简单介绍一下free的流程
- free()函数首先判断__free_hook是否为NULL,不是NULL则调用__free_hook,return,否则转下一步。
- 判断传入的指针是否为 0,如果为 0,则什么都不做,直接 return。否则转下一步。
- 判断所需释放的 chunk 是否为 mmaped chunk,如果是,则调用 munmap()释放
mmaped chunk,解除内存空间映射,该该空间不再有效。如果开启了 mmap 分配
阈值的动态调整机制,并且当前回收的 chunk 大小大于 mmap 分配阈值,将 mmap
分配阈值设置为该 chunk 的大小,将 mmap 收缩阈值设定为 mmap 分配阈值的 2
倍,释放完成,否则跳到下一步。 - 判断 chunk 的大小,若 chunk_size <= max_fast,则转到下一步,否则跳到第 6 步。
- 将 chunk 放到 fast bins 中,chunk 放入到 fast bins 中时,并不修改该 chunk 使用状
态位 P。也不与相邻的 chunk 进行合并。只是放进去,如此而已。这一步做完之后
释放便结束了,程序从 free()函数中返回。 - 判断前一个 chunk 是否处在使用中,如果前一个块也是空闲块,则合并。并转下一
步。 - 判断当前释放 chunk 的下一个块是否为 top chunk,如果是,则转第 9 步,否则转
下一步。 - 判断下一个 chunk 是否处在使用中,如果下一个 chunk 也是空闲的,则合并,并将
合并后的 chunk 放到 unsorted bin 中。注意,这里在合并的过程中,要更新 chunk
的大小,以反映合并后的 chunk 的大小。并转到第 10 步。 - 如果执行到这一步,说明释放了一个与 top chunk 相邻的 chunk。则无论它有多大,
都将它与 top chunk 合并,并更新 top chunk 的大小等信息。转下一步。 - 判断合并后的 chunk 的大小是否大于 FASTBIN_CONSOLIDATION_THRESHOLD(默认
64KB),如果是的话,则会触发进行 fast bins 的合并操作,fast bins 中的 chunk 将被
遍历,并与相邻的空闲 chunk 进行合并,合并后的 chunk 会被放到 unsorted bin 中。
fast bins 将变为空,操作完成之后转下一步。 - 判断 top chunk 的大小是否大于 mmap 收缩阈值(默认为 128KB),如果是的话,对
于主分配区,则会试图归还 top chunk 中的一部分给操作系统。但是最先分配的
128KB 空间是不会归还的,ptmalloc 会一直管理这部分内存,用于响应用户的分配
请求;如果为非主分配区,会进行 sub-heap 收缩,将 top chunk 的一部分返回给操
作系统,如果 top chunk 为整个 sub-heap,会把整个 sub-heap 还回给操作系统。做
完这一步之后,释放结束,从 free() 函数退出。可以看出,收缩堆的条件是当前
free 的 chunk 大小加上前后能合并 chunk 的大小大于 64k,并且要 top chunk 的大
小要达到 mmap 收缩阈值,才有可能收缩堆。
__libc_free
一上来查看__free_hook是否为0,不是0调用,这里区别于__malloc_hook的一点就是__free_hook默认是0,不会像__malloc_hook初始化为malloc_hook_ini
所以一般系统不会主动去调用__free_hook除非两种情况
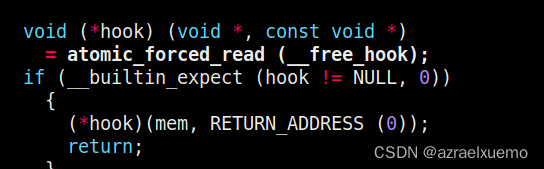
- 开发人员自己写了个free函数,所以会修改 free_hook
- 攻击者利用free_hook getshell
这个其实给libc带来了很多安全隐患,但这个hook机制在libc-2.34中才被移除

接下来就是check如果传入的参数是0,那么直接return,也就是free(0)无效果
然后转化成chunk,用户直接拿过来的指针都是指向mem区域,防止用户误操作,而对于glibc来说他们想要的更多是chunk区域
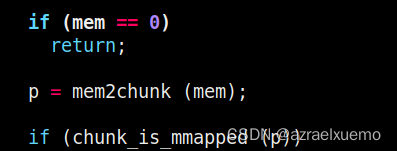
如果是mmaped,进入下面处理mmap分配的部分
其实不复杂,就是判断是不是开启了动态调整门槛,如果开启了,还要保证当前的大小>mmap的门槛,太小了没必要修改,并且小于最大的分配分配,太大了认为不合法,如果满足,就修改mmap分配门槛为chunksize,默认mmap分配门槛为0x20000,128kb,并且收缩门槛设置为2倍chunksize
最后统一调用munmap_chunk去释放

