《Linux6.5源码分析:进程管理与调度系列文章》
本系列文章将对进程管理与调度进行知识梳理与源码分析,重点放在linux源码分析上,并结合eBPF程序对内核中进程调度机制进行数据实时拿取与分析。
在进行正式介绍之前,有必要对文章引用进行提前说明。本系列文章参考了大量的博客、文章以及书籍:
-
《深入理解Linux内核》
-
《Linux操作系统原理与应用》
-
《奔跑吧Linux内核》
-
《深入理解Linux进程与内存》
-
《基于龙芯的Linux内核探索解析》
Linux进程调度与管理:(五)进程的调度之调度节拍
在之前的文章中,我们介绍了进程是如何被创建出来的(我称之为进程肉体重塑)、进程是如何加载并启动的(我称之为进程灵魂注入)、进程的调度时机(进程何时加入就绪队列、何时被调度上CPU),以及进程调度时执行进程切换的细节,具体详细信息请参考以下文章:
- Linux 进程管理与调度:(零)预备知识
- Linux 进程管理与调度:(一)进程的创建与销毁
- Linux 进程调度与管理:(二)进程的加载与启动
- Linux 进程调度与管理:(三)进程的调度之调度时机
- Linux 进程调度与管理:(四)进程的调度之schedule进程切换
我们在本系列第三篇文章中介绍了进程调度时机,其中涉及到了进程何时加入就绪队列,何时触发调度,在介绍被动调度时讲到了调度时机中的何时触发调度,我们用一张图回忆一下,上一篇文章涉及到的调度时机(也就是何时调用schedule函数),其中涉及到调度节拍,每当调度节拍被触发,都会判断是否需要触发抢占。本篇文章将接着Linux 进程调度与管理:(三)进程的调度之调度时机对调度节拍展开讲讲。
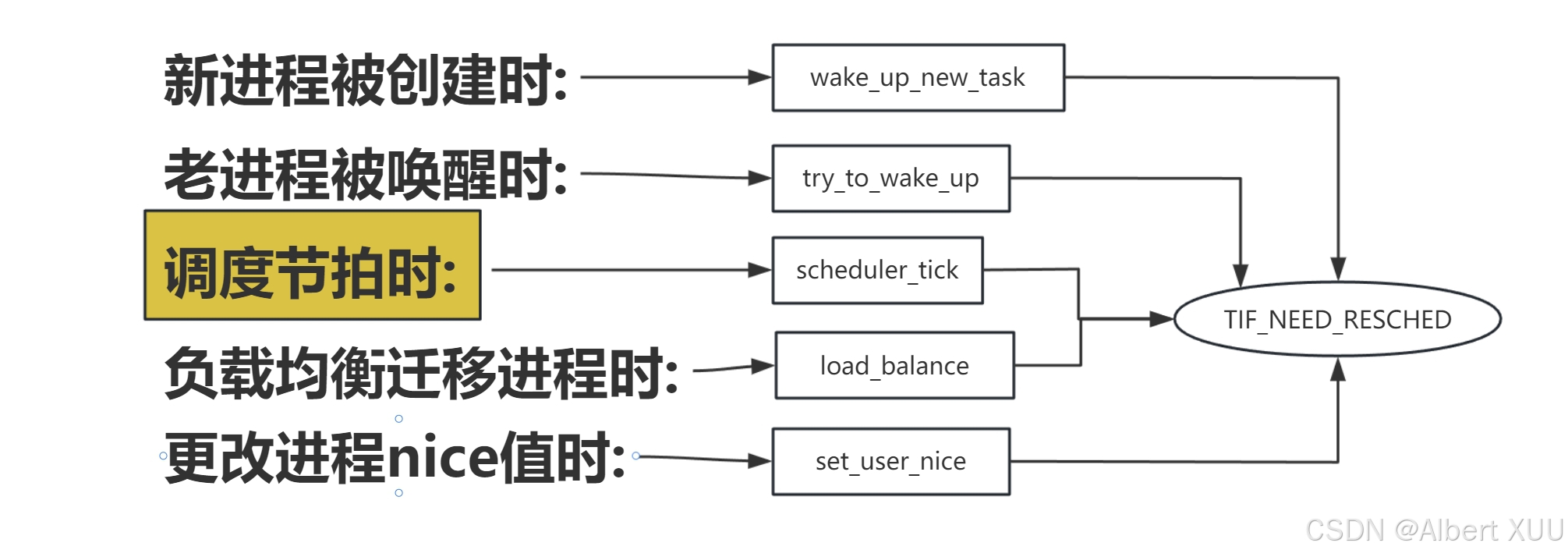
1. 调度节拍/周期调度 scheduler_tick()
在Linux中有一套时钟节拍机制,计算机系统随着时钟节拍需要周期性地做很多事着,例如刷新屏幕、数据落盘、进程调度等。Linux每隔固定周期会发出timer interrupt (IRQ0),HZ用来定义每一秒有多少次timer interrupt。
对于任务调度器来说,定时器驱动的调度节拍是一个很重要的调度时机。时钟节拍最终会调用调度类的task_tick,完成调度相关的工作,会在这里判断是否需要调度下一个任务来抢占当前CPU核。也会触发多核之间任务队列的负载均衡。保证不让忙的核忙死,闲的核闲死。调度节拍的核心入口是scheduler_tick。
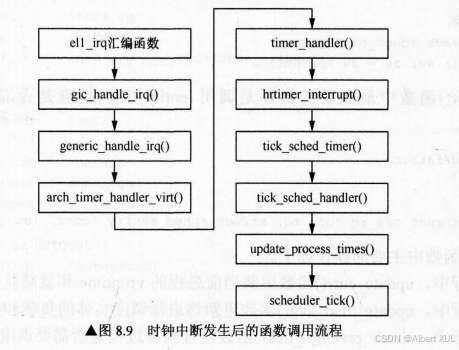
每隔固定的时间, 时钟中断会被触发一次,此时内核会依靠周期性的时钟中断来处理CPU的控制权,具体是Linux调度器的scheduler_tick()函数被调用;
当时钟中断被触发后,会经过如下的调用流程,最终调用scheduler_tick()函数;
我们看一下schedule_tick函数的执行流程, 其实就是在获取完所在cpu的就绪队列之后,调用当前调度类中的ops, task_tick函数执行, 最终再进行负载均衡操作;
