一、什么是线索二叉树
概括来讲,线索二叉树就是将二叉树中空的指针域利用了起来,用来保存遍历过程中前驱结点和后继结点的信息。其中这样的信息叫做线索。
二叉树的遍历其实就是一个将非线性结构(树,一对多的关系)转化成一个线性结构(线性表,一对一的关系)的过程。得到的线性序列中除第一个结点和最后一个结点外其它结点都只有一个直接前驱和一个直接后继(简称前驱后继)。
有了这些前驱后继信息的好处是:在查找某个结点时就可以类似链表那样很方便的从表头遍历到表尾,并且空间复杂度只有 O ( 1 ) Ο(1) O(1)。而前面二叉树的遍历中,无论递归还是非递归,都要用到栈,空间复杂度跟二叉树的具体形态有关。
二、线索二叉树的存储方式
使用链式存储,其中:
(1)首先最容易想到的办法就是直接在每个结点中单独增加两个指针用来指向前驱后继,但这样增加了结点的空间,降低了存储密度。
(2)因为n个结点必定存在n+1个空指针域,可以利用这些空指针域来存放结点的前驱或后继信息。具体方法是:
-
对于一个结点,如果它的左子结点非空,那么结点左指针指向左子结点不变,否则左指针指向它的前驱结点;同理如果右子结点非空,结点右指针指向右子树不变,否则指向它的后继结点。
-
因为指针域指向的可能是子结点,也可能是前驱或后继结点,所以还需要在结点中为左右两个指针增加两个标志位,分别为LTag,RTag。并表示:
L
T
a
g
=
{
0
结点左指针指向左孩子
1
结点左指针指向前驱结点
LTag= \begin{cases} 0 & \text {结点左指针指向左孩子} \\ 1 & \text{结点左指针指向前驱结点} \end{cases}
LTag={01结点左指针指向左孩子结点左指针指向前驱结点
R
T
a
g
=
{
0
结点右指针指向右孩子
1
结点右指针指向后驱结点
RTag= \begin{cases} 0 & \text {结点右指针指向右孩子} \\ 1 & \text{结点右指针指向后驱结点} \end{cases}
RTag={01结点右指针指向右孩子结点右指针指向后驱结点
关于n个结点存在n+1个空链域:可以这样理解,n个结点一定有2n个指针域,又除根结点外所有结点都被一个指针指向,共占用了n-1个指针域,所以还剩n+1个空指针域。
三、二叉树线索化及遍历
首先创建一棵二叉树
public static TreeNode buildTree(char[] arr, int index) {
TreeNode root = null;
if (index < arr.length) {
if (arr[index] == '#') {
return null;
}
root = new TreeNode(arr[index]);
root.lchild = buildTree(arr, 2 * index + 1);
root.rchild = buildTree(arr, 2 * index + 2);
}
return root;
}
其中结点的结构为
class TreeNode {
char data;
TreeNode lchild;
TreeNode rchild;
int LTag;
int RTag;
public TreeNode(char data) {
this.data = data;
this.LTag = 0;
this.RTag = 0;
}
}
(一)前序线索化及遍历
前序线索化
前序线索化就是在前序遍历的过程中动态的为每个结点添加前驱或后继的信息。
//首先创建一个结点用来保存访问结点的前驱结点
static TreeNode preNode = null;
public static void preThreading(TreeNode T) {
if (T != null) {
// 访问结点的左指针为空则指向前驱结点,修改标志位
if (T.lchild == null) {
T.lchild = preNode;
T.LTag = 1;
}
// 前驱结点存在且右指针为空则右指针指向后继结点也就是访问结点,修改标志位
if (preNode != null && preNode.rchild == null) {
preNode.rchild = T;
preNode.RTag = 1;
}
// 修改前驱结点
preNode = T;
// 递归处理左子树
if (T.LTag == 0)
preThreading(T.lchild);
// 递归处理右子树
if (T.RTag == 0)
preThreading(T.rchild);
}
}
下面是这棵二叉树前序线索化后的结果(虚线表示线索),可以发现前序线索化后可以根据后继线索从前往后遍历,但不能根据前驱线索从后往前遍历。总结就是前序线索化找前驱困难。
要注意前序线索化过程存在死循环,进入递归时必须要有 if 条件限制。以上面二叉树为例,如果没有限制,假设当前访问结点是D,和前驱结点B建立线索也就是左指针指向B,然后递归进入左子树回到了B,B又递归进入左子树回到D,陷入死循环。
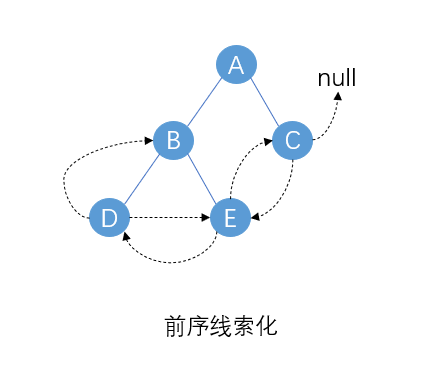
前序线索化的遍历(按后继线索)(ABDEC)
