
日升时奋斗,日落时自省
目录
MySQL在初阶操作是一些简单操作,也是在以后最长用的,但是还没有约束条件的限制,不能算是完整的,数据库具有约束性
一、数据库约束
1.1约束类型
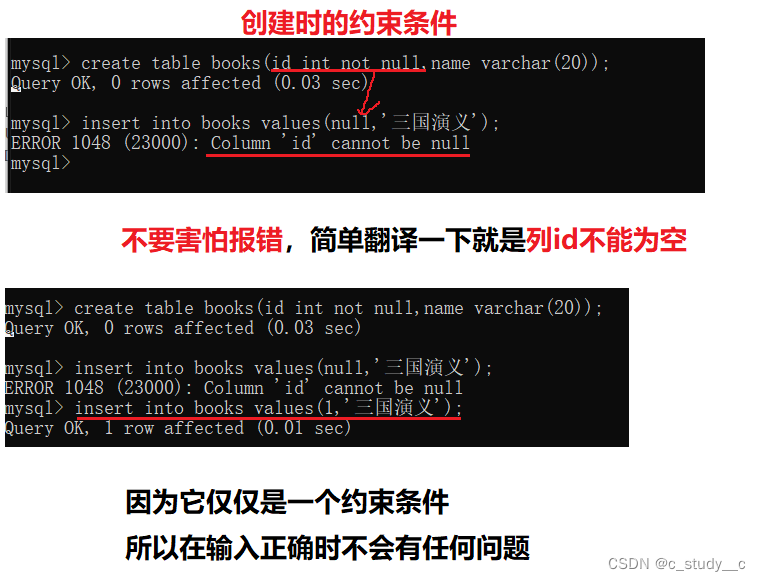
(1)not null(大小写不影响)存储列不为null
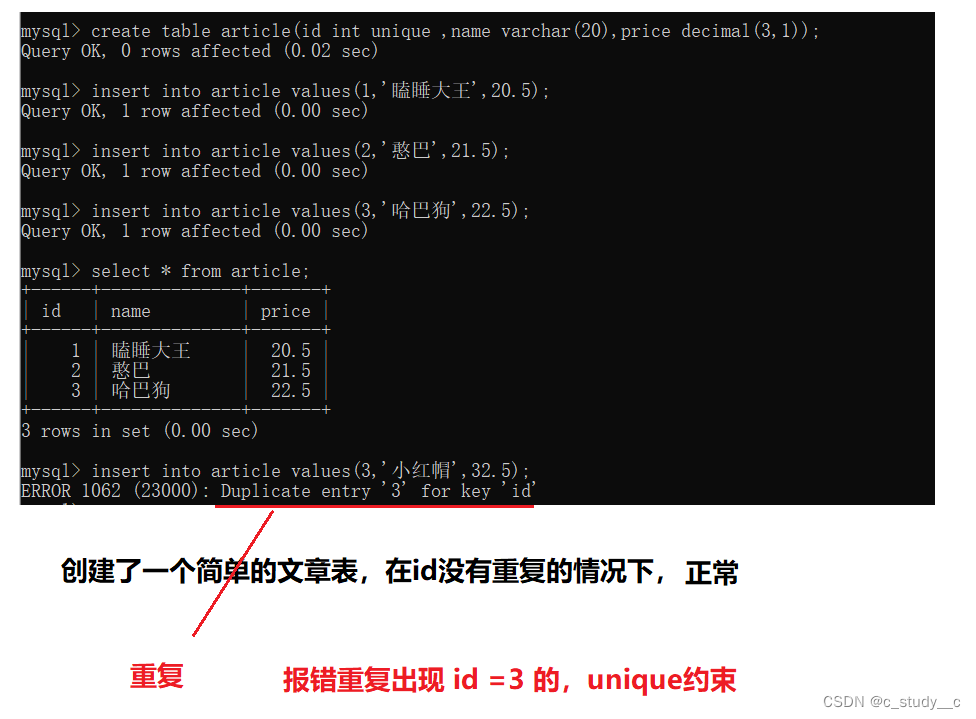
(2)unique 存储列必须是独一无二(无重复的)
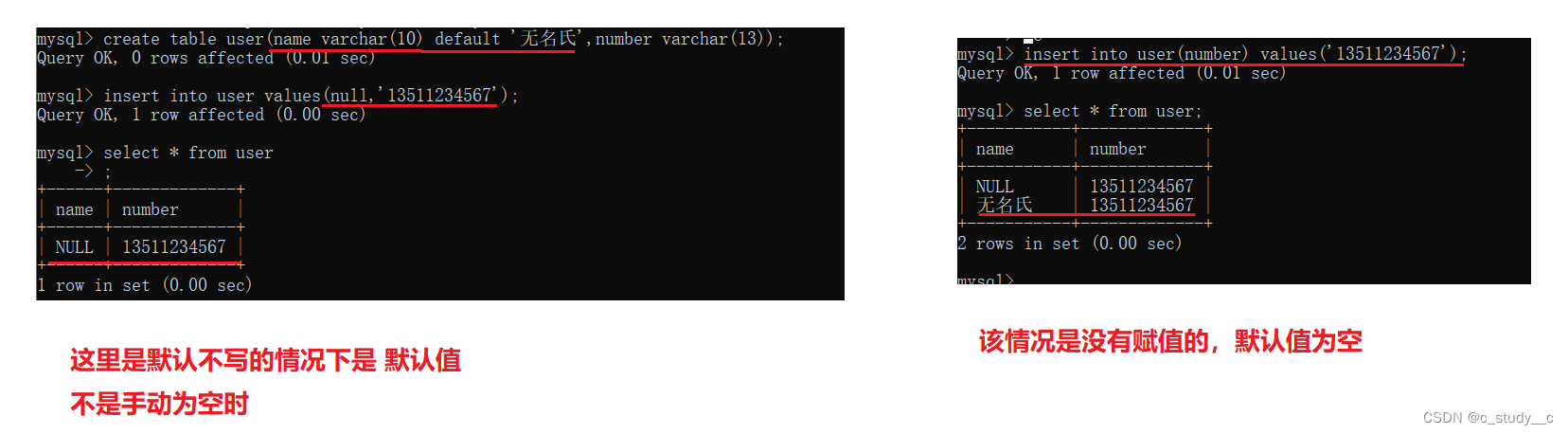
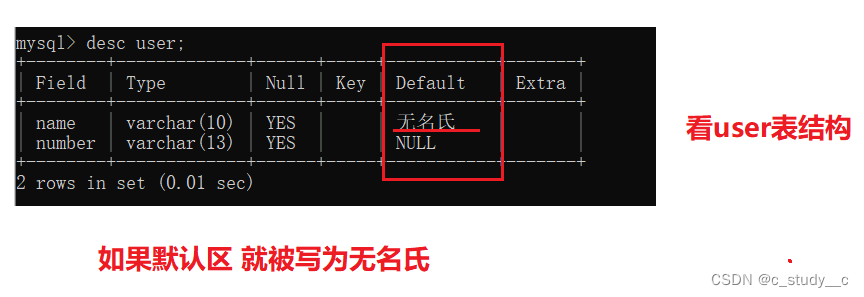
(3)default 设置为空时的默认值
(4)primary key 翻译过来就是主键,主键是什么,主键就是独一无二的,为我们做查找的,他其实就是not null和unique 的结合版,不为空也是独一无二的
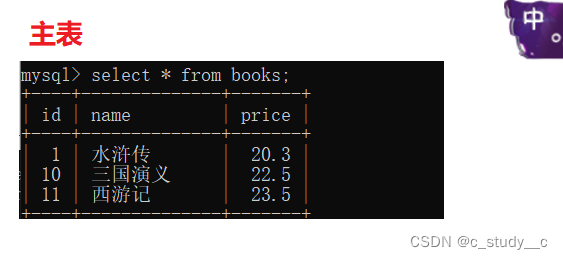