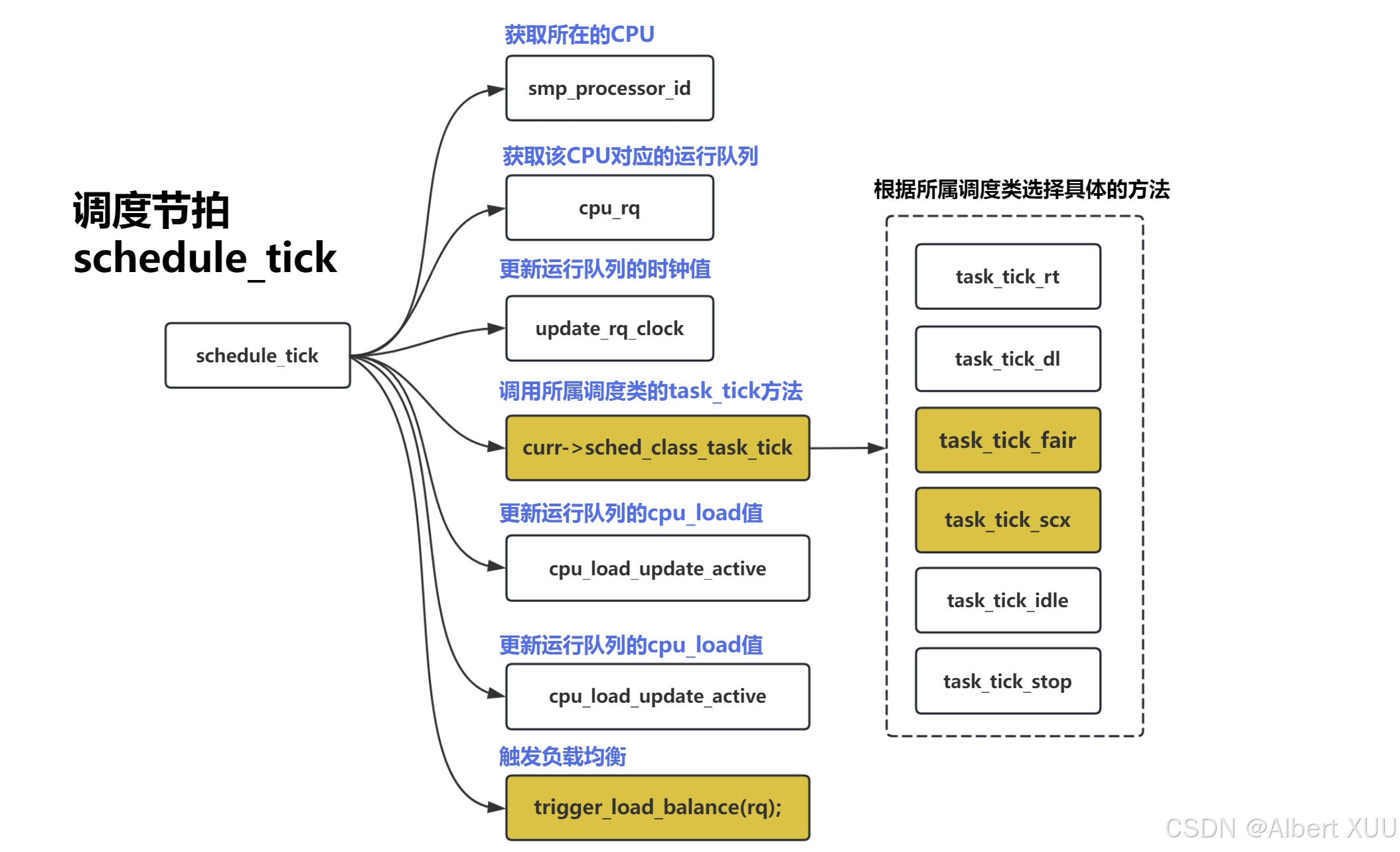
其实scheduler_tick()函数主要是调用当前调度类中的task_tick函数执行相关操作;
void scheduler_tick(void)
{
int cpu = smp_processor_id();//当前CPU号
struct rq *rq = cpu_rq(cpu);//当前核的运行队列
struct task_struct *curr = rq->curr;//该cpu上运行的进程
struct rq_flags rf;
unsigned long thermal_pressure;/*热压*/
u64 resched_latency;
if (housekeeping_cpu(cpu, HK_TYPE_TICK))
arch_scale_freq_tick();// 如果是管理CPU,更新CPU频率缩放
sched_clock_tick(); // 更新调度时钟
/*1.更新运行队列的时钟及负载信息*/
rq_lock(rq, &rf);
update_rq_clock(rq);///*1.更新运行队列的时钟计数*/
thermal_pressure = arch_scale_thermal_pressure(cpu_of(rq)); // 获取CPU热压力
update_thermal_load_avg(rq_clock_thermal(rq), rq, thermal_pressure);// 更新热负载平均值
/*2.判断是否需要调度下一个任务
* 不同调度类使用对应的task_tick函数实现
* 用于检查当前进程是否已经运行足够长时间,是否需要被调度出去;
*/
curr->sched_class->task_tick(rq, curr, 0);
if (sched_feat(LATENCY_WARN))
resched_latency = cpu_resched_latency(rq);
/*3.更新运行队列的cpu_load数组*/
calc_global_load_tick(rq);
sched_core_tick(rq);
task_tick_mm_cid(rq, curr);
esched_latency_warn(cpu, resched_latency);
perf_event_task_tick();
/*5. 工作队列线程,更新其状态*/
if (curr->flags & PF_WQ_WORKER)
wq_worker_tick(curr);
#ifdef CONFIG_SMP
/*6.触发SMP负载均衡*/
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);//触发一个软中断,让ksoftirq线程处理真正地负载均衡过程
#endif
}
- 时钟中断处理程序中,调用
schedule_tick()函数; - 时钟中断是调度器的脉搏,内核依靠周期性的时钟来处理器CPU的控制权;
- 时钟中断处理程序,检査当前进程的执行时间是否超额,如果超额则设置重新调度标志
