2025年安居客二手小区数据爬取
这段时间需要爬取安居客二手小区数据,看了一下相关教程基本也都有点久远,趁着新年期间我也把自己爬取的思路跟流程记录一下(适合有一点爬虫基础的宝宝食用),如有不对,欢迎私信交流~
观察目标网页
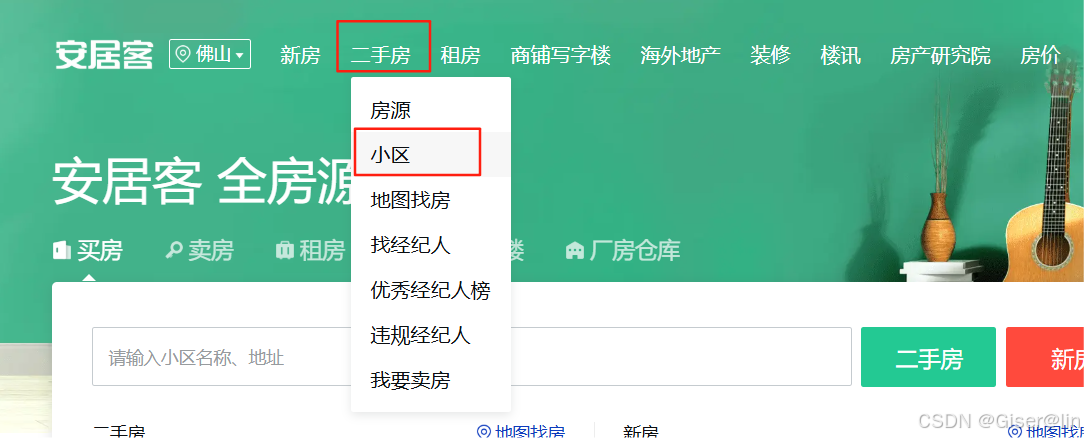
我们这里爬取的是安居客二手小区数据,从官网进去