(5)foreign key 翻译后就是外键,外键就把和主键建立关系,两个表成了一种父子关系,当前表是子表,连接的表是父表(下面会演示)
(6)check 约束:check有检查的意思,在这里是限定我们要设置值,比如在输入性别时,仅限制在男女,check (sex ='男' or sex='女');
注:check在8版本MySQL是可以使用的也会生效,但是在5版本是不会生效的,但是不会报错
1.2 null约束条件
使用方法:列 not null
1.3unique 约束条件
使用方法 : 列 unique
1.4default约束条件
使用方法: 列 default 默认值
1.5primary key (主键)约束
主键特性:不能为空,不能重复
使用方法: 列 primary key

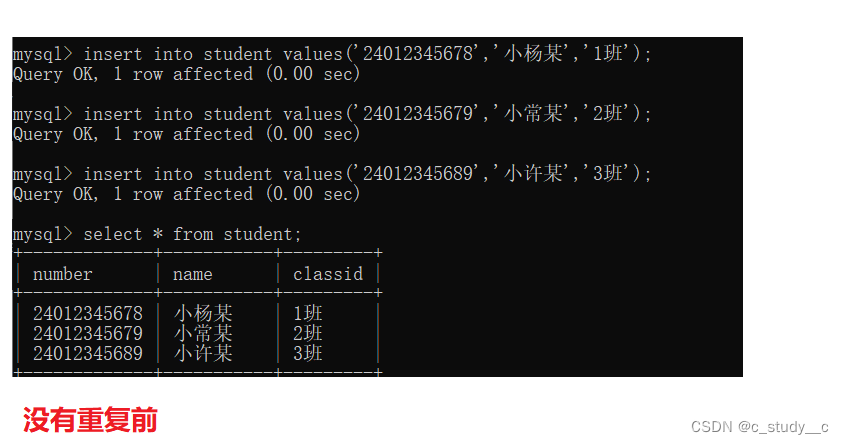
(1)具有 unique的特性

(2)具有not null的特性
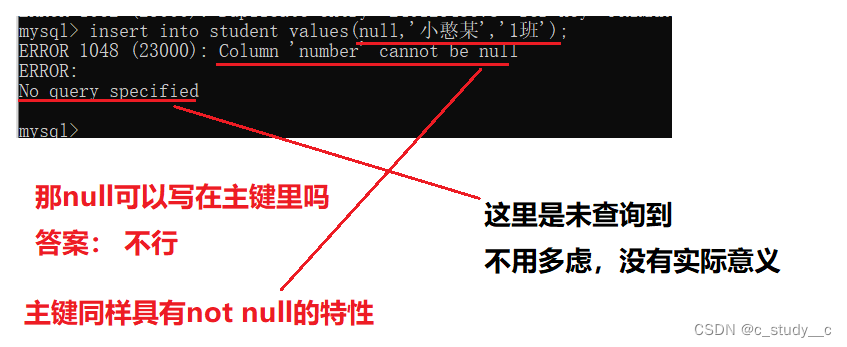
(3)主键表结构

