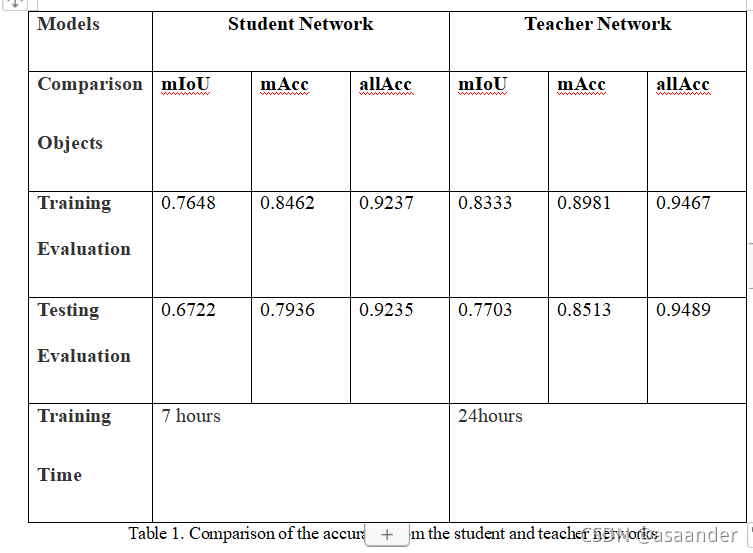
PSPNet logits 蒸馏和特征蒸馏
Introduction
随着神经网络和CNN的发展,越来越多的复杂问题可以得到解决,但近年来,伴随着计算机的性能提升,神经网络结构变得越来越复杂和庞大。为了获得更高性价比的模拟计算,神经网络的迁移学习和压缩算法逐渐受到更多关注。研究人员期望以更小的时间成本和存储成本来获得更灵活的网络应用。
关于提高网络效率和准确性的问题,本文采用logits蒸馏和特征蒸馏的结合蒸馏方法,利用ResNet50为backbone的PSPNet模型来teach ResNet18 为backbone的PSPNet模型,并在PASCAL-VOC2012增强数据集上进行训练和测试。
Innovations
1.这篇文章结合了logits蒸馏和特征蒸馏各自的优点,融合了两种算法对PSPnet进行压缩。使学生网络可以同时从中间层和输出层引用教师网络,并且有技巧地规避了特征维度不匹配的问题。
2.结合PSPnet本身的网络特点,针对性地改进了适合这个网络蒸馏训练的loss函数,并通过实验验证了其有效性。
蒸馏现状
到目前为止,主要有两大类知识蒸馏:一类是logits蒸馏,另一类是特征蒸馏。前者是直接匹配网络输出的概率分布或学习一批logits的分布来强制匹配;后者是直接匹配中间的特征或学习特征之间的转换关系。例如,在特征No.1和No.2中间,知识可以表示为如何模做两者中间的转化,可以用一个矩阵让学习者产生这个矩阵,学习者和转化之间的学习关系。
目前这两种方法都有比较严谨的算法思路,可以让网络以小部分的性能为代价,大幅提高训练难度和训练时间,让深度网络在空间或时间限制的应用中得到更广泛的使用。
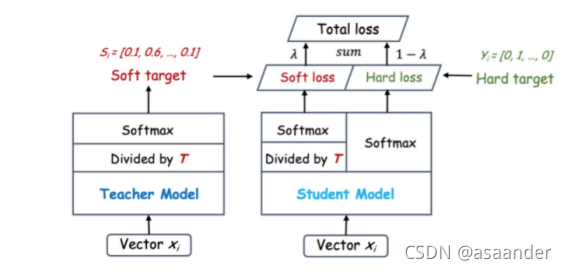
第一种方法最初是由Hilton提出的,通过引入与复杂但可高度概括的学生网络相关的软目标来实现信息传递,作为学习者网络训练整体损失的一部分。如图所示(摘自论文),学生网络的预测输出除以温度参数,然后通过使用softmax变换,得到一个软对数分布,其数值范围为0-1,数值分布比较适中。