额外知识点
与np.array()方法不同的是Series和DataFrame创建是带标签的数组。而np.array()方法仅仅是创建数组,但是你可以利用np.array()方法创建一个数组以及一个标签数组来类比pandas库中的Series和DataFrame。但是np.array()方法只能创建数据类型相同的数组,而Series和DataFrame则不用注意这一点。
统计的基本概念
- 总体:研究对象的全体–eg:所有学生的身高、成绩和体重等
- 个体:总体中的每一个成员–eg:单个同学的身高、成绩
- 样本:从总体中抽出部分个体组成的集合 样本容量:样本中所含个体的数目
常用统计量含义
- 均值:样本(一组数据)的算术平均值,反应数据的集中趋势
- 方差:描述一组数据的离散程度或样本个体距离均值的分散程度
- 频率:频数与样本容量的比值
- 众数:样本中出现次数最多的值,若所有值出现的次数一样多则认为样本没有众数
- 分位数:将一个随机变量的概率分布范围分为几个等份的数值点
(1)中位数:样本容量为奇数时,处在中间的数,否则为最中间两个数的平均值
(2)四分位数:将样本从小到大排列后分为4等份,处于3个分割点位置的数值即为所 求。
pandas数据结构–Series 、DataFrame
使用前需要导入库:
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
Series------一维数据 由索引(index)和值(values)两个相关联的数组组成 Series([values, index, …]) values:为列表或由np.array()创建的一维ndarray对象
index:列表,若省略则自动生成0~n-1的序号标签索引
DataFrame—二维数据和高维数据
Series------一维数据
创建方式:
方式1:借助numpy函数创建一维数组
import numpy as np
import pandas as pd
from pandas import Series
data= Series(np.arange(0,5), index=['13', '14', '7', '2','9']
方式2:
height= Series([187, 190, 185, 178, 185], index=['13', '14', '7', '2','9'])
方式3:用字典创建Series,将字典的键(key)作为索引
height= Series({'13':187,'14':190,'7':185,'2':178,'9':185})
Series数据选取
索引名选取:
obj[index]—选取某个值—只显示索引对应的值,不显示索引
obj[indexList]—选取多个值–索引和值均显示 若索引名为数字则(详细理解请看索引修改处的例子):
obj.loc[a:b]—选取a~b行的值 obj.loc[[indexList]]
基于位置(下标)选取:
obj[loc]—选取某个值—只显示该位置下标对应的值,不显示索引
obj[locList]—选取多个值—索引和值均显示obj[a:b]—选取位置a~(b-1)的值—索引和值均显示
条件筛选:
obj[condition]—选取满足条件表达式的值
import pandas as pd
from pandas import Series
height= Series([187, 190, 185, 178, 185], index=['13', '14', '7', '2','9'])
height
#索引名选取
a0= height['13']
a1=height[['13','7']]
#位置选取
a2=height[2]
a3=height[[0,1,3]]
a4=height[1:3]
#条件筛选(布尔型)
a5=height[height.values>=186]
print("{}\n{}\n{}\n{}\n{}\n{}\n".format(a0,a1,a2,a3,a4,a5))
>>> 187
13 187
7 185
dtype: int64
185
13 187
14 190
2 178
dtype: int64
14 190
7 185
dtype: int64
13 187
14 190
dtype: int64
Series数据修改
基于索引名修改:
obj[index]=修改值—选取某个值—只显示索引对应的值,不显示索引
obj[indexList]=修改值/修改值列表—选取多个值–索引和值均显示
基于位置修改:
obj[loc]=修改值—选取某个值—只显示该位置下标对应的值,不显示索引
obj[locList]=修改值/修改值列表—选取多个值—索引和值均显示
obj[a:b]=修改值/修改值列表—选取位置a~(b-1)的值—索引和值均显示
基于条件修改:
obj[condition]=修改值—选取满足条件表达式的值
height
>>> 13 187
14 190
7 185
2 178
9 185
dtype: int64
height['13']= 188
height
>>> 13 188
14 190
7 185
2 178
9 185
dtype: int64
height[1:3]=160
height
>>> 13 188
14 160
7 160
2 178
9 185
dtype: int64
height[1:3]=[155,165]
height
>>> 13 188
14 155
7 165
2 178
9 185
dtype: int64
Series索引修改
Series对象创建后,值可以修改,索引也修改,索引用新的列表替换即可
obj.index=indexList
当索引均为数字的形式–此时基于位置序号访问需要使用
iloc方式,基于索引访问需要使用loc方式,当不加loc或iloc时将按照索引的方式查询,但当索引均为字符串的形式时可以不加loc和iloc,例子如下:
height
>>> 13 188
14 155
7 165
2 178
9 185
dtype: int64
#更改一维标签数组索引
height.index=[1,2,3,4,5]
height
>>> 1 188
2 155
3 165
4 178
5 185