如果不是mmap的,也就是通过sbrk分配的,就会进入下面流程
通过arena_for_chunk获取到main_arena,然后调用_int_free,可以说大部分free操作都是再_int_free里面实现

_int_free
上来先求个size
简单的check,所有heap必经之路,p指针是否对齐,并且位置不应该特别大,因为-size是0xff开头,其实是内核区域,这里面注释也说了,只是一个不消耗性能的check
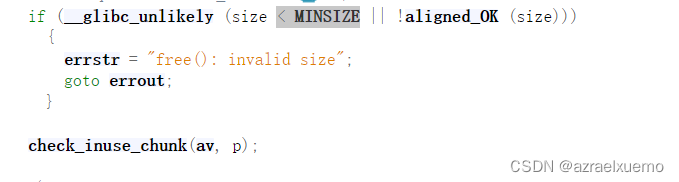
第二个必须经过的check,size不应该特别小,因为我们free的堆块归根到底是malloc出来的,malloc出来的块不可能比MINSIZE0x20还要小(没有说明默认amd64),然后size必须也要对齐,也就是size&0xf==0
这里可以看到源码里面其实还有一个check,也就是check_inuse_chunk
我们可以找到对应源码的定义,一般我们都不会开malloc_debug这个宏,所以下面这些函数其实是无用的
然后进入复杂的free流程




fastbin范围的chunk处理
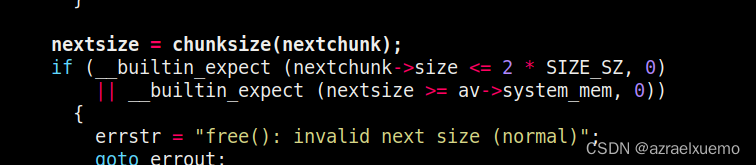
首先检查下一个堆块是否合法,具体来说就是下一个块的大小是不是过小(<0x10),是否过大(>=system_mem这个值是main_arena里面一共分配的内存,你不可能比堆管理器总共分配的大小还大)
下面有一个类似于清空的函数
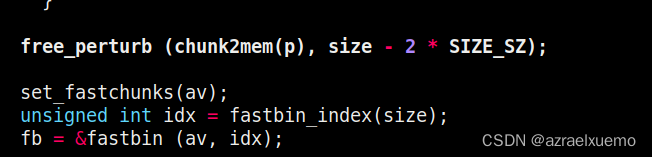
可以看到正如if里面 unlikely所言,perturb_byte很可能不是1,所以free_perturb基本上没有任何效果,不管是malloc还是free里面
set_fastchunks其实就是给main_arena设置一个状态,表示我现在有free的fastbin,因为某些情况largebin里有合并fastbin的操作
接着就是找到对应的fastbin的索引
old就是当前fastbinY里面的节点
double free check,其实这个check是个弱check,他只check 了第一个节点是不是等于当前free的块,绕过很简单,doublefree中间随便free一个,相比于libc-2.30之后的tcache double free检查不知道弱了很多,tcache double free check会检查里面每一个空闲块是不是和当前要被free的一致
这里我是单线程,所以也没上锁,have_lock==0
这里其实操作就是插入
把我们这个要free的块插入到里面
由于fastbin是一个filo的结构
他先把old也就是free之前的节点保存到old2里面
然后让我们当前free的块指向他



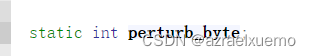
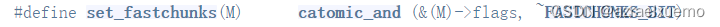


下面然后就是把fd里面保存的值从old2替换成p,catomic操作是原子交换,防止多线程干扰,返回值就是原来的值,这个还做了一个check,防止被交换失败,但实际是不会改变的
后面还有一个跟锁有关的操作,这里我们关注old_idx,可以看到old_idx是之前我们求得,这里其实还是比较严谨得,因为他去判断你fastbin里面当前第一个free chunk对应的索引是不是正确的,但是由于这里我have_lock为NULL,所以不会进入判断,如果有have_lock的时候可能还要注意
因为fastbin的size不会超过限制,那么就直接return就好


