本文介绍一篇一阶段的3D物体检测网络:SE-SSD,论文已收录于 CVPR 2021。 这里重点是理解本文提出的 Consistency Loss 、Orientation-Aware Distance-IoU Loss、Shape-Aware Data Augmentation。

论文链接为:https://arxiv.org/pdf/2104.09804.pdf (中文翻译)
项目链接为:https://github.com/Vegeta2020/SE-SSD
0. Abstract
这里先给出本文摘要:
针对室外点云数据,作者提出了一个准确而又高效的3D物体检测模型:SE-SSD。其关注点是使用 soft 目标和 hard 目标以及制定的约束来共同优化模型,且在推理中不引入额外计算量(这里 soft 为 teacher 模型预测的目标,hard 为标注的目标)。
具体来说:
SE-SSD包含一对teacher和studentSSD 模型,作者设计了一个有效的IOU-based匹配策略来过滤teacher预测的soft目标,并使用一致性损失来使student的预测和teacher预测保持一致。- 此外,为了使
teacher模型的蒸馏知识最大化,作者设计了一种新的数据增强方案来训练student模型,以推断出物体的完整形状。 - 最后,为了更好地利用
hard目标,作者还设计了一个ODIoU损失来监督student模型预测的 bbox 中心和方向。
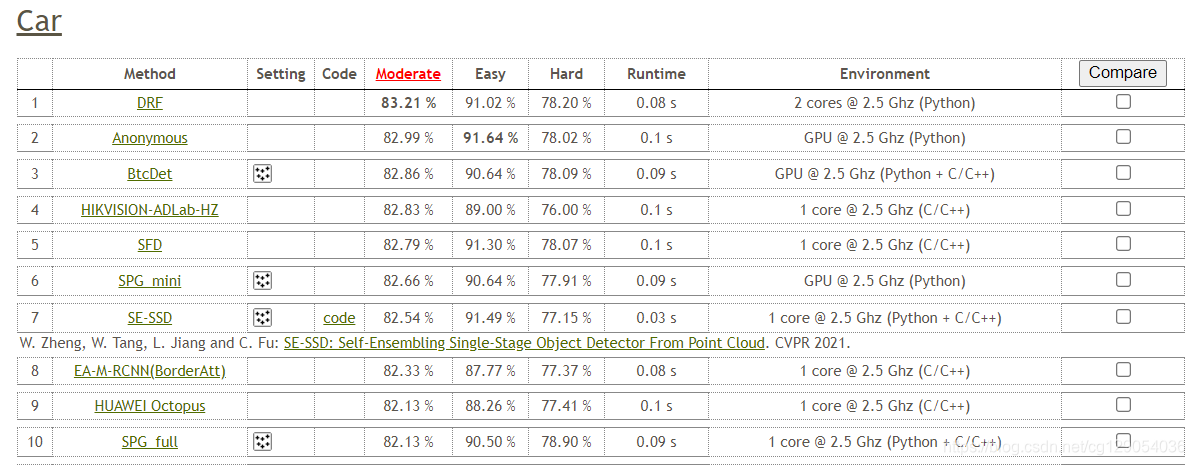
在 KITTI 数据集上,目前在开源项目中排名暂列第一(截至2021-06-17)。
1. Introduction & Related Work
( 本文的引言部分和第二部分研究现状这里就不详细介绍了,大家可以查看原文,我在这里大致总结下。)
在追求高效率的同时,为了提高物体3D检测精度,本文设计了具有一对 teacher SSD 和 student SSD的 SE-SSD模型。
teacher模型由student模型集成而来 ,可以得到相对更精确的边界框和置信度,可作为监督student模型的soft目标。与hard目标相比,来自teacher的soft目标通常有更高的信息熵,从而为student模型 提供了更多可学习的信息。因此,本文利用soft目标和hard目标以及制定的约束来共同优化模型,且不需要额外的推理时间。- 为了使