(4)自增主键(特殊)
使用方法:primary key auto_ increment
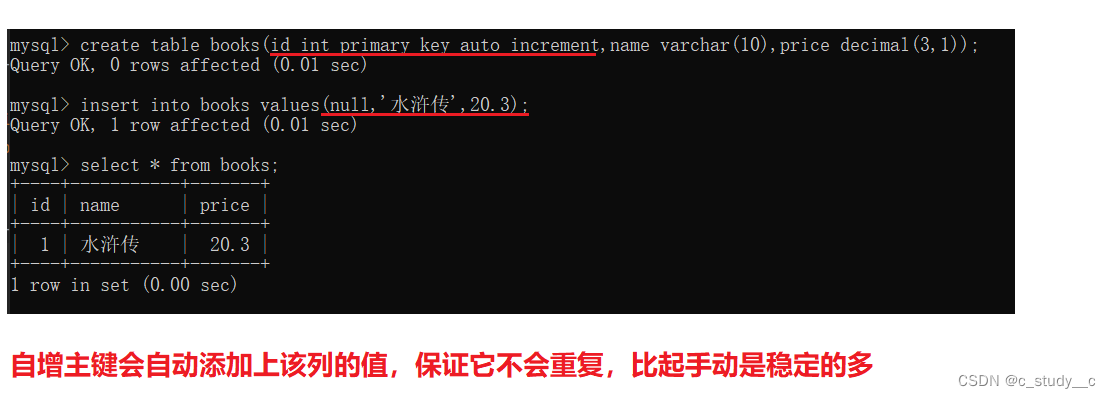
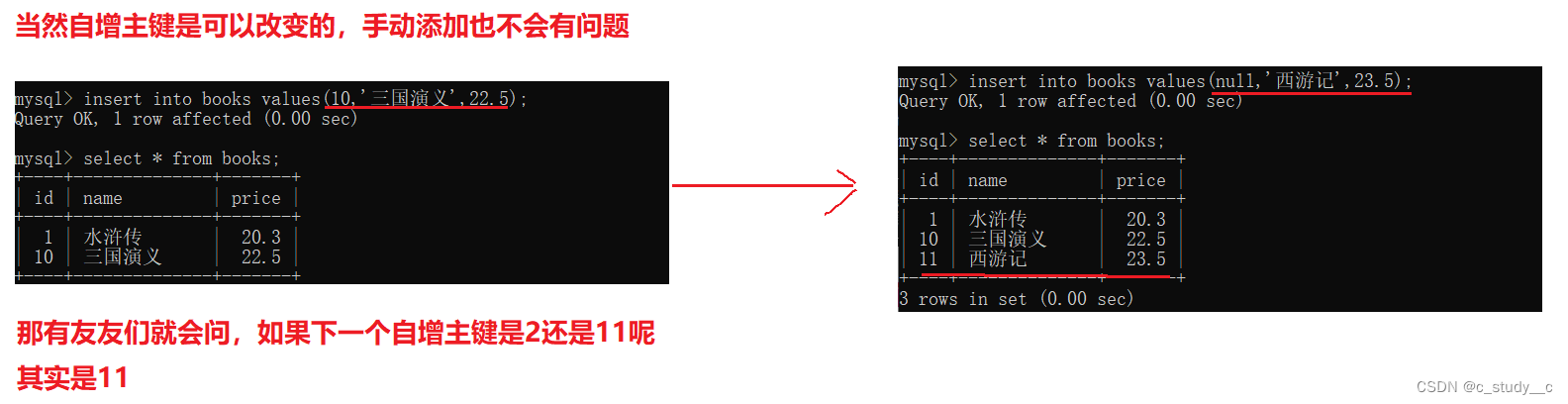
那浪费空间,当然浪费,但是对于数据来说很难有很大的数据,数据库可以支持上亿的数据,这点数据量还是很微小的,所以空间浪费并不大相对上亿的空间
1.6foreign key外键 约束
外键使用:foreign key(列) references 主表(列)
主表的列要求:是带有主键的
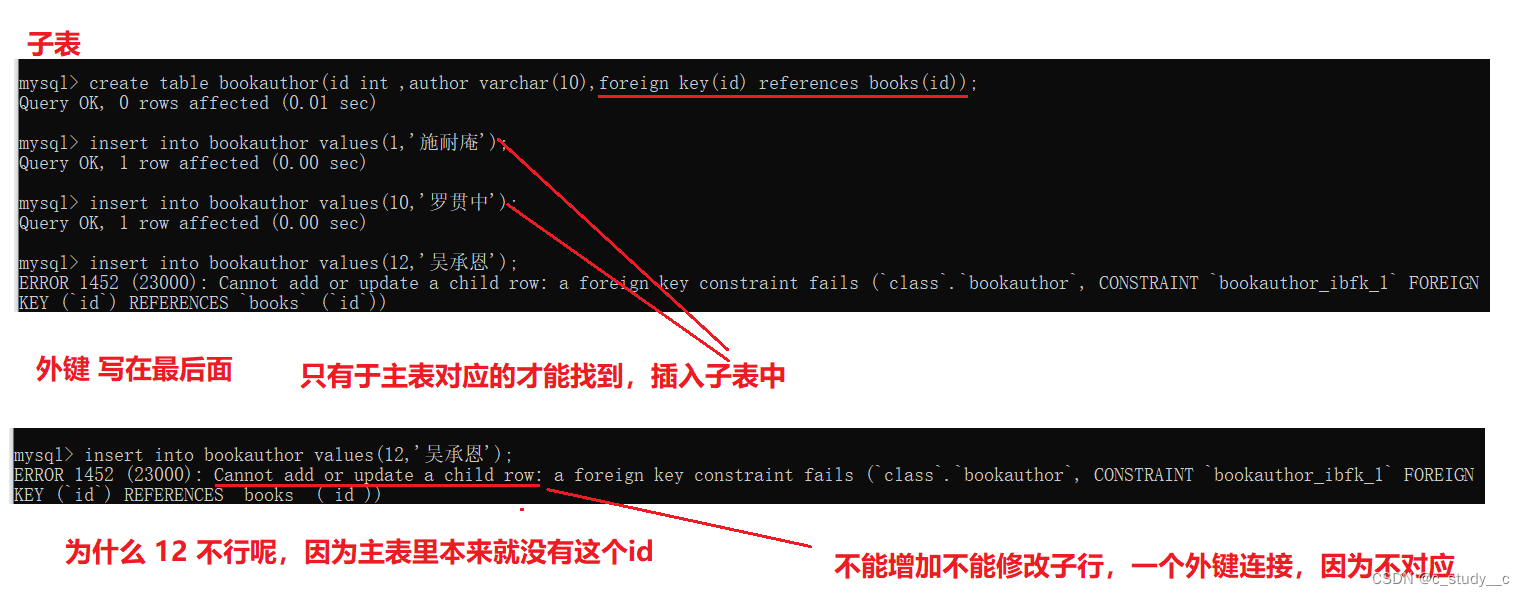
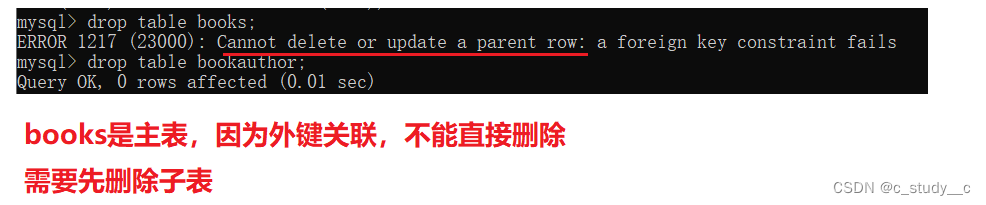
经过外键关联之后是不能轻易删除的
过度:
表的设计(当前很少见到)没有实例
一对一,一对多,多对多
仅仅提一下
一对一: 就是当前 一个人只有一个身份证,
一对多:一个部门有多个员工
多对多:老师会带多个学生,一个学生多个老师的课程
