文章来自于李强老师nodejs讲解时的内容总结,记录后便于之后复习使用
目录
一、概念
HTTP
(
hypertext transport protocol
)协议;中文叫
超文本传输协议,
是一种基于
TCP/IP的应用层通信协议,这个协议详细规定了
浏览器
和万维网
服务器
之间互相通信的规则。
协议中主要规定了两个方面的内容:
- 客户端:用来向服务器发送数据,可以被称之为请求报文
- 服务端:向客户端返回数据,可以被称之为响应报文
报文:可以简单理解为就是一堆字符串
二、请求报文的组成
- 请求行
- 请求头
- 空行
- 请求体
三、HTTP 的请求行
- 请求方法(get、post、put、delete等)
- 请求 URL(统一资源定位器)
例如:
http://www.baidu.com:80/index.html?a=100&b=200#logo
- http: 协议(https、ftp、ssh等)
- www.baidu.com 域名
- 80 端口号
- /index.html 路径
- a=100&b=200 查询字符串
- #logo 哈希(锚点链接)
- HTTP协议版本号
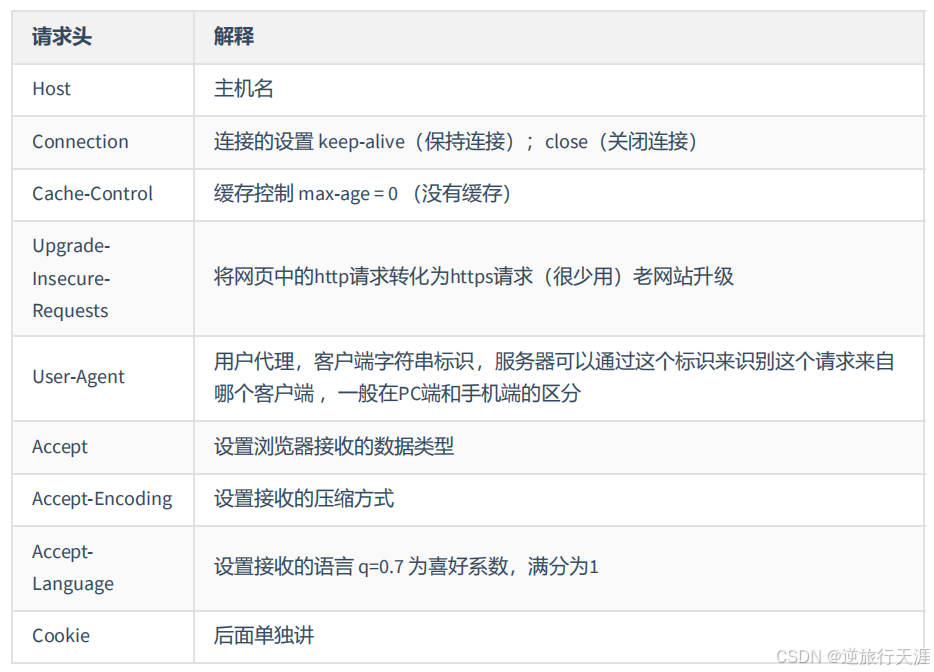
四、HTTP 请求头
格式:『头名:头值』
常见的请求头有:
五、HTTP 的请求体
请求体内容的格式是非常灵活的,(可以是空) ==> GET 请求,(也可以是字符串,还可以是 JSON ) ===> POST 请求
例如:
字符串:
keywords=
手机
&price=2000
JSON
:
{"keywords":"
手机
","price":2000}
六、响应报文的组成
- 响应行
HTTP/1.1 200 OK
- HTTP/1.1:HTTP协议版本号
- 200:响应状态码 404 Not Found 500 Internal Server Error
还有一些状态码,参考:
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
- OK:响应状态描述
- 响应状态码和响应字符串关系是一一对应的。
- 响应头
Cache-Control: 缓存控制 private 私有的,只允许客户端缓存数据Connection 链接设置Content-Type:text/html;charset=utf-8 设置响应体的数据类型以及字符集 , 响应体为 html ,字符集utf-8Content-Length: 响应体的长度,单位为字节
- 空行
- 响应体
- 响应体内容的类型是非常灵活的,常见的类型有 HTML、CSS、JS、图片、JSON
七、创建 HTTP 服务(重点)
使用
nodejs
创建
HTTP
服务
7.1 操作步骤
//1. 导入 http 模块
const http = require('http');
//2. 创建服务对象 create 创建 server 服务
// request 意为请求. 是对请求报文的封装对象, 通过 request 对象可以获得请求报文的数据
// response 意为响应. 是对响应报文的封装对象, 通过 response 对象可以设置响应报文
const server = http.createServer((request, response) => {
response.end('Hello HTTP server');
});
//3. 监听端口, 启动服务
server.listen(9000, () => {
console.log('服务已经启动, 端口 9000 监听中...');
});7.2 测试
浏览器请求对应端口
http : //127.0.0.1:9000
7.3 注意事项
1.
