
《C++程序设计基础教程》——刘厚泉,李政伟,二零一三年九月版,学习笔记
文章目录
1、函数定义与函数声明
在C++中,函数是代码的基本构建块之一,用于执行特定的任务或计算值。函数封装了一段代码,使其可以在程序中多次调用,从而提高代码的重用性和模块化。
从用户的角度,函数可分为系统内部函数(库函数)和用户自定义函数两类
1.1、函数的定义
函数的定义包含了函数的返回类型、函数名、参数列表(如果有的话)以及函数体。
函数定义告诉编译器函数执行什么操作以及如何处理传递给它的数据。
返回类型 函数名(参数列表) {
// 函数体
}
- 返回类型:指定函数返回值的类型。如果函数不返回任何值,则返回类型为void。
- 函数名:函数的标识符,用于在程序中调用该函数。
- 参数列表:也叫形参列表,包含在圆括号中的参数声明,这些参数是函数执行时所需的输入值。每个参数都由其类型和名称组成,参数之间用逗号分隔。如果函数不接受任何参数,则参数列表为空(即只有一对空圆括号)。
- 函数体:包含执行函数任务的语句块。这些语句定义了函数的行为。函数体由一对大括号{}包围。
eg
int multiply(int a, int b) {
return a * b; // 返回两个整数的乘积
}
形参列表中不能出现同名参数
形参是局部变量
1.2、函数的返回值
使用 return 语句
- 在函数体中,return 语句用于指定函数的返回值。当执行到 return 语句时,函数会立即结束执行,并将指定的值返回给调用者。如果函数返回类型是 void,则 return 语句后面不需要跟任何值,或者可以省略 return 语句(但函数体末尾隐式包含一个返回 void 的 return)。
返回类型
- 函数的返回类型可以是任何有效的 C++ 数据类型,包括基本数据类型(如 int、float、double、char 等)、用户定义的类型(如类、结构体等)、指针类型、引用类型以及void类型(表示函数不返回任何值)。
返回值的作用域和生命周期
- 局部变量:如果函数返回的是一个局部变量(例如,在函数内部定义的int变量),这是不安全的,因为局部变量在函数返回后会被销毁。然而,如果函数返回的是一个值(如整数、浮点数等),那么实际上返回的是该值的副本,而不是变量本身。这是因为 C++ 采用值传递的方式返回基本数据类型。
- 动态分配的内存:如果函数返回的是一个指向动态分配内存的指针,调用者需要负责释放这块内存,以避免内存泄漏。这是一种常见的做法,但需要谨慎管理内存。
- 引用和指针:函数可以返回引用或指针,但这通常要求返回的对象在函数返回后仍然有效。例如,函数可以返回类成员的引用或指向静态分配内存的指针。
如果函数类型和 return 语句中表达式的值不一致,则以函数类型为准
函数类型为 void 的时候,函数体中可以有 return,也可以没有
1.3、函数声明
函数声明(函数原型,function prototype)扮演着至关重要的角色。它不仅是编译器理解函数接口(即函数的返回类型、名称以及参数列表)的窗口,还允许我们在函数实际定义之前便能够调用它。函数声明通常被置于头文件中,以便在多个源文件间实现重用。
返回类型 函数名(参数类型1 参数名1, 参数类型2 参数名2, ...);
- 返回类型:明确函数返回值的类型。如果函数不返回任何值,则使用void关键字。
- 函数名:作为函数的唯一标识符,用于在程序中调用。
- 参数列表:包含函数执行所需输入参数的详细信息。每个参数均注明其类型和名称,参数间以逗号分隔。若函数不接受任何参数,则参数列表为空(仅一对空圆括号)。
函数声明只比函数头多了一个分号
声明中形参的名字可以省略,只要指明形参的个数、类型及顺序就足够了(即使函数原型)
int multiply(int, int);
先声明后使用
声明就是在函数尚未定义的情况下,提前将该函数的相关信息告诉编译系统,以保证编译过程的正常进行
如果被调函数的定义出现在主函数之前,可以不必声明
2、函数的调用
2.1、函数调用的概念
调用一个函数就是执行该函数的函数体
函数名(参数1, 参数2, ...);
- 函数名:指定要调用的函数。
- 参数:提供函数执行所需的输入值。参数的数量和类型必须与函数声明和定义中指定的相匹配。
当你调用一个函数时,程序的控制流会跳转到该函数,执行其中的语句,并在函数返回后继续执行调用点之后的代码。
主调函数、被调函数
实参、形参
#include <iostream>
using namespace std;
int main()
{
int a=3,b=4,c;
int max(int, int);
c = max(a,b);
cout << c << endl;
return 0;
}
int max(int a, int b)
{
return a>b?a:b;
}
output
4
只有在发生函数调用时,函数 max 中的形参才被分配内存单元,以便接收从实参传过来的数据
函数调用结束后,形参所占的内存单元将被释放
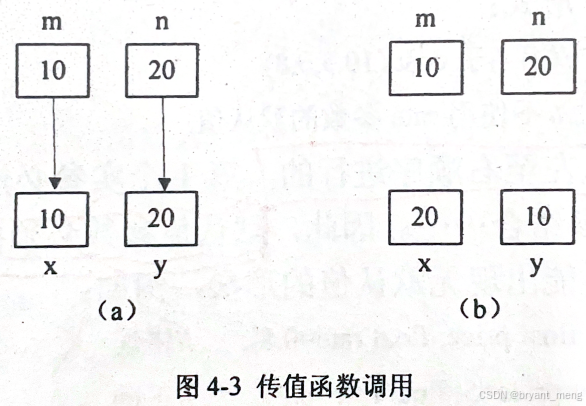
2.2、函数的传值调用
被调函数执行时,只能访问形参对应的内存单元(单元中存放了实参的值),而不能直接访问实参对应的单元,因而无法改变实参的值