二、查询
1、聚合查询
这里简单的几个常用聚合函数,仅仅需要一点点英语水平,不用担心
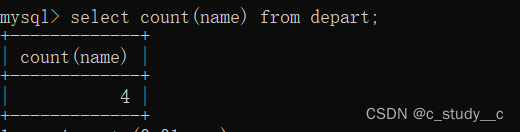
count : 计算个数的
sum :求和的,前提得是数字
max : 求最大值的
min : 求最小值的
avg :求平均值的
以上函数都比较单一,其实打出来一个基本剩下的这些都就明白了
这里先提及其他两个表述条件使用,然后放在一起连用
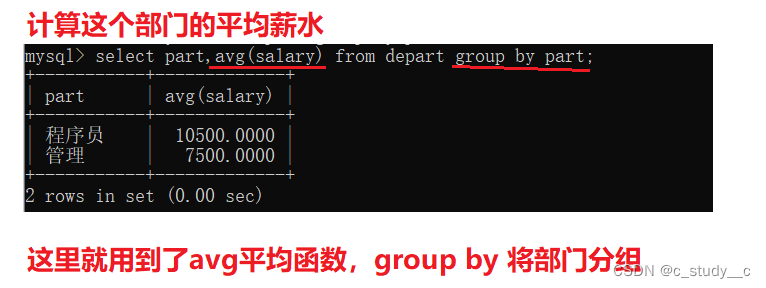
1.1group by(分组)与 having条件
group by使用在where 的后面,在where条件之后可以加group by ,但是想把条件后面的话应该怎办,这时候就需要having 了,
先写条件语句,再分组,用where
先分组,后写条件语句,用having
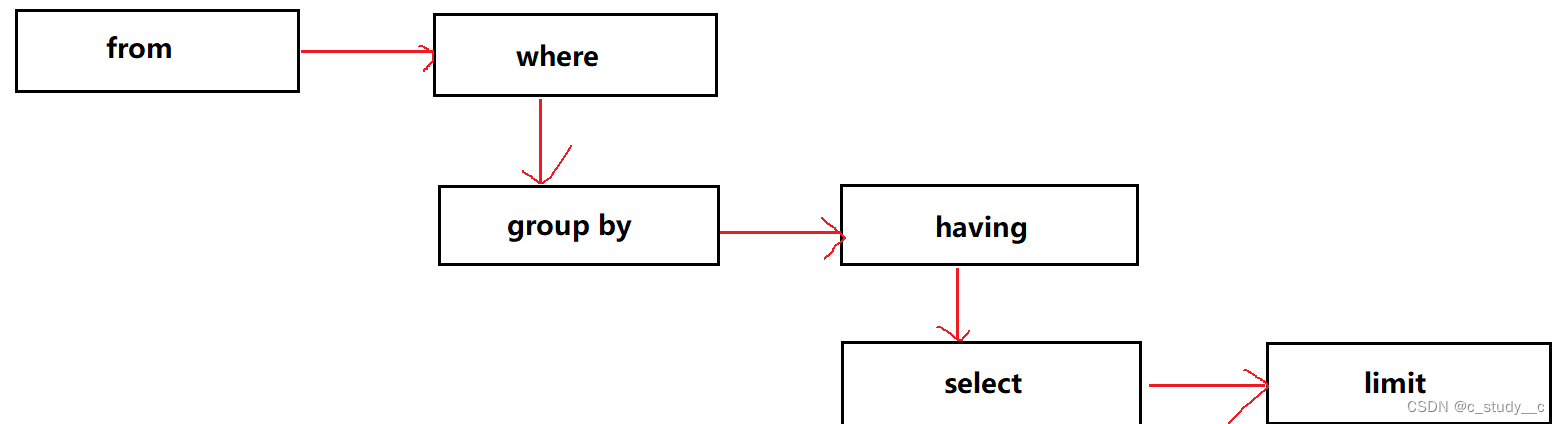
一个大概的执行顺序
我们来使用一下group by
(1)where 在前,group by 在后