命令行
ctrl + c
停止服务
2.
当服务启动后,更新代码
必须重启服务才能生效
3.
响应内容中文乱码的解决办法
response.setHeader('content-type','text/html;charset=utf-8');
4.
端口号被占用
Error: listen EADDRINUSE: address already in use :::9000
1
)关闭当前正在运行监听端口的服务 (
使用较多
)
2
)修改其他端口号
5. HTTP
协议默认端口是
80
。
HTTPS
协议的默认端口是
443, HTTP
服务开发常用端口有
3000
,
8080
,
8090
,
9000
等
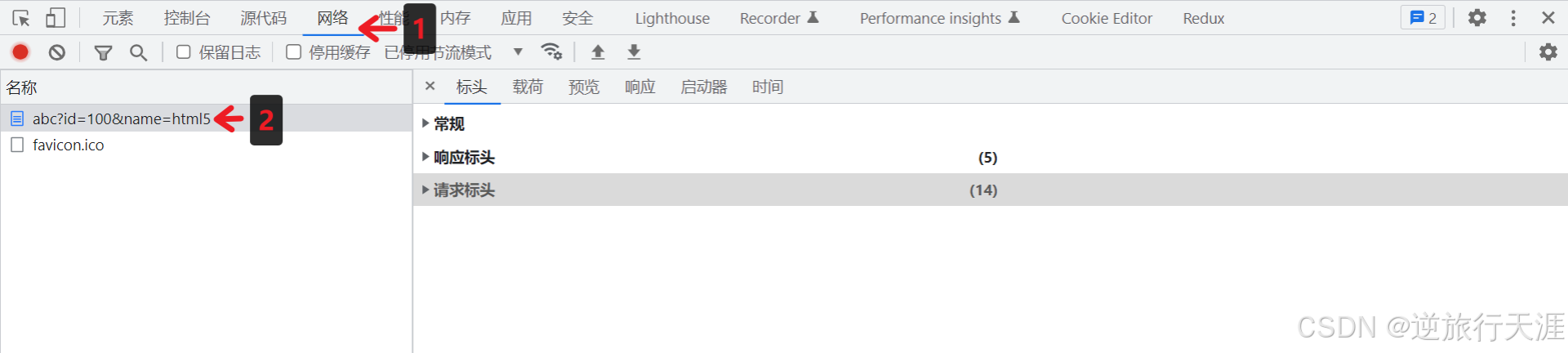
八、浏览器查看 HTTP 报文
点击步骤