student预测的边界框和置信度更好地与soft目标保持一致,作者设计了一种有效的IOU-based匹配策略来过滤soft目标,并将其与student的预测进行配对,并利用一致性损失减少它们之间的错位。 - 另一方面,为了使
student模型能够探索更大的数据空间,在传统的数据增强策略之上设计了新的数据增强方案,即以一种形状感知的方式生成增强样本。通过该方案,模型可以从不完整的信息中推断出物体完整的形状。是一个即插即用的3D检测通用模块。 - 此外,因为
hard目标是模型收敛的最终目标,为了更好地利用它们,本文提出了一种新的orientation-aware distance-IoU (ODIOU)损失,监督student预测的 bbox 中心和方向。
下面介绍研究现状,作者将3D物体检测分为一阶段和两阶段来介绍:
- Two-stage Object Detectors:
PointRCNN,Part-A2,STD,PV-RCNN,3D-CVF,CLOCs。 - Single-stage Object Detectors :
VoxelNet,PointPillar,SECOND,TANet,Point-GNN,3DSSD,Associate-3Ddet,SA-SSD,CIA-SSD。
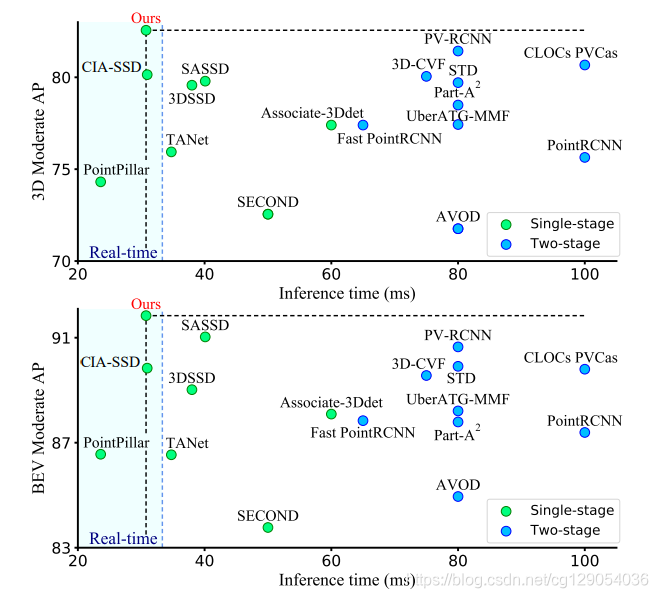
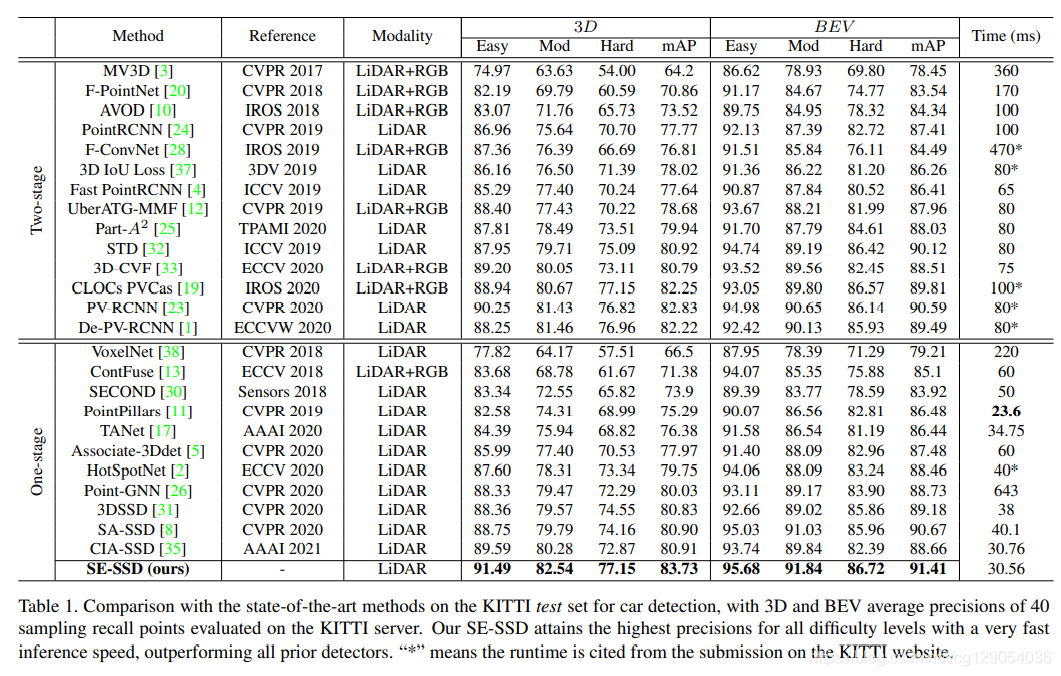
下图是 SE-SSD 与其它3D物体检测器在 3D和BEV上检测效果的比较,其每一帧处理时间为30.56ms。
2. Self-Ensembling Single Stage Detector (重点)
2.1 Overall Framework
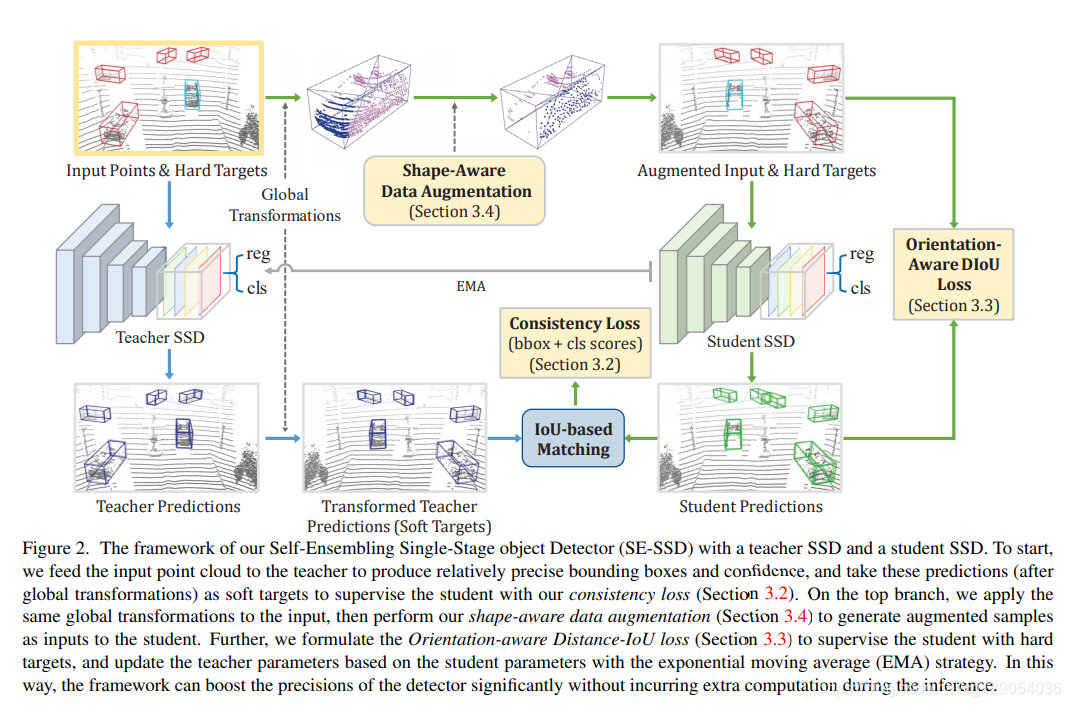
SE-SSD网络框架如下图所示,左边是Teacher SSD,右边是Student SSD,两个SSD同时训练(两个SSD网络结构相同)。训练时,先使用预训练好的SSD模型来初始化teacher SSD和 student SSD。整个网络框架包含两个处理路径:
- 第一个路径(蓝色箭头所示),
teacher SSD从输入点云生成相对精确的预测。然后,对预测结果进行全局转换,并将其作为soft目标来监督student SSD。 - 第二个路径(绿色箭头所示),通过与第一条路径相同的
