一.数据文件归档
1.数据归档命令:
hadoop archive -archiveName gd3_fr_husbandry.har -p /user/hive/warehouse/ods.db/gd3_fr_husbandry -r 3 /tmp/gd3_fr_husbandry
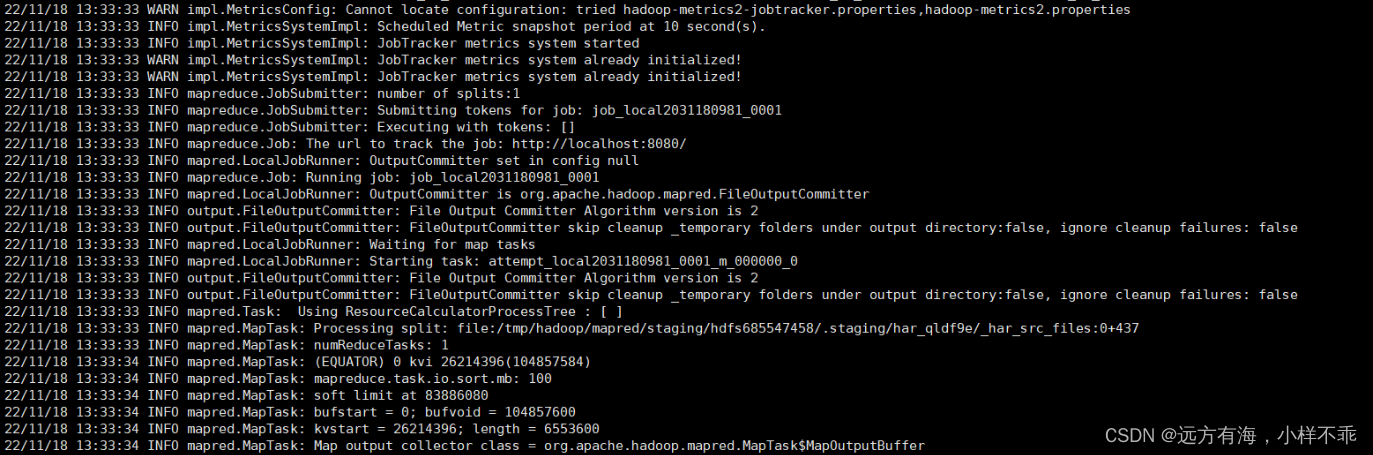
参数说明:
-p :可以递归
-r :归档的副本数
2.归档数据查看
3.归档数据还原
hadoop fs -cp har:/tmp/gd3_fr_husbandry/gd3_fr_husbandry.har/* /tmp/gd3_fr_husbandry

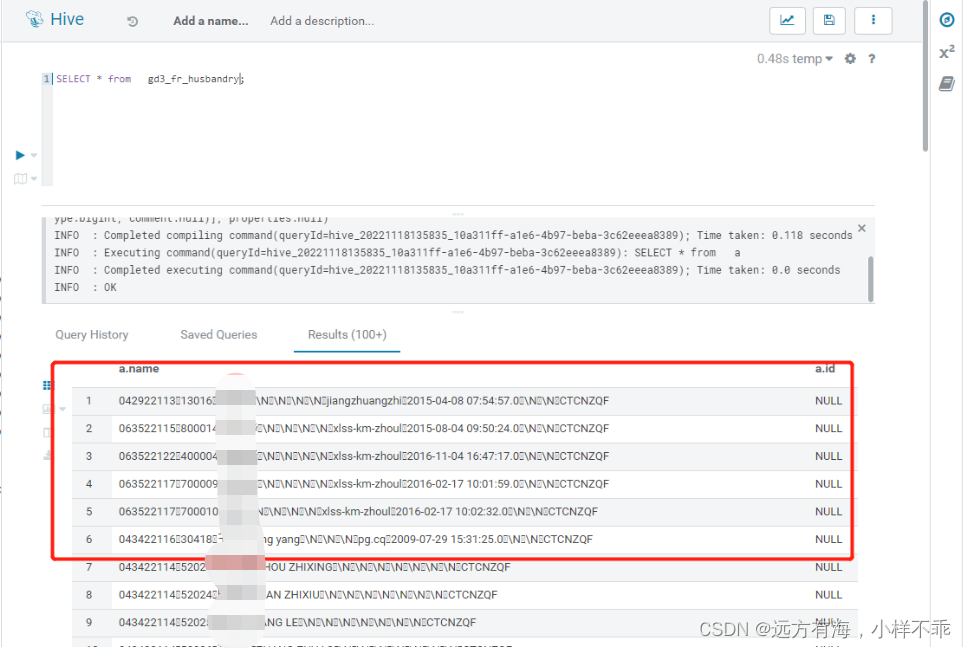
4.数据查询
二.数仓表分区表归档
1.开启归档
set hive.archive.enabled=true;
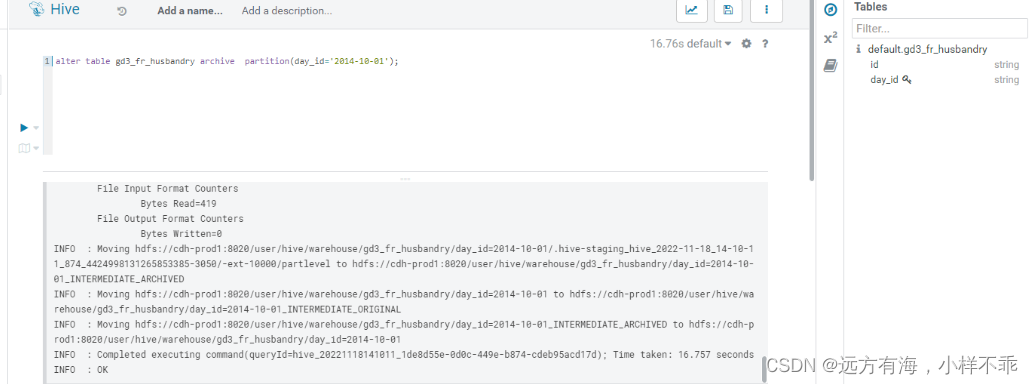
2.开始归档
alter table gd3_fr_husbandry archive partition(day_id='2014-10-01');
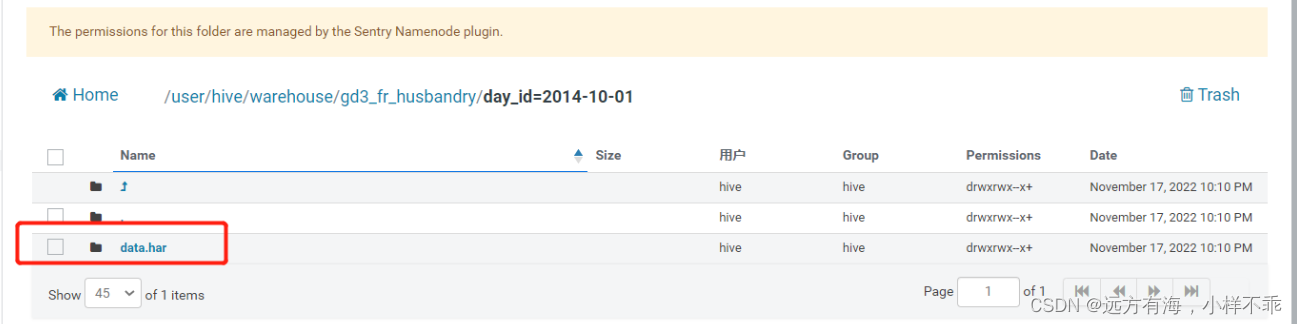
查看归档之后的目录为一个文件