TIF NEED RESCHED - 时钟中断处理函数返回时,被中断的进程如果在用户模式下运行,需要检查是否有重新调度标志,设置了则调用schedule()调度 (也就是我们再第三篇文章Linux 进程调度与管理:(三)进程的调度之调度时机中介绍的调度执行时机)
- 如果系统开启了SMP,则会触发负载均衡
load_balance()
这里的核心函数是task_tick(rq, curr, 0), 是调用当前调度类中的task_tick函数实现,不同调度类对应不同的task_tick实现方法;
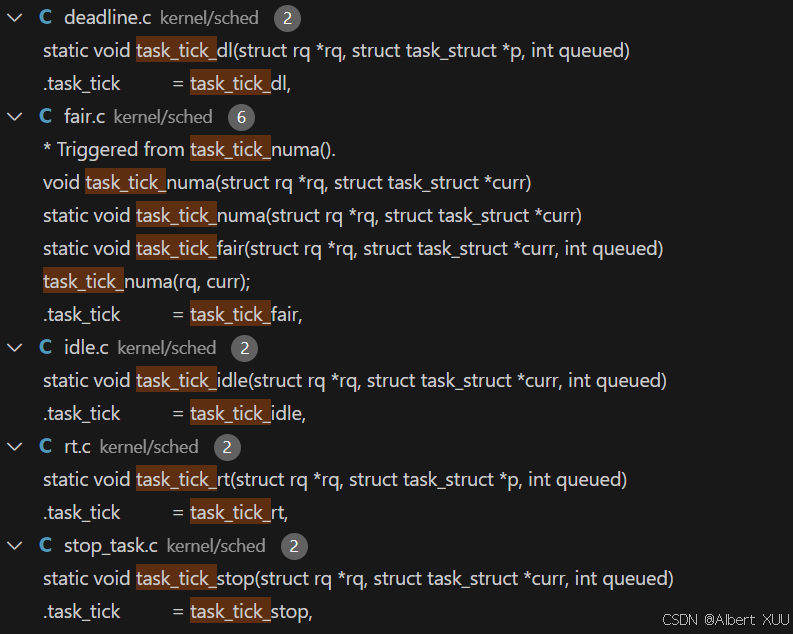
2. task_tick_fair()
这里以cfs这个调度类为例子,分析该调度类对应的task_tick函数—>task_tick_fair():
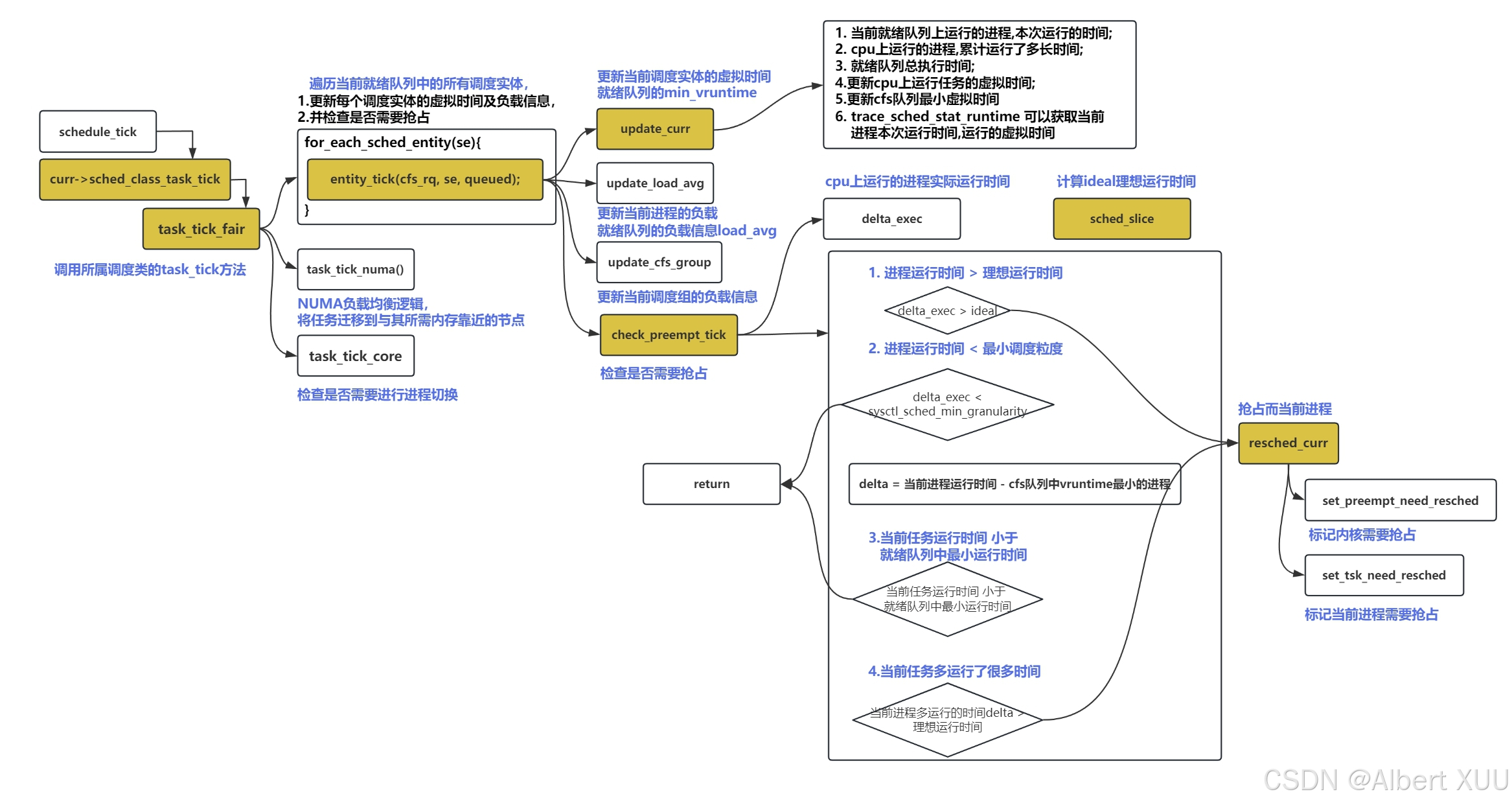
//更新当前任务 及其 相关调度实体的状态信息;
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;//curr为当前cpu上运行的进程
/*1.遍历当前任务所有调度实体;
* (牵扯到组调度机制,需分情况)
* 1.1如果系统实现了组调度机制,则遍历当前进程调度实体以及上一级调度实体;
* 1.2如果未开启组调度机制,则仅遍历当前进程调度实体
*/
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
/*1.3 更新调度实体的状态,检查是否需要调度*/
entity_tick(cfs_rq, se, queued);
}
/*2.执行NUMA负载均衡,尝试将任务迁移到与其所需内存靠近的节点,通过调用task_tick_numa实现*/
if (static_branch_unlikely(&sched_numa_balancing))
/*触发时,执行NUMA负载均衡逻辑*/
task_tick_numa(rq, curr);
update_misfit_status(curr, rq);
update_overutilized_status(task_rq(curr));
/*3.执行核心调度相关操作逻辑*/
task_tick_core(rq, curr);
}
此处先是遍历当前进程的所有调度实体==(如果开启了组调度机制,则遍历当前进程调度实体和上一级调度实体;如果没开启组调度机制,则仅遍历当前进程调度实体)==,并通过核心函数entity_tick函数更新调度实体的状态,并检查当前进程是否需要调度;
这里可以通过查看对for_each_sched_entity()的定义,来理解到底遍历了哪些调度实体:
-
对于开启了组调度机制的,
for_each_sched_entity()的定义是:#ifdef CONFIG_FAIR_GROUP_SCHED //会从当前调度实体开始,持续遍历其上一级的调度实体,直到se==NULL #define for_each_sched_entity(se) \ for (; se; se = se->parent)会从当前调度实体开始,持续遍历其上一级的调度实体,直到se==NULL;