全局转换对点云进行扰动处理,再加上本文提出的形状感知数据增强方案。然后,将增强后的数据输入到student SSD进行训练,这里student预测时使用了一致性损失(与soft进行对齐);我们也用hard目标来监督student预测的方向感知距离损失。
训练中,迭代更新两个SSD模型:使用上述提到的两个损失来优化 student SSD,并对 student SSD参数通过标准指数移动平均(EMA)更新teacher SSD。因此,teacher SSD 可以从 student SSD 那里获得蒸馏知识,并产生 soft 目标来监督 student SSD。
teacher and student SSD模型结构: 模型与 CIA-SSD模型结构相同,但移除了置信度函数和DI-NMS。包含一个稀疏卷积网络(SPConvNet),一个BEV卷积网络(BEVConvNet)和一个multi-task head (MTHead)。点云经过体素化后处理,计算每个体素的平均3D坐标和点密度来作为初始特征,然后使用 SPConvnet 提取特征,SPConvNet 有四个块({2,2,3,3}子稀疏卷积层),最后有一个稀疏卷积层。接下来,沿
z
z
z 轴将稀疏3D特征连接成2D密集特征,用 BEVConVNet 提取特征。最后,使用 MTHead来回归边界框并进行分类。
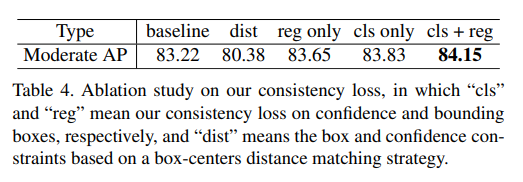
2.2 Consistency Loss
在3D物体检测中,预定义 anchor 中的点云可能因距离和遮挡而有很大差异。因此,同一 hard 物体的样本点云和特征也会差异很大。相比之下,每个训练样本的 soft 目标信息更加丰富,有助于探索同类的数据样本之间差异。这启发我们将相对精确的teacher prediction当作soft 目标,并利用它们来优化student模型。因此,本文提出一致性损失 来优化 student 模型。
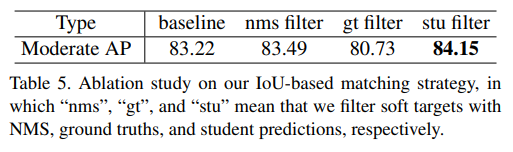
在计算一致性损失前,本文首先设计了一个高效的 IoU-based 匹配策略,目的是在稀疏室外点云中匹配 非轴对齐的teacher和student的 box。
- 为了从
teacher中获得高质量的soft目标,使用置信度过滤teacher和student预测的部分边界框,减少一致性损失的计算量; - 然后,计算剩余