之后X. Liu等人[ Liu X , Wang X , Matwin S . “Improving the Interpretability of Deep Neural Networks with Knowledge Distillation” [J]. IEEE, 2018.]通过引入精简网络输出和教师网络输出之间的KL分散来重新定义总损失,并在诱导训练期间将教师的预测输出先放在CPU内存中,以此来减少GPU的内存负载。至此,logits蒸馏工作基本定型。
后来,基于Hinton提出的基于softmax的知识蒸馏适应性,Romero A和他的同事进一步提出了一种蒸馏特征的方法。在本文中,他们提出了一种比较中间层学生特征的方法,这相当于一个助教在中间起作用。
中间层的输出被引入作为训练学生网络的指导,类似于基于特征图的知识提炼,其中首先选择要提炼的中间层,例如,教师的提示层和学生的指导层。由于这两个层的初始大小可能不同,所以在引导层之后增加一个卷积层,以匹配教师提示层的初始大小。然后用知识提炼法训练学生引导层之前的所有层,这样学生网络中的中间层就可以学习教师提示层的输出,损失函数是新增卷积层的输出和提示层的输出的L2Norm。
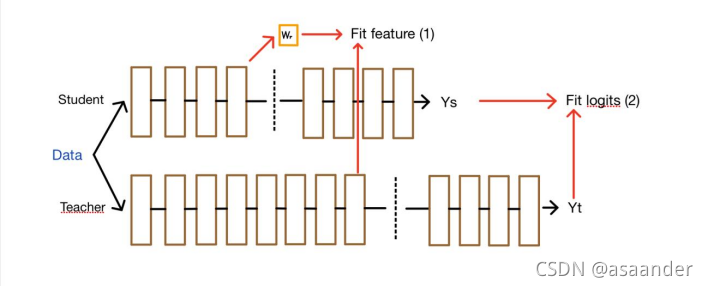
然而,这种FitNet仍然存在一些问题:首先,模型容量不同,其次,教师网络中有许多冗余元素。因此,如果特征太复杂,太难学,可能学不好。冗余的参数并不重要,对结果的影响也不大。此外,如果学生不知道哪些特征是活的,哪些神经元是更重要的,学生的网络就会只是一般地学习,脑容量太小的学生很容易就会用四种不同的方式学习。
所以,如果一个复杂的老师产生了一个中间有很多冗余的特征图,可以想办法把这些特征压缩得更近,把知识压缩得更小,这样可以同时解决上述问题。
本文方法
参考并结合基于特征的转移和蒸馏学习,本文提出了一种除了需要参考教师的输出结果外,还要在中间层增加特征比较的方法,也就是除了在最后增加蒸馏损失,还增加了特征损失,并以网络本身的交叉熵函数作为主要损失函数。
上节中提到了在语义分割网络需要高准确度和高精度,以及大小语义分割网络各自存在优缺点,知识蒸馏可以融合大模型精确和小模型不占内存的优点。
纯粹的logits蒸馏可能会引起学生网络难以学习的情况,因此考虑到可以结合特征蒸馏,具体是需要在教师和学生网络的中间层做feature之间的map,但因为往往特征蒸馏会因为中间层特征尺度不一致的情况,导致蒸馏过程需要额外的线性匹配,与此同时,实现难度也因此高了一点点。