-
对于未开启组调度机制的,for_each_sched_entity()`的定义是:
#else /* !CONFIG_FAIR_GROUP_SCHED */ //仅遍历当前调度实体,随后se==NULL #define for_each_sched_entity(se) \ for (; se; se = NULL)仅遍历当前进程的调度实体;
此处的重点就是entity_tick(cfs_rq, se, queued);,该函数会更新遍历到的调度实体的状态,并检查是否需要调度;接下来将围绕entity_tick做进一步分析。
2.1 entity_tick()更新时间信息,检查抢占
该函数主要就做了两件事:①更新调度实体的各种时间信息;②检查是否需要调度(抢占当前任务)
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* 1.更新当前任务的各种时间信息;(当前进程的vruntime以及该就绪队列的min_vruntime)
*/
update_curr(cfs_rq);
/*
* 2.更新当前进程的负载以及就绪队列的负载信息load_avg;
*/
update_load_avg(cfs_rq, curr, UPDATE_TG);
/* 3.更新调度组的负载信息*/
update_cfs_group(curr);
#ifdef CONFIG_SCHED_HRTICK
/*关于高精度定时器的相关处理逻辑*/
#endif
/*4.check_preempt_tick检查是否需要抢占当前任务*/
if (cfs_rq->nr_running > 1)//如果当前队列只有一个任务,则不执行,因为抢占逻辑不适用
check_preempt_tick(cfs_rq, curr);//比较当前任务的vruntime和其他任务的vruntime来判断要不要抢占
}
梳理一下entity_tick的核心函数:
- 【重点】通过update_curr()函数更新当前任务的各种时间信息,后面会详细分析这个函数;
- 通过update_load_avg()以及update_cfs_group()函数来更新进程负载以及调度组负载信息,为负载均衡做准备;
- 【重点】通过check_preempt_tick()判断是否需要抢占当前任务,这个是核心实现函数,后面会详细分析这个函数;
2.1.1 更新时间信息update_curr()
该函数主要用于更新计算进程的各种时间信息,主要进行了两步计算:
- curr->sum_exec_runtime += delta_exec;计算出当前就绪队列上运行的进程本次运行的时间;
- 通过
calc_delta_fair(delta_exec, curr);计算出运行的虚拟时间;
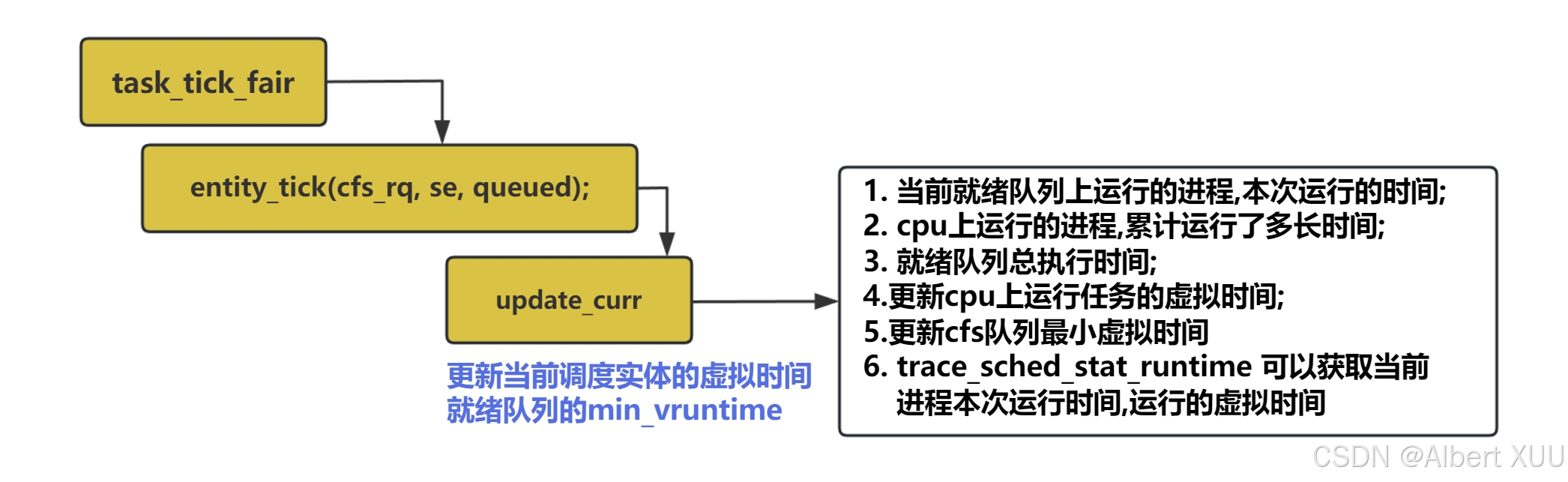
除了以上的两个核心计算步骤,还针对cfs队列以及cgroup组进行了信息更新;