teacher和student边界框的IoU,过滤IoU较低的匹配边界框; - 最后,对于每一个
student边界框,将它与具有最大IoU的teacher边界框匹配,以增加soft目标的置信度。
与 hard 目标相比,由于它们是基于相似的特征预测的,因此过滤后的 soft 目标通常更接近 student 预测。
本文采用 Smooth-L1 损失作为回归损失:
L
box
c
=
1
N
′
∑
i
=
1
N
1
(
I
o
U
i
>
τ
I
)
∑
e
1
7
L
δ
e
c
and
δ
e
=
{
∣
e
s
−
e
t
∣
if
e
∈
{
x
,
y
,
z
,
w
,
l
,
h
}
∣
sin
(
e
s
−
e
t
)
∣
if
e
∈
{
r
}
\begin{array}{l}\mathcal{L}_{\text {box }}^{c}=\frac{1}{N^{\prime}} \sum_{i=1}^{N} \mathbb{1}\left(I o U_{i}>\tau_{I}\right) \sum_{e} \frac{1}{7} \mathcal{L}_{\delta_{e}}^{c} \\\text { and } \delta_{e}=\left\{\begin{array}{ll}\left|e_{s}-e_{t}\right| & \text { if } e \in\{x, y, z, w, l, h\} \\\left|\sin \left(e_{s}-e_{t}\right)\right| & \text { if } e \in\{r\}\end{array}\right.\end{array}
Lbox c=N′1∑i=1N1(IoUi>τI)∑e71Lδec and δe={∣es−et∣∣sin(es−et)∣ if e∈{x,y,z,w,l,h} if e∈{r}
对于分类损失,采用sigmoid函数作为预测置信度:
L
c
l
s
c
=
1
N
′
∑
i
=
1
N
1
(
I
o
U
i
>
τ
I
)
L
δ
c
c
and
δ
c
=
∣
σ
(
c
s
)
−
σ
(
c
t
)
∣
\begin{array}{l}\mathcal{L}_{c l s}^{c}=\frac{1}{N^{\prime}} \sum_{i=1}^{N} \mathbb{1}\left(I o U_{i}>\tau_{I}\right) \mathcal{L}_{\delta_{c}}^{c} \\\text { and } \delta_{c}=\left|\sigma\left(c_{s}\right)-\sigma\left(c_{t}\right)\right|\end{array}