dtype: int64
#基于索引选取
aa0= height.loc[2]#基于索引选取
aa1= height.loc[[2,4]]#基于索引列表选取
aa2= height[[3,5]]#基于索引列表选取
aa3= height.loc[2:4]
print("{}\n{}\n{}\n{}\n".format(aa0, aa1, aa2, aa3))
>>>
190
dtype: int64
2 155
4 178
dtype: int64
3 165
5 185
dtype: int64
2 155
3 165
4 178
dtype: int64
#基于位置选取
bb0= height.iloc[1]#基于位置选取
bb1= height.iloc[[1,3]]#基于位置列表选取
bb2= height.iloc[1:4]#基于位置列表选取
print("{}\n{}\n{}\n".format(bb0,bb1,bb2))
>>>
188
dtype: int64
2 155
4 178
dtype: int64
2 155
3 1
4 178
dtype: int64
Series数据添加–最好利用append()函数拼接
方式1:
obj.append(obj1)------推荐
方式2:obj[index]=value
#方式1:
#obj.append(a)---出现在第一次课List相关方法中
#注意:append()函数不改变原Series,即height的元素及索引还是原来的内容,
#所以需要将拼接后的Series给new
a= Series([190,187], index=['23','5'])
new=height.append(a)
new
>>> 13 188
14 155
7 165
2 178
9 185
23 190
5 187
dtype: int64
height.append(Series([2],index=['1']))
height
>>> 13 188
14 155
7 165
2 178
9 185
dtype: int64
#方式2:
height['6']=75
height
>>> 13 188
14 155
7 165
2 178
9 185
6 75
dtype: int64
Series数据删除
方式1:基于索引删除
obj.drop(index,inplace,...)
obj.drop(indexList,inplace,...)
inplace=True 直接覆盖,将原Series的内容变为更改后的内容
方式2:基于位置删除—index出现在第一次课Tuple和List的相关函数中
obj.drop(obj.index[loc])或
obj.drop(obj.index[locList])或
obj.drop(obj.index[a:b])
import pandas as pd
from pandas import Series, DataFrame
height = Series([187, 190, 185, 178, 185], index=['13', '14', '7', '2','9'])
height
>>>
13 187
14 190
7 185
2 178
9 185
dtype: int64
基于索引删除
a1 = height.drop('13')
a2 = height.drop(['13','14'])
print("{}\n{}\n".format(a1,a2))
>>>
14 190
7 185
2 178
9 185
dtype: int64
7 185
2 178
9 185
dtype: int64
height.index = [1,2,3,4,5]#更改索引名
height
>>>
1 187
2 190
3 185
4 178
5 185
dtype: int64
a3 = height.drop(1)
a4 = height.drop([1,2])
print("{}\n{}\n".format(a3,a4))
>>>
2 190
3 185
4 178
5 185
dtype: int64
3 185
4 178
5 185
dtype: int64
基于位置删除
#基于位置删除
b1 = height.drop(height.index[1])#删除位置下标为1的元素
b2 = height.drop(height.index[[1,2]])#删除位置下标为1和2的元素
b3= height.drop(height.index[0:3])#删除位置下标为0,1,2的元素
print("{}\n{}\n{}\n".format(b1,b2,b3))
>>>
1 187
3 185
4 178
5 185
dtype: int64
1 187
4 178
5 185
dtype: int64
4 178
5 185
dtype: int64
思考与练习1

import pandas as pd
from pandas import Series
data=Series([30, 25, 27, 41, 25, 34], index= ['a', 'b', 'c', 'd', 'e', 'f'])
data
>>> a 30
b 25
c 27
d 41
e 25
f 34
dtype: int64
'''
添加数据方式1:
a=Series([27], index= ['g'])
new= data.append(a)
new
'''
#添加数据方式2:
data['g']= 27
data
>>> a 30
b 25
c 27
d 41
e 25
f 34
g 27
dtype: int64
data[data.values>27]
>>> a 30
d 40
f 34
dtype: int64
data.drop(data.index[1:4], inplace= True)
data
>>> a 30
e 25
f 34
g 27
dtype: int64
DataFrame—二维数据
- DataFrame包括values、index(行索引)、columns(列索引)三部分
- DataFrame(values, index=[…], columns=[…])