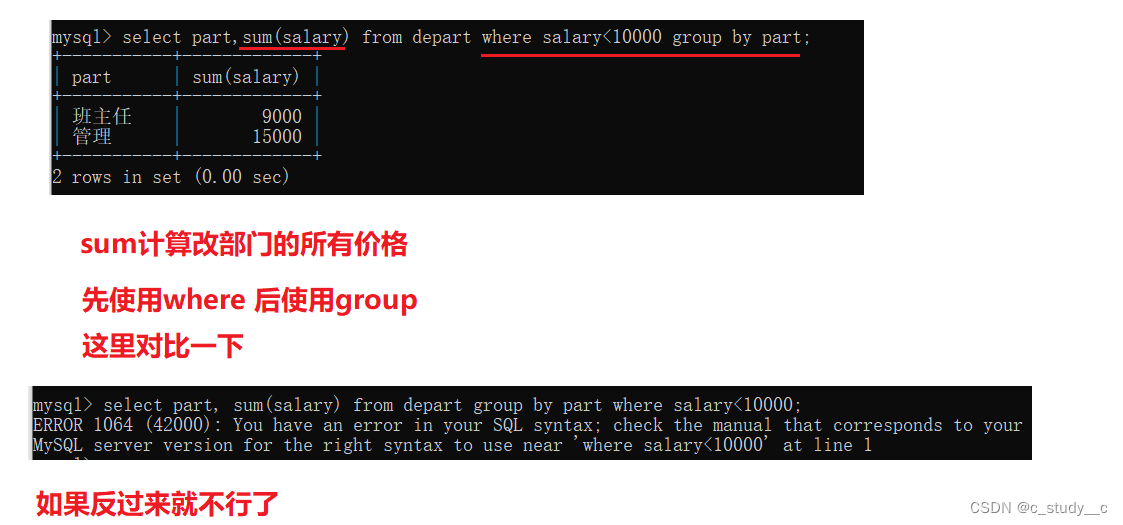
(2)group by 在前,having在后

其他的函数这里就不一一列举了,按照前面MySQL执行顺序,合适时使用函数;
2、联合查询
联合查询就涉及到多个表
联合最开始进行一个笛卡尔积,
笛卡尔积:在查询的数据里解释就是 多表列之和,多表行之积
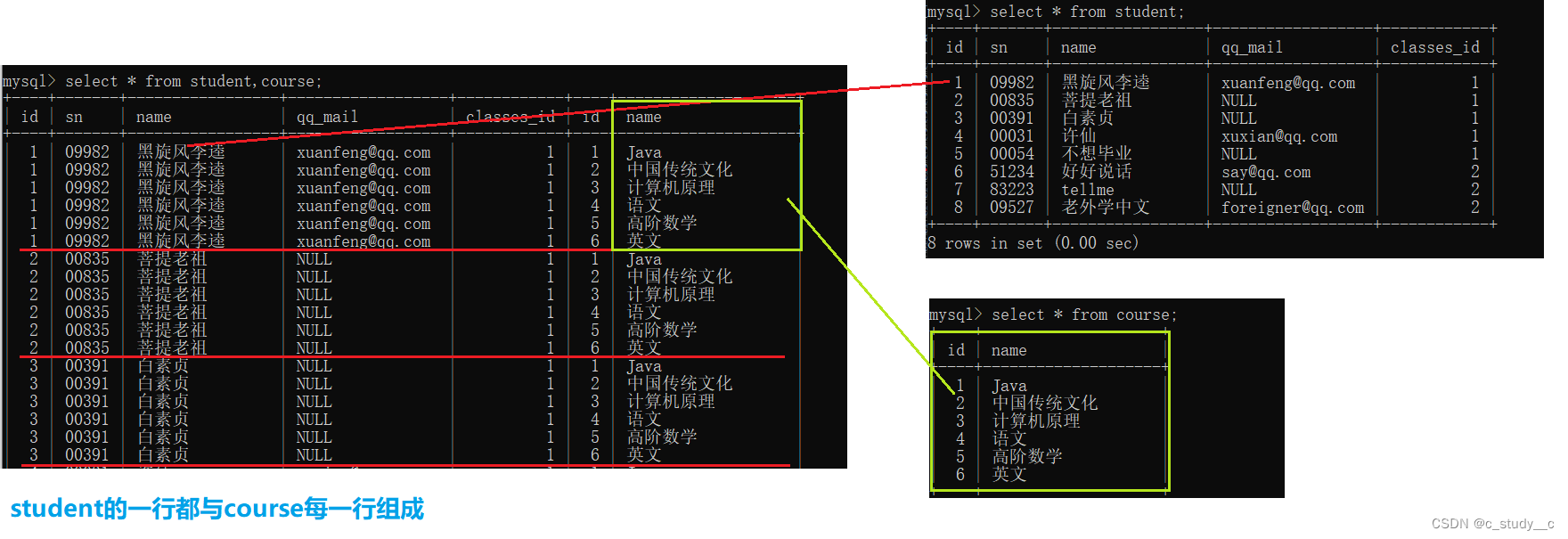
当然笛卡尔积显示了所有,但是并不是我们所需要的,我们需要的是将两个表构建在一起
2.1内连接
可以用两种方法来连接
一种是where条件连接
select 列名 from 表名(可以多个)where 连接条件 and 其他条件
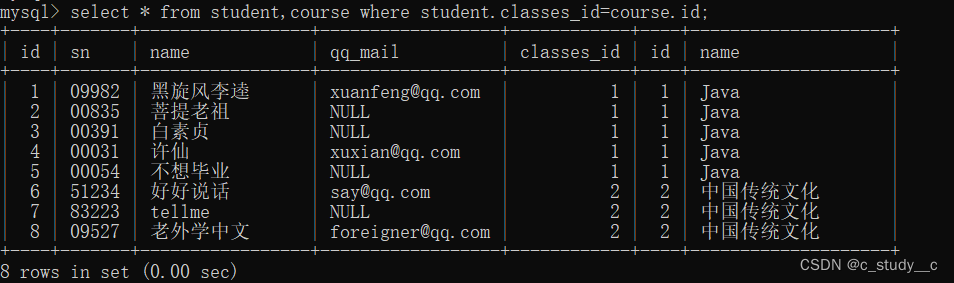
另一种
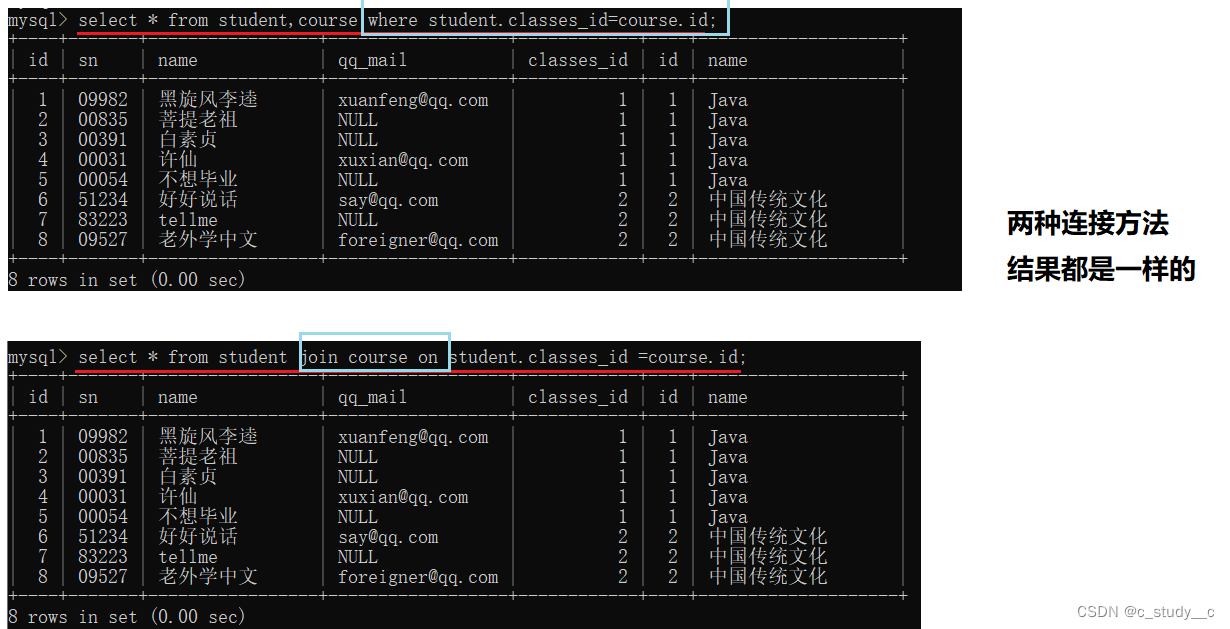
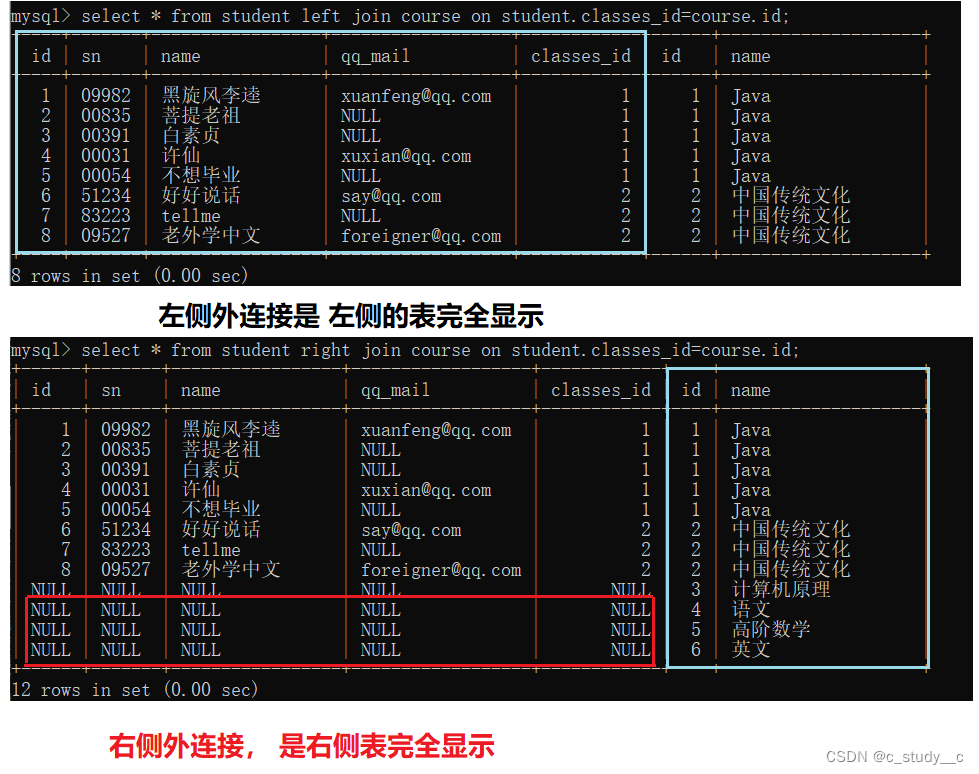
2.2外连接
