一、InfluxDB 简介
InfluxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。
类似的数据库有Elasticsearch、Graphite等。
其主要特色功能
1)基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等)
2)可度量性:你可以实时对大量数据进行计算
3)基于事件:它支持任意的事件数据
InfluxDB的主要特点
1)无结构(无模式):可以是任意数量的列
2)可拓展的
3)支持min, max, sum, count, mean, median 等一系列函数,方便统计
4)原生的HTTP支持,内置HTTP API
5)强大的类SQL语法
6)自带管理界面,方便使用
自带管理界面:
Docker Image
docker pull influxdb
OS X (via Homebrew)
brew update brew install influxdb MD5: 4f0aa76fee22cf4c18e2a0779ba4f462
RedHat & CentOS (64-bit)
wget https://dl.influxdata.com/influxdb/releases/influxdb-0.13.0.x86_64.rpm sudo yum localinstall influxdb-0.13.0.x86_64.rpm MD5: 286b6c18aa4ef37225ea6605a729b61d在实际安装过程中,只需要选好对应的版本,然后按照 命令 执行就可以了。
三、InfluxDB启动
1)服务端启动
如果是通过包安装的,可以使用如下语句启动:
sudo service influxdb start
如果直接下载的二进制包,则通过如下方式启动
进入InfluxDB目录下的usr/bin文件夹,执行:
./influxd
即可。
这样就启动了服务端。
2)客户端
在usr/bin里使用influx即可登入Influx服务器。也可以将路径加入环境变量中,这样既可在任意地方使用influx。
InfluxDB自带web管理界面,在浏览器中输入 http://服务器IP:8083 即可进入web管理页面。
四、InfluxDB的基本概念
InfluxDB与传统数据库在概念上有许多的不同
一、与传统数据库中的名词做比较
| influxDB中的名词 | 传统数据库中的概念 |
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
二、InfluxDB中独有的概念
1)Point
Point由时间戳(time)、数据(field)、标签(tags)组成。
Point相当于传统数据库里的一行数据,如下表所示:
| Point属性 | 传统数据库中的概念 |
| time | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields | 各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 |
| tags | 各种有索引的属性:地区,海拔 |
2)series
所有在数据库中的数据,都需要通过图表来展示,而这个series表示这个表里面的数据,可以在图表上画成几条线:通过tags排列组合算出来。
如下所示:
>show series from cpu key cpu,cpu=cpu-total,host=ResourcePool-0246-billing07 cpu,cpu=cpu-total,host=billing07 cpu,cpu=cpu0,host=ResourcePool-0246-billing07 cpu,cpu=cpu0,host=billing07 cpu,cpu=cpu1,host=ResourcePool-0246-billing07 cpu,cpu=cpu1,host=billing07 cpu,cpu=cpu10,host=ResourcePool-0246-billing07 cpu,cpu=cpu10,host=billing07 cpu,cpu=cpu11,host=ResourcePool-0246-billing07 cpu,cpu=cpu11,host=billing07 cpu,cpu=cpu12,host=ResourcePool-0246-billing07 cpu,cpu=cpu12,host=billing07 cpu,cpu=cpu13,host=ResourcePool-0246-billing07 cpu,cpu=cpu13,host=billing07 cpu,cpu=cpu14,host=ResourcePool-0246-billing07 cpu,cpu=cpu14,host=billing07 cpu,cpu=cpu15,host=ResourcePool-0246-billing07