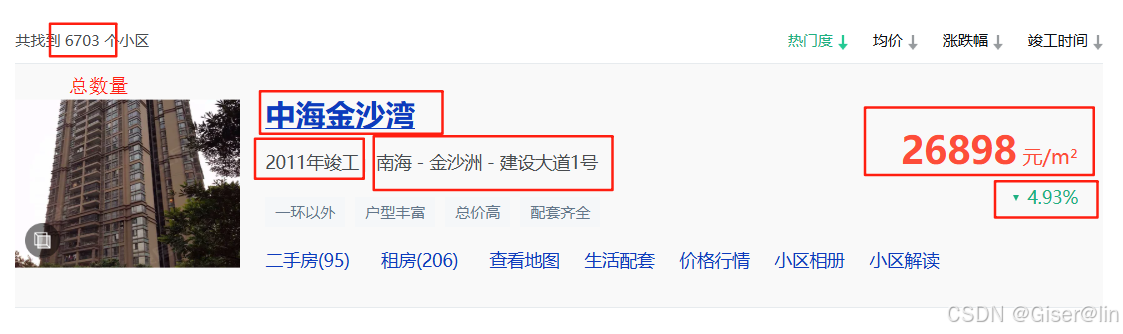
这里看到小区的总数量,以及相关的小区的名字等信息,红框框起来的数据一般是我们所关心的
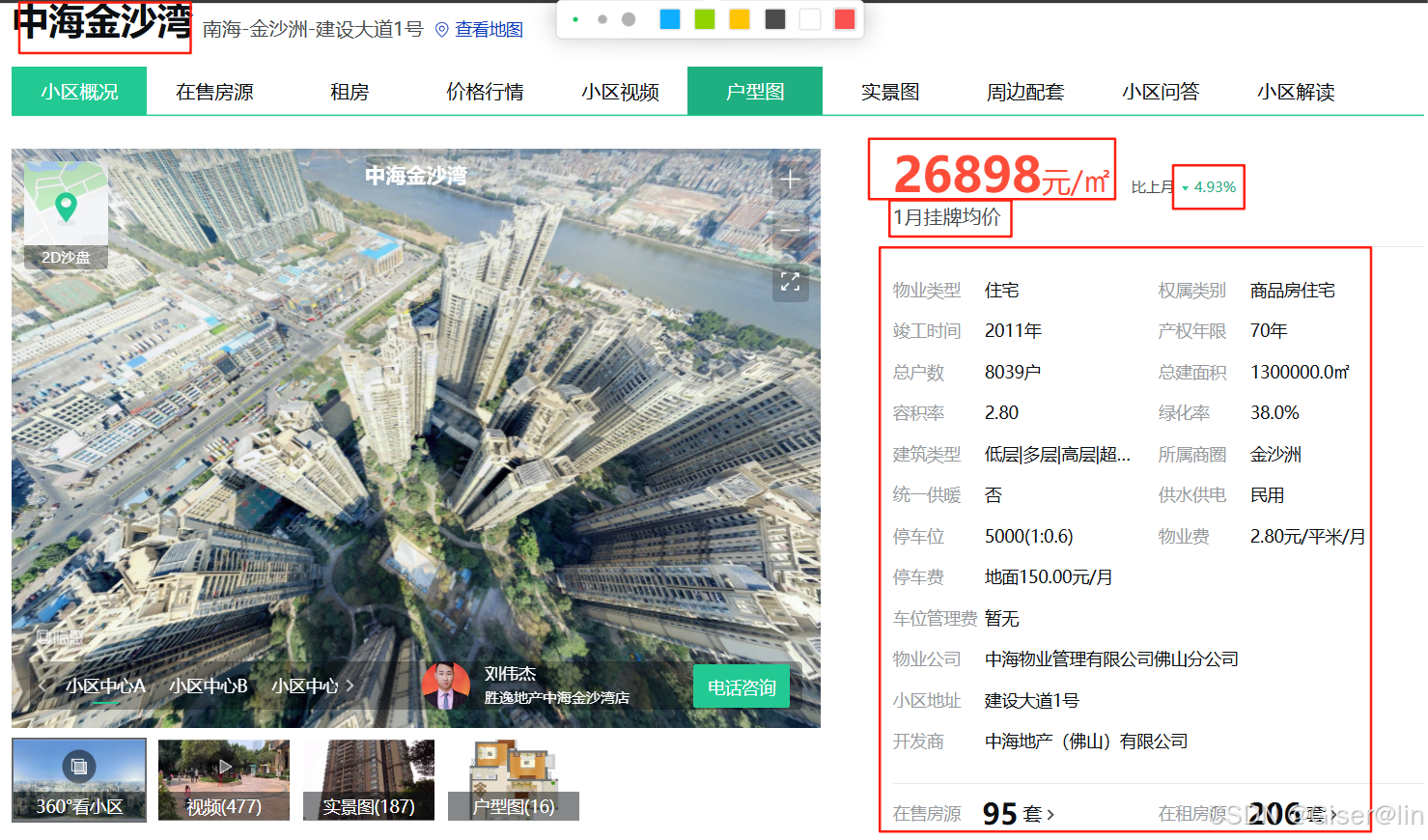
当然,点击小区可以进入详情页,这里列出了关于该小区更加具体的信息,我们这里尝试把框起来的数据都爬取下来!