#include <iostream>
using namespace std;
void exchange(int, int);
int main()
{
int m = 10, n = 20;
cout << "实参交换前:" << m << " " << n << endl;
exchange(m, n);
cout << "实参交换后:" << m << " " << n << endl;
return 0;
}
void exchange(int x, int y)
{
cout << "形参交换前:" << x << " " << y << endl;
int tmpt;
tmpt = x;
x = y;
y = tmpt;
cout << "形参交换后:" << x << " " << y << endl;
}
output
实参交换前:10 20
形参交换前:10 20
形参交换后:20 10
实参交换后:10 20
2.3、默认值参数
在函数声明或定义中,直接在参数列表内为参数指定默认值。
void myFunction(int a, double b = 3.14, string c = "default") {
// 函数体
}
默认值参数必须按从右向左的顺序定义
void illegalFunction(int a = 1, int b, int c = 3);
上述声明是错误的
如果你将函数声明和定义分开,默认值应该在函数声明中指定,而不是在定义中。这有助于确保所有调用该函数的地方都能看到默认值。
// 声明
void myFunction(int a, double b = 3.14);
// 定义
void myFunction(int a, double b) {
// 函数体
}
#include <iostream>
#include <string>
using namespace std;
// 声明函数,其中两个参数有默认值
void printInfo(int age = 25, string name = "John Doe", bool isStudent = false)
{
cout << "Age: " << age << endl;
cout << "Name: " << name << endl;
cout << "Is Student: " << (isStudent ? "Yes" : "No") << endl;
}
int main()
{
// 调用函数,省略所有默认值参数
printInfo();
// 调用函数,省略第二个和第三个参数(使用默认值)
printInfo(30);
// 调用函数,省略第三个参数(使用默认值)
printInfo(22, "Bob");
return 0;
}
output
Age: 25
Name: John Doe
Is Student: No
Age: 30
Name: John Doe
Is Student: No
Age: 22
Name: Bob
Is Student: No
3、函数重载
重载,就是一名多用
函数重载(Function Overloading)是一种允许在同一作用域内创建多个同名函数的方法,但这些函数的参数列表(参数的数量、类型或顺序)必须不同。函数重载提高了代码的可读性和灵活性,因为它允许使用相同的函数名来执行不同的任务,而这些任务是通过不同的参数来区分的。
函数重载的要点
- 相同的函数名:所有重载的函数必须具有相同的名称。
- 不同的参数列表:重载函数的参数列表必须不同。这可以通过改变参数的数量、类型或顺序来实现。
- 返回类型:在C++中,函数的返回类型不能作为重载的依据。也就是说,即使两个函数的返回类型不同,但如果它们的参数列表相同,那么它们也不能被重载。
- 作用域:重载的函数必须在同一作用域内声明。
#include <iostream>
#include <string>
using namespace std;
// 重载函数,打印整数
void print(int i) {
cout << "Integer: " << i << endl;
}
// 重载函数,打印浮点数
void print(double d) {
cout << "Double: " << d << endl;
}
// 重载函数,打印字符串
void print(const string& str) {
cout << "String: " << str << endl;
}
// 重载函数,打印整数和字符串
void print(int i, const string& str) {
cout << "Integer and String: " << i << ", " << str << endl;
}
int main() {
print(42); // 调用打印整数的函数
print(3.14); // 调用打印浮点数的函数
print("Hello, World!"); // 调用打印字符串的函数
print(10, "points"); // 调用打印整数和字符串的函数
return 0;
}
output
Integer: 42
Double: 3.14
String: Hello, World!