非fastbin大小的chunk处理
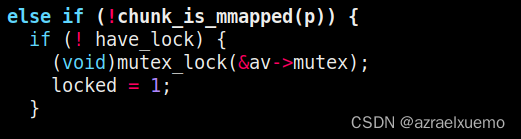
当我们size不在fastbin范围,也就是默认情况下>0x80的时候,那么我们进入不了第一个if
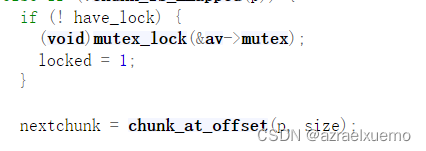
那么进入else if,这里判断这个块是不是 非mmap出来,然后检查锁,这里之前提到过我们fastbin处理的时候是没有锁的,所以先上个锁
找到nextchunk
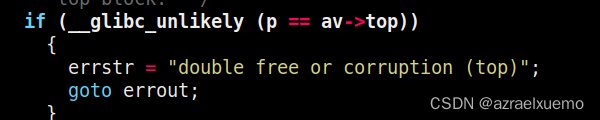
这里有个check,因为其实对于用户来说,我们一般是不会获取到top chunk的,或者这样理解,topchunk的free只能是glibc堆管理器来做的,他认为用户free top chunk是非法的,那么就会报错
这里由于我们是sbrk分配的,所以都是连续的,不像mmap可能有空袭,而且这里注释主要提到的是第二个check,这个check的是nextchunk的范围是否合理,因为av->top+chunksize(av->top)其实是合法堆里面最大的地址,对于非mmap的堆块,这个地址就是上限,不能比这个还大,不然就报错
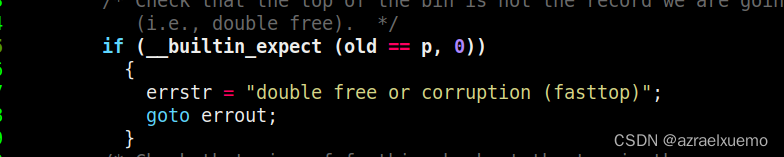
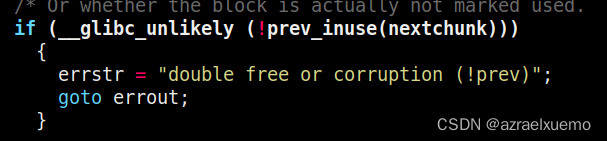
double free check因为对于fastbin来说,他的inuse状态一直是1,因为这是glibc管理器设计的,他不让合并fastbin除非特殊情况,一般情况下free的chunk都会被设置为not in use,然后就会出现相邻合并,所以这里就check,如果这个chunk已经被free过,那么就不能再free了,一个很质朴的检查
这里和fastbin一样,都check了下一个块的大小是否合法
没有效果,跳过
接下来就是我提到的合并操作


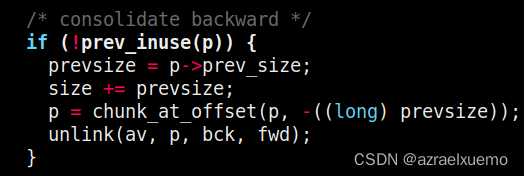
如果前一个块是free的,那么当前块的size就修改为两个之后,并且指针调整到第一个块,同时把第一个块从对应的链上取下来
这里还有一个判断,所以会有两条路,那我们先看下一个块是top chunk的
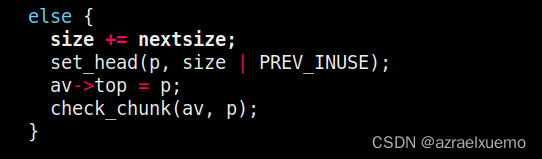
可以看到直接把他合并到top chunk,具体操作是,首先算出新的size=size+top chunksize,然后修改header,然后让top chunk指向p
那么在回到如果下一个不是topchunk
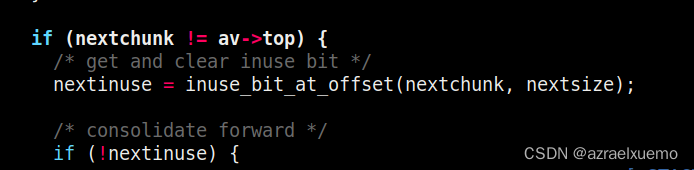
首先看看一个块是否在使用,如果是那么也是同样的合并,unlink
不是的话就把下一个块设置prev_inuse=0,标志前面的块free了
然后就是把当前的块放入unsorted bin
因为unsorted bin是FIFO的结构
我们去块都是从Last(unsortedbin()),也就是unsortedbin()->bk开始用,所以插入就得从unsortedbin()->fd开始插入,也就是插入到unsortedbin()和unsortedbin()->fd之间
这里还check了双向链表的完整性
然后就是上链操作
并且如果对应chunk size是large bin,要清空fd_nextsize 和bk_nextsize,因为这两个对于unsorted bin没有意义
接着设置大小,和下一个块的prev_inuse
同时最后一个check_free_chunk(av,p)也没有效果

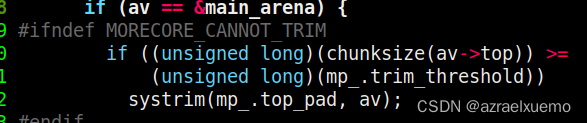
接下来就是提到的收缩操作
如果size过大的话,会尝试缩小空间
顺便看一下具体的大小
这里如果还有空闲的fastbin,那么再合并一下,这样有可能可以回收更多的空间
下面就是源码里面提到的,如果top chunk过大,那么就会缩小top chunk
具体systemtrim没有什么好说的,如果有兴趣可以自己看看