values:列表或由numpy生成的二维ndarray对象
index、columns:列表,若省略则自动生成0~n-1的序号标签
import pandas as pd
from pandas import DataFrame
data0= [[19, 170, 68], [20, 165, 65], [18, 175, 65]]
students= DataFrame(data0, index= [1, 2 ,3], columns= ['age', 'height', 'weight'])
students
>>>
age height weight
1 19 170 68
2 20 165 65
3 18 175 65
DataFrame数据选取
- 索引名选取:
obj[col]------选取某列 obj[colList]—选取某几列
obj.loc[index,clo]—选取某行某列
obj.loc[indexList,colList]—选取多行多列
若index和columns索引均为数字:
obj.loc[a:b,c:d]—选取a~~b行,c~d列
obj.loc[indexList, colList]
- 基于位置序号选取:
obj[a:b]—选取a~b-1行的所有列,列的“:”可以省略
obj.iloc[iloc,cloc]—选取某行某列
obj.iloc[ilocList,clocList]—选取多行多列
obj.iloc[a:b,c:d]—选取a~~b-1行,c~d-1列
- 基于条件筛选:
obj.loc[condition,colList]—使用索引构造条件表达式,选取满足条件的行
obj.iloc[condition,clocList]—使用位置序号构造条件表达式,选取满足条件的行(根据位置序号筛选暂时无例子)
c= students[['height', 'weight']]#查询所有同学的身高和体重
#等同于students.loc[:, ['height', 'weight']]
c0= students.loc[1, 'age']#查询1号同学的年龄
c1= students.loc[[1, 3], ['height', 'weight']] #查询1、3号同学的身高和体重
c2= students.iloc[[0, 2], [0, 1]]#查询第0、2行的第0、1列的值
print("{}\n{}\n{}\n{}\n".format(c, c0, c1, c2))
>>>
height weight
1 170 68
2 165 65
3 175 65
19
height weight
1 170 68
3 175 65
age height
1 19 170
3 18 175
students[0:2]#等同于students.iloc[0:2]或students.iloc[0:2,:]
>>>
age height weight
1 19 170 68
2 20 165 65
students.columns=[4,5,6]
students
>>>
4 5 6
1 19 170 68
2 20 165 65
3 18 175 65
students.loc[1:3,4:5]#基于索引选取(索引均为数字)
>>>
4 5
1 19 170
2 20 165
3 18 175
students.iloc[1:3,0:2]#基于位置选取
>>>
4 5
2 20 165
3 18 175
#筛选身高大于168的同学,显示其身高和体重值
students.loc[students.loc[:,'height']>=168]
#等同于students.loc[students['height']>=168]
>>>
1 19
3 18
Name: age, dtype: int64
#筛选身高大于168的同学,显示其身高
students.loc[students['height']>=168,'height']
>>>
1 170
3 175
Name: height, dtype: int64
DataFrame数据修改
- 基于索引名修改:
obj[col]=修改值
obj[colList]=修改值/修改值列表—选取某几列
obj.loc[index,clo]=修改值—选取某行某列
obj.loc[indexList,colList]=修改值/修改值列表—选取多行多列
若index和columns索引均为数字:
obj.loc[a:b,c:d]=修改值/修改值列表—选取ab行,cd列
obj.loc[indexList, colList]=修改值/修改值列表
- 基于位置序号修改:
obj[a:b]=修改值/修改值列表—选取a~b-1行的所有列,列的:可以省略
obj.iloc[iloc,cloc]=修改值—选取某行某列
obj.iloc[ilocList,clocList]=修改值/修改值列表—选取多行多列
obj.iloc[a:b,c:d]=修改值/修改值列表—选取ab-1行,cd-1列
- 基于条件筛选修改:
obj.loc[condition,colList]=修改值/修改值列表—使用索引构造条件表达式
obj.iloc[condition,clocList]=修改值/修改值列表—使用位置序号构造条件表达式
修改DataFrame中的大于m的所有元素:
obj[obj >m]=修改值 ===obj[obj.values > m]= 修改值
students
>>>
age height weight
1 19 170 68
2 20 165 65
3 18 175 65
students.loc[1,'age']=95
students
>>>
age height weight
1 95 170 68
2 20 165 65
3 18 175 65
students.loc[1,:]=[21, 180, 70, 20]
students
>>>
age height weight expense
1 21 180 70 20
2 20 165 65 1000
3 18 175 65 1000
DataFrame索引修改
df.index=[…] 修改行索引
df.columns=[…] 修改列索引
students.index=[4,5,6]