Integer and String: 10, points
同名函数应该具有相同或相似功能,这是比较好的编程风格
#include <iostream>
using namespace std;
int myabs(int x)
{
return x>0?x:-x;
}
long myabs(long x)
{
return x>0?x:-x;
}
double myabs(double x)
{
return x>0?x:-x;
}
int main()
{
int a = 3, ra;
long b = -1234567, rb;
double c = -0.123, rc;
ra = myabs(a);
cout << ra << endl;
rb = myabs(b);
cout << rb << endl;
rc = myabs(c);
cout << rc << endl;
return 0;
}
output
3
1234567
0.123
默认参数与函数重载
#include <iostream>
using namespace std;
int func(int x)
{
return 0;
}
int func(int x, int y=2)
{
return 0;
}
int func(int x=1, int y=2)
{
return 0;
}
int main()
{
func(3); // 错误
func(3, 4); // 错误
return 0;
}
上面展示的例子都是错误的,func(3) 不知道调用3个中的哪一个,func(3,4) 不知道调用后面两个中的哪一个
4、函数模板
函数模板(function template)是C++编程中一种强大的特性,它允许程序员编写与类型无关的通用函数。通过使用模板,你可以定义一个函数或类,并在编译时由编译器自动实例化出针对特定类型的版本。
基本语法
template <typename T>
return_type function_name(parameter_list);
适用于函数的参数个数相同而类型不同,且函数体相同的情况
模板是泛型编程(Generic Programming)的基础
eg:
#include <iostream>
using namespace std;
template <typename T>
T myabs(T x)
{
return x > 0? x: -x;
}
int main()
{
int a = 3, ra;
long b = -1234567, rb;
double c = -0.123, rc;
ra = myabs(a);
cout << ra << endl;
rb = myabs(b);
cout << rb << endl;
rc = myabs(c);
cout << rc << endl;
return 0;
}
output
3
1234567
0.123
可以看到利用函数模板可以很大程度上简化代码
简化前
int myabs(int x)
{
return x>0?x:-x;
}
long myabs(long x)
{
return x>0?x:-x;
}
double myabs(double x)
{
return x>0?x:-x;
}
简化后
template <typename T>
T myabs(T x)
{
return x > 0? x: -x;
}
求两个数当中的最大值
#include <iostream>
using namespace std;
// 函数模板定义
template <typename T>
T mymax(T a, T b)
{
return (a > b) ? a : b;
}
int main() {
int int1 = 3, int2 = 4;
double double1 = 3.1, double2 = 2.5;
// 使用模板函数
cout << "Max of int1 and int2: " << mymax(int1, int2) << endl;
cout << "Max of double1 and double2: " << mymax(double1, double2) << endl;
return 0;
}
output
Max of int1 and int2: 4
Max of double1 and double2: 3.1
交换数据
#include <iostream>
using namespace std;
// 函数模板定义,有两个模板参数
template <typename T>
void myswap(T& a, T& b)
{
T temp = a;
a = b;
b = temp;
}
int main() {
int int1 = 3, int2 = 4;
string str1 = "Hello", str2 = "World";
// 使用模板函数
myswap(int1, int2);
myswap(str1, str2);
cout << "Swapped int1 and int2: " << int1 << ", " << int2 << endl;
cout << "Swapped str1 and str2: " << str1 << ", " << str2 << endl;
return 0;
}
output
