本文用于对DCLGAN网络进行代码对照讲解,仍是新手,如有错误,请指正
论文地址:https://arxiv.org/abs/2104.07689
代码地址:https://github.com/JunlinHan/DCLGAN
DCLGAN 介绍
一种基于对比学习(contrastive learning)和双学习设置(dual learning setting)的新方法,用于无监督的图像到图像翻译任务。这种方法被称为DCLGAN(Dual Contrastive Learning for Unsupervised Image-to-Image Translation)
方法:对比学习;双GAN,
任务:图像翻译,
优势:非对称,对比学习来最大化输入和输出图像块之间的互信息,两个不同的编码器(encoders)来学习不同域的特征
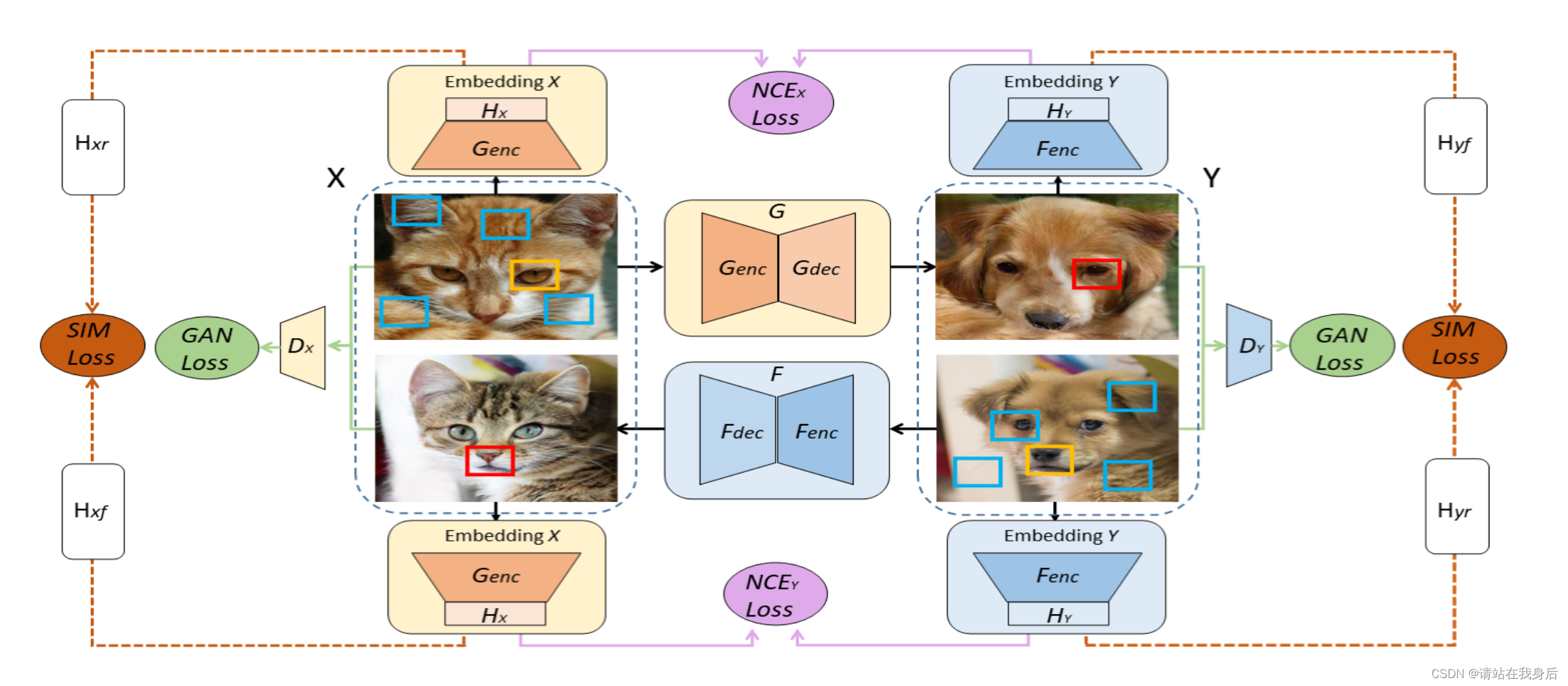
G:X->Y 任务 ;F:Y->X 任务
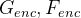
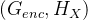
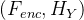
GAN损失:绿线 ;基于patch的多NCE损失 :紫线 ;相似度损失:橙线
任务很简单:real A-> fake B; real B ->fake A
损失有三个
1、GAN loss(绿):loss(real A,fakeA) 常规GAN损失,调整生成器的
2、PatchNCE loss(紫):loss(patch(realA),patch(fake B)),让红框和黄框越像越好,篮框越不像越好
3、sim loss (橙):loss(sim(real A),sim(fake A)) ,sim 用来提取领域的特征,用来学习领域相似性的,这个是simDCL的改进
是不是蛮简单的,咱们看代码。
代码对照讲解
因为至少讲网络,训练部分大部分就带过去了,如果有不懂的可以留言
看代码的顺序是根据个人习惯来的,仍是菜鸟,请见谅
官方代码给出了一种比较完善的网络封装框架,与其直接去解读不如从train 入手
dataset
from data import create_dataset
dataset = create_dataset(opt)初始化给出了这个函数
def create_dataset(opt):
data_loader = CustomDatasetDataLoader(opt)
dataset = data_loader.load_data()
return dataset继续看下去,CustomDatasetDataLoader函数里面初始化给出了dataset 和dataloader:
class CustomDatasetDataLoader():
def __init__(self, opt):
self.opt = opt
dataset_class = find_dataset_using_name(opt.dataset_mode)
self.dataset = dataset_class(opt)
self.dataloader = torch.utils.data.DataLoader(
self.dataset,
batch_size=opt.batch_size,
shuffle=not opt.serial_batches,
num_workers=int(opt.num_threads),
drop_last=True if opt.isTrain else False,
)find_dataset_using_name(opt.dataset_mode)是base里面根据数据集名字寻找dataset构建方法的一个中转站,导入“data/[dataset_name]_dataset.py”模块,比如默认的是“unaligned”(你可以在base_options ctil+f 查找参数名),就定位到 data/unaligned_dataset.py这个dataset 文件。
