序列化:这个意思就是把需要处理的数据转化为字节序列,以便于传输,java中有自己的序列化框架,但是java是重量级的框架,一个对象被序列化后,会附带很多额外信息(校验信息,继承体等),这些信息是mapreduce用不着的,所以只需要简单的序列化就行。
在开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。

具体实现bean对象序列化步骤如下7步。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
| public FlowBean() { super(); } |
(3)重写序列化方法
| @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } |
(4)重写反序列化方法
| @Override public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong(); } |
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用”\t”分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
| @Override public int compareTo(FlowBean o) { // 倒序排列,从大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; } |
看一个案例:统计手机的上行流量、下行流量、总流量。难点在于KV值中,value需要定义为一个单独的对象,这样才能进行数据传输。

编写程序:
(1)编写流量统计的Bean对象
| package com.atguigu.mapreduce.flowsum; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; // 1 实现writable接口 public class FlowBean implements Writable{ private long upFlow; private long downFlow; private long sumFlow; //2 反序列化时,需要反射调用空参构造函数,所以必须有 public FlowBean() { super(); } public FlowBean(long upFlow, long downFlow) { super(); this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } //3 写序列化方法 @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } //4 反序列化方法 //5 反序列化方法读顺序必须和写序列化方法的写顺序必须一致 @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } // 6 编写toString方法,方便后续打印到文本 @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } } |
(2)编写Mapper类
| package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ FlowBean v = new FlowBean(); Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 切割字段 String[] fields = line.split("\t"); // 3 封装对象 // 取出手机号码 String phoneNum = fields[1]; // 取出上行流量和下行流量 long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]); k.set(phoneNum); v.set(downFlow, upFlow); // 4 写出 context.write(k, v); } } |
(3)编写Reducer类
| package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> { @Override protected void reduce(Text key, Iterable<FlowBean> values, Context context)throws IOException, InterruptedException { long sum_upFlow = 0; long sum_downFlow = 0; // 1 遍历所用bean,将其中的上行流量,下行流量分别累加 for (FlowBean flowBean : values) { sum_upFlow += flowBean.getUpFlow(); sum_downFlow += flowBean.getDownFlow(); } // 2 封装对象 FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow); // 3 写出 context.write(key, resultBean); } } |
(4)编写Driver驱动类
| package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowsumDriver { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { // 输入输出路径需要根据自己电脑上实际的输入输出路径设置 args = new String[] { "e:/input/inputflow", "e:/output1" }; // 1 获取配置信息,或者job对象实例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 6 指定本程序的jar包所在的本地路径 job.setJarByClass(FlowsumDriver.class); // 2 指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 3 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 4 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 5 指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } |
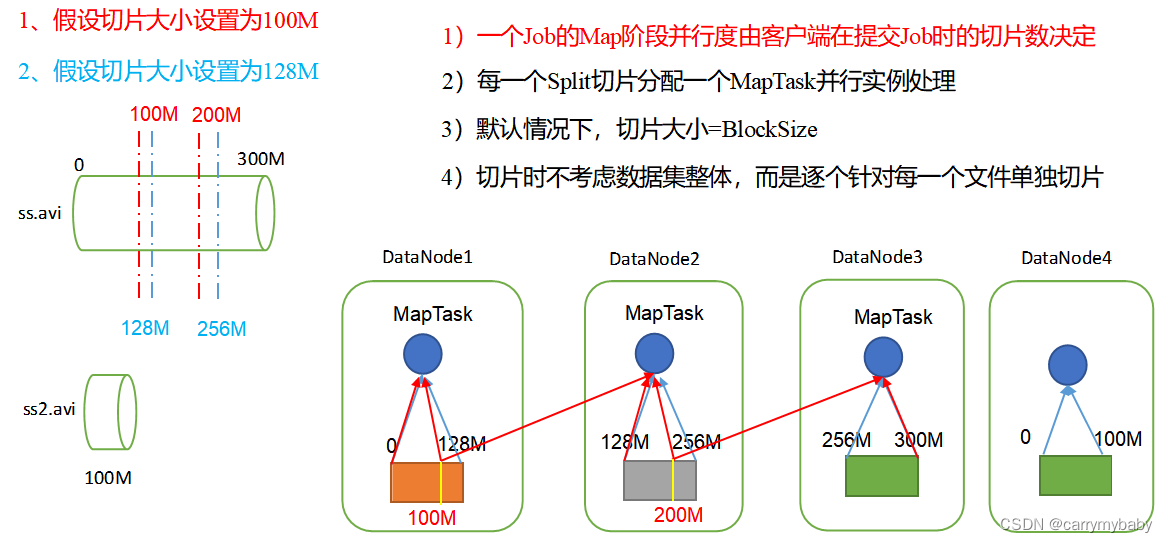
MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。