Swapped int1 and int2: 4, 3
Swapped str1 and str2: World, Hello
5、函数的嵌套调用
不可以嵌套定义函数,但是可以嵌套调用函数
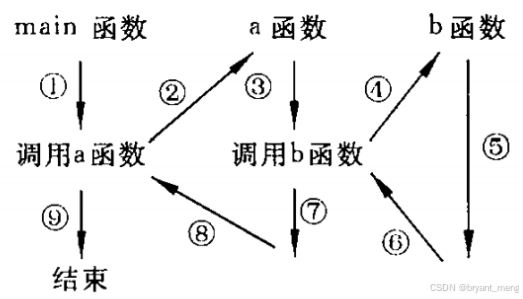
函数的嵌套调用是指在一个函数的执行过程中调用另一个函数。这种机制允许你将复杂的问题分解成更小的、更易于管理的部分。 在嵌套调用中,被调用的函数会先执行完毕,控制权再返回到调用它的函数。
递归是一种特殊的嵌套调用,其中函数直接或间接地调用自身。递归常用于解决可分解为类似子问题的问题,如遍历树结构、排序算法等。
eg:用弦截法求解方程 f ( x ) = x 3 − 5 x 2 + 16 x − 80 = 0 f(x) = x^3 - 5x^2 + 16x - 80 =0 f(x)=x3−5x2+16x−80=0 的根
弦截法
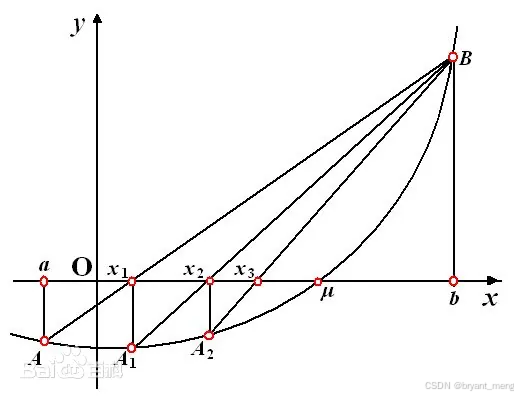
分析方程 f ( x ) = ( x 2 + 16 ) ( x − 5 ) = 0 f(x) = (x^2 + 16)(x-5) = 0 f(x)=(x2+16)(x−5)=0,实数范围内只有唯一解
思路,随机取两个点 x 1 x_1 x1 和 x 2 x_2 x2, f ( x 1 ) f(x_1) f(x1) 和 f ( x 2 ) f(x_2) f(x2) 符号相反的时候表示方程的解介于 x 1 x_1 x1 和 x 2 x_2 x2 之间
我们可以求 f ( x 1 ) f(x_1) f(x1) 和 f ( x 2 ) f(x_2) f(x2) 连线与 X X X 轴的交点 x x x,计算 x x x 处方程的值 f ( x ) f(x) f(x),如果 f ( x 1 ) f(x_1) f(x1) 和 f ( x ) f(x) f(x) 符号相同,表示方程的解不在 x 1 x1 x1 至 x x x 之间,此时可以用 x x x 更新 x 1 x1 x1
如果 f ( x 1 ) f(x_1) f(x1) 和 f ( x ) f(x) f(x) 符号不相同,则表示解介于 f ( x 1 ) f(x_1) f(x1) 和 f ( x ) f(x) f(x) 之间,此时可以用 x x x 更新 x 2 x2 x2
重复上述迭代判断,直到 y ( x ) ≈ 0 y(x) \approx 0 y(x)≈0(编程的时候,小于特别小的值即可,eg:1e-5)
#include <iostream>
#include<math.h>
#include<iomanip> // 指定输出几位小数
using namespace std;
double func(double x) // 实现 f(x)
{
double y = pow(x,3) - 5 * pow(x,2) + 16 * x - 80;
return y;
}
double xpoint(double x1, double x2) // 实现 f(x1) 和 f(x2) 连线与 X 轴的交点横坐标 x
{
double x;
x = (x1 * func(x2) - x2 * func(x1)) / (func(x2) - func(x1));
return x;
}
double root(double x1, double x2) // 迭代缩小 x1 和 x2 的范围,直至求解出 x
{
double x, y, y1;
y1 = func(x1);
do{
x = xpoint(x1, x2);
y = func(x);
if ( y1 * y >0)
{
x1 = x;
y1 = y; // 这里可以省略 y1 = func(x1) 的计算,把其挪到 do-while 循环外
}
else
x2 = x;
}while(fabs(y)>=1e-5);
return x;
}
int main()
{
double x1, x2, x;
do
{
cout << "请输入 x1 和 x2 的值:";
cin >> x1;
cin >> x2;
}while(func(x1) * func(x2) >= 0);
x = root(x1, x2);
cout << setiosflags(ios::fixed) << setprecision(7) << x << endl; // 指定输出 7 位小数
return 0;
}
output
请输入 x1 和 x2 的值:2.5 6.7
4.9999998
root 会嵌套调用 xpoint 和 func,xpoint 和嵌套调用 func
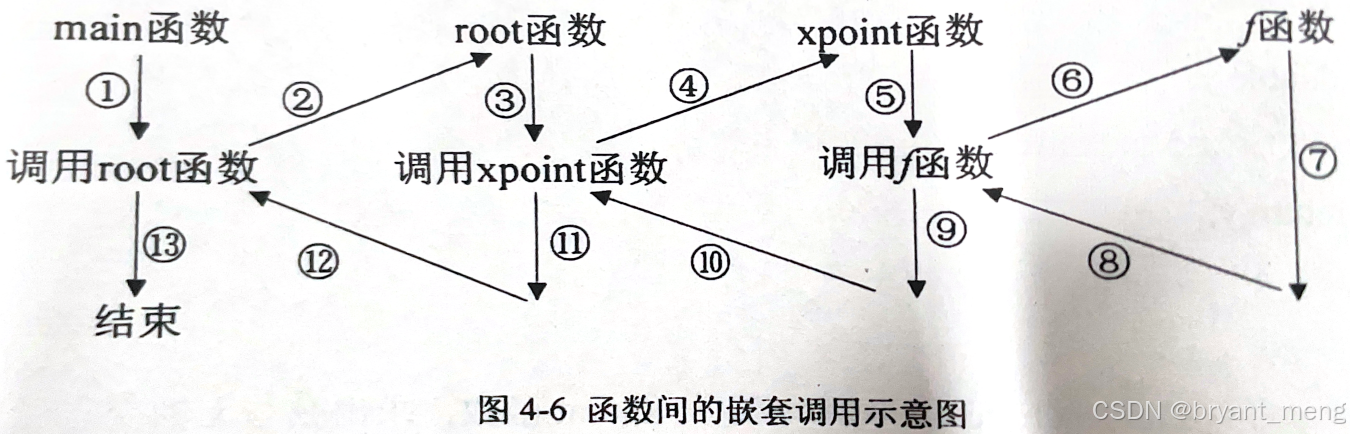
要保证方程的解介于输入的 x 1 x1 x1 和 x 2 x2 x2 之间,所以输入的时候要加判断剔除不合理的输入
root 函数中 y1 = y; 赋值节省了 y1 = func(x1); 重复计算的开销
xpoint 的公式推导如下
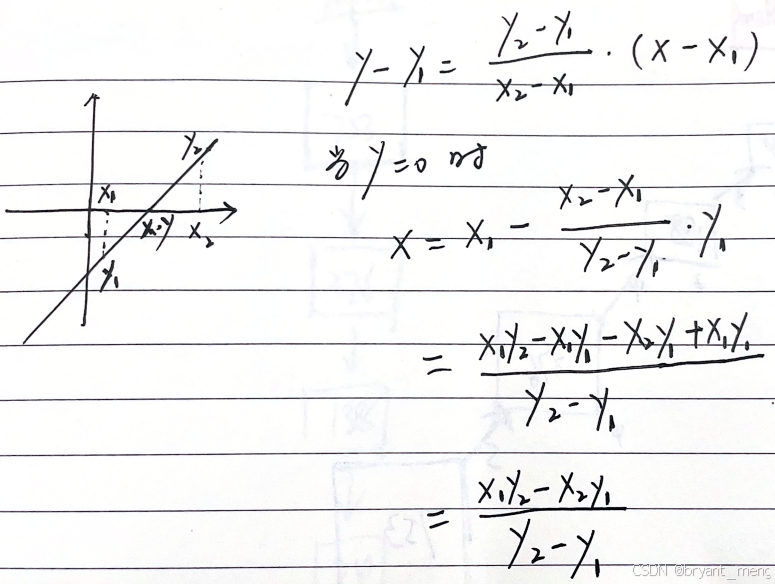
6、递归函数
recursive funciton,直接或间接地调用自身。
递归函数通常用于解决可以分解为相似子问题的问题,如阶乘计算、斐波那契数列生成、树的遍历等。

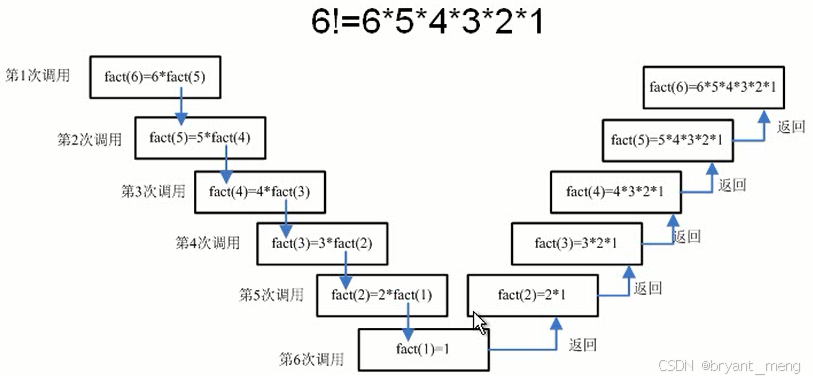