static void update_curr(struct cfs_rq *cfs_rq)
{
/*1.计算当前进程运行了多少时间*/
delta_exec = now - curr->exec_start;//自上次调度以来的时间
curr->exec_start = now;//记录本次调度的时间
/*2.更新任务的最大执行时间片*/
/*3.累加当前进程的总执行时间*/
curr->sum_exec_runtime += delta_exec;//自进程创建以来累计运行时间
schedstat_add(cfs_rq->exec_clock, delta_exec);//当前cfs队列总执行时间,所有任务的运行时间
/*4.更新当前任务的虚拟运行时间
* calc_delta_fair来计算虚拟时间的增量
* update_min_vruntime更新CFS队列的最小虚拟时间
*/
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
/*5.更新相关统计信息*/
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
/*一个可以获取的当前进程运行时间,运行虚拟时间的tracepoint*/
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
/*统计cgroup的相关信息*/
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
/*更新CFS队列的运行时间*/
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
值得注意的是,trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);为我们提供了一个tracepoint,用于获取当前进程运行的时间以及虚拟时间;
接下来对于calc_delta_fair()函数如何计算虚拟时间的,进行进一步分析:
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
/*1.计算真正的虚拟时间
* 1.1 nice = 0 时,权重为1024,即虚拟时间等于真实时间,直接跳过计算返回delta;
* 1.2 nice!= 0 时,通过__calc_delta计算虚拟时间,并返回虚拟时间;
*/
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
其中__calc_delta()函数主要通过如下算法计算虚拟时间:
vruntime = (时间运行时间 * ((NICE__LOAD*2^32)/weight))>>32
2.1.2 检查抢占check_preempt_tick()
该函数主要用于判断是否需要抢占;主要通过以下几个步骤实现判断:
- 1.实际运行时间大于理想运行时间,则需重新调度
- 通过
sched_slice函数计算出当前任务预期运行时间,具体实现方式会在后面提到; - 实际运行时间大于预期运行时间则重新调度
