金额计算规则特别复杂,要根据当前的汇率、市场波动情况以及用户的会员等级等多个因素来确定。普通的参数设置根本满足不了这个需求,这时候就轮到 BeanShell 前置处理器大显身手啦!它可以让你通过编写代码来实现复杂的计算逻辑。
脚本能力展示
BeanShell 前置处理器就像一个 “代码魔法师”,它允许你在发送请求之前,编写一段 BeanShell 脚本代码。这段代码可以做很多事情,比如根据当前时间生成一个唯一的交易订单号,或者根据用户的等级调整交易手续费。它还能对 JMeter 里的变量进行各种操作,像赋值、修改、判断等等。
代码示例与操作流程
- 创建测试计划、线程组和 HTTP 请求。
- 在线程组下添加 “BeanShell PreProcessor” 前置处理器。
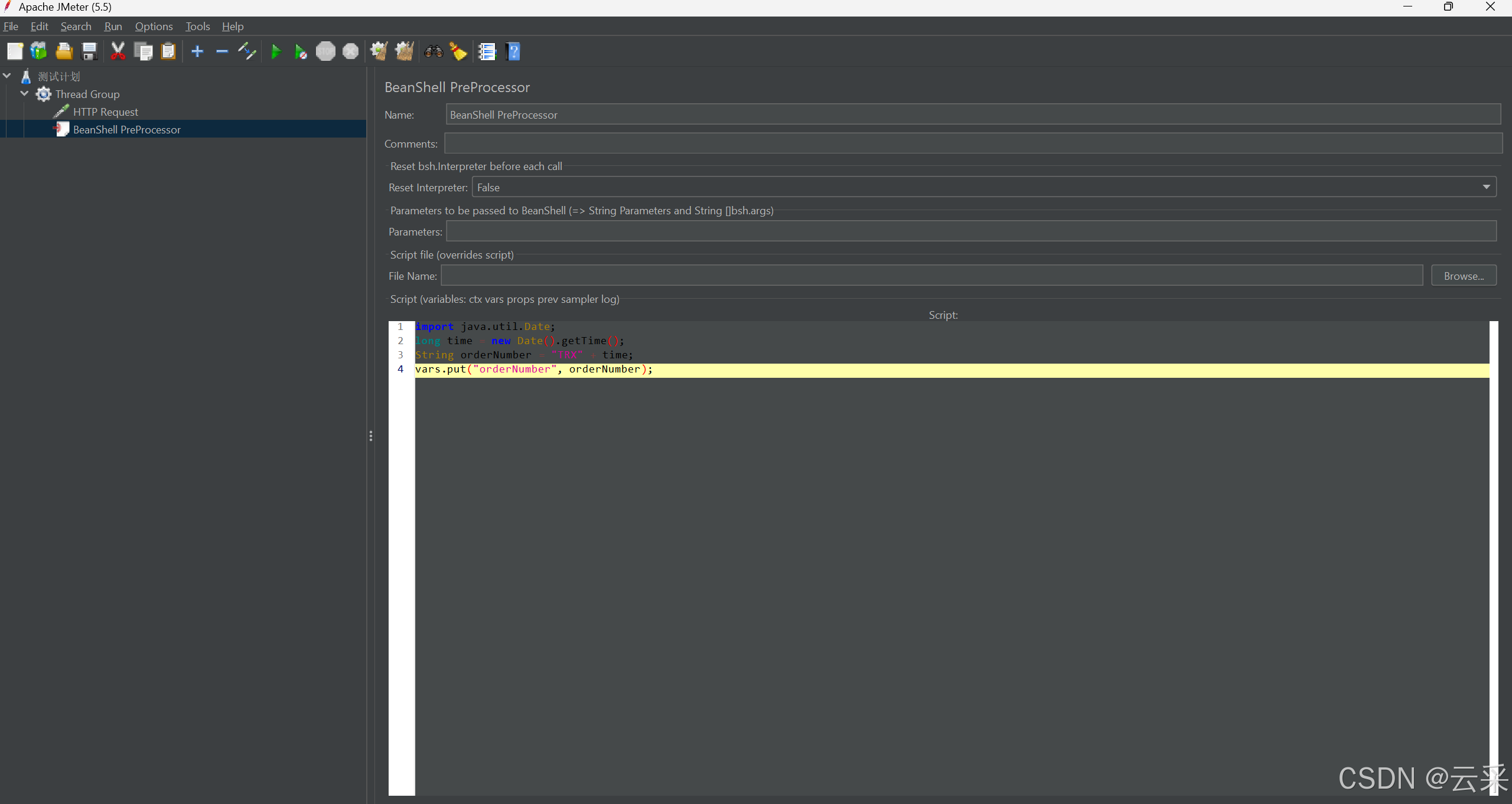
- 在脚本区域编写代码,例如:
import java.util.Date;
long time = new Date().getTime();
String orderNumber = "TRX" + time;
vars.put("orderNumber", orderNumber);
这段代码根据当前时间生成了一个以 “TRX” 开头的唯一订单号,并把它设置为 JMeter 的变量 “orderNumber”。
4. 在后续的 HTTP 请求中,比如提交交易请求时,就可以用${orderNumber}来引用这个订单号。
5. 运行测试,看看请求里是不是带上了正确生成的订单号。
JSR223 前置处理器(JSR223 PreProcessor)
与 BeanShell 对比优势场景
还是以刚才的金融交易系统为例,随着业务的发展,交易逻辑变得更加复杂,对性能的要求也更高了。这时候,虽然 BeanShell 前置处理器能满足需求,但代码写起来有点繁琐,而且性能上也有点力不从心。这时候,JSR223 前置处理器就来救场啦!它支持更多的脚本语言,其中 Groovy 语言特别好用,不仅性能更好,还能让代码写得更简洁、更高效。