例如计算 6 ! 6! 6!
eg:用递归的方法求阶乘
#include <iostream>
using namespace std;
long fac(int x)
{
long y;
if (x == 1) // 递归终止条件
y = 1;
else
y = x*fac(x-1);
return y;
}
int main()
{
int x, result;
cin >> x;
result = fac(x);
cout << result << endl;
return 0;
}
output
5
120
递归函数的关键在于确保有一个明确的基准条件来终止递归,否则函数将无限调用自身,导致栈溢出错误。
此外,递归函数通常也需要仔细考虑其性能,因为某些递归算法可能非常低效,特别是在处理大数据集时。在可能的情况下,使用迭代算法或优化递归算法(如尾递归优化)可能是一个更好的选择。
7、存储类别
storage class
存储类别指的是数据在内存中存储的方法
- 静态存储
- 动态存储
| 存储类别描述符 | 意义 | 存储方式 |
|---|---|---|
| auto | 自动变量 | 动态存储 |
| register | 寄存器变量 | 动态存储 |
| extern | 外部(全局)变量 | 静态存储 |
| static | 静态变量(局部、全局) | 静态存储 |
7.1、自动变量
使用关键字 auto(通常可以省略)声明的变量。
变量存储在栈中。
生命周期从声明点开始,到包含它的代码块结束时结束。(动态存储)
void func() {
int a = 10; // 自动存储类别,等同于 auto int a = 10;
// ...
} // a 在这里被销毁
7.2、寄存器变量
register variable
使用关键字 register 声明的变量。
提示编译器尽可能将变量存储在CPU寄存器中以提高访问速度。
寄存器数量有限,所以这种声明并不保证变量一定存储在寄存器中。
register int i, sum=0; // 寄存器存储类别,但不保证一定存储在寄存器中
for(i=1; i<=100; i++)
sum += i;
一般情况下变量的值存放在内存中,而在计算机中,对数据进行计算和处理只能在寄存器中进行。因而当对一个变量频繁读写时,势必要反复访问内存。
7.3、用 extern 声明全局变量
使用关键字 extern 声明的变量。
用于声明在其他文件中定义的变量,实现跨文件共享。
变量存储在静态存储区。
生命周期从程序开始到程序结束。
// file1.cpp
int a = 10; // 定义全局变量
// file2.cpp
extern int a; // 声明外部变量,使用 file1.cpp 中定义的 a
作用域
- 文件作用域:若全局变量在普通文件中声明(非在头文件中),则它仅在该文件内部可见。
- 全局作用域:若全局变量在头文件中使用extern关键字声明,并在一个或多个源文件中定义,则它将在包含该头文件的所有文件中可见。
使用场景
- 当需要在多个函数间共享数据时。
- 当数据需要在程序的整个生命周期内保持可用时。
- 当需要实现跨文件的常量或配置参数时(尽管常量通常建议使用const关键字并定义在头文件中)。
7.4、静态变量
static variable
全局静态变量、局部静态变量
局部静态变量
当静态变量在函数或代码块内部声明时,它被称为局部静态变量。以下是其特点:
- 存储期:局部静态变量的存储期与全局变量相同,即从程序启动到程序结束。然而,其作用域仅限于声明它的函数或代码块。退出函数或者语句块后,尽管该变量还继续存在,但是其他程序代码不能直接使用它。不过如果再次进入定义它的函数时,它又可以继续使用,而且保存了上次被调用后留下的值。
- 初始化:局部静态变量仅在程序首次执行到其声明点时进行初始化。之后,即使函数被多次调用,该变量也不会被重新初始化。
- 内存位置:局部静态变量存储在静态存储区,而非栈上。这意味着它们的值在函数调用之间保持不变。
#include <iostream>
using namespace std;
long func(int a)
{
int b=0;
static int c = 3;
b++;
c++;
return a + b + c;
}
int main()
{
int a = 2;
for (int i=0; i<3; i++)
cout<<func(a)<<endl;
return 0;
}
output
7
8
9
全局静态变量
在程序设计中有时候希望某些全局变量仅限于被本文件引用,而不被其它文件引用。这时可以在定义全局变量时加上 static 修饰符,称之为全局静态变量
当静态变量在函数外部或命名空间内声明时,且未使用 extern 关键字,它被称为全局静态变量(或文件作用域静态变量)。
- 作用域:全局静态变量的作用域仅限于声明它的文件。这意味着它不能在其他文件中直接访问,除非通过某种形式的接口(如函数)。
- 链接性:全局静态变量具有内部链接性,这意味着它仅在声明它的文件内部可见。这与普通的全局变量(具有外部链接性,可在多个文件中通过extern访问)形成对比。
- 存储期:与局部静态变量相同,全局静态变量的存储期也是从程序启动到程序结束。
//file1.cpp
static int a = 3; // 只限于 file1.cpp
int main()
{
...