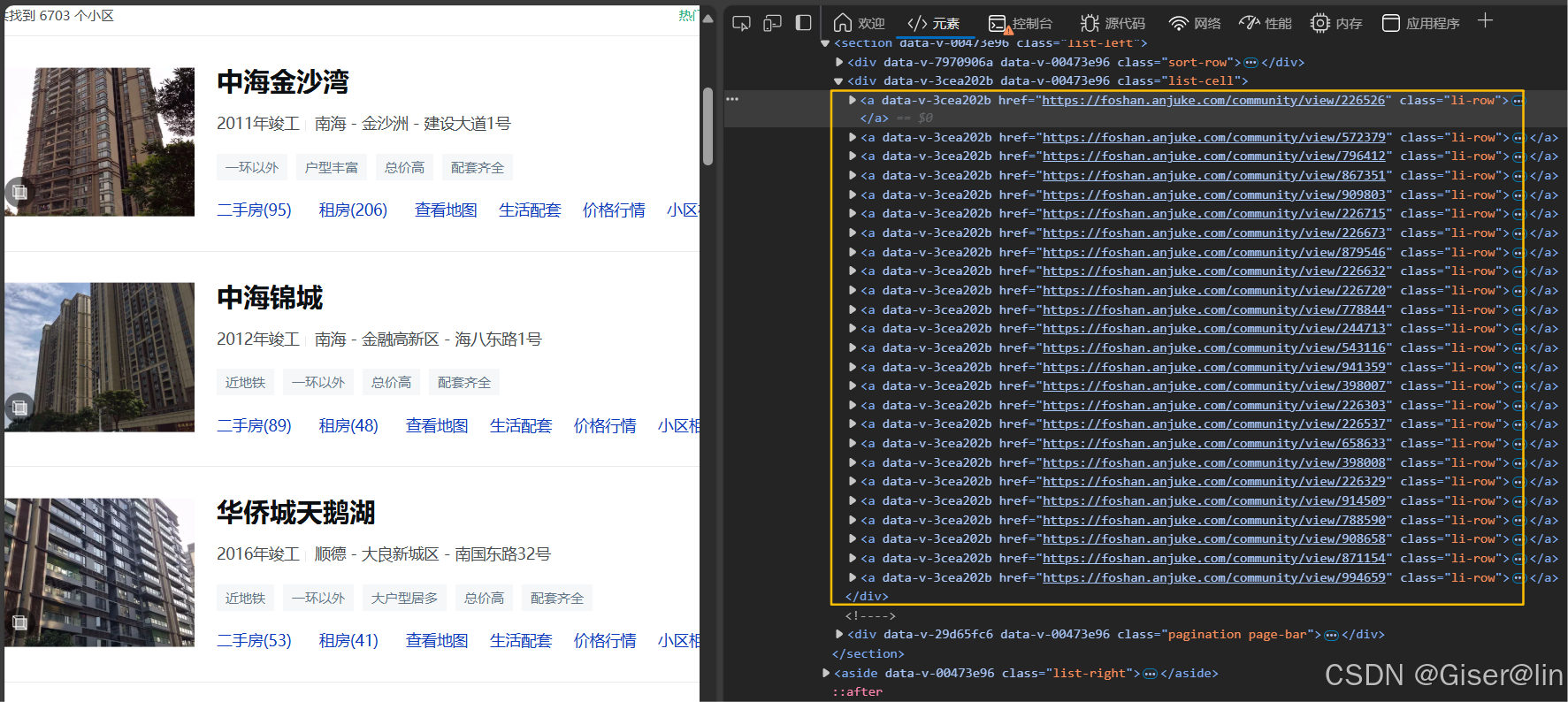
知道了我们需要爬取的数据之后,下一步我们需要进一步分析这些数据的来源——数据是写在静态网页中还是从服务器异步加载过来的,让我们分析一下网页结构:
从上面这张图里我们可以发现数据是写在了html的源码里的,每个小区的数据都包裹在一个li-row的a标签里面,因此我们只需要把list-cell里面的所有li-row都遍历一遍,就可以获取一页的小区相关数据,当然这里还没包含详情页数据~

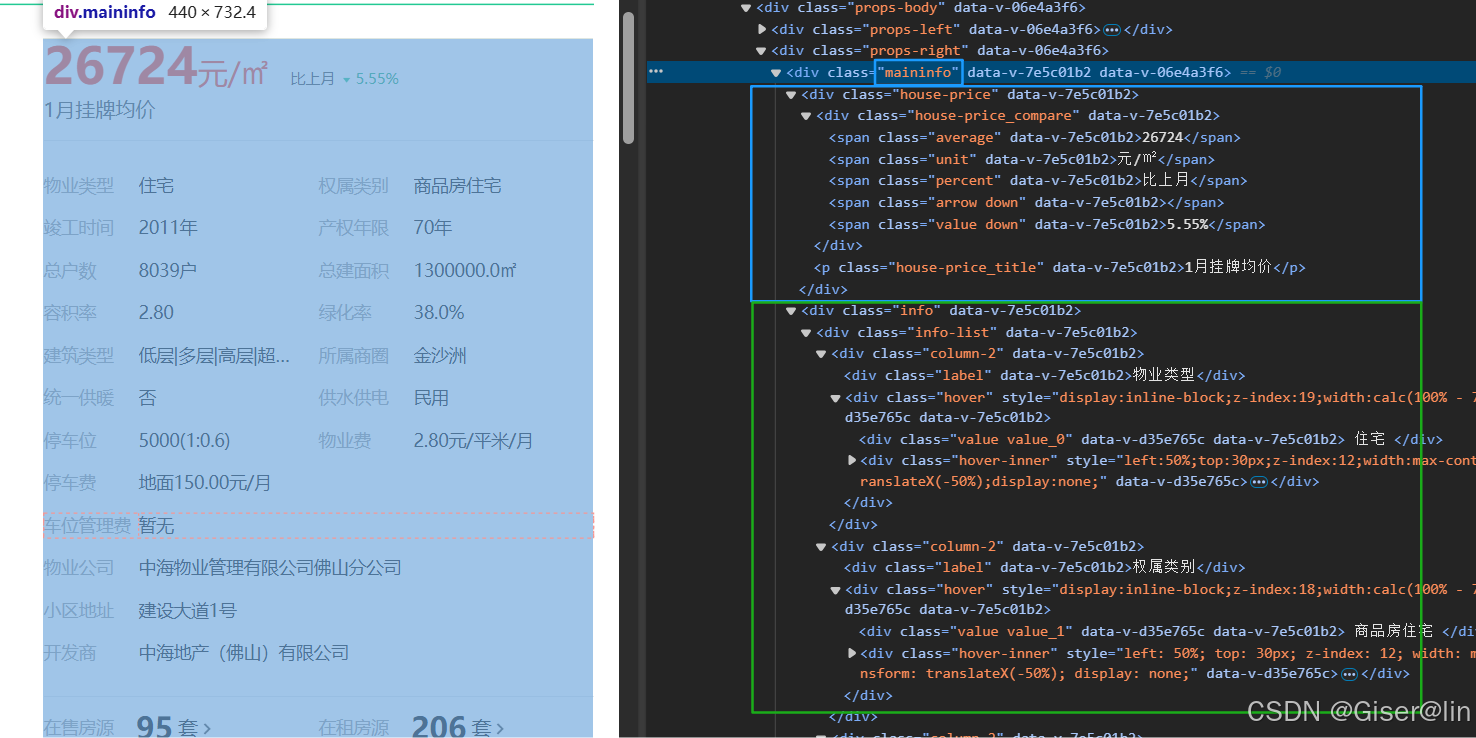
观察详情页数据
我们可以发现这个小区详情页的数据会存放在maininfo的div大盒子里面,然后这个大盒子里由house-price跟info两个div小盒子组成,因此我们只需要从这两个小盒子里取数据即可~下面开始搓我们的代码!
准备工作:安装装备就像打游戏
1️⃣ 装Python环境(不会的看这里)
👉 去Python官网下载最新版,安装时记得勾选"Add Python to PATH"
2️⃣ 安装必备武器库(打开cmd / powershell)
pip install requests beautifulsoup4
💡 这俩库相当于你的"爬虫工具箱",一个负责上网,一个负责解析网页
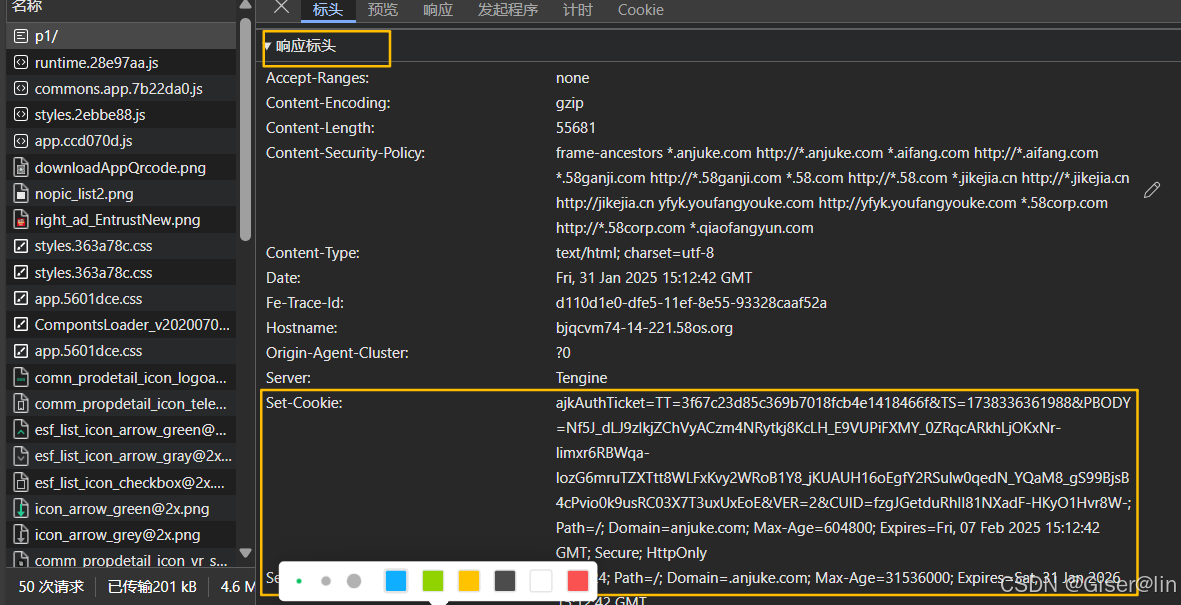
3️⃣ 准备VIP通行证 (Cookie获取)
cookie的作用可以让我们在模拟登陆的时候维持一下会话,因为安居客这个网站每隔一段时间就需要输入一下验证码或者重新登陆,设置一下cookie方便很多!!!
具体自己浏览器的cookie在登陆之后,按F12打开开发者工具,找到Network标签 → 刷新页面 → 随便选个请求 → 复制一下响应标头里的set-cookie里的内容即可~
代码详解:每行代码都是你的小兵
🛠️ 先看整体作战计划:
"""
作战目标:自动抓取指定数量的小区信息
作战路线:列表页 → 详情页 → 数据保存
武器配置:requests发请求,BeautifulSoup解析
特殊装备:自动重试机制防掉线
"""
🎯 核心代码拆解(重点!)
- 配置侦察兵参数
# 伪装成浏览器(重要!)
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)...' # 完整UA太长省略
}
# 你的VIP通行证(定期更新!)
COOKIES = {
'ajkAuthTicket': 'TT=3f67c23d85c369b7018fcb4e...', # 填你复制的Cookie
'ctid': '24'
}
- 创建不死鸟连接器
def create_session():
session = requests.Session()
# 配置自动重试(网络不好也不怕)
adapter = HTTPAdapter(max_retries=Retry(
total=3,
backoff_factor=1,