外连接分为左连接,右连接
2.3自连接
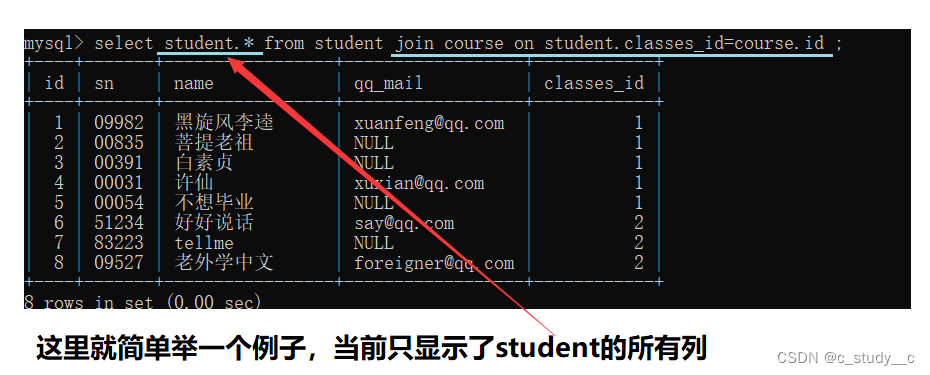
想尝试其他的也可以尝试其他的,这里只简单的举个例,过个表中联系后进行,单个表的某些列的信息打印
使用例:
如果我们想要找同一个人的成绩进行对比,那就成为了行对比,但是MySQL里面没有行对比这一说,我们就需要把行转化为列
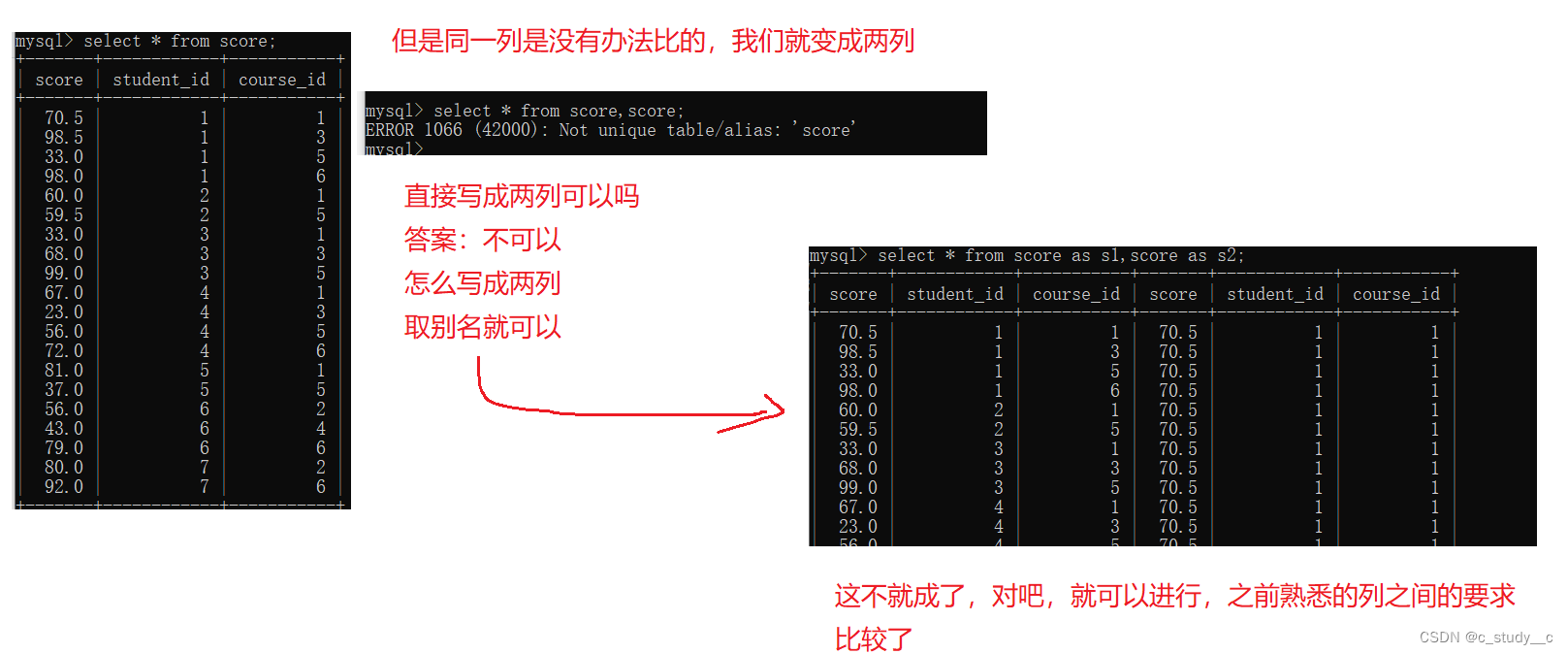
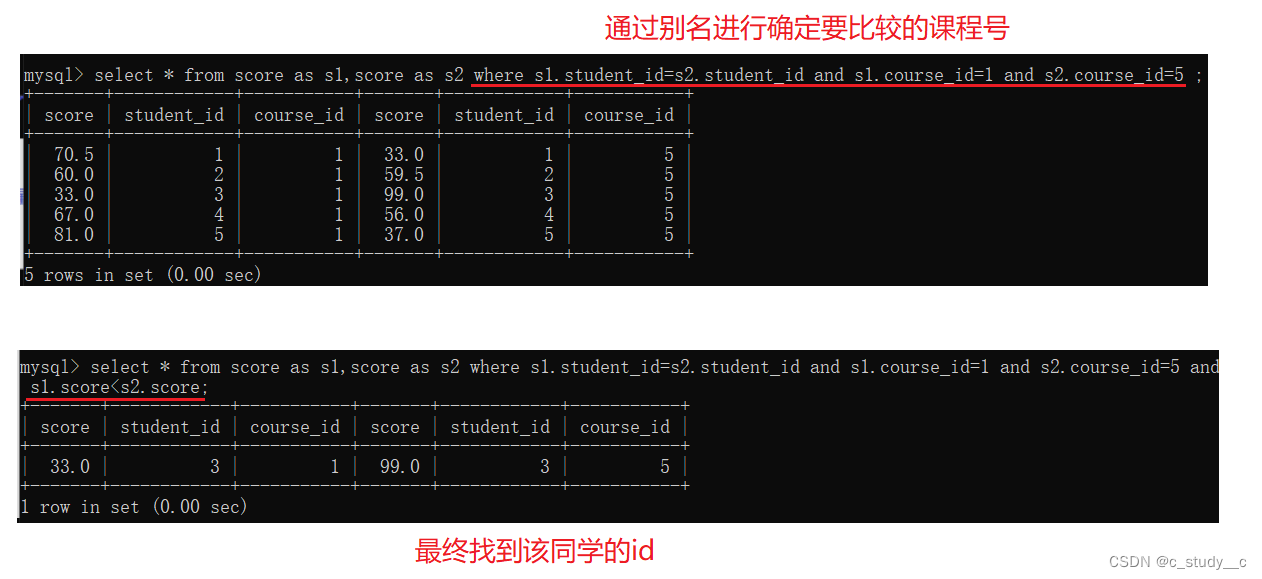
自连接查询就是解决行与行之间的比较
2.4子查询
子查询其实很好了理解,当你要查一个重名的人员的所有信息时,我们应该怎么查,这里就可以用到子查询来解决,像套娃一样,相当于查询的是你想要值的子值,先找到子值,子值满足了,当前要求也就满足了,子值中也可以包含子值哈,无限套娃(哈哈哈)
缺点:子查询代码比较复杂,SQL语言此时可读性比较低,维护成本较高,执行效率也有很大的影响。
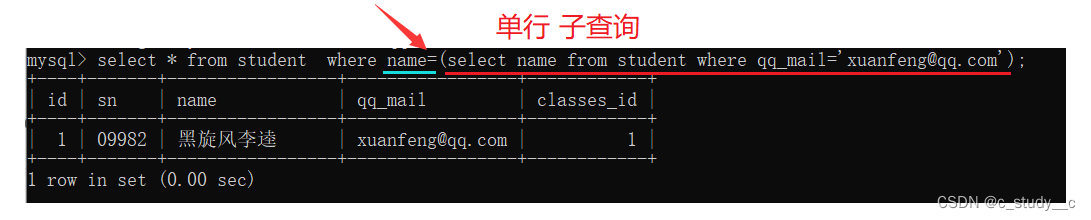
