Springboot多线程实战
2022-12-12 By jihong
在系统中遇到海量数据需要处理的时候,如果处理效率很低,可以使用线程池来优化代码,提高代码效率,在Springboot中使用多线程的方式来模拟真实的业务场景
- 为什么使用线程池,而不是new Thread()?
在JAVA中,如果每需要一个线程就去new一个Thread的话,开销是很大的,甚至可能比实际业务所需要的资源要更大,除了创建和销毁的开销以外,JVM也扛不住过多的线程存在。
线程池主要用来解决线程生命周期开销问题和资源不足问题。通过对多个任务重复使用线程,线程创建的开销就被分摊到了多个任务上了,而且由于在请求到达时线程已经存在,所以消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使用应用程序响应更快。另外,通过适当的调整线程中的线程数目可以防止出现资源不足的情况。
- 多线程的原理
public static String threadTest(){
new Thread(() -> {
try {
// 睡15秒
Thread.sleep(150000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
return "我返回了";
}
如上代码,当执行上方代码时,在返回结果直接去开启一个线程,线程内的代码是睡15秒钟。实际执行结果是直接返回了这个字符串,而没有去睡这15秒。实际是这样吗?
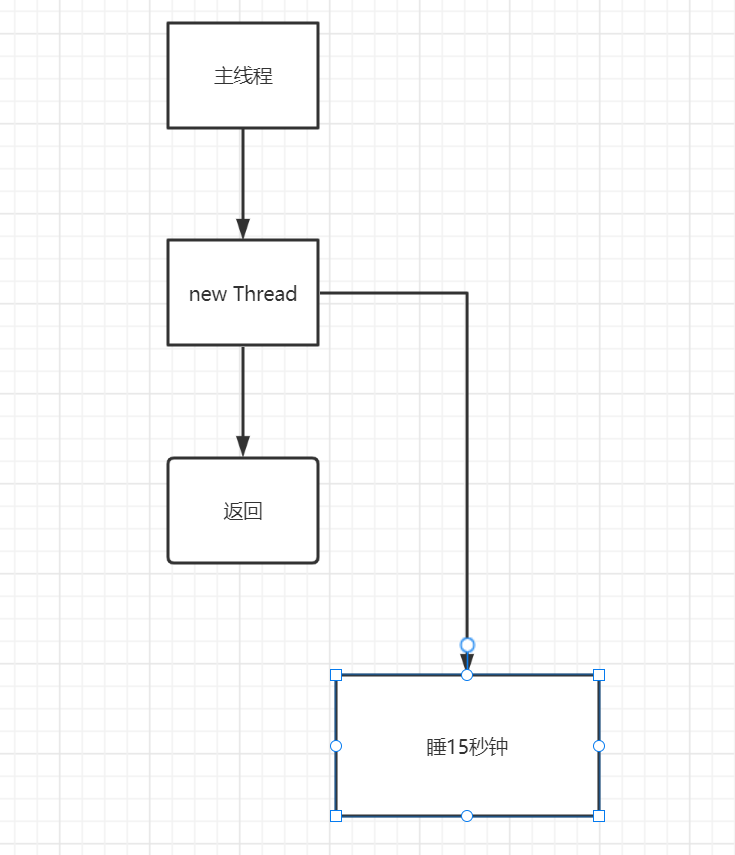
实际情况是主线程在运行代码时,如果有发现创建了新的线程,新的线程内的代码不会影响主线程的执行,所以才会出现直接返回了字符串,没有睡15秒的情况,其实并不是没有执行,只是交给了另外一个线程去执行,这个线程不会影响主线程的代码块执行。
如果我们换种思路想一下,我们现在有一个接口,去数据库里查询了十万条数据,我们去遍历这十万条数据去执行业务代码,就会出现接口处理速度很慢的情况,如果我们能将这十万条数据划分为1000份,然后开启1000个线程同时处理这段业务代码,处理完成后再返回,这样速度就会快很多,这就是多线程的概念,接下来我们来实际操作一下。
- 多线程实战
3.1 线程池的创建
创建如下线程池配置,然后注入到Bean中
/**
* @author lijihong
* @date Created in 2021/09/10 09:40
* @Description: 线程池配置
*/
@EnableAsync // 启用 Spring 的异步方法执行功能
@Configuration
public class ExecutorConfig {
// new ThreadPoolTaskExecutor();
/**
* 核心线程数量,默认1
*/
private int corePoolSize = 10;
/**
* 最大线程数量,默认Integer.MAX_VALUE;
*/
private int maxPoolSize = 25;
/**
* 空闲线程存活时间
*/
private int keepAliveSeconds = 60;
/**
* 线程阻塞队列容量,默认Integer.MAX_VALUE
*/
private int queueCapacity = 1;
/**
* 是否允许核心线程超时
*/
private boolean allowCoreThreadTimeOut = false;
@Bean("asyncExecutor")
public ThreadPoolTaskExecutor asyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 配置核心线程数量
executor.setCorePoolSize(corePoolSize);
// 配置最大线程数
executor.setMaxPoolSize(maxPoolSize);
// 配置队列容量
executor.setQueueCapacity(queueCapacity);
// 配置空闲线程存活时间
executor.setKeepAliveSeconds(keepAliveSeconds);
executor.setAllowCoreThreadTimeOut(allowCoreThreadTimeOut);
// 设置拒绝策略,直接在execute方法的调用线程中运行被拒绝的任务
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 执行初始化
executor.initialize();
return executor;
}
}