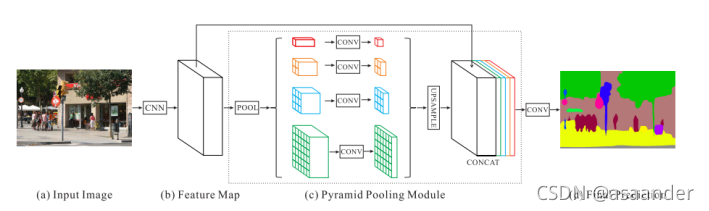
但是幸运的是,这篇文章所研究的PSPNet并不需要这个过程。为什么这么说呢?这就需要介绍一下PSPNet:
(上述图片摘自PSPNet原文)
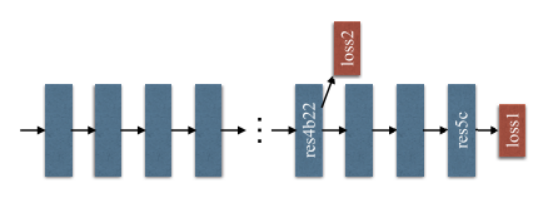
PSPNet 首先使用预训练的ResNet模型和扩张网络策略来提取特征图,然后在该图之上,使用一个四层的金字塔模块来收集上下文信息,除了使用软最大损失来训练最终分类器的主分支外,在第四阶段之后应用另一个分类器,即res4b22残余块。这个PSPnet自带的 aux layer,其输出和最终输出的维度都是一样的。而本实验所要研究的以Resnet50作为backbone的教师的网络和以Resnet18作为backbone的学生网络只有第一个sequential模块是维度不同的,学生网络少了几个卷积层和池化层,除此之外在后面的金字塔模块里结构是差不多的,所以原本在loss2处的aux部分,其输出负责了PSPnet分支loss任务,帮助加速收敛,这个aux部分输出维度正好和target一致,这一点在教师的网络和学生的网络上是一样的。所以也就是说这两个网络在这里的输出维度是一致的,这样就在特征蒸馏时可以省去了特征维度线性匹配的麻烦,直接在这里蒸馏就好了。
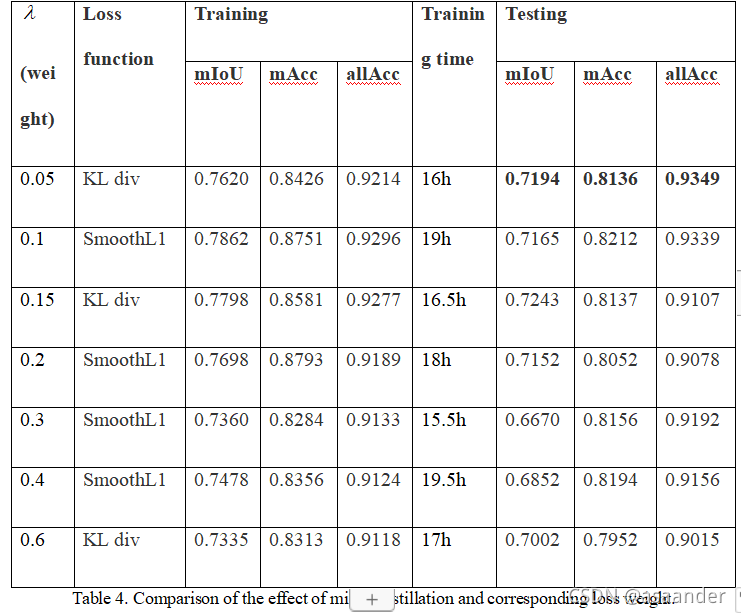
所以本论文结合以上所有优势,开发和应用了一个适合PSPNet的loss,也就是将教师和学生网络在aux layer的输出做一个KL散度的对比计算或者SmoothL1的计算,让学生网络不仅可以参考教师网络的最终输出,也能在中间层获取更多的信息提示,以帮助学生网络的加速训练.当然具体选用哪个loss函数。
当然这里直接对aux层的输出做特征蒸馏只是针对PSPNet而言的特殊处理。其他的网络如果想要加同样的损失函数,必须要保证在中间的某一层的特征输出的维度是一样的,否则就必须做相应的变换。虽然结构和loss计算会更复杂一点,但我们有理由相信这会让学生网络在一定程度上有训练效果或者速度上的提升。
原理以及公式