def find_dataset_using_name(dataset_name):
dataset_filename = "data." + dataset_name + "_dataset"
datasetlib = importlib.import_module(dataset_filename)
dataset = None
target_dataset_name = dataset_name.replace('_', '') + 'dataset'
for name, cls in datasetlib.__dict__.items():
if name.lower() == target_dataset_name.lower() \
and issubclass(cls, BaseDataset):
dataset = cls
return datasetunaligned_dataset的数据集类可以加载未对齐/未配对的数据集。
它需要两个目录分别存放域A和域B的训练图像,如果你要训练自己数据集,首先要做的,也是照着他的数据集给是进行修改。
class UnalignedDataset(BaseDataset):
首先,初始化给出了文件的路径:
def __init__(self, opt):
"""Initialize this dataset class.
Parameters:
opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
BaseDataset.__init__(self, opt)
self.dir_A = os.path.join(opt.dataroot, opt.phase + 'A') # create a path '/path/to/data/trainA'
self.dir_B = os.path.join(opt.dataroot, opt.phase + 'B') # create a path '/path/to/data/trainB'
if opt.phase == "test" and not os.path.exists(self.dir_A) \
and os.path.exists(os.path.join(opt.dataroot, "valA")):
self.dir_A = os.path.join(opt.dataroot, "valA")
self.dir_B = os.path.join(opt.dataroot, "valB")
self.A_paths = sorted(make_dataset(self.dir_A, opt.max_dataset_size)) # load images from '/path/to/data/trainA'
self.B_paths = sorted(make_dataset(self.dir_B, opt.max_dataset_size)) # load images from '/path/to/data/trainB'
self.A_size = len(self.A_paths) # get the size of dataset A
self.B_size = len(self.B_paths) # get the size of dataset B接下来主要看如何取数据的,
def __getitem__(self, index):图片直接读取进来,保存为RGB格式,如果B类图片数量比A少,那就要注意下标
A_path = self.A_paths[index % self.A_size] # make sure index is within then range
if self.opt.serial_batches: # make sure index is within then range
index_B = index % self.B_size
else: # randomize the index for domain B to avoid fixed pairs.