}
//file2.cpp
static int a = 3; // 只限于 file2.cpp
int main()
{
...
}
8、作用域
一个标识符能被使用的程序区间范围称为这个标识符的作用域
- 局部作用域
- 全局作用域
- 函数原型作用域
- 文件作用域
- 类作用域
- 命名空间作用域
(1)局部作用域(Local Scope)
在函数、块(由花括号 {} 包围的代码块)或控制结构(如 if、for、while)内部声明的变量具有局部作用域。
局部变量只能在声明它们的块或结构中访问。
#include <iostream>
using namespace std;
int main()
{ // 块 1
int a = 2;
cout<< a <<endl;
{ // 块 2
cout<< a <<endl;
int a = 3;
cout << a << endl;
}
cout << a << endl;
return 0;
}
output
2
2
3
2
可以看到块2中重新定义了 a,最近嵌套原则
(2)全局作用域(Global Scope)
在所有函数、类和命名空间之外声明的变量和函数具有全局作用域。
全局变量和函数可以在整个程序中访问。
int globalVar = 10;
void globalFunction() {
// 可以访问 globalVar 和其他全局变量/函数
}
(3)函数原型作用域(Function Prototype Scope,形参)
是 C++ 中最小的作用域
在函数原型中声明的参数只在原型中有效。
这种作用域在实际编程中不常用,主要用于在函数声明中避免名称冲突。
void functionWithPrototypeScope(int x) {
// x 的作用域仅限于函数参数列表和函数体
}
(4)文件作用域(File Scope)
在文件顶部(但在任何函数外部)声明的静态变量具有文件作用域。
这些变量只能在该文件内部访问。
static int fileScopeVar = 40; // 仅在声明它的文件中可见
void anotherFunction() {
// 可以访问 fileScopeVar
}
(5)类作用域(Class Scope)
在类内部声明的成员变量和成员函数具有类作用域。
类成员变量和函数可以通过类的对象或类本身(对于静态成员)访问。
class MyClass {
public:
int classVar; // 类成员变量
void classFunction() { // 类成员函数
// 可以访问 classVar 和其他类成员
}
};
(6)命名空间作用域(Namespace Scope)
在命名空间内部声明的变量和函数具有命名空间作用域。
要访问这些变量和函数,需要使用命名空间名或 using 声明。
namespace MyNamespace {
int namespaceVar = 50;
void namespaceFunction() {
// 可以访问 namespaceVar
}
}
int main() {
MyNamespace::namespaceFunction(); // 使用命名空间名访问
using namespace MyNamespace;
namespaceFunction(); // 使用 using 声明后可以直接访问
return 0;
}
eg 4-10,变量的作用域和生存期示例
#include <iostream>
using namespace std;
void a(void);
void b();
void c(int i);
int x = 1;
int main()
{
int x = 5;
cout << "进入 main 函数时局部变量 x(块外) 的值为" << x << endl; // 5
{ // 块
int x = 7;
cout << "main 函数中局部变量 x(块内) 的值为" << x << endl; // 7
}
cout << "main 函数中局部变量 x(块外) 的值为" << x << endl; // 5
a();
b();
c(10);
a();
b();
c(10);
cout << "退出 main 函数前局部变量 x(块外) 的值为" << x << endl; // 5
return 0;
}
void a(void)
{
int x = 25;
cout << "进入 a 函数后局部变量 x 的值为" << x << endl; // 25 25
x++;
cout << "退出 a 函数前局部变量 x 的值为" << x << endl; // 26 26
}
void b()
{
static int x = 50;
cout << "进入 b 函数后静态局部变量 x 的值为" << x << endl; // 50 51
x++;
cout << "退出 b 函数前静态局部变量 x 的值为" << x << endl; // 51 52
}
void c(int i)
{
cout << "进入 c 函数后全局变量 x 的值为" << x << endl; // 1 10
x *= i;
cout << "退出 c 函数前全局变量 x 的值为" << x << endl; // 10 100
}
output
进入 main 函数时局部变量 x(块外) 的值为5
main 函数中局部变量 x(块内) 的值为7
main 函数中局部变量 x(块外) 的值为5
进入 a 函数后局部变量 x 的值为25
退出 a 函数前局部变量 x 的值为26
进入 b 函数后静态局部变量 x 的值为50
退出 b 函数前静态局部变量 x 的值为51
进入 c 函数后全局变量 x 的值为1
退出 c 函数前全局变量 x 的值为10
进入 a 函数后局部变量 x 的值为25
退出 a 函数前局部变量 x 的值为26
进入 b 函数后静态局部变量 x 的值为51
退出 b 函数前静态局部变量 x 的值为52
进入 c 函数后全局变量 x 的值为10
退出 c 函数前全局变量 x 的值为100
退出 main 函数前局部变量 x(块外) 的值为5
9、内部函数和外部函数
根据函数能否被其他源文件调用,将函数分为内部函数和外部函数
9.1、内部函数(局部函数/静态函数)
在 C++ 中,你可以将函数声明为 static,使其在文件内局部可见。这种函数在编译时仅在当前文件内可见,对其他文件不可见。
#include <iostream>
static void staticFunction() {
std::cout << "This is a static function." << std::endl;
}
void externalFunction() {
staticFunction(); // Can call static function from the same file
}
int main() {
externalFunction();
staticFunction();
return 0;
}
output
This is a static function.