resched_curr;
- 通过
- 2.避免当前任务运行时间太短,如果当前进程运行时间太短,则继续运行该任务,跳出抢占判断;
- 将当前任务实际运行时间与
sysctl_sched_min_granularity(任务调度的最小时间粒度)作对比;
- 将当前任务实际运行时间与
- 3.当前进程虚拟运行时间与就绪队列中最优先任务的虚拟时间做比较,若大出一定范围,则需重新调度;
- 前面1步是保证当前任务实际运行时间不要太多;2步是当前任务实际运行时间不要太少;将实际运行时间限定在一定范围内;
- 前面的1,2步均是拿当前进程的实际运行时间进行对比,而这里是对虚拟运行时间进行评判;
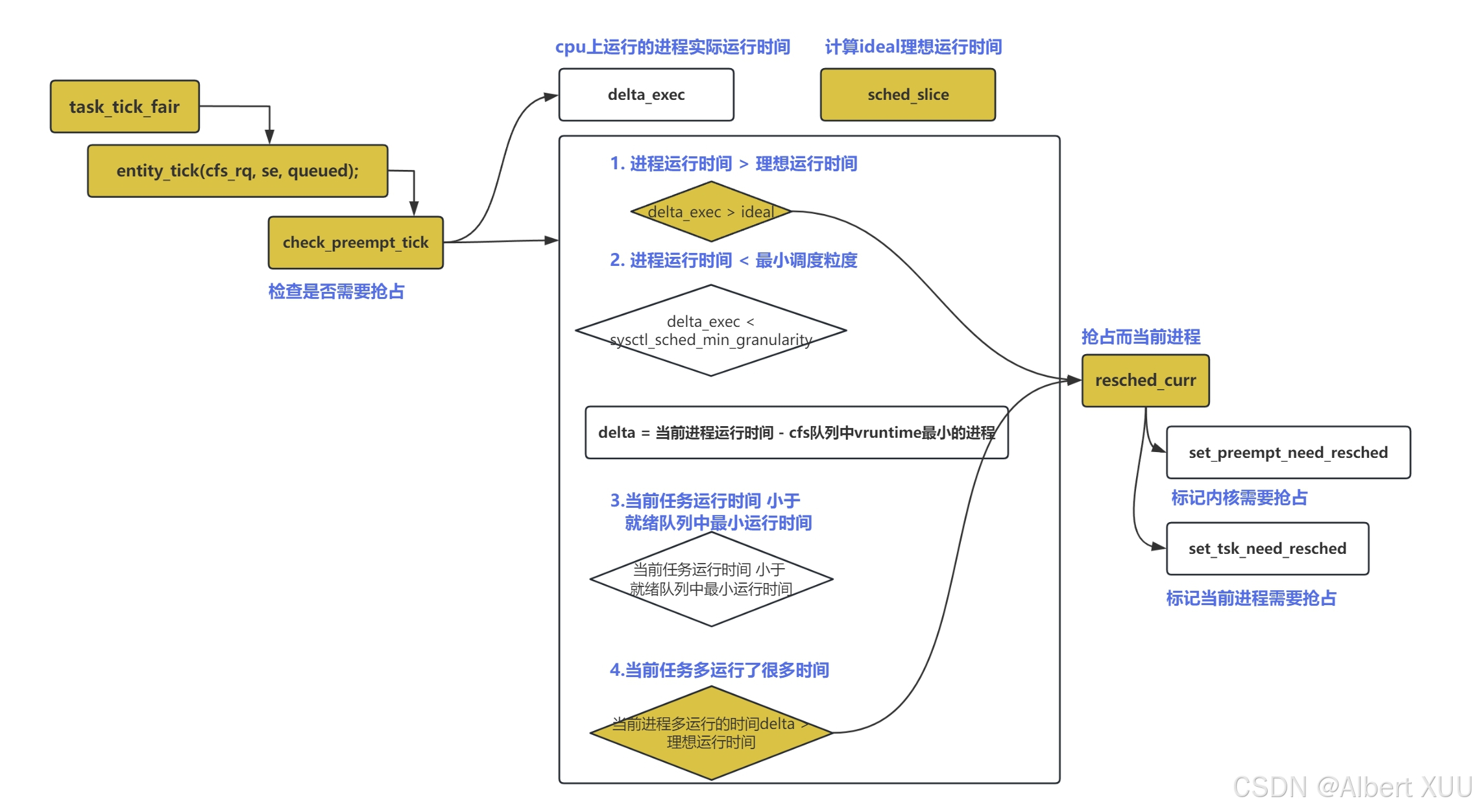
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
/*
*1.当前进程实际运行的时间比预期时间长
*1.1 通过sched_slice计算当前任务理想时间片长度,赋值给ideal_runtime;
*1.2 检查进程运行时间 是否超出 预期运行时间
*/
ideal_runtime = min_t(u64, sched_slice(cfs_rq, curr), sysctl_sched_latency);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;//当前进程本次实际运行时间
if (delta_exec > ideal_runtime) {//实际运行时间超出预期,则重新调度resched_curr
resched_curr(rq_of(cfs_rq));
/*
* 清除调度器中的“亲密任务”(buddy)信息,
* 避免当前任务因调度优先级偏好被再次选中。
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* 2.避免当前进程运行时间太短;
* sysctl_sched_min_granularity是任务调度的最小时间粒度
* 如果实际运行时间小于最小时间粒度,说明其运行时间不足,
* 不满足重新调度的要求,直接退出抢占判断
*/
if (delta_exec < sysctl_sched_min_granularity)
return;
/*
* 3. 当前进程运行的时间比预期时间大一定幅度,则需抢占;
* 3.1 先计算出 当前任务虚拟时间 与 cfs队列中最优先任务(即红黑树左下角的任务)虚拟时间 之间的差;
* 3.2 若 当前任务虚拟时间 < 最优先任务虚拟时间,则说明公平性未得到破坏,继续运行当前任务;
* 3.3 若 当前任务虚拟时间 > 最优先任务虚拟时间,但超出的时间在一定范围内
* (超出时间小于一个调度周期ideal_runtime),继续运行当前任务;
* 3.4 若 超出时间太多(即超出时间大于一个调度周期ideal_runtime),需要重新调度;
*/
se = __pick_first_entity(cfs_rq);//获取cfs调度队列中虚拟时间最小的任务