Lclsc=N′1∑i=1N1(IoUi>τI)Lδcc and δc=∣σ(cs)−σ(ct)∣
总的损失为:
L
c
o
n
s
=
L
c
l
s
c
+
L
b
o
x
c
\mathcal{L}_{cons}= \mathcal{L}_{c l s}^{c} + \mathcal{L}_{box}^{c}
Lcons=Lclsc+Lboxc
2.3 Orientation-Aware Distance-IoU Loss
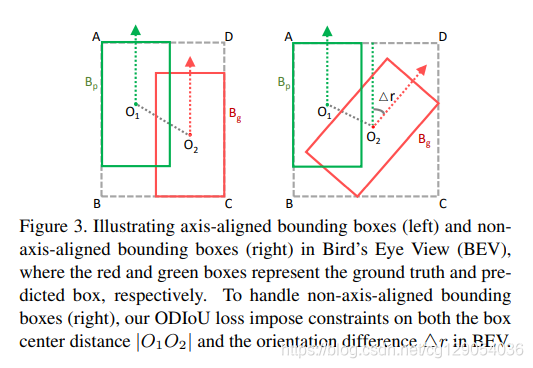
在 hard 目标监督训练中,通常采用 Smooth-L1 损失来约束边界框回归。然而,由于室外场景中的远距离和遮挡,很难从稀疏点云中获得足够信息来精确地预测边界框。为了更好地利用 hard 目标来预测边界框,设计了 方向感知distance-IoU损失(ODIOU),关注边界框中心的对准以及预测和真值边界框之间的方向,如下图所示。
引入预测框与真值框3D中心的约束,以最小化中心不对齐;同时设计了在预测 BEV上的方向约束,进一步减少方向差别问题,本文提出方向距离损IoU损失公式如下:
L
b
o
x
s
=
1
−
IoU
(
B
p
,
B
g
)
+
c
2
d
2
+
γ
(
1
−
∣
cos
(
△
r
)
∣
)
\mathcal{L}_{b o x}^{s}=1-\operatorname{IoU}\left(B_{p}, B_{g}\right)+\frac{c^{2}}{d^{2}}+\gamma(1-|\cos (\triangle r)|)
Lboxs=1−IoU(Bp,Bg)+d2c2+γ(1−∣cos(△r)∣)
对于边界框分类损失,使用 Focal loss;方向分类损失,使用交叉熵损失。student SSD的总损失为:
L
student
=
L
c
l
s
s
+
ω
1
L
box
s
+
ω
2
L
dir
s
+
μ
t
(
L
c
l
s
c
+
L
box
c
)