This is a static function.
9.2、外部函数
全局函数是在文件或命名空间范围内声明的函数,它们在编译后对整个程序可见(除非受到访问控制如类的私有成员限制)。
2.cpp
#include <iostream>
int mymax(int x, int y)
{
return x>y?x:y;
}
1.cpp
#include <iostream>
#include "2.cpp"
using namespace std;
int main() {
extern int mymax(int, int); // 声明
int x = 3, y = 4;
cout << mymax(x, y) << endl;
return 0;
}
output
4
在上面的例子中,mymax 在2.cpp中定义,并在1.cpp中通过 extern 关键字声明,然后在main函数中调用。
如果定义函数时省略 extern,则默认为外部函数。
下述两个函数声明没有明显区别
extern int fun(int, int); 和 int fun(int, int); 没有明显区别
10、预处理指令
preprocessor directives
C++ 预处理命令是编译器在编译程序之前执行的一系列指令。这些指令用于文本替换、条件编译、文件包含等操作。
预处理发生在编译之前
经过预处理后程序不再包括预处理指令了,最后再由编译器对预处理后的源程序进行编译处理,得到可供执行的目标代码
以#开头,不含分号
10.1、#include 指令
#include:用于包含(或插入)另一个文件的内容。
#include <filename>:包含标准库文件。会去环境变量指定的目录中寻找#include "filename":包含用户自定义文件。源文件所在位置查找
#include <iostream>
#include "myheader.h"
#include "C:\demo\C++\myheader.h" // 也可以用绝对路径
10.2、#define、#undef 指令
用于定义符号常量和带参数的宏
- 定义常量:
#define PI 3.14159 - 定义代码块(宏函数):
#define SQUARE(x) ((x) * (x))
#define MAX_SIZE 100
#define SWAP(a, b) { int temp = a; a = b; b = temp; }
看看下面的例子
#include <iostream>
using namespace std;
#define S(a,b) (a)*(b)
#define B(a,b) a*b
int main() {
cout << S(1+2, 2+3) << endl; // (1+2)*(2+3) = 15
cout << B(1+2, 2+3); // 1+2*2+3 = 8
return 0;
}
output
15
8
上面的例子可以看出定义宏函数的时候,括号很重要
#undef:用于取消之前定义的宏。
eg
#undef MAX_SIZE
10.3、#if、#else、#elif、#endif
用于条件编译
有时候希望程序中某一部分内容只在满足一定条件下才进行编译,这就是“条件编译”
商业软件广泛应用条件编译来提供和维护某一程序的许多定制版本。
#if:如果条件为真,则编译包含的代码。
#elif:如果前面的条件为假且当前条件为真,则编译包含的代码。
#else:如果前面的所有条件都为假,则编译包含的代码。
#endif:结束条件编译块。
eg:
#include <iostream>
using namespace std;
#define MAXVALUE 99
#define PRINT 1
int main() {
#if MAXVALUE>100
cout << "Too Big" << std::endl;
#elif MAXVALUE>80
cout << "Great" << std::endl;
#else
cout << "Too Small" << std::endl;
#endif
return 0;
}
output
Great
10.4、#ifdef、#ifndef
#ifdef:如果宏已定义,则编译包含的代码。
#ifndef:如果宏未定义,则编译包含的代码。
eg
#include <iostream>
using namespace std;
#define LOG 1
int main() {
#if LOG