delta = curr->vruntime - se->vruntime;//计算当前任务与最优先任务之间的虚拟运行时间差。
if (delta < 0)//无需抢占,因为当前任务的虚拟时间比cfs队列中最优先任务的虚拟时间还小
return;
//超出的时间 都大于 预期运行时间,则重新调度;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
不难看出,这里的核心函数是sched_slice()与resched_curr(),下面将详细分析这两个函数。
sched_slice():该函数根据当前系统的负载计算出一个调度周期,也即前面提到的预期运行时间,作为一个评判标准,以免当前任务运行时间过长;
首先是shced_slice()函数:调用__sched_period()函数计算单个调度周期;再循环遍历任务中的所有调度实体,计算slice预期运行时间;
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/*1.计算出一个调度周期__sched_period()*/
slice = __sched_period(nr_running + !se->on_rq);
/*2.遍历任务的所有调度实体,计算时间片*/
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
struct cfs_rq *qcfs_rq;
/*获取当前cfs队列的总负载*/
qcfs_rq = cfs_rq_of(se);
load = &qcfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = qcfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
/*根据当前调度实体的权重,计算其分配到的时间片长度*/
slice = __calc_delta(slice, se->load.weight, load);
/* 当前调度实体权重 队列总负载*/
}
return slice;
}
关于__sched_period()函数是如何实现的,他通过将就绪队列中的任务数与一个固定值sched_nr_latency作对比,来使用不同的策略,如果就绪队列中的任务少于sched_nr_latency,则直接使用系统默认的sysctl_sched_latency作为一个调度周期,如果就绪队列中的任务多于sched_nr_latency,则将nr_running * sysctl_sched_min_granularity作为一个调度周期,其中sysctl_sched_min_granularity是最小时间片,也即就绪队列中所有任务都运行最小时间片后作为一个调度周期。
/*
* This value is kept at sysctl_sched_latency/sysctl_sched_min_granularity
*/
static unsigned int sched_nr_latency = 8;