按后继线索是指遍历过程中用到的线索是指向后继结点的线索,下面同理。
public static void preThreadTraverse(TreeNode T) {
while (T != null) {
// 从根结点开始往左一直遍历到最左子结点
while (T.LTag == 0) {
System.out.print(T.data);
T = T.lchild;
}
System.out.print(T.data);
// 这里的T.rchild可能是线索,可能是右子结点
T = T.rchild;
}
}
(二)中序线索化及遍历
中序线索化
中序线索化即在中序遍历的过程中动态的为每个结点添加前驱或后继的信息。
static TreeNode preNode = null;
public static void inThreading(TreeNode T) {
if (T != null) {
// 递归处理左子树
inThreading(T.lchild);
// 访问结点的左指针为空则指向前驱结点,修改标志位
if (T.lchild == null) {
T.lchild = preNode;
T.LTag = 1;
}
// 前驱结点存在且右指针为空则右指针指向后继结点也就是访问结点,修改标志位
if (preNode != null && preNode.rchild == null) {
preNode.rchild = T;
preNode.RTag = 1;
}
// 修改前驱结点
preNode = T;
// 递归处理右子树
inThreading(T.rchild);
}
}
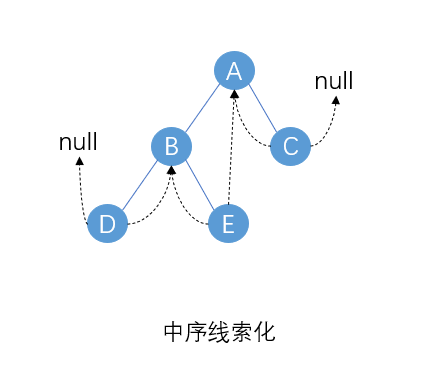
还是上面那棵二叉树中序线索化后的结果,可以发现中序线索化后既可以按照后继线索从前往后遍历也可以按照前驱线索从后往前遍历。
中序线索化的遍历(按后继线索)(DBEAC)
public static void inThreadTraverse(TreeNode T) {
while (T != null) {
// 找到开始遍历的结点也就是最左子结点并输出
while (T.LTag == 0) {
T = T.lchild;
}
System.out.print(T.data);
/*
* 如果存在右线索不断的沿右线索遍历后继结点并输出。
* 其实个人觉得下面while也可以替换成if,因为中序左根右,线索一定是左子结点指向父结点,
* 那么接下来一定是遍历这个父结点的右子树,即不存在两条连续的后继线索。 如果有不同想法欢迎指出。
*/
while (T.rchild != null && T.RTag == 1) {
T = T.rchild;
System.out.print(T.data);
}
// 不存在右线索时转向这个结点的右子树
T = T.rchild;
}
}
(三)后序线索化及遍历
后序线索化
后序线索化即在后序遍历的过程中动态的为每个结点添加前驱或后继的信息。
static TreeNode preNode = null;
public static void postThreading(TreeNode T) {
if (T != null) {
// 递归处理左子树
postThreading(T.lchild);
// 递归处理右子树
postThreading(T.rchild);
// 访问结点的左指针为空则指向前驱结点,修改标志位
if (T.lchild == null) {
T.lchild = preNode;
T.LTag = 1;
}
// 前驱结点存在且右指针为空则右指针指向后继结点也就是访问结点,修改标志位
if (preNode != null && preNode.rchild == null) {
preNode.rchild = T;
preNode.RTag = 1;
}
// 修改前驱结点
preNode = T;
}
}
后序线索化后的结果,可以发现后序线索化后可以按照前驱线索从后往前遍历,但不能根据后继线索从前往后遍历。总结就是后序线索化找后继困难。
后序线索化的遍历(按后继线索)(DEBCA)
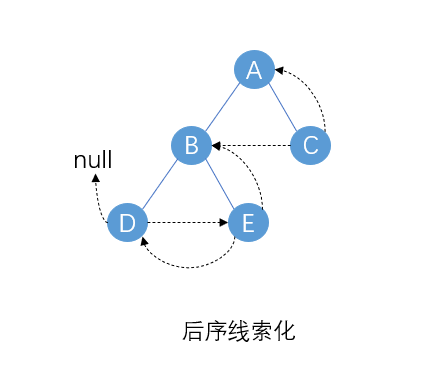
因为后序遍历左右根的次序,所以后序遍历建立线索时必然存在两种情况:
(1)一个结点与父结点建立线索时因为该结点的右子结点存在右指针域非空导致后继线索建立失败。
(2)从根结点的左子树往右子树建立线索时因为根结点的左子节点右指针域非空导致后继线索建立失败。
比如上面这棵树按后继线索遍历时,先找到开始遍历的结点D,然后依次遍历E,B,但结点B的右指针保存的是右子结点而不是线索,无法遍历到结点C。对应上述的情况(2)。
再来回顾一下前序中序的线索化:因为前序遍历根左右中序遍历左根右的顺序,最后访问的结点一定是左右叶子结点,两个指针域为空线索可以建立。否则在原二叉树中一定存在一条路径可以间接找到后继结点,也就不存在后序线索化中的既后继线索建立失败又无法通过原二叉树中的指向关系找到后继结点。
无论出现上面两种情况中的哪种情况,都可以通过在原二叉树结点中添加一个指向父结点的指针来解决。比如上面这棵树遍历到结点B时,可以通过先回到父结点A再寻找到结点C。