InfluxDB学习之InfluxDB的基本操作
一、InfluxDB操作方式
InfluxDB提供三种操作方式:
1)客户端命令行方式
2)HTTP API接口
3)各语言API库
今天主要以命令行为例,为大家介绍下InfluxDB的基本操作,HTTP API接口和各种语言API库会在以后的文章中为大家详细介绍。
二、InfluxDB数据库操作
如同MYSQL一样,InfluxDB提供多数据库支持,对数据库的操作也与MYSQL相同。
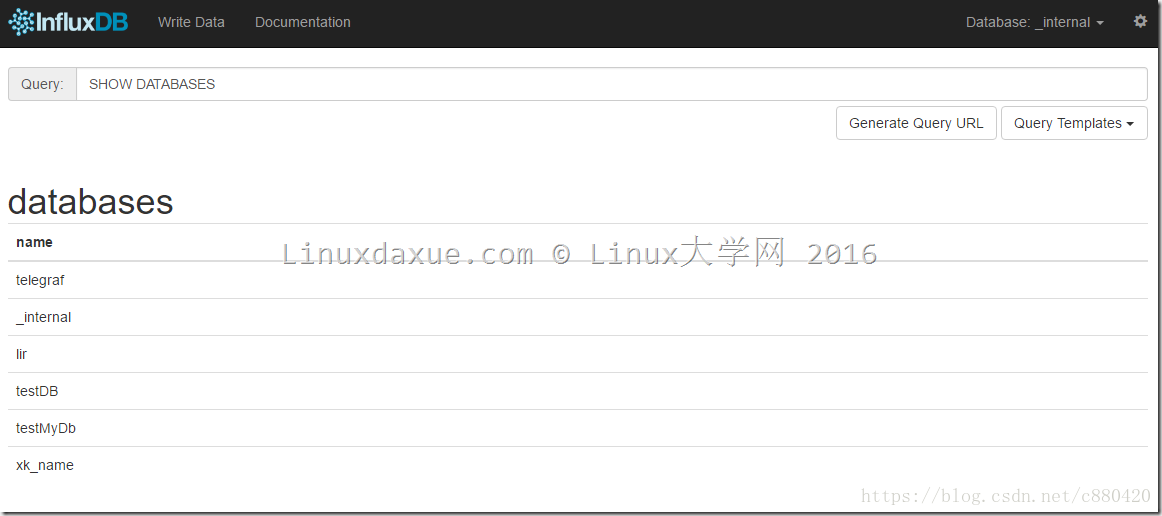
1)显示数据库:
> show databases name: databases --------------- name telegraf _internal lir testDB testMyDb
2)新建数据库:
> create database test > show databases name: databases --------------- name telegraf _internal lir testDB testMyDb xk_name test
3)删除数据库
> drop database test > show databases name: databases --------------- name telegraf _internal lir testDB testMyDb xk_name
4)使用某个数据库
> use xk_name Using database xk_name
三、InfluxDB数据表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是MEASUREMENTS,MEASUREMENTS的功能与传统数据库中的表一致,因此我们也可以将MEASUREMENTS称为InfluxDB中的表。
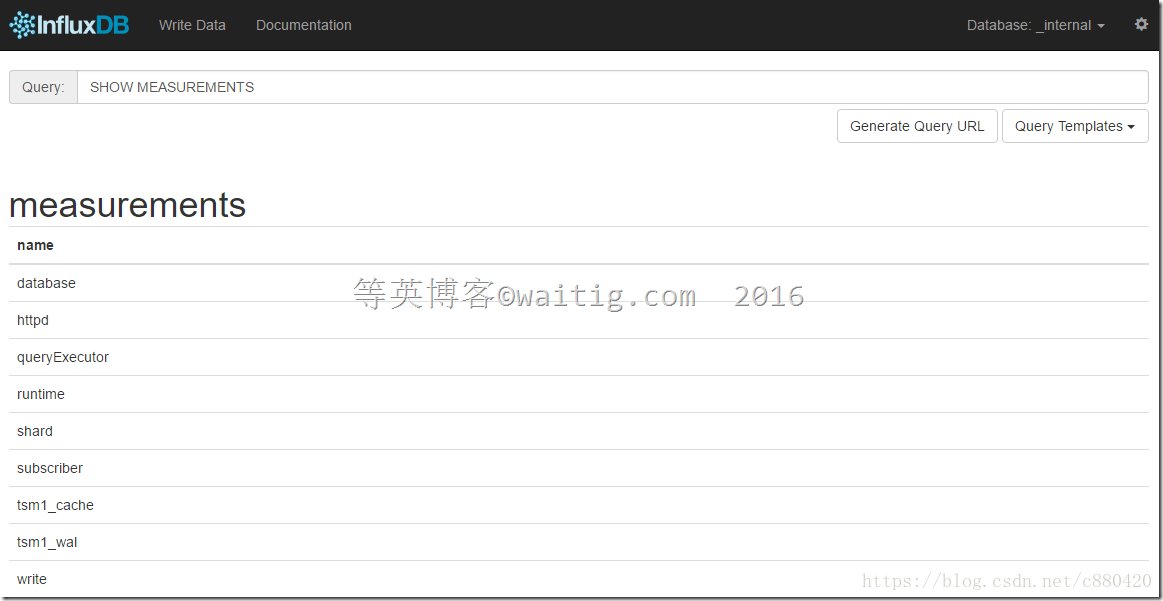
1)显示所有表
> SHOW MEASUREMENTS name: measurements ------------------ name weather
2)新建表
InfluxDB中没有显式的新建表的语句,只能通过insert数据的方式来建立新表。如下所示:
insert disk_free,hostname=server01 value=442221834240i 1435362189575692182
其中 disk_free 就是表名,hostname是索引,value=xx是记录值,记录值可以有多个,最后是指定的时间
执行后结果如下
> select * from disk_free name: disk_free --------------- time hostname value 1435362189575692182 server01 442221834240
3)删除表
> drop measurement disk_free > show measurements name: measurements ------------------ name weather
四、数据操作
1)增加数据
增加数据采用insert的方式,要注意的是 InfluxDB的insert中,表名与数据之间用逗号(,)分隔,tag和field之间用 空格分隔,多个tag或者多个field之间用逗号(,)分隔。
> insert disk_free,hostname=server01 value=442221834240i 1435362189575692182 > select * from disk_free name: disk_free --------------- time hostname value 1435362189575692182 server01 442221834240
在这条语句中,disk_free是表名,hostname=server01是tag,属于索引,value=xx是field,这个可以随意写,随意定义。