8.1
查看请求行与请求头

8.2
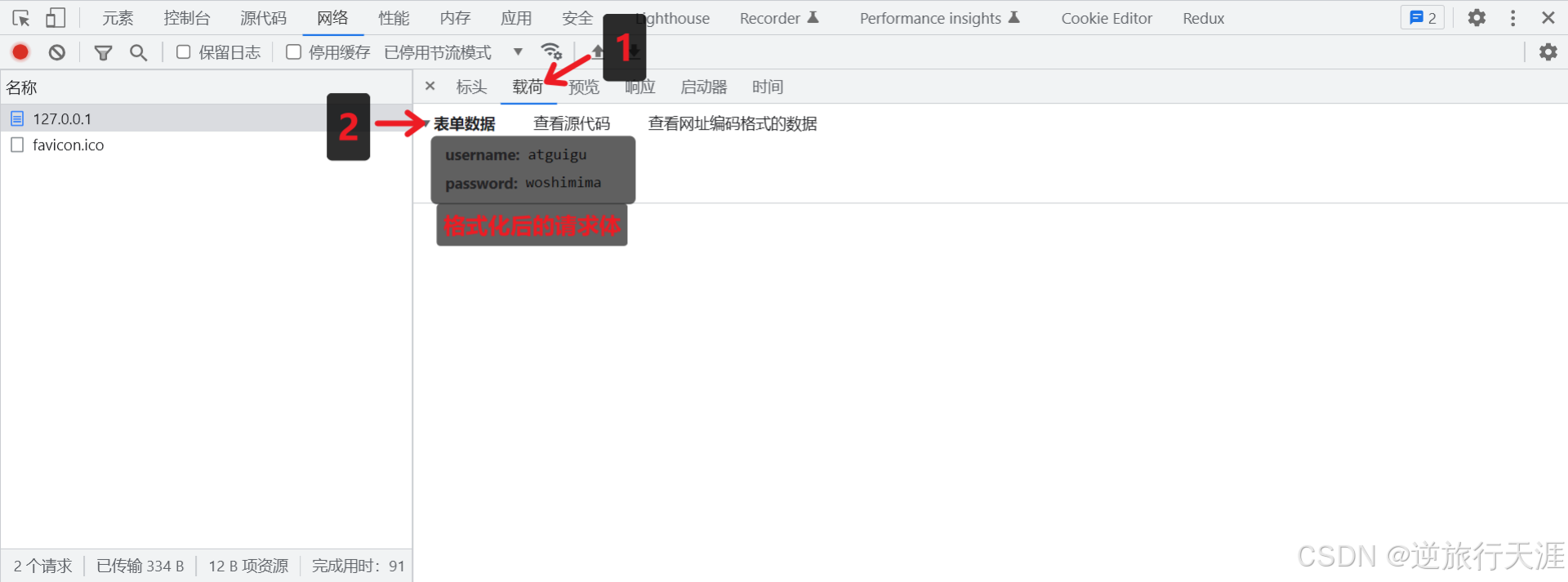
查看请求体
8.3
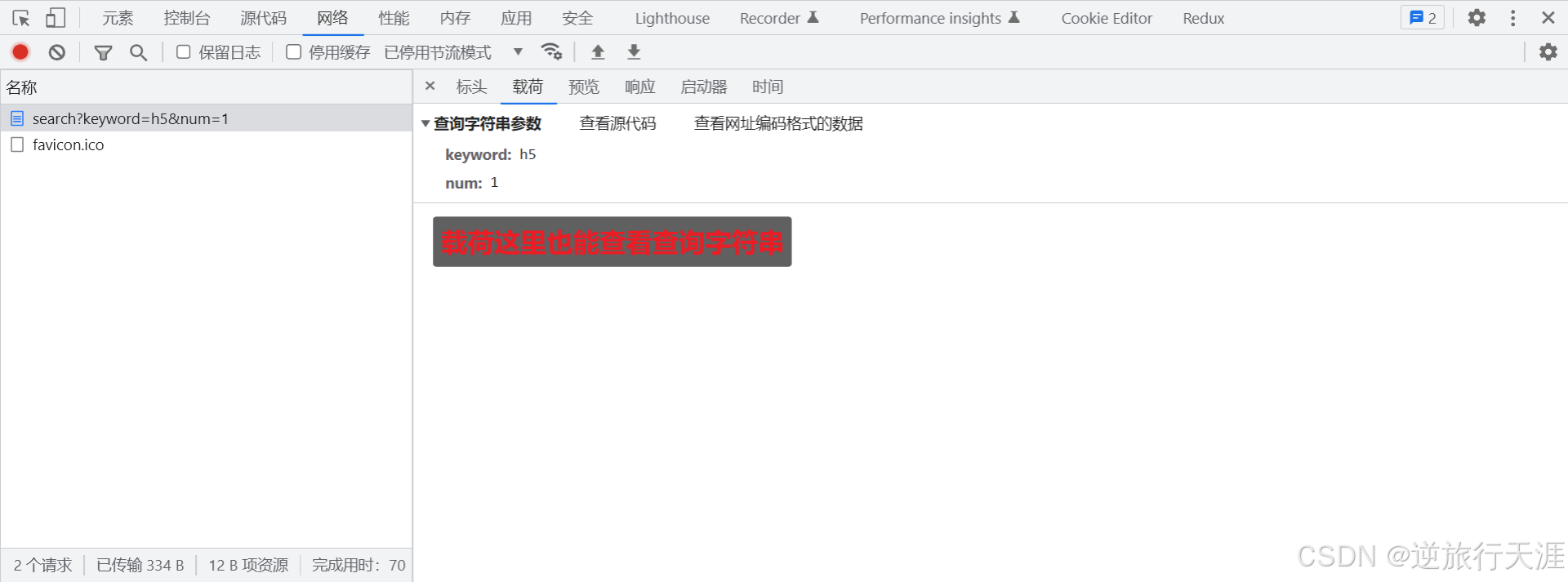
查看
URL
查询字符串
8.4
查看响应行与响应头
8.5
查看响应体
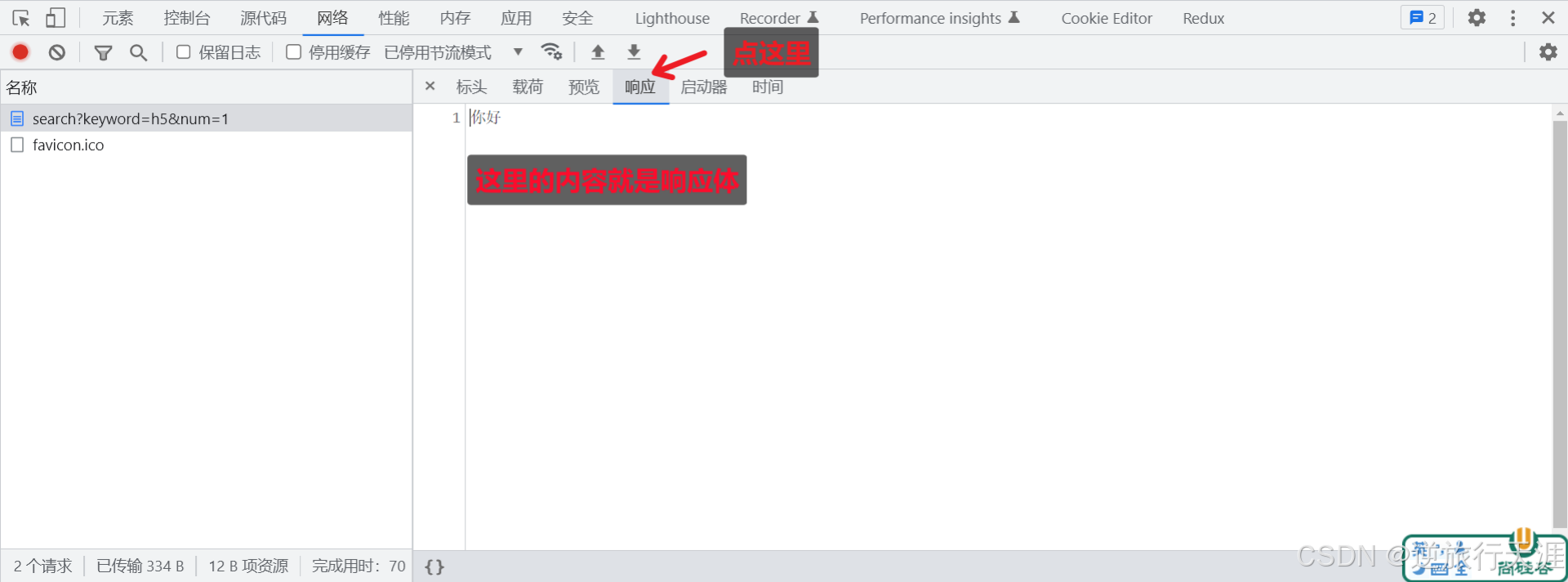
九、获取 HTTP 请求报文
想要获取请求的数据,需要通过
request
对象

注意事项:1. request.url 只能获取路径以及查询字符串,无法获取 URL 中的域名以及协议的内容2. request.headers 将请求信息转化成一个对象,并将属性名都转化成了『小写』3. 关于路径:如果访问网站的时候,只填写了 IP 地址或者是域名信息,此时请求的路径为『 / 』4. 关于 favicon.ico :这个请求是属于浏览器自动发送的请求
十、设置 HTTP 响应报文

write 和 end 的两种使用情况:
//1. write 和 end 的结合使用 响应体相对分散
response.write('xx');
response.write('xx');
response.write('xx');
response.end(); //每一个请求,在处理的时候必须要执行 end 方法的
//2. 单独使用 end 方法 响应体相对集中
response.end('xxx');十一、网页资源的基本加载过程
网页资源的加载都是循序渐进的,首先获取
HTML
的内容, 然后解析
HTML 在发送其他资源的请求,如 CSS
,
Javascript
,图片等。
理解了这个内容对于后续的学习与成长有非常大的帮助