对应的结点结构
class TreeNode {
char data;
TreeNode lchild;
TreeNode rchild;
TreeNode parent; // 添加父结点的指针
int LTag;
int RTag;
public TreeNode(char data) {
this.data = data;
this.LTag = 0;
this.RTag = 0;
}
}
带父指针的二叉树初始化
public static TreeNode buildTree(char[] arr, int index) {
TreeNode root = null;
if (index < arr.length) {
if (arr[index] == '#') {
return null;
}
root = new TreeNode(arr[index]);
root.lchild = buildTree(arr, 2 * index + 1);
root.rchild = buildTree(arr, 2 * index + 2);
// 记录父结点
if (root.lchild != null)
root.lchild.parent = root;
if (root.rchild != null)
root.rchild.parent = root;
}
return root;
}
线索化过程不变。
遍历
public static void postThreadTraverse(TreeNode T) {
TreeNode root = T;
TreeNode preNode = null;
// 找到后序遍历开始的结点
while (T.LTag == 0) {
T = T.lchild;
}
while (true) {
// 右指针是线索
if (T.RTag == 1) {
System.out.print(T.data);
preNode = T;
T = T.rchild;
} else {
// 上个访问的结点是右子结点
if (T.rchild == preNode) {
System.out.print(T.data);
if (T == root) {
return;
}
preNode = T;
T = T.parent;
} else {
// 上个访问的结点是左子结点转到右子树
T = T.rchild;
while (T.LTag == 0) {
T = T.lchild;
}
}
}
}
}
四、带头结点的中序线索化
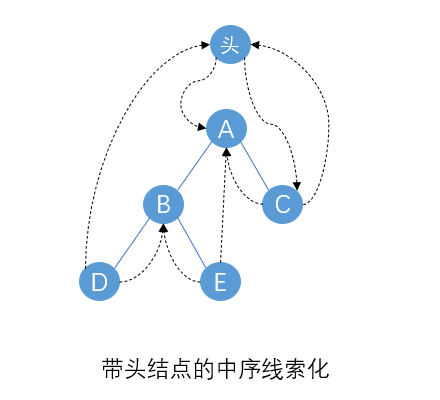
因为中序线索化可以根据前驱线索或后继线索双向遍历的特点,所以可以通过添加一个头结点形成类似双向循环链表结构,既可以从头结点从前往后遍历,也可以从头结点从后往前遍历。
具体步骤为:
(1)新建一个头结点,头结点左指针指向根节点,左标记LTag=0不变,右标记Rtag初始修改为1表示用来存放线索。preNode初始指向头结点。
(2)调用中序线索化的算法,调用完毕后preNode会停在最后个结点的位置。
(3)最后将头结点右指针指向最后一个结点preNode,最后一个结点右指针指向头结点。
// 注意head是一个data为空的结点而不是null,且LTag默认为0
public static void inThreadingWithHead(TreeNode head, TreeNode T) {
if (T != null) {
head.lchild = T;
head.RTag = 1;
preNode = head;
inThreading(T);
preNode.rchild = head;
preNode.RTag = 1;
head.rchild = preNode;
}
}
线索化后的结果:
遍历
public static void inThreadWithHeadTraverse(TreeNode head) {
TreeNode T = head.lchild;
// 此处循环结束条件不再是T!=null
while (T != head) {
while (T.LTag == 0) {
T = T.lchild;
}
System.out.print(T.data);
// 此处循环条件要加上T.rchild!=head限制,如果不限制会陷入头结点与最后个结点之间的死循环
while (T.RTag == 1 && T.rchild != head) {
T = T.rchild;
System.out.print(T.data);
}
T = T.rchild;
}
}
五、总结
(1)无论有没有线索化,遍历的过程中都只访问了
n
n
n个结点,时间复杂度都是
O
(
n
)
Ο(n)
O(n)。线索化的空间复杂度除第一次遍历建立线索外,之后遍历都是
O
(
1
)
Ο(1)
O(1)。
(2)前序线索化找前驱困难,后序线索化找后继困难。
(3)因为中序线索化可以双向遍历的原因,所以可以在中序线索化中添加一个头结点构成双向循环链表。
(4)点击查看后序线索化动态演示过程。