(1)单行子查询
单行子查询就比较单一了,只能进行一个子值的接收
(2)多行子查询
多行子查询,也可以进行,单行子查询,多行包括了1行

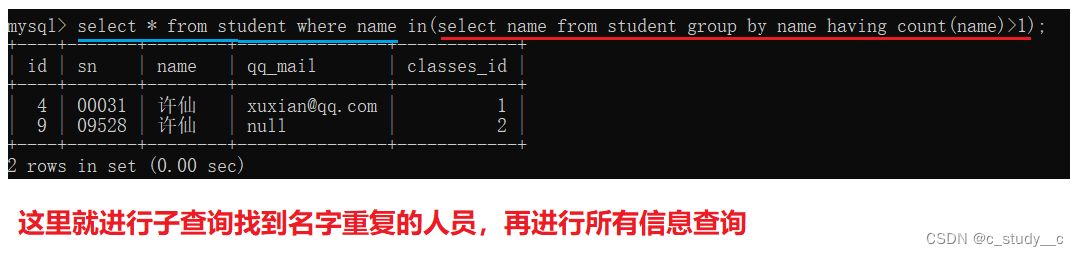
学生表里有重复的两个名字,当不知道谁是重名的时候就需要先去找
例题:显示出所有重复名字的人员信息
2.5合并查询
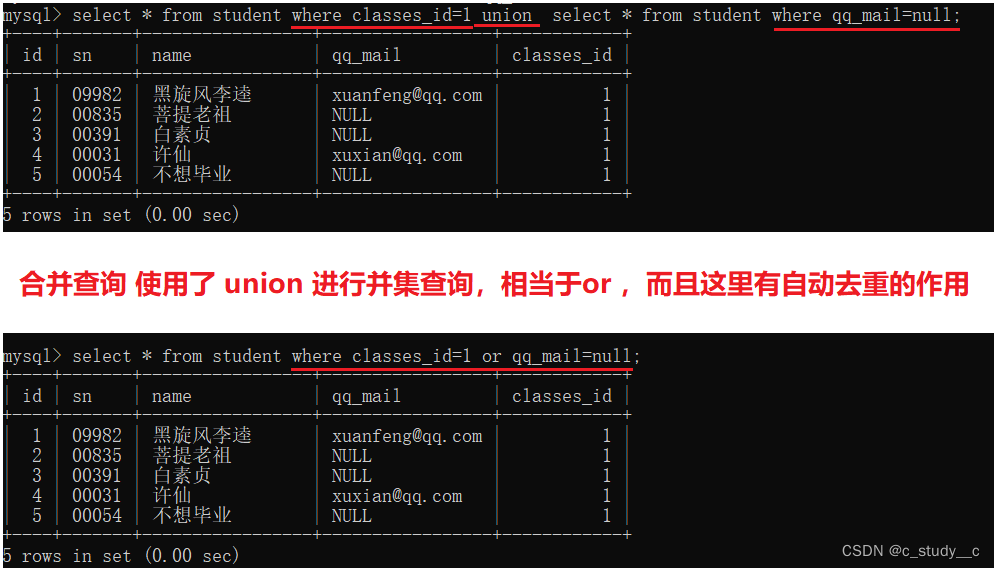
(1)union 具有or的作用,同时可以自动去重
使用方法: select 列 from 表 条件 union select 列 from 表 条件
合并查询有点像or 就是将两个查询结果都显现出来
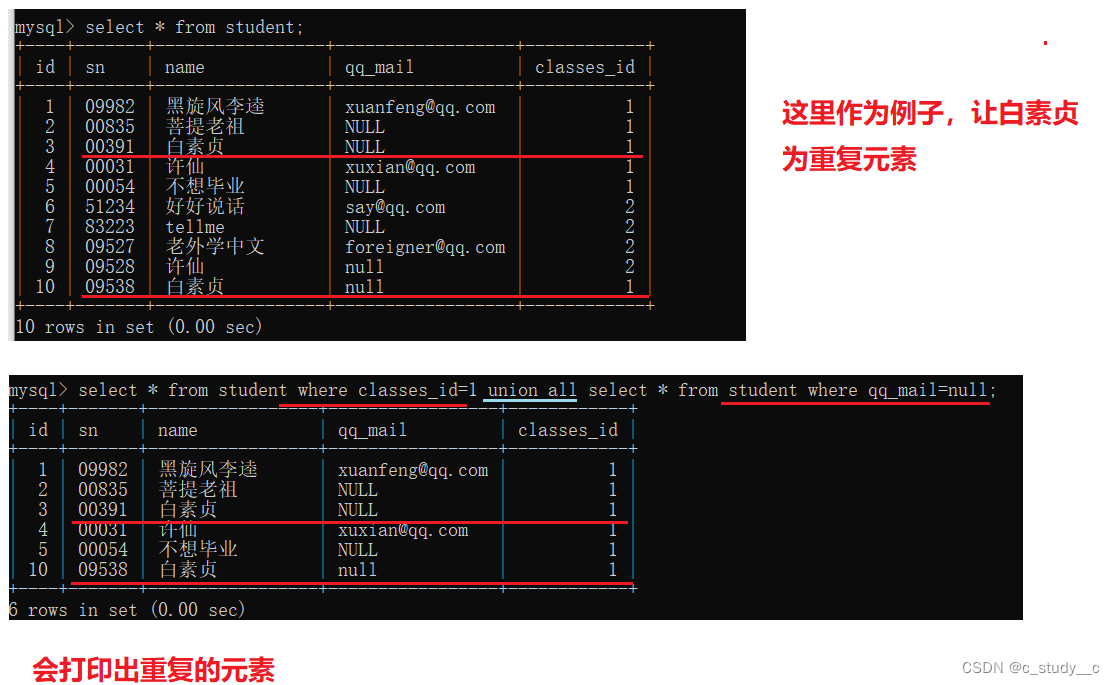
(2)union all 有or的作用,但是不能去重,是全部的
使用方法: select 列 from 表 条件 union all select 列 from 表 条件
