吾名爱妃,性好静亦好动。好编程,常沉浸于代码之世界,思维纵横,力求逻辑之严密,算法之精妙。亦爱篮球,驰骋球场,尽享挥洒汗水之乐。且喜跑步,尤钟马拉松,长途奔袭,考验耐力与毅力,每有所进,心甚喜之。
吾以为,编程似布阵,算法如谋略,需精心筹谋,方可成就佳作。篮球乃团队之艺,协作共进,方显力量。跑步与马拉松,乃磨炼身心之途,愈挫愈勇,方能达至远方。愿交志同道合之友,共探此诸般妙趣。诸君,此文尚佳,望点赞收藏,谢之!
1. 下载anaconda安装包:Index of /

2. 直接点击安装即可
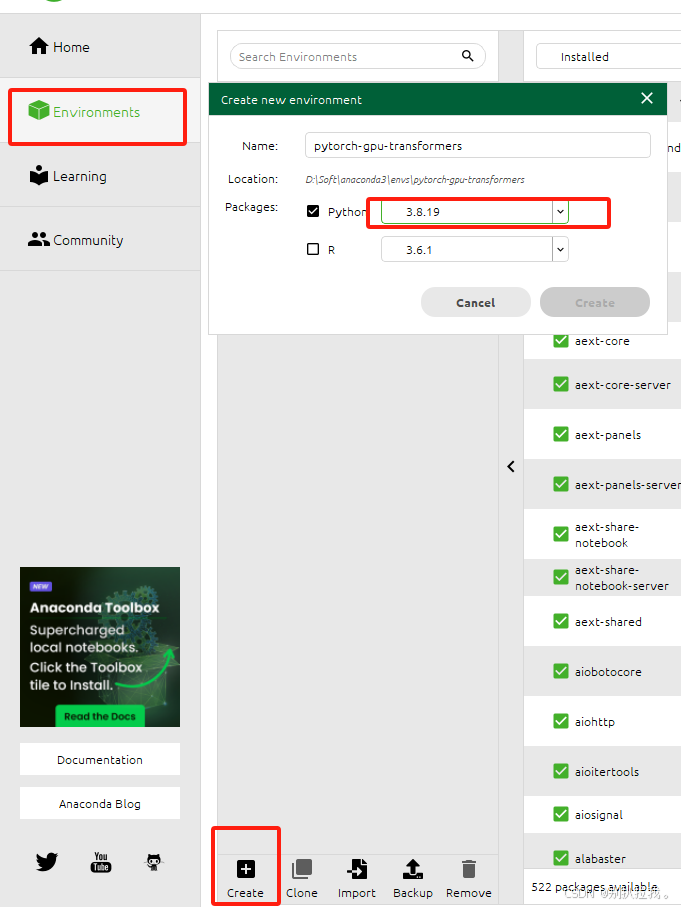
3. 运行Anacode Navigator,创建虚拟环境,名称是pytorch-gpu-transformers。选择Python3.8.19版本。(后续使用这个环境进行pytorch、transformers的安装以及Qwen2-0.5B-Instruct模型的运行)
4. 运行Pycharm IDE(Pycharm安装步骤略,我安装的是PyCharm Community Edition 2024.1.4)可以选择官网下载安装包,可以直接在anaconda界面选择install,但是安装时注意切换到刚才创建好的虚拟环境