index_B = random.randint(0, self.B_size - 1)
B_path = self.B_paths[index_B]
A_img = Image.open(A_path).convert('RGB')
B_img = Image.open(B_path).convert('RGB')应用图像变换,如果是在微调,不需要变换
modified_opt = util.copyconf(self.opt, load_size=self.opt.crop_size if is_finetuning else self.opt.load_size)
transform = get_transform(modified_opt)
A = transform(A_img)
B = transform(B_img)
主要有裁剪等操作,参数可以在option调整:
parser.add_argument('--crop_size', type=int, default=256, help='then crop to this size')
返回的是一个字典,里面包括 A领域图像,B领域图像,和各自路径
return {'A': A, 'B': B, 'A_paths': A_path, 'B_paths': B_path}
model
重头戏来了,数据集没啥特殊,自己建就行,看看model部分
from models import create_model
model = create_model(opt)def create_model(opt):
model = find_model_using_name(opt.model)
instance = model(opt)
print("model [%s] was created" % type(instance).__name__)
return instancedef find_model_using_name(model_name):
model_filename = "models." + model_name + "_model"
modellib = importlib.import_module(model_filename)
model = None
target_model_name = model_name.replace('_', '') + 'model'
for name, cls in modellib.__dict__.items():
if name.lower() == target_model_name.lower() \
and issubclass(cls, BaseModel):
model = cls
return model跟dataset 同理,不赘述了,直接跳到 网络里,以simDCL举例,simdcl_model.py 举例
要直接看原网络,会发现有些看不懂,因为写法不一样,还是看回train,我只复制主要的网络部分啦。
for epoch in range(opt.epoch_count, opt.n_epochs + opt.n_epochs_decay + 1):
for i, data in enumerate(dataset):
if epoch == opt.epoch_count and i == 0:
model.data_dependent_initialize(data)
model.setup(opt) # regular setup: load and print networks; create schedulers
model.parallelize()
model.set_input(data) # unpack data from dataset and apply preprocessing
model.optimize_parameters() # calculate loss functions, get gradients, update network weights首先万物开始的data_dependent_initialize,见simdcl_model.py,特征网络netF是根据netG的编码器部分的中间提取特征的形状来定义的。因此,netF的权重在第一次前馈传递时初始化一些输入图像。
因为网络一个循环的结构,所以要构建一个圆,必须要有起点,这个函数里面便可以理解为是第一个forward,但是咱们先不看这个,后面的流程跟这个一样。
def set_input(self, input):
AtoB = self.opt.direction == 'AtoB'
self.real_A = input['A' if AtoB else 'B'].to(self.device)
self.real_B = input['B' if AtoB else 'A'].to(self.device)set_input,加载数据到class 中,方向是A 2B ,简单易懂
接下来是训练部分,也就是优化环节 !!
def optimize_parameters(self):
# forward
self.forward()
# update D
self.set_requires_grad([self.netD_A, self.netD_B], True)
self.optimizer_D.zero_grad()
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B() # calculate graidents for D_B
self.optimizer_D.step()
# update G
self.set_requires_grad([self.netD_A, self.netD_B], False)
self.optimizer_G.zero_grad()
if self.opt.netF == 'mlp_sample':
self.optimizer_F.zero_grad()
self.loss_G = self.compute_G_loss()
self.loss_G.backward()
self.optimizer_G.step()
if self.opt.netF == 'mlp_sample':
self.optimizer_F.step()一开始就是forward, 在model 内部进行计算,
def forward(self):
"""Run forward pass; called by both functions <optimize_parameters> and <test>."""