status_forcelist=[500, 502, 503, 504]
))
session.mount('https://', adapter)
return session
💡 这个相当于你的"网络保镖",遇到问题自动重试三次
3. 万能数据提取器
def safe_get_text(element, selector, default='N/A'):
""" 安全提取文本,找不到元素也不报错 """
target = element.select_one(selector)
return target.text.strip() if target else default
🌟 使用场景:就像用镊子精准夹取页面数据,夹不到就返回默认值
4. 主力作战部队(main函数)
def main():
# 输入要抓多少小区
community_count = int(input("想抓多少小区?输入数字:"))
# 创建侦察兵小队
with open('小区数据.csv', 'w', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['小区名称', '价格', '地址', ...]) # 完整表头
# 开始翻页抓取
for page in range(1, 总页数+1):
# 获取当前页所有小区链接
# 逐个访问详情页提取数据
# 保存到CSV
# 休息0.5秒防止被封
💡 这里用了with open自动管理文件,就像有个小秘书帮你保存数据
完整代码大放送
"""
安居客小区信息爬虫
"""
import csv
import time
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
from bs4 import BeautifulSoup
# ========================== 全局配置 ==========================
# 请求头配置(模拟浏览器访问)
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0',
'Referer': 'https://member.anjuke.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
}
# Cookies配置(需要定期更新)
COOKIES = {
'ajkAuthTicket': 'TT=3f67c23d85c369b7018fcb4e1418466f&TS=1738219179437&PBODY=IotzzfNhkTJKGH_LuUrSfcNHUGin1wBsHjAQYBL3k0USZDHrUxL6RQUv1ZsFPDHjxvQl0uvU2zSgIEdSFCHUc7wYEf4slKV2U2F9rwNnp6xHgufTxMgdYWZEob_Tep-poDqBMbQQgayOQhsaRgVjw8K8ut3QqqMfPgYGpKJJBHw&VER=2&CUID=fzgJGetduRhII81NXadF-HKyO1Hvr8W-',
