项目名称: 摄影图片分析助手
报告日期: 2024年8月18日
项目负责人: NHDBL
项目概述
本项目旨在开发一个智能对话机器人,能够对摄影图片进行评价,并提供提高摄影水平的建议。该机器人利用先进的NVIDIA AI技术,结合图像识别和自然语言处理,能够分析用户上传的照片,判断其风格(如肖像或风景),并根据分析结果给出具体的改进建议。项目的亮点在于其多模态能力,能够处理图像和文本信息,提升用户的互动体验。
技术方案与实施步骤
模型选择
本项目采用了NVIDIA的多种大模型,包括“phi-3-vision-128k-instruct”和“llama-3.1-405b-instruct”。选择这些模型的理由包括:
- 高效的图像处理能力:phi-3模型能够快速准确地分析图像内容,判断其风格。
- 强大的自然语言处理能力:llama-3模型在文本生成和翻译方面表现优异,能够为用户提供清晰的建议和反馈。
- RAG模型的优势:通过结合检索增强生成(RAG)技术,系统能够在生成文本时引入外部知识,提高回答的准确性和相关性。在本项目中,使用RAG来获得不同分类的图片的好坏衡量标准。
数据的构建
数据构建过程包括:
- 评估标准收集: 通过gpt生成各种类型的图片的好坏衡量标准,事先存储到对应的txt文档中。
- 向量化处理:将收集好的不同语句进行向量化处理。
功能整合
本项目整合了多模态功能,包括:
- 图像分析:通过图像识别模型判断照片风格。
- 文本生成:根据分析结果生成建议文本。
- 多语言支持:实现了将建议翻译成中文的功能,增强了用户体验。因为目前phi-3对于中文的支持并不好,因此使用llama3.1对回答进行了翻译。
实施步骤
环境搭建
参考https://blog.csdn.net/kunhe0512/article/details/140910139
代码实现
关键代码实现步骤如下:
- 图像转为Base64编码:使用
image2b64函数将图像文件转换为Base64格式。 - 图像分析与建议生成:通过
chart_agent_gr函数,结合图像分析和文本生成,输出建议。 - 多语言翻译:使用
instruct_chain将生成的建议翻译为中文。
测试与调优
测试过程包括:
- 设计测试用例,验证不同风格图像的分析准确性。
集成与部署
各模块的集成方法包括:
- 将图像分析、文本生成和翻译模块整合为一个完整的工作流。
- 使用gradio部署前端,方便使用。
项目成果与展示
应用场景展示
该对话机器人应用于:
- 摄影指导:为摄影爱好者提供专业的摄影建议。
- 辅助选照片:帮助摄影爱好者挑选照片。
功能演示
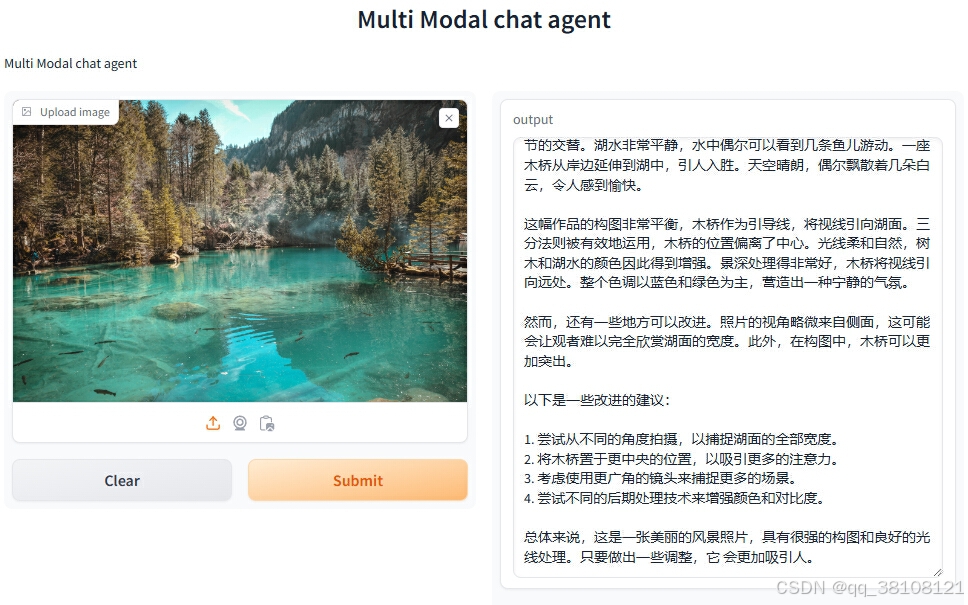
UI界面如下:
问题与解决方案
问题分析
在项目实施过程中,主要遇到的问题包括:
- 图像分析准确性不足,导致建议不够精准。
- 图片内容识别有时存在错误,对于图片上的内容存在幻觉。
项目总结与展望
项目评估
整体表现良好,成功实现了图像分析和建议生成的功能。成功点在于多模态整合和用户体验的提升,但在模型准确性上仍有改进空间。