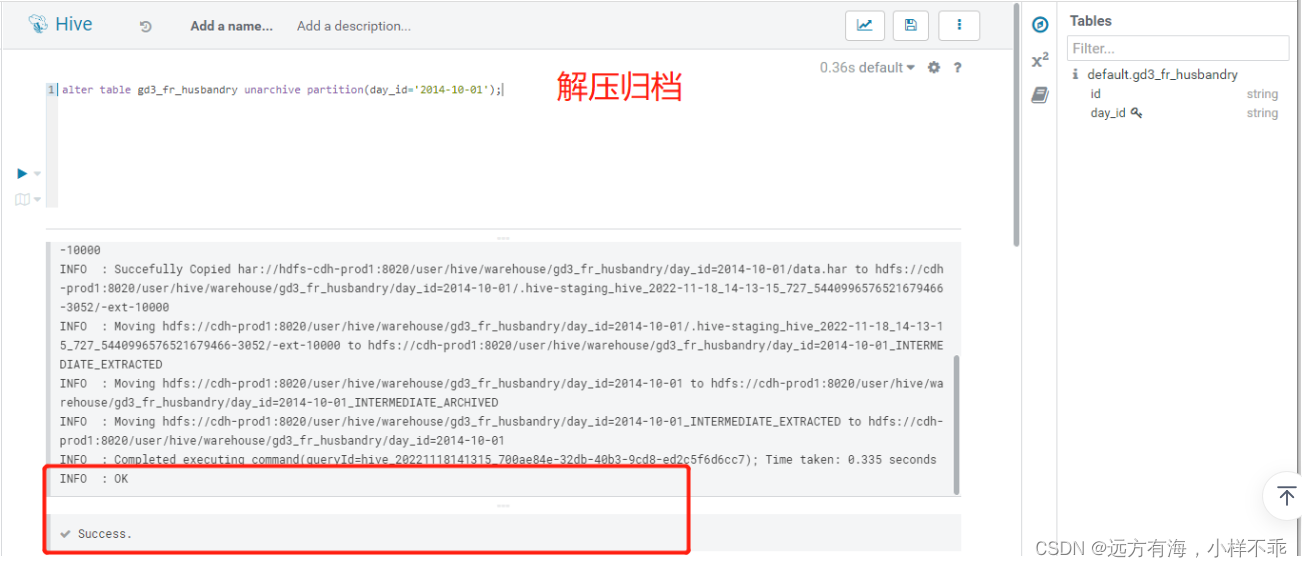
3.解压归档文件
alter table gd3_fr_husbandry unarchive partition(day_id='2014-10-01');
注意:
1.归档的表必须是内部表,不能是外表表,目前不支持
2.归档之后的数据可以解压归档也可以不解压归档,两者都可以通过hive进行查询。区别:解压之后可以提高计算的并发,不解压归档可能计算性能会慢,对于分区小文件而言可以不进行解压
三.不足之处
1、archive文件本占用与原文件相同的硬盘空间;
2、archive文件不支持压缩;
3、archive一旦创建就不能进行修改;
4、archive虽然解决了namenode的空间问题,但是,在执行mapreduce时,会把多个小文件交给同一个map去split,这可能会降低mapreduce的效率,另外创建HAR和解压HAR依赖MapReduce,查询文件时耗很高。
注意:归档命令执行完成后,其原始文件仍旧还在,需要手动删除才能真正做到释放小文件在NN中对应存储的block信息。另外,由于小文件的内容被打包写入到了数据文件中,因此磁盘空间并没有因此减少,相反还增加了索引文件(但索引文件长度一般都比不大)。
总结:
目前数仓内部有的是内部表,有的是外部表,现有的外部表使用数据文件归档, 内部表使用分区表归档