'ctid': '24',
}
# 重试策略配置
RETRY_STRATEGY = Retry(
total=3, # 最大重试次数
backoff_factor=1, # 重试等待时间因子
status_forcelist=[500, 502, 503, 504], # 需要重试的状态码
allowed_methods=frozenset(['GET', 'POST']) # 允许重试的HTTP方法
)
# 其他配置
BASE_URL = 'https://foshan.anjuke.com/community/p{page}/' # 分页URL模板
REQUEST_DELAY = 0.5 # 请求间隔时间(秒),防止被封禁
CSV_HEADERS = [ # CSV文件表头
'小区名称', '价格', '地址', '小区链接',
'物业类型', '权属类别', '竣工时间', '产权年限', '总户数', '总建筑面积', '容积率',
'绿化率', '建筑类型', '所属商圈', '统一供暖', '供水供电', '停车位', '物业费',
'停车费', '车位管理费', '物业公司', '小区地址', '开发商', '在售房源', '在租房源'
]
# ========================== 工具函数 ==========================
def create_session():
"""
创建带有重试策略的请求会话
返回:
requests.Session - 配置好的会话对象
"""
session = requests.Session()
adapter = HTTPAdapter(max_retries=RETRY_STRATEGY)
session.mount('https://', adapter)
session.mount('http://', adapter)
return session
def safe_get_text(element, selector, default='N/A'):
"""
安全获取元素文本内容
参数:
element: BeautifulSoup对象 - 父元素
selector: str - CSS选择器
default: str - 默认返回值
返回:
str - 元素的文本内容或默认值
"""
target = element.select_one(selector)
return target.get_text(strip=True) if target else default
# ========================== 主程序 ==========================
def main():
# 用户输入
community_count = int(input("请输入需要抓取的小区数量:"))
# 初始化会话
session = create_session()