cout << "Write Log" << endl;
#endif
#ifndef PRINT
cout << "Not Print" << endl;
#endif
return 0;
}
output
Write Log
Not Print
10.5、其他的指令
#line:用于改变当前行号和文件名,通常用于生成代码的工具中。
#line 100 "newfile.cpp"
#error:用于生成编译错误消息。
#if __cplusplus < 201103L
#error "This code requires C++11 or later"
#endif
11、应用实例
eg 4-12,求解 300~400范围内所有素数
基于 eg 3-11,封装成了函数而已(【C++】 Flow of Control)
#include <iostream>
#include<math.h>
using namespace std;
bool isPrime(int x)
{
if(x <=1)
return false;
int i,b;
b = sqrt(x);
for (i=2; i<=b; i++)
{
if (x % i == 0)
break;
}
if (i>=b+1)
return true;
else
return false;
}
int main()
{
for (int x=301; x < 400; x+=2)
{
if (isPrime(x))
cout << x << " ";
}
return 0;
}
output
307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397
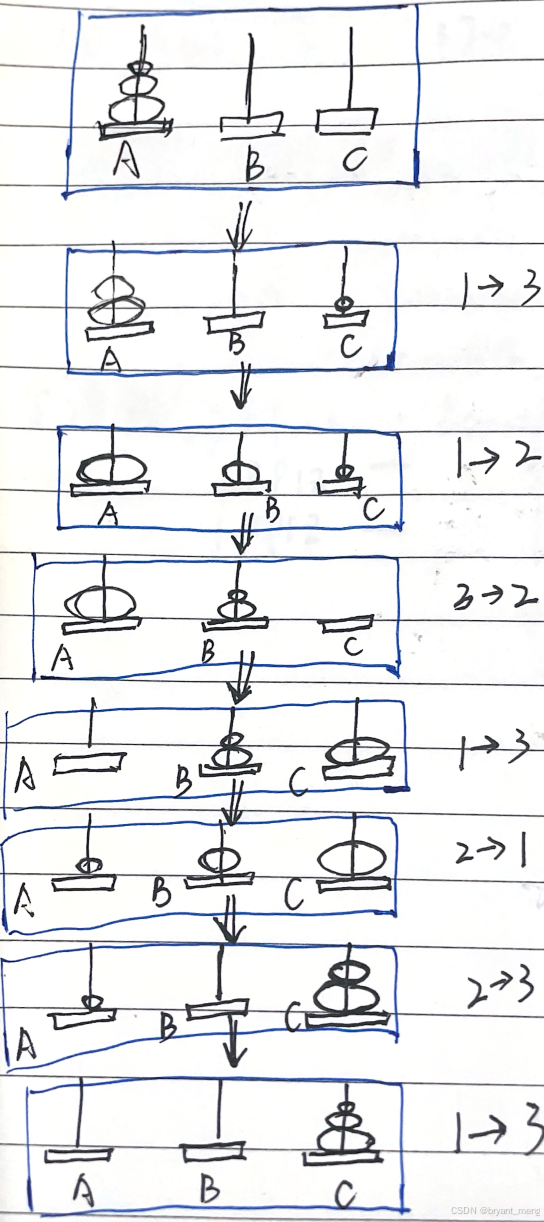
eg 4-13,汉诺塔问题,A、B、C 三根柱子,A 柱 N 个盘子(大的在下,小的在上)移到 C 柱
思路:递归
- N-1 从 A 移动到 B,借助 C
- 最大盘从A 移动到 C
- N-1 从 B 移动到 C,借助 A
可以发现规模从移动 N 个盘子变成移动 N-1 个盘子
#include <iostream>
using namespace std;
void move(int num, char src, char mid, char tgt)
{
if(num==1)
{
cout<<src<<"->"<<tgt<<endl;
}
else
{
move(num-1, src, tgt, mid);
cout<<src<<"->"<<tgt<<endl;
move(num-1, mid, src, tgt);
}
}
int main()
{
move(3, '1', '2', '3');
return 0;
}
output
1->3
1->2
3->2
1->3
2->1
2->3
1->3
附录——内存和寄存器的关系
一、定义与功能
内存:
- 内存是计算机中用于存储数据和指令的主要部件之一。
- 它由大量的内存单元组成,每个内存单元用于存放一个数据项(如一个字节)。
- 内存的容量相对较大,可以存储大量的数据和程序。
寄存器:
- 寄存器是CPU内部的小型存储区域,用于暂时存放参与运算的数据和运算结果。
- 它包括通用寄存器、专用寄存器和控制寄存器等类型。
- 寄存器的存储容量有限,但读写速度非常快,因为它直接连接到CPU的内部总线。
二、存储位置与访问速度
存储位置:
- 内存位于CPU外部,通过内存总线与CPU相连。
- 寄存器则位于CPU内部,是CPU的组成部分。
访问速度:
- 由于寄存器直接连接到CPU的内部总线,因此CPU访问寄存器的速度非常快。
- 相比之下,内存虽然容量大,但CPU访问内存的速度相对较慢,因为需要通过内存总线进行数据传输。
三、数据交换与工作流程
- 当CPU需要处理数据时,它通常会先从内存中读取数据到寄存器中,然后在寄存器中进行运算和处理。
- 运算完成后,CPU再将结果写回内存或寄存器中存储起来。
- 这种数据交换机制使得CPU能够高效地处理数据,同时充分利用内存的大容量存储能力。
四、相互关系与影响
相互依赖:
- 内存和寄存器相互依赖,共同支持计算机系统的正常运行。
- 内存提供大容量存储能力,而寄存器则提供高速数据处理能力。
性能影响:
- 寄存器的数量和速度对CPU的性能有重要影响。更多的寄存器和更快的访问速度可以显著提高CPU的数据处理能力。
- 内存的容量和访问速度也对系统的整体性能产生影响。更大的内存容量和更快的访问速度可以支持更大的程序和更复杂的数据处理任务。