\mathcal{L}_{\text {student }}=\mathcal{L}_{\mathrm{cls}}^{s}+\omega_{1} \mathcal{L}_{\text {box }}^{s}+\omega_{2} \mathcal{L}_{\text {dir }}^{s}+\mu_{t}\left(\mathcal{L}_{\mathrm{cls}}^{c}+\mathcal{L}_{\text {box }}^{c}\right)
Lstudent =Lclss+ω1Lbox s+ω2Ldir s+μt(Lclsc+Lbox c)
2.4 Shape-Aware Data Augmentation
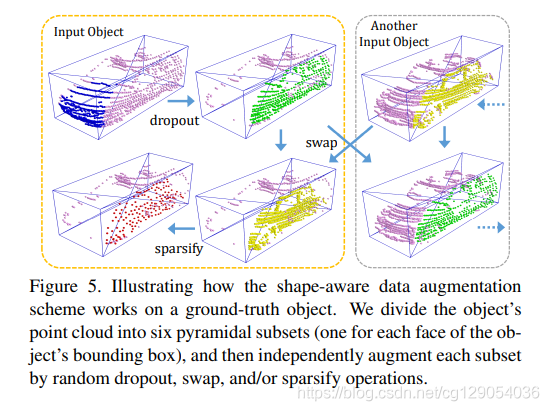
hard目标中的点云在现实中由于遮挡、距离变化和物体形状等因素差异很大。因此,本文设计了形状感知数据增强方案来模仿在数据增强时点云如何受到这些因素的影响。
形状感知数据增强模块是即插即用模块。首先,对于点云中的每个目标,找到它的真值边界框中心,并将中心与顶点连接起来,形成锥体,将目标点分成六个子集。注意到 LiDAR 点主要分布在目标表面,划分就像目标分解,数据增强方案通过操作分解部件,来有效地增强每个目标的点云。
具体而言,使用随机概率 p 1 , p 2 , p 3 p1,p2,p3 p1,p2,p3执行3个操作:
- 在随机选择的金字塔中随机
删掉所有点(如下图左上所示蓝色点),模拟物体被部分遮挡,以帮助网络从剩余的点推断出完整的形状。 - 随机
交换,在当前场景中随机选择一个输入目标,并将点集(绿色)交换到另一个输入目标中的点集(黄色),从而利用目标间的表面相似性来增加目标样本的多样性。 - 使用
最远点采样算法,在随机选择的金字塔中随机采样子样本点,模拟由于LiDAR距离变化引起的点的稀疏变化(下图左下所示)。
除此之外,在形状感知数据增强前,先在输入点云上执行全局转换,包括随机平移、翻转和缩放等。
3. Experiments
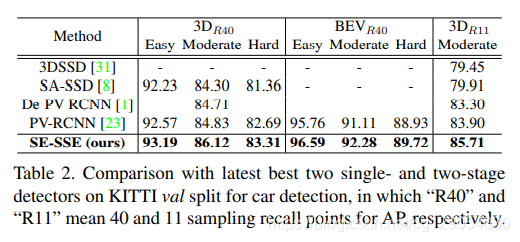
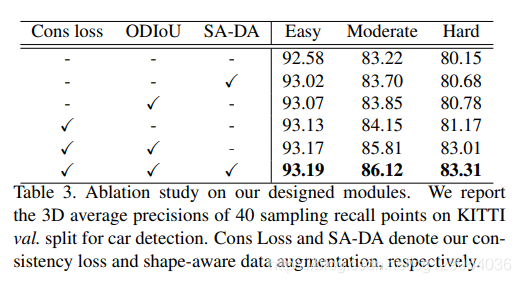
实验部分,作者在 KITTI 数据集上进行了验证,实验细节这里不介绍了,后面可以查看代码和论文,下面几张表是实验结果。
| 测试集对比 | 验证集对比 |
|---|---|
 |  |
| 设计模块对比试验 | 一致性对比试验 | IoU匹配对比试验 |
|---|---|---|
 |  |  |