# 准备CSV文件
with open('communities.csv', mode='w', newline='', encoding='utf-8') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(CSV_HEADERS)
page_count = (community_count // 25) + (1 if community_count % 25 else 0)
collected = 0 # 已收集数量
# 分页抓取
for current_page in range(1, page_count + 1):
print(f"\n➤ 正在处理第 {current_page}/{page_count} 页...")
# 获取列表页
try:
list_url = BASE_URL.format(page=current_page)
response = session.get(
list_url,
headers=HEADERS,
cookies=COOKIES,
timeout=10
)
response.raise_for_status()
except Exception as e:
print(f"⚠️ 列表页请求失败: {e}")
continue
# 解析小区列表
list_soup = BeautifulSoup(response.text, 'html.parser')
communities = list_soup.find_all('a', class_='li-row')
# 遍历每个小区
for community in communities:
if collected >= community_count:
break
# 提取基本信息
name = safe_get_text(community, 'div.li-title')
price = safe_get_text(community, 'div.community-price')
address = safe_get_text(community, 'div.props')
link = community.get('href', '')
print(f"\n▌ 正在处理小区:{name}")
# 获取详情页
try:
detail_response = session.get(
link,
headers=HEADERS,
cookies=COOKIES,
timeout=15
)
detail_response.raise_for_status()
except Exception as e:
print(f" ⚠️ 详情页请求失败: {e}")
continue
# 解析详情页
detail_soup = BeautifulSoup(detail_response.text, 'html.parser')
details = []
# 提取主要信息
for index in range(14): # 0-13对应预设的标签