@Resource(name = "asyncExecutor")
ThreadPoolTaskExecutor threadPoolExecutor;
这样我们就可以使用线程池来创建线程了
3.2 实战
使用如下代码创建出一个10000条的List来模拟从数据库中查询的数据
public static List<String> initData(){
ArrayList<String> data = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
data.add(String.valueOf(i));
}
return data;
}
使用如下代码模拟我们的业务方法,执行需要一秒钟
public static void deal(String str) throws InterruptedException {
System.out.println("str = " + str);
Thread.sleep(1000);
}
正常执行
public static void main(String[] args) throws InterruptedException {
// 获取数据
List<String> data = initData();
// 遍历
for (String datum : data) {
// 执行业务
deal(datum);
}
// 返回
System.out.println("我执行完毕了!");
}
如上代码执行的话,需要一万秒才可以执行完毕,此时我们再优化一下,加入线程池,使用多线程执行
加入线程池
public static void main(String[] args) throws InterruptedException {
// 获取数据
List<String> data = initData();
// 将一个list 分割为 1000个list
List<List<String>> partitionList = Lists.partition(data, 1000);
for (List<String> strings : partitionList) {
threadPoolExecutor.execute(() -> {
// 执行业务
for (String datum : strings) {
try {
deal(datum);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
}
// 返回
System.out.println("我执行完毕了!");
}
按照理论来说应该只需要10秒就可以执行完毕,但是我们直接看到返回了,因为每一个线程都是异步执行的,而主线程不会管异步的代码块,所以直接返回了,现在我们需要进一步优化
阻塞主线程 - countDownLatch
public static void main(String[] args) throws InterruptedException {
// 获取数据
List<String> data = initData();
// 将一个list 分割为 1000个list
List<List<String>> partitionList = Lists.partition(data, 1000);
// 创建countDownLatch来阻塞主线程,当通过数量等于开启数量时,就会重新开启主线程
CountDownLatch countDownLatch = new CountDownLatch(partitionList.size());
for (List<String> strings : partitionList) {
threadPoolExecutor.execute(() -> {
// 执行业务
for (String datum : strings) {
try {
deal(datum);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
// 每当完成一个线程的任务后,countDownLatch会增加一次计数器
countDownLatch.countDown();
});
}
// 在此处阻塞住主线程,当所有线程的任务全部完成后,放开主线程
countDownLatch.await();
// 返回
System.out.println("我执行完毕了!");
}
如上代码,我们在26行的位置进行了线程阻塞,当全部任务完成后,才会放行主线程去执行下面的代码,从而执行完毕,这次测试10000条数据只用了10秒就完毕了。代码执行的效率取决于第五行代码开启线程的数量,越大越快,但是也就越容易破坏原子性。