self.fake_B = self.netG_A(self.real_A) # G_A(A)
self.fake_A = self.netG_B(self.real_B) # G_B(B)
if self.opt.nce_idt:
self.idt_A = self.netG_A(self.real_B)
self.idt_B = self.netG_B(self.real_A)可以看到,只用到了两个网络,其实只用到了一种生成器,看向netG
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.normG,
not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias,
opt.no_antialias_up, self.gpu_ids, opt)前两个参数很简单,输入输出尺度
第三个第四个参数,代表着生成器使用的网络,归一化等参数,我找找
parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in the last conv layer')
parser.add_argument('--netG', type=str, default='resnet_9blocks', choices=['resnet_9blocks', 'resnet_6blocks', 'unet_256', 'unet_128', 'stylegan2', 'smallstylegan2', 'resnet_cat'], help='specify generator architecture')
parser.add_argument('--normG', type=str, default='instance', choices=['instance', 'batch', 'none'], help='instance normalization or batch normalization for G')使用的网络是resnet,残差网络,看向define_G()函数中
if netG == 'resnet_9blocks':
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, no_antialias=no_antialias, no_antialias_up=no_antialias_up, n_blocks=9, opt=opt)
千辛万苦,终于找到了使用的网络了
直接从 ResnetGenerator的forward 开始看
def forward(self, input, layers=[], encode_only=False):
if -1 in layers:
layers.append(len(self.model))
if len(layers) > 0:
feat = input
feats = []
for layer_id, layer in enumerate(self.model):
# print(layer_id, layer)
feat = layer(feat)
if layer_id in layers:
# print("%d: adding the output of %s %d" % (layer_id, layer.__class__.__name__, feat.size(1)))
feats.append(feat)
else:
# print("%d: skipping %s %d" % (layer_id, layer.__class__.__name__, feat.size(1)))
pass
if layer_id == layers[-1] and encode_only:
# print('encoder only return features')
return feats # return intermediate features alone; stop in the last layers
return feat, feats # return both output and intermediate features
else:
"""Standard forward"""
fake = self.model(input)
return fake很经典的残差结构,关注一个bolck块就行,也就是看一个layer 是怎么运行的,看向
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6, padding_type='reflect', no_antialias=False, no_antialias_up=False, opt=None):
model = [nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),
norm_layer(ngf),
nn.ReLU(True)]
可以看到,model中首先获得了一个卷积模块,
添加下采样层,两层
n_downsampling = 2
for i in range(n_downsampling): # add downsampling layers
mult = 2 ** i
if(no_antialias):
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),
norm_layer(ngf * mult * 2),
nn.ReLU(True)]
else:
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=1, padding=1, bias=use_bias),
norm_layer(ngf * mult * 2),
nn.ReLU(True),
Downsample(ngf * mult * 2)]添加残差层
mult = 2 ** n_downsampling
for i in range(n_blocks): # add ResNet blocks
model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
然后上采用回来,顺便激活一下
for i in range(n_downsampling): # add upsampling layers
mult = 2 ** (n_downsampling - i)
if no_antialias_up:
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=2,
padding=1, output_padding=1,
bias=use_bias),
norm_layer(int(ngf * mult / 2)),
nn.ReLU(True)]
else:
model += [Upsample(ngf * mult),
nn.Conv2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=1,
padding=1, # output_padding=1,
bias=use_bias),
norm_layer(int(ngf * mult / 2)),
nn.ReLU(True)]
model += [nn.ReflectionPad2d(3)]
model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
model += [nn.Tanh()]
self.model = nn.Sequential(*model)一个残差网络就结束啦,simdcl forward完美结束
获得了 fake B ,和fake A
loss
接下俩就是损失了
def optimize_parameters 大家还记得吗,第一步是forward的哪个,下一步进行辨别器的优化,也就是传统的GAN损失
# update D
self.set_requires_grad([self.netD_A, self.netD_B], True)
self.optimizer_D.zero_grad()
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B() # calculate graidents for D_B
self.optimizer_D.step() def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
fake_A = self.fake_A_pool.query(self.fake_A)
self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)那么损失是怎么计算的呢,看这个函数,跟上面流程一样,我就不一步步讲了
def backward_D_basic(self, netD, real, fake):
# Real
pred_real = netD(real)
loss_D_real = self.criterionGAN(pred_real, True)
# Fake
pred_fake = netD(fake.detach())
loss_D_fake = self.criterionGAN(pred_fake, False)
# Combined loss and calculate gradients
loss_D = (loss_D_real + loss_D_fake) * 0.5
loss_D.backward()
return loss_D
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device)
parser.add_argument('--gan_mode', type=str, default='hinge', help='the type of GAN objective. [vanilla| lsgan | wgangp| hinge]. vanilla GAN loss is the cross-entropy objective used in the original GAN paper.')