value = safe_get_text(detail_soup, f'div.value.value_{index}')
details.append(value)
# 提取额外信息
extra_info = {
'停车费': 'N/A',
'车位管理费': 'N/A',
'物业公司': 'N/A',
'小区地址': 'N/A',
'开发商': 'N/A'
}
for column in detail_soup.find_all('div', class_='column-1'):
label = safe_get_text(column, 'div.label')
value = safe_get_text(column, 'div.value')
for key in extra_info:
if key in label:
extra_info[key] = value
# 提取房源信息
sale = detail_soup.find('div', class_='sale')
rent = detail_soup.find('div', class_='rent')
sale_info = f"{safe_get_text(sale, 'i.source-number')} {safe_get_text(sale, 'i.source-unit')}" if sale else 'N/A'
rent_info = f"{safe_get_text(rent, 'i.source-number')} {safe_get_text(rent, 'i.source-unit')}" if rent else 'N/A'
# 构建完整数据行
row = [
name, price, address, link,
*details,
*extra_info.values(),
sale_info, rent_info
]
# 写入CSV
writer.writerow(row)
collected += 1
print(f" ✅ 已保存 {collected}/{community_count} - {name}")
# 请求间隔
time.sleep(REQUEST_DELAY)
print("\n🎉 数据抓取完成!结果已保存到 communities.csv")
if __name__ == '__main__':
main()
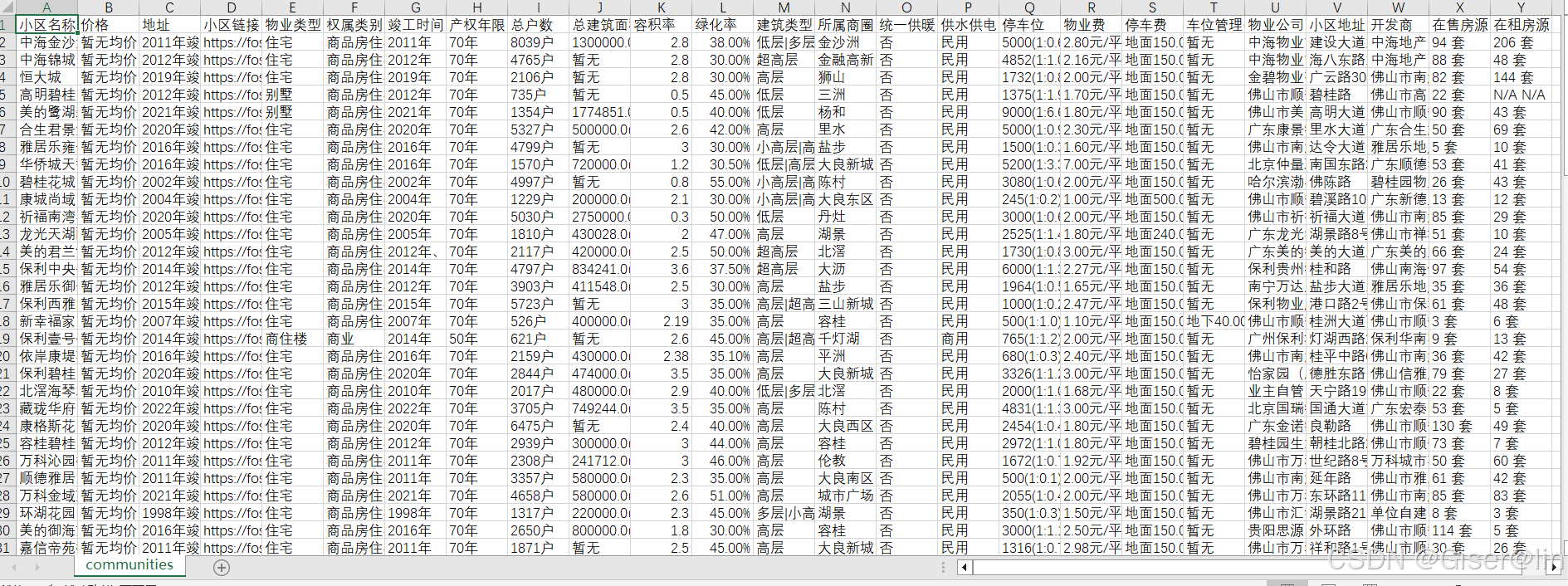
爬取结果
这是爬取的结果,如果只要其中的部分列,我建议直接删除最终的csv表格,而不是修改代码,代码能运行就尽量别动 -_-!!!

完结撒花~
参考文章:
[1]: 菜鸟爬虫——获取安居客二手房信息
[2]:Python爬虫之路(9)–an居客数据获取
[3]:Python之爬取安居客网二手房小区详情页数据
[4]:python使用代理爬取安居客二手房数据(一)
[5]:(项目)爬取安居客二手房房屋信息
[6]:【爬虫】安居客二手房数据爬取