支持语言及特性
JSR223 前置处理器就像一个 “多语言脚本舞台”,除了 Groovy,还支持 JavaScript、Python 等多种符合 JSR223 规范的脚本语言。Groovy 语言有很多强大的特性,比如闭包,它可以让你的代码像搭积木一样,简单又灵活。而且它对新的 Java 特性支持得更好,能让你更方便地和现代 Java 开发环境集成。
Groovy 脚本示例与应用
- 创建测试计划、线程组和 HTTP 请求。
- 在线程组下添加 “JSR223 PreProcessor” 前置处理器。
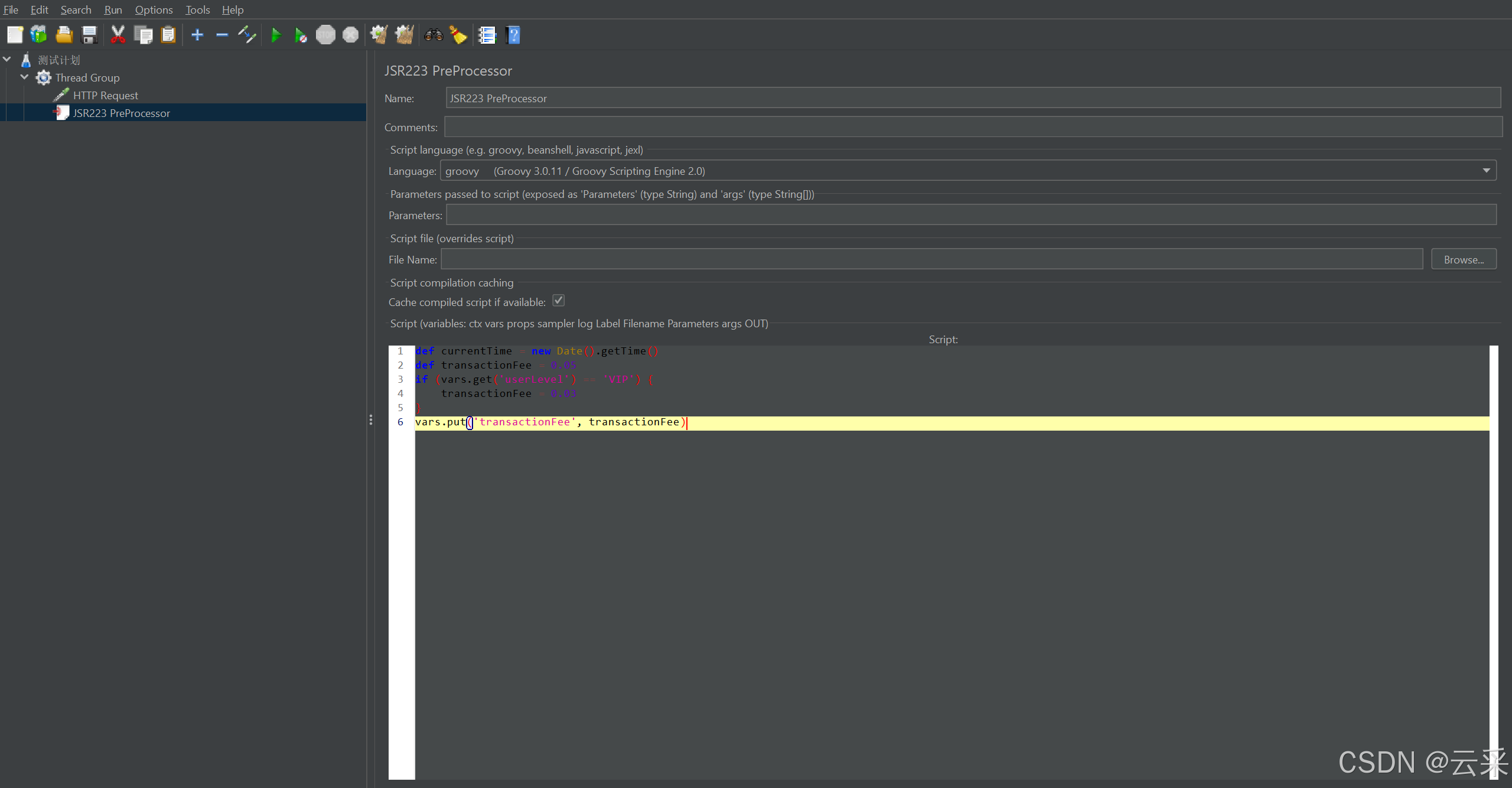
- 在脚本区域选择语言为 “Groovy”,并编写代码,例如:
def currentTime = new Date().getTime()
def transactionFee = 0.05
if (vars.get('userLevel') == 'VIP') {
transactionFee = 0.03
}
vars.put('transactionFee', transactionFee)
这段 Groovy 代码根据用户等级(假设已经存在 “userLevel” 变量)来确定交易手续费,并把结果设置为变量 “transactionFee”。
4. 在后续的 HTTP 请求中,比如计算交易金额时,就可以用${transactionFee}来引用这个手续费。
5. 运行测试,看看交易金额的计算是不是按照正确的手续费来进行的。
JDBC 前置处理器(JDBC PreProcessor)
数据库相关测试场景
你在测试一个在线图书馆管理系统,这个系统的很多功能都和数据库紧密相关。比如,要测试用户借阅书籍的功能,就需要先在数据库里准备一些不同状态的书籍数据,有的是可借阅的,有的是已借出的。这时候,JDBC 前置处理器就派上用场了,它能让你在测试之前,通过执行 SQL 语句来操作数据库,准备好所需的数据。