2)查询数据
查询语句与SQL一样,在此不再赘述。
3)修改和删除数据
InfluxDB属于时序数据库,没有提供修改和删除数据的方法。
但是删除可以通过InfluxDB的数据保存策略(Retention Policies)来实现,这个会在以后的文章中讲到。
五、series操作
series表示这个表里面的数据,可以在图表上画成几条线,series主要通过tags排列组合算出来。
我们可以查询表的series,如下所示:
> show series from mem key mem,host=ResourcePool-0246-billing07 mem,host=billing07
六、界面操作
InfluxDB还提供了管理界面,大大降低了入门难度,在启动了InfluxDB服务之后,直接输入 <IP>:8083 即可访问界面。界面如下图所示
InfluxDB的HTTP API写入操作
一、说明
为了方便,本文主要使用curl来发起http请求,示例当中也是使用curl这个工具来模拟HTTP 请求。
在实际使用中,可以将请求写入代码中,通过其他编程语言来模拟HTTP请求。
二、InfluxDB通过HTTP API操作数据库
1)建立数据库
curl -POST http://localhost:8086/query --data-urlencode "q=CREATE DATABASE mydb"
执行这个语句后,会在本地建立一个名为mydb的数据库。
2)删除数据库
curl -POST http://localhost:8086/query --data-urlencode "q=DROP DATABASE mydb"
其实使用HTTP API就是向 InfluxDB 接口发送相应的POST请求。
将语句通过POST方式发送到服务器。
三、InfluxDB通过HTTP API添加数据
InfluxDB通过HTTP API添加数据主要使用如下格式:
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000'
说明:db=mydb是指使用mydb这个数据库。
--data-binary后面是需插入数据。
cpu_load_short是表名(measurement),tag字段是host和region,值分别为:server01和us-west。
field key字段是value,值为0.64。
时间戳(timestamp)指定为1434055562000000000。
这样,就向mydb数据库的cpu_load_short表中插入了一条数据。
其中,db参数必须指定一个数据库中已经存在的数据库名,数据体的格式遵从InfluxDB规定格式,首先是表名,后面是tags,然后是field,最后是时间戳。tags、field和时间戳三者之间以空格相分隔。
四、InfluxDB通过HTTP API添加多条数据
InfluxDB通过HTTP API添加多条数据与添加单条数据相似,示例如下:
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server02 value=0.67 cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257 cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257'
这条语句向数据库mydb的表cpu_load_short中插入了三条数据。
第一条指定tag为host,值为server02,第二条指定tag为host和region,值分别为server02和us-west,第三条指定tag为direction,host,region,值分别为:in,server01,us-west。
五、InfluxDB 的HTTP API响应
在使用HTTP API时,InfluxDB的响应主要有以下几个:
1)2xx:204代表no content,200代表InfluxDB可以接收请求但是没有完成请求。一般会在body体中带有出错信息。
2)4xx:InfluxDB不能解析请求。
3)5xx:系统出现错误。
InfluxDB数据保留策略(Retention Policies)
一、InfluxDB 数据保留策略 说明
InfluxDB的数据保留策略(RP) 用来定义数据在InfluxDB中存放的时间,或者定义保存某个期间的数据。
