数据导入导出
数据文件导入
LOAD DATA INFILE '文件路径和文件名' INTO TABLE 表名字;
或
source *.sql导出
SELECT 列1,列2 INTO OUTFILE '文件路径和文件名' FROM 表名字;
每个部门工资最高的员工
创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
+----+-------+--------+--------------+
创建Department 表,包含公司所有部门的信息。
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
SELECT Department,Employee,Salary FROM
(SELECT d.Name as Department,e.Name as Employee,e.Salary FROM Employee e join Department d
on e.DepartmentId=d.Id) t
GROUP BY Department;

换座位
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的
小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
请创建如下所示seat表:
示例:
+---------+---------+
| id | student |
+---------+---------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
+---------+---------+
假如数据输入的是上表,则输出结果如下:
+---------+---------+
| id | student |
+---------+---------+8
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
+---------+---------+
注意:
如果学生人数是奇数,则不需要改变最后一个同学的座位。
SELECT
a.id,a.student
FROM
(SELECT id-1 AS id,student FROM seat WHERE id MOD 2=0
UNION
SELECT id,student FROM seat WHERE id MOD 2=1 and id =(SELECT COUNT(*) FROM seat)
UNION
SELECT id+1 as id,student FROM seat WHERE id MOD 2=1 and id!=(SELECT count(*) FROM seat)
)a
ORDER BY a.id

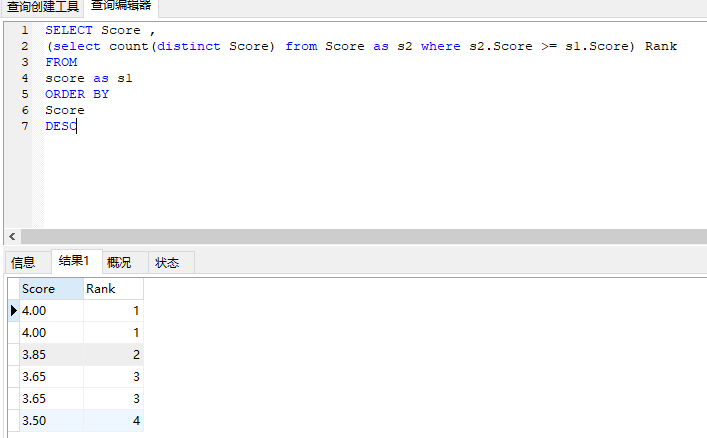
分数排名
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
创建以下score表:
+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
SELECT Score ,
(select count(distinct Score) from Score as s2 where s2.Score >= s1.Score) Rank
FROM
score as s1
ORDER BY
Score
DESC
行程和用户
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
+----+-----------+-----------+---------+--------------------+----------+
| Id | Client_Id | Driver_Id | City_Id | Status |Request_at|
+----+-----------+-----------+---------+--------------------+----------+
| 1 | 1 | 10 | 1 | completed |2013-10-01|
| 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01|
| 3 | 3 | 12 | 6 | completed |2013-10-01|
| 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01|
| 5 | 1 | 10 | 1 | completed |2013-10-02|
| 6 | 2 | 11 | 6 | completed |2013-10-02|
| 7 | 3 | 12 | 6 | completed |2013-10-02|
| 8 | 2 | 12 | 12 | completed |2013-10-03|
| 9 | 3 | 10 | 12 | completed |2013-10-03|
| 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03|
+----+-----------+-----------+---------+--------------------+----------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+
| Users_Id | Banned | Role |
+----------+--------+--------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
+----------+--------+--------+
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
select t.Request_at as day,
round(sum(case when t.status='completed' then 0 else 1 end)/count(*),2) as 'Cancellation Rate'
from
Trips t inner join users u1 on t.Client_Id=u1.Users_Id and u1.Banned='No'
where t.Request_at between '2013-10-01' and '2013-10-03'
group by t.Request_at;

各部门前3高工资的员工
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
+----+-------+--------+--------------+
编写一个 SQL 查询,找出每个部门工资前三高的员工。例如,根据上述给定的表格,查询结果应返回:
此外,请考虑实现各部门前N高工资的员工功能。
SELECT D1.Name Department, E1.Name Employee, E1.Salary
FROM Employee E1, Employee E2, Department D1
WHERE E1.DepartmentID = E2.DepartmentID
AND E2.Salary >= E1.Salary
AND E1.DepartmentID = D1.ID
GROUP BY E1.Name
HAVING COUNT(DISTINCT E2.Salary) <= 3
ORDER BY D1.Name, E1.Salary DESC;

分数排名
+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 3 |
| 3.65 | 4 |
| 3.65 | 4 |
| 3.50 | 6 |
+-------+------
SELECT Score,
(SELECT count(*) FROM Score AS s2 WHERE s2.Score > s1.Score)+1 AS Rank
FROM Score AS s1
ORDER BY Score DESC;