(3)合并查询不仅仅只有or的作用,比or更加宽泛,union 和 union all可以在不同的表里面实现查询,但是查询有条件要求,需要列的类型相同,列的个数相同,列的名称相同
3、总结
在插入的时候,尽量就一次插入多个元组,因为每次我给数据库添加数据的时候都需要花费一定的时间,所以当前一次多个元组能够减少不少的时间浪费,挺高效率。
数据是怎么来的呢,是有客户端通过MySQL进行输入给服务器的,服务器响应发送数据给在接收数据的客户端
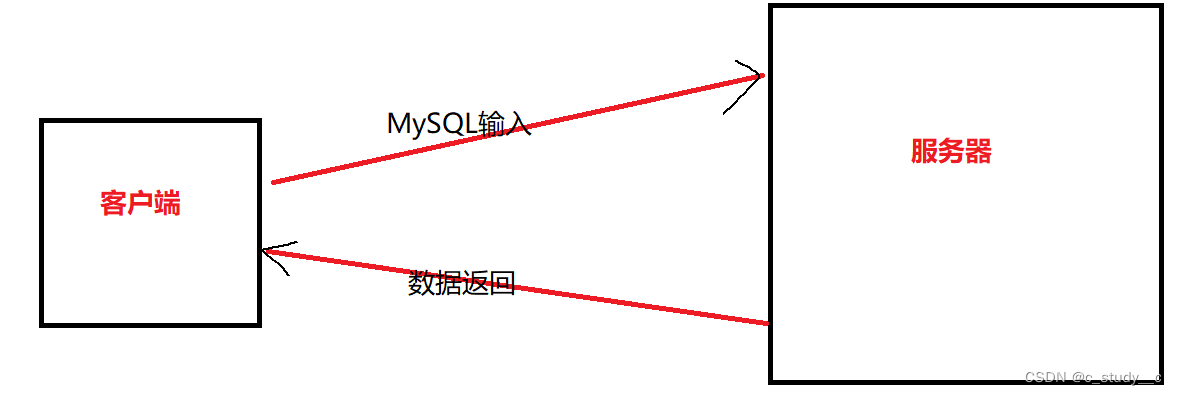
那就说MySQL是不是就这些了,其实不是,SQL也是编译语言,但是不太使用,也是存在想java一样的语言构造的(条件,循环,函数) 这些更复杂,执行效率不高,很少使用,耦合性比较高, 我们使用MySQL一般都是连接其他编译语言一起使用,更快,更便捷。
实现低耦合,高内聚
耦合:简单理解联系不紧密,就不会有很多麻烦的事情(耦合性低)
模块关联越大工作量就越大,
内聚:内聚就相当于代码排列一样,如果是分块排版就会有高的可读性,便于维护(高内聚)