unsigned int sysctl_sched_min_granularity= 750000ULL;
unsigned int sysctl_sched_latency= 6000000ULL;
static u64 __sched_period(unsigned long nr_running)
{
/*1.就绪队列中进程较多,每个任务运行最小时间粒度*/
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
/*2. 就绪队列中进程较少,sysctl_sched_latency作为默认调度周期*/
return sysctl_sched_latency;
}
**resched_curr()😗*该函数执行重新调度相关工作;
void resched_curr(struct rq *rq)
{
struct task_struct *curr = rq->curr;//就绪队列当前进程
int cpu;
lockdep_assert_rq_held(rq);//确保运行队列被锁定;
/*1.检查当前任务是否已经被标记为需要重新调度,防止重复标记*/
if (test_tsk_need_resched(curr))
return;
/*2.重新调度相关工作:
* 2.1运行队列所属cpu是当前cpu,即处理本地cpu情况:
* set_tsk_need_resched(curr)更改 task_struct下面thread_info->flag为TIF_NEED_RESCHED;
* set_preempt_need_resched()设置内核的抢占标志位,允许调度器在下一次中断时触发任务切换
*/
cpu = cpu_of(rq);
if (cpu == smp_processor_id()) {
set_tsk_need_resched(curr);
set_preempt_need_resched();
return;
}
/*2.重新调度相关工作:
* 2.2处理远程CPU情况:
* set_nr_and_not_polling(curr)标记当前任务为TASK_RUNNING并判断目标CPU是否是空闲轮询状态
* smp_send_reschedule(cpu)发送信号,通知目标 CPU 触发调度操作。
*/
if (set_nr_and_not_polling(curr))
smp_send_reschedule(cpu);
else
trace_sched_wake_idle_without_ipi(cpu);
}
resched_curr()重新调度相关工作主要分以下两个情况:
- 本地CPU:即目标运行队列所属CPU就是当前CPU
- 这种情况更改当前任务的thread_info标识符中的TIF_NEED_RESCHED;
- set_preempt_need_resched()设置内核的抢占标志位;
- 远程CPU:即目标任务所属cpu不是当前cpu;
- smp_send_reschedule(cpu)发送信号,通知目标 CPU 触发调度操作;