数据库操作原理
JDBC 前置处理器就像一个 “数据库使者”,它可以在 JMeter 执行 HTTP 请求之前,先和数据库建立连接。然后,你可以通过编写 SQL 语句,让它在数据库里执行各种操作,比如查询数据、插入数据、更新数据等等。执行完后,还可以把查询结果存储为 JMeter 的变量,供后续请求使用。
SQL 语句编写与执行示例
- 首先要确保 JMeter 已经配置好数据库驱动(把数据库驱动 jar 包放到 JMeter 的 lib 目录下,就像给 JMeter 装上了通往数据库的 “钥匙”)。
- 创建测试计划、线程组和 HTTP 请求。
- 在线程组下添加 “JDBC PreProcessor” 前置处理器。
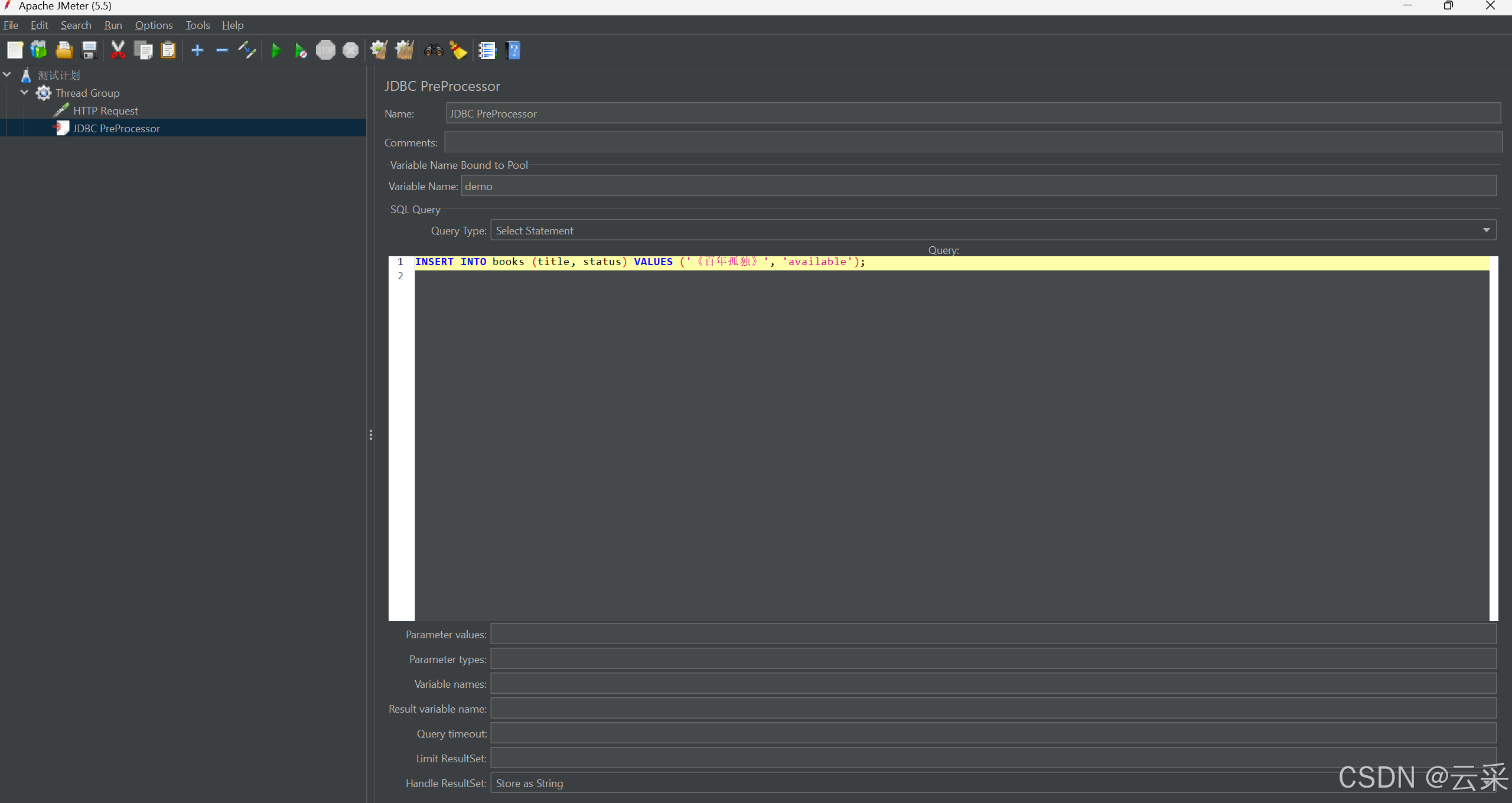
- 在前置处理器中配置数据库连接信息,比如数据库的地址、用户名、密码等。然后编写 SQL 语句,比如:
INSERT INTO books (title, status) VALUES ('《百年孤独》', 'available');
这条语句在数据库里插入了一本名为《百年孤独》且状态为可借阅的书籍。
5. 运行测试,看看数据库里是不是真的多了这本书。
RegEx 用户参数(RegEx User Parameters)
数据关联场景需求
你在测试一个社交媒体平台,用户登录后,可以查看自己的个人信息,然后还能对自己发布的内容进行点赞、评论等操作。在这个过程中,需要从登录后的响应里获取用户的 ID,然后在后续的点赞、评论请求里使用这个 ID。这时候,RegEx 用户参数前置处理器就能帮你实现这个数据关联的需求。
正则表达式提取原理