默认使用的hinge哦
elif self.gan_mode == 'hinge':
if target_is_real:
minvalue = torch.min(prediction - 1, torch.zeros(prediction.shape).to(prediction.device))
loss = -torch.mean(minvalue)
else:
minvalue = torch.min(-prediction - 1,torch.zeros(prediction.shape).to(prediction.device))
loss = -torch.mean(minvalue)
return loss大家可以了解下hinge损失,也可以使用其他几个哦
ok,知道了两个辨别器器损失,然后平均一下就得到了整体的辨别器损失
赶紧back
然后看第二个损失
self.loss_G = self.compute_G_loss()
def compute_G_loss(self):
"""Calculate GAN and NCE loss for the generator"""
fakeB = self.fake_B
fakeA = self.fake_A
# First, G(A) should fake the discriminator
if self.opt.lambda_GAN > 0.0:
pred_fakeB = self.netD_A(fakeB)
pred_fakeA = self.netD_B(fakeA)
self.loss_G_A = self.criterionGAN(pred_fakeB, True).mean() * self.opt.lambda_GAN
self.loss_G_B = self.criterionGAN(pred_fakeA, True).mean() * self.opt.lambda_GAN
else:
self.loss_G_A = 0.0
self.loss_G_B = 0.0
# L1 IDENTICAL LOSS
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B)
self.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A)
# Similarity Loss and NCE losses
self.loss_Sim, self.loss_NCE1, self.loss_NCE2 = self.calculate_Sim_loss_all \
(self.real_A, self.fake_B, self.real_B, self.fake_A)
loss_NCE_both = (self.loss_NCE1 + self.loss_NCE2) * 0.5 + (self.loss_idt_A + self.loss_idt_B) * 0.5 \
+ self.loss_Sim
self.loss_G = (self.loss_G_A + self.loss_G_B) * 0.5 + loss_NCE_both
return self.loss_G计算生成器的GAN和NCE损失
里面主要的不同有一个计算L1 IDENTICAL LOSS和计算相似性损失,前者就是一个简单的l1,后者如下:
def calculate_Sim_loss_all(self, src1, tgt1, src2, tgt2):
n_layers = len(self.nce_layers)
feat_q1 = self.netG_B(tgt1, self.nce_layers, encode_only=True)
feat_k1 = self.netG_A(src1, self.nce_layers, encode_only=True)
feat_q2 = self.netG_A(tgt2, self.nce_layers, encode_only=True)
feat_k2 = self.netG_B(src2, self.nce_layers, encode_only=True)
feat_k_pool1, sample_ids1 = self.netF1(feat_k1, self.opt.num_patches, None)
feat_q_pool1, _ = self.netF2(feat_q1, self.opt.num_patches, sample_ids1)
feat_q_pool1_noid, _ = self.netF2(feat_q1, self.opt.num_patches, None)
feat_k_pool2, sample_ids2 = self.netF2(feat_k2, self.opt.num_patches, None)
feat_q_pool2, _ = self.netF1(feat_q2, self.opt.num_patches, sample_ids2)
feat_q_pool2_noid, _ = self.netF1(feat_q2, self.opt.num_patches, None)
nce_loss1 = 0.0
for f_q, f_k, crit in zip(feat_q_pool1, feat_k_pool1, self.criterionNCE):
loss = crit(f_q, f_k)
nce_loss1 += loss.mean()
nce_loss2 = 0.0
for f_q, f_k, crit in zip(feat_q_pool2, feat_k_pool2, self.criterionNCE):
loss = crit(f_q, f_k)
nce_loss2 += loss.mean()
m, n = self.opt.num_patches, self.opt.netF_nc
nce_loss1 = nce_loss1 / n_layers
nce_loss2 = nce_loss2 / n_layers
feature_realA = torch.zeros([n_layers, m, n])
feature_fakeB = torch.zeros([n_layers, m, n])
feature_realB = torch.zeros([n_layers, m, n])
feature_fakeA = torch.zeros([n_layers, m, n])
for i in range(n_layers):