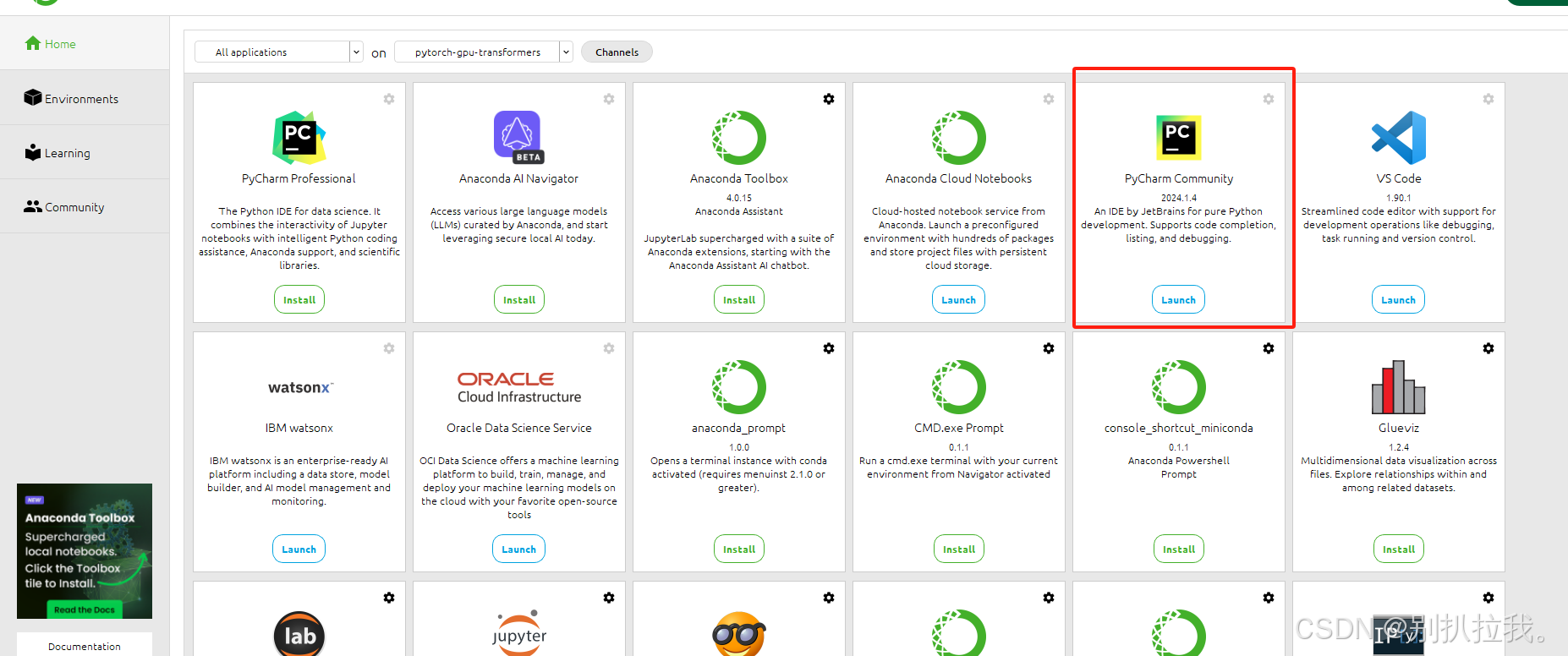
Pycharm安装好之后,后续就不需要运行anaconda了,除非想要管理虚拟环境。
5. 给Pycharm配置conda虚拟环境,使用刚才新建的pytorch-gpu-transformers虚拟环境
File -> Settings -> Python Interpreter
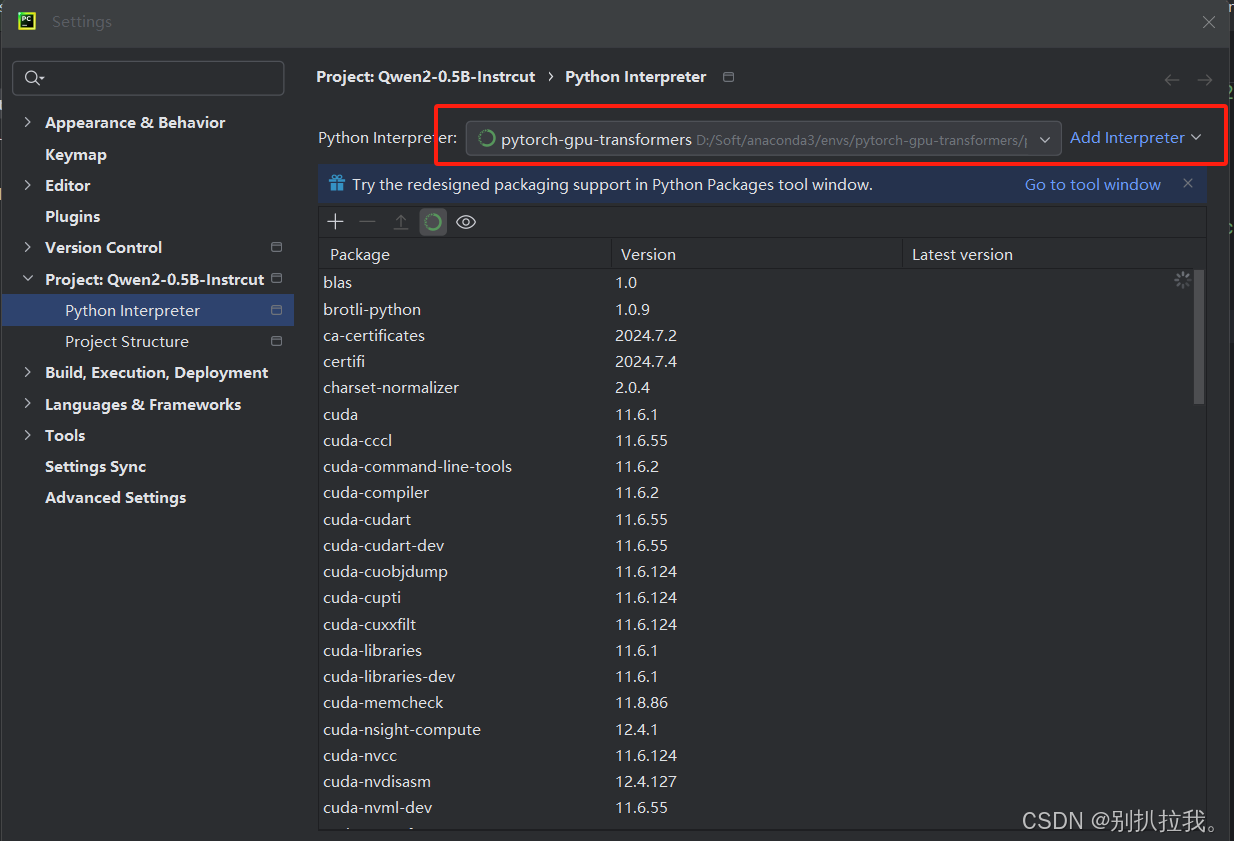
如果没有刚才新建的虚拟环境可选项,点击Add Interpreter添加。
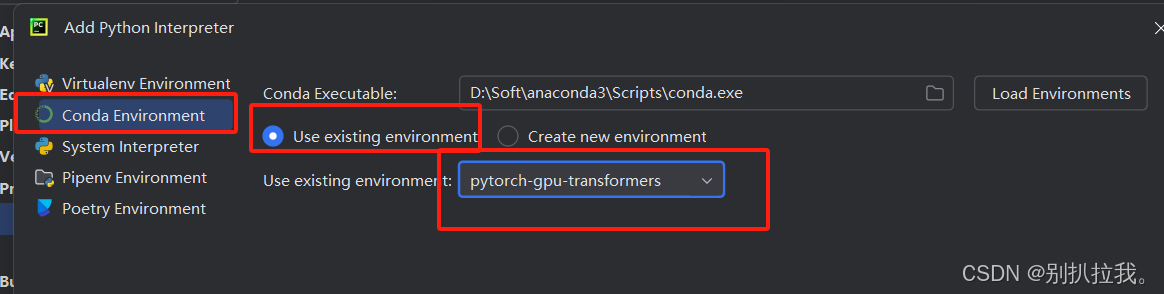
Pycharm会自动检测本机安装好的conda虚拟环境。
配置成功后,当前Pycharm的开发环境已经切换到了刚才新建的虚拟环境中。在此环境安装的所有依赖包将与其他环境不影响。
6. 在当前虚拟环境安装Pytorch、transformers平台依赖:
GPU版本:CSDN
CPU版本:CSDN
7. 下载Qwen-0.5B-Instruct模型(以为GPU比较垃圾,所以选择小参数量的非量化模型)
将所有文件下载,存储到自己定义的目录即可
8. 运行Qwen-0.5B-Instruct
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"path to Qwen2-0.5B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("path to Qwen2-0.5B-Instruct")
prompt = "解释一下'人生得意须尽欢,莫使金樽空对月'"
messages = [
{"role": "system", "content": "你是个擅长研究中国唐诗的专家."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)

9. 备注:
运行模型时可能会碰到依赖包缺少的情况,根据具体提示,pip install 安装即可。
如果碰到非依赖确实问题,那基本都是依赖版本的问题,要么需要升级版本,要么需要回退版本,根据各个组件官网的版本要求进行安装即可