RegEx 用户参数前置处理器就像一个 “数据提取小能手”,它利用正则表达式这个强大的工具,从 HTTP 请求的响应内容里,按照你设定的规则,精准地提取出你想要的参数值。正则表达式就像是一个定制的 “数据筛选器”,只有符合你设定模式的内容才能被提取出来。
实际表达式编写与应用
- 创建两个 HTTP 请求,一个用于登录,一个用于点赞操作。
- 在登录请求所在的线程组下添加 “RegEx User Parameters” 前置处理器。
- 假设登录响应里用户 ID 的格式是
<user_id>12345</user_id>,那我们可以设置正则表达式为<user_id>(.*?)</user_id>,这里(.*?)就是用来提取用户 ID 的部分。 - 设置提取的变量名为 “userId”。
- 在点赞请求中,用
${userId}作为请求参数,指定要点赞的用户。 - 运行测试,看看点赞请求是不是正确地使用了从登录响应里提取的用户 ID。
样本超时(Sample Timeout)
性能瓶颈场景引入
你在测试一个在线视频播放平台,有时候用户会遇到视频加载特别慢的情况,等了好久都播放不出来。这可能是因为网络不好,也可能是服务器太忙了。在性能测试中,我们要模拟这种情况,看看系统在这种压力下的表现。样本超时前置处理器就能帮我们实现这个测试。
超时机制原理
样本超时前置处理器就像一个 “时间警察”,它为每个 HTTP 请求都设置了一个时间限制。当请求开始执行时,它就开始计时。如果请求在规定的时间内没有完成,它就会果断出手,中断这个请求的执行。这样可以避免因为个别请求长时间不响应,导致整个测试被卡住。
超时设置与结果分析
- 创建测试计划、线程组和 HTTP 请求(假设是请求播放一个视频的请求)。
- 在线程组下添加 “Sample Timeout” 前置处理器。
- 设置超时时间,比如 15000 毫秒(15 秒)。
- 运行测试,如果某个视频请求超过 15 秒还没完成,查看结果中关于这个超时请求的记录。从记录里,我们可以分析出是哪个环节可能出了问题,是网络延迟太高,还是服务器处理能力不足。