feature_realA[i] = feat_k_pool1[i]
feature_fakeB[i] = feat_q_pool1_noid[i]
feature_realB[i] = feat_k_pool2[i]
feature_fakeA[i] = feat_q_pool2_noid[i]
feature_realA_out = self.netF3(feature_realA.to(self.device))
feature_fakeB_out = self.netF4(feature_fakeB.to(self.device))
feature_realB_out = self.netF5(feature_realB.to(self.device))
feature_fakeA_out = self.netF6(feature_fakeA.to(self.device))
sim_loss = self.criterionSim(feature_realA_out, feature_fakeA_out) + \
self.criterionSim(feature_fakeB_out, feature_realB_out)
return sim_loss * self.opt.lambda_SIM, nce_loss1, nce_loss2 self.netF1 = networks.define_F(opt.input_nc, opt.netF, opt.normG,
not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids,
opt)
self.netF2 = networks.define_F(opt.input_nc, opt.netF, opt.normG,
not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids,
opt)
n_layers = len(self.nce_layers)
self.netF3 = networks.define_F(n_layers, 'mapping', opt.normG,
not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids,
opt)
self.netF4 = networks.define_F(n_layers, 'mapping', opt.normG,
not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids,
opt)
self.netF5 = networks.define_F(n_layers, 'mapping', opt.normG,
not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids,
opt)
self.netF6 = networks.define_F(n_layers, 'mapping', opt.normG,
not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids,
opt)def define_F(input_nc, netF, norm='batch', use_dropout=False, init_type='normal', init_gain=0.02, no_antialias=False, gpu_ids=[], opt=None):
if netF == 'global_pool':
net = PoolingF()
elif netF == 'reshape':
net = ReshapeF()
elif netF == 'mapping':
net = MappingF(input_nc, gpu_ids=gpu_ids)
elif netF == 'sample':
net = PatchSampleF(use_mlp=False, init_type=init_type, init_gain=init_gain, gpu_ids=gpu_ids, nc=opt.netF_nc)
elif netF == 'mlp_sample':
net = PatchSampleF(use_mlp=True, init_type=init_type, init_gain=init_gain, gpu_ids=gpu_ids, nc=opt.netF_nc)
elif netF == 'strided_conv':
net = StridedConvF(init_type=init_type, init_gain=init_gain, gpu_ids=gpu_ids)
else:
raise NotImplementedError('projection model name [%s] is not recognized' % netF)
return init_net(net, init_type, init_gain, gpu_ids)
class ReshapeF(nn.Module):
def __init__(self):
super(ReshapeF, self).__init__()
model = [nn.AdaptiveAvgPool2d(4)]
self.model = nn.Sequential(*model)
self.l2norm = Normalize(2)
def forward(self, x):
x = self.model(x)
x_reshape = x.permute(0, 2, 3, 1).flatten(0, 2)
return self.l2norm(x_reshape)简单描述下这一段的意义,就是通过池化和转换维度,使得领域之间的特征映射出来,然后对各个领域的特征进行l1 loss
然后将idt 和sim 损失合在一起作为NCE损失再加上生成器损失获得了整体的生成器损失
loss_NCE_both = (self.loss_NCE1 + self.loss_NCE2) * 0.5 + (self.loss_idt_A + self.loss_idt_B) * 0.5 \
+ self.loss_Sim
self.loss_G = (self.loss_G_A + self.loss_G_B) * 0.5 + loss_NCE_bothbackwardbackwardbackward
就此终于结束了
损失部分大家可以继续看看,三个损失对应着生成器的三个损失,loss_G_A/B,loss_NCE,loss_Sim