首先,我们需要单独训练出一个足够强大的教师网络,然后将所有的参数保存并固定,然后再帮助学生网络训练。在帮助学生网络训练时,所有的数据需要共同流经教师网络和学生网络,流经教师网络的数据经过强大的处理之后的输出结果,会先除以温度参数,然后再做softmax变换,这样会使得输出结果更加缓和。而流经学生网络的数据会做很多其他的处理,除了自身需要以ground truth为参考之外,同时还需要和教师网络一样,先除以温度参数,再做softmax变换,然后将这个结果与教师网络处理过的数据进行KL散度对比作为蒸馏损失。这个过程和普通的蒸馏几乎一致。
另外,就像前面PSPNet结构介绍的,PSPNet自带一个辅助损失从aux layer 流出,所以本实验保留了这个损失,并且将这个损失的权重也从网络本身继承了下来,因为这些已经在PSPNet中得到了足够的验证,证实了这个辅助损失有助于网络训练。
至于添加的特征蒸馏部分,本论文同样参考了FitNet的做法,将教师网络的aux layer前面的所有层作为学生网络的Hint来帮助学生网络训练,其输出和学生在这一层的输出做一个KL散度计算或者交叉熵计算,当然这一部分的函数选择也同样做了对比实验。且由于aux layer本身的设计,恰好使得学生和教师网络在这一层的特征输出维度一致,免去了维度卷积处理的复杂设计,这一点比FitNet本身要简便许多。此外,所有的训练不像FitNet一样分两步训练,而是同步训练的。
原理图: (https: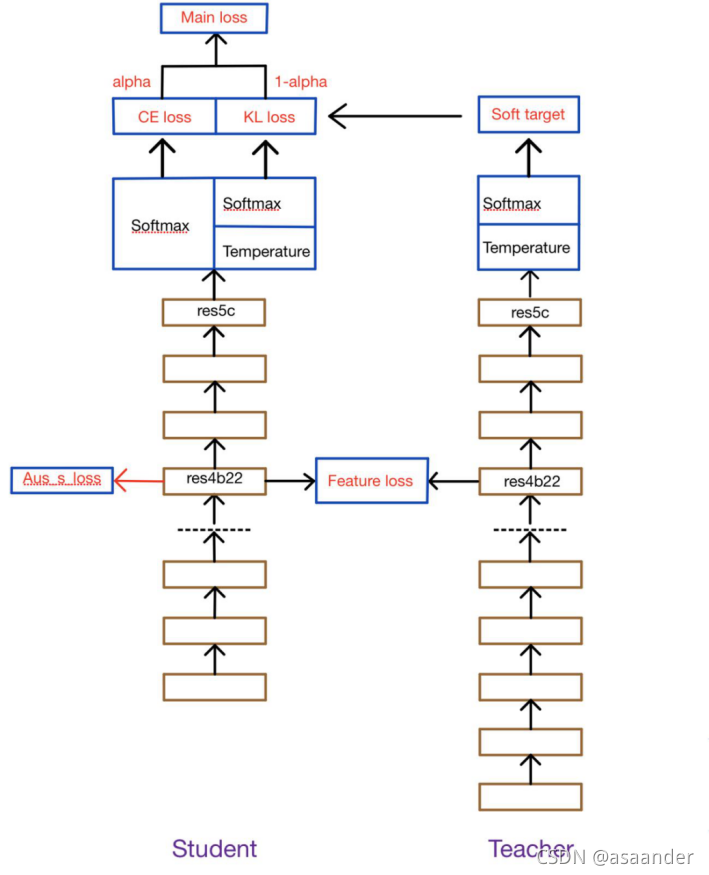
(https://imgconvert.csdnimg.cn/aHR0cHM6Ly9hdmF0YXIuY3Nkbi5uZXQvNy83L0IvMV9yYWxmX2h4MTYzY29tLmpwZw)
代码已经发布在GitHub中:link
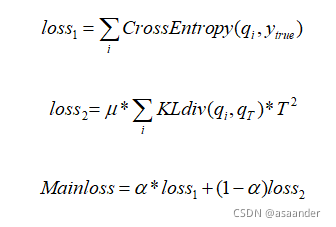
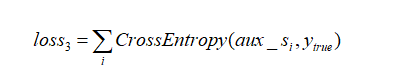
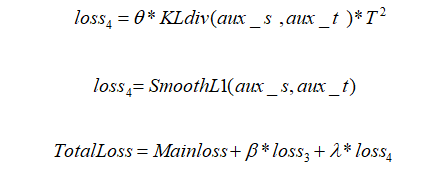
Results
###复现Code:https://github.com/asaander719/PSPNet-knowledge-distillation