一个数据库可以有多个保留策略,但每个策略必须是独一无二的。
二、InfluxDB 数据保留策略 目的
InfluxDB本身不提供数据的删除操作,因此用来控制数据量的方式就是定义数据保留策略。
因此定义数据保留策略的目的是让InfluxDB能够知道可以丢弃哪些数据,从而更高效的处理数据。
三、InfluxDB 数据保留策略 操作
1)查询策略
可以通过如下语句查看数据库的现有策略:
> SHOW RETENTION POLICIES ON telegraf name duration shardGroupDuration replicaN default default 0 168h0m0s 1 true
可以看到,telegraf只有一个策略,各字段的含义如下:
name--名称,此示例名称为 default
duration--持续时间,0代表无限制
shardGroupDuration--shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构,应该大于这个时间的数据在查询效率上应该有所降低。
replicaN--全称是REPLICATION,副本个数
default--是否是默认策略
2)新建策略
> CREATE RETENTION POLICY "2_hours" ON "telegraf" DURATION 2h REPLICATION 1 DEFAULT > SHOW RETENTION POLICIES ON telegraf name duration shardGroupDuration replicaN default default 0 168h0m0s 1 false 2_hours 2h0m0s 1h0m0s 1 true
通过上面的语句可以添加策略,本例在 telegraf 库添加了一个2小时的策略,名字叫做 2_hours, duration为2小时,副本为1,设置为默认策略。
因为名为default的策略不再是默认策略,因此,在查询使用default策略的表时要显式的加上策略名 “default”。
> select * from "default".cpu limit 2 name: cpu --------- time cpu host host_id usage_guest usage_guest_nice usage_idle usage_iowait usage_irq usage_nice usage_softirq usage_steal usage_system usage_user 1467884670000000000 cpu-total ResourcePool-0246-billing07 0 0 99.79994164175388 0 0 0.06251823446523729 0 0 0.12920435125646068 0.008335764603451727 1467884670000000000 cpu9 billing07 0 0 97.79338014069532 1.8054162487519367 0 0 0 0 0.10030090272883943 0.3009027081135398
3)修改策略
修改策略使用如下语句修改
> ALTER RETENTION POLICY "2_hours" ON "telegraf" DURATION 4h DEFAULT > show retention POLICIES on telegraf name duration shardGroupDuration replicaN default default 0 168h0m0s 1 false 2_hours 4h0m0s 1h0m0s 1 true
可以看到,修改后的策略发生了变化。
4)删除策略
InfluxDB中策略的删除操作如下所示:
> drop retention POLICY "2_hours" ON "telegraf" > show retention POLICIES on telegraf name duration shardGroupDuration replicaN default default 0 168h0m0s 1 false
可以看到,名为2_hours的策略已经被删除了。
四、其他说明
策略这个关键词“POLICY”在使用是应该大写,小写应该会出粗。
当一个表使用的策略不是默认策略时,在进行操作时一定要显式的指定策略名称,否则会出现错误。