Dual Graph Convolutional Networks for Aspect-based Sentiment Analysis
GitHub:https://github.com/CCChenhao997/DualGCN-ABSA
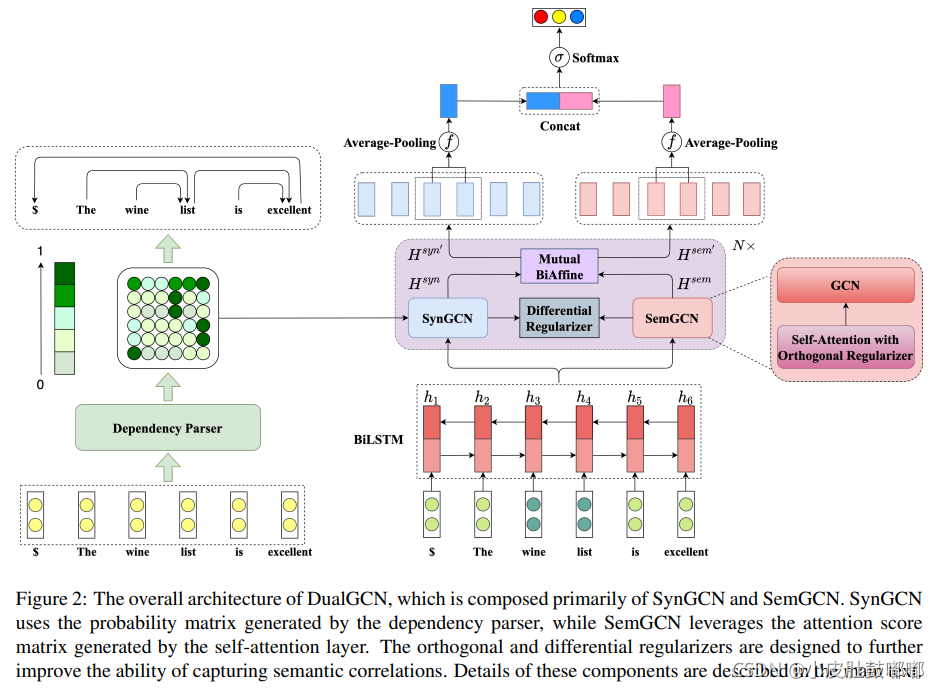
SynGCN:利用依赖弧概率矩阵,对比parser的最终输出包含更丰富的语法信息;
SemGCN:自注意力——捕获语义关联;
Mutual BiAffine:在SynGCN和SemGCN模块间有效交换相关特征;
两个Regularizer:
SemGCN里的.Orthogonal Regularizer:期望词间注意力分数不重叠→注意力矩阵正交,加入了正交正则化;
SynGCN和SemGCN之间的.Differential Regularizer:期望从 SynGCN 和 SemGCN 模块学习的两种特征表示能够包含语法、语义不同信息。
Multi-Label Few-Shot Learning for Aspect Category Detection
Abstract:Aspect category detection (ACD) in sentiment analysis aims to identify the aspect categories mentioned in a sentence. In this paper, we formulate ACD in the few-shot learning scenario. However, existing few-shot learning approaches mainly focus on single-label predictions. These methods can not work well for the ACD task since a sentence may contain multiple aspect categories. Therefore, we propose a multi-label few-shot learning method based on the prototypical network. To alleviate the noise, we design two effective attention mechanisms. The support-set attention aims to extract better prototypes by removing irrelevant aspects. The query-set attention computes multiple prototype-specific representations for each query instance, which are then used to compute accurate distances with the corresponding prototypes. To achieve multi-label inference, we further learn a dynamic threshold per instance by a policy network. Extensive experimental results on three datasets demonstrate that the proposed method significantly outperforms strong baselines.
情感分析中的方面类别检测(Aspect category detection, ACD)的目的是识别句子中提到的方面类别。在本文中,我们提出了在few-shot学习场景下的ACD。然而,现有的few-shot学习方法主要集中在单标签预测。这些方法不能很好地用于ACD任务,因为一个句子可能包含多个方面类别。因此,我们提出了一种基于原型网络的多标签few-shot学习方法。为了减少噪音,我们设计了两种有效的注意机制。支持集关注的目的是通过移除不相关的方面来提取更好的原型。查询集注意力为每个查询实例计算多个特定于原型的表示,然后使用这些表示来计算与相应原型的精确距离。为了实现多标签推理,我们进一步通过策略网络学习每个实例的动态阈值。在三个数据集上的大量实验结果表明,该方法的性能明显优于强基线。
DynaSent: A Dynamic Benchmark for Sentiment Analysis
GitHub:https://github.com/cgpotts/dynasent
Abstract:We introduce DynaSent (‘Dynamic Sentiment’), a new English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. DynaSent combines naturally occurring sentences with sentences created using the open-source Dynabench Platform, which facilities human-and-model-in-the-loop dataset creation. DynaSent has a total of 121,634 sentences, each validated by five crowdworkers, and its development and test splits are designed to produce chance performance for even the best models we have been able to develop; when future models solve this task, we will use them to create DynaSent version 2, continuing the dynamic evolution of this benchmark. Here, we report on the dataset creation effort, focusing on the steps we took to increase quality and reduce artifacts. We also present evidence that DynaSent’s Neutral category is more coherent than the comparable category in other benchmarks, and we motivat