students.columns=['qwe', 'asd', 'zxc']
students
>>>
qwe asd zxc
4 95 170 68
5 20 165 65
6 18 175 65
students.index=[1,2,3]
students.columns=['age', 'height', 'weight']
students
>>>
age height weight
1 95 170 68
2 20 165 65
3 18 175 65
DataFrame数据添加
- 若列索引标签不存在则添加新列,反之则为修改该列索引所在列的值
- DataFrame对象可以添加新的列,但不能直接添加新的行,增加行需要通过两个DataFrame对象的合并实现—即:
import pandas as pd
newstu = pd.concat([obj1,obj2], axis=0)–将obj2的所有行合并到obj1中
详见本章数据规整化数据合并的内容
students
>>>
age height weight
1 19 170 68
2 20 165 65
3 18 175 65
students['expense']=[1500, 1600, 1200]
students
>>>
age height weight expense
1 19 170 68 1500
2 20 165 65 1600
3 18 175 65 1200
students['expense']=[200,1000,1000]
students
>>>
age height weight expense
1 19 170 68 200
2 20 165 65 1000
3 18 175 65 1000
students.loc[students['expense']<500,'expense']= 1200
students
>>>
age height weight expense
1 19 170 68 1200
2 20 165 65 1000
3 18 175 65 1000
DataFrame数据删除
- 基于索引删除:
- 删除行:
obj.drop(index,axis,inplace,…)
obj.drop(indexList,axis,inplace,…)
obj.drop(obj.index[a:b],axis=0)===obj.drop(obj.index[ilocList],axis=0)- 删除列:
obj.drop(columns,axis,inplace,…)
obj.drop(colList,axis,inplace,…)
obj.drop(obj.columns[a:b],axis=1)===obj.drop(obj.columns[[cloList]],axis=1)
#删除行
students.drop(1,axis=0)
>>>
age height weight expense
2 20 165 65 1000
3 18 175 65 1000
#删除多行
students.drop([1,2], axis=0)
>>>
age height weight expense
3 18 175 65 1000
#删除列
students.drop('age',axis=1)
>>>
height weight expense
1 170 68 1200
2 165 65 1000
3 175 65 1000
students.drop(students.index[[0,1]],axis= 0)
>>>
age height weight expense
3 18 175 65 1000
课后练习1

import pandas as pd
from pandas import DataFrame
import numpy as np
data0= DataFrame(np.arange(1,10).reshape(3,3), index= ['a', 'b', 'c'], columns= ['one', 'two', 'three'])
data0
>>>
one two three
a 1 2 3
b 4 5 6
c 7 8 9
data0[['one', 'two']]
>>>
one two
a 1 2
b 4 5
c 7 8
data0.iloc[[0,2], [0,2]]
>>>
one three
a 1 3
c 7 9
data1= data0.loc[data0['one'] > 2]
data1
>>>
one two three
b 4 5 6
c 7 8 9
data1['four']= 10
data1
>>>
one two three four
b 4 5 6 10
c 7 8 9 10
data1[data1.values > 9]= 8#等同于data1[data1 > 9]= 8
data1
>>>
one two three four
b 4 5 6 8
c 7 8 9 8
data1.drop(data1.index[0:2],axis= 0)
>>>
one two three four
数据文件的读写—基于pandas库
pandas支持多种格式的数据导入和导出
CSV TXT Excel HTML等文件格式
MySQL SQLServer等数据库格式
JSON等Web API数据交换格式
读取CSV文件
pd.read_csv(file,sep=‘,’,header=‘infer’, index_col=None, names=None,skiprows,nrows…)
参数已经写上的代表是默认值eg:header=‘infer’
- file:字符串(意思就是加上单引号的内容),文件路径及文件名
- sep:字符串,各行数据之间的分隔符,默认为‘,’。具体请详见文本文件的读取
- nrows:读取数据的行数
注意:只有在obj.to_csv()保存文件的函数中,参数header才有header=True
- header:
‘infer’—系统自动默认推断列索引
None—知名文件中不包括列索引,列索引名可由name给出
int整型–如header=0文件的数据中位置下标为0的那一行为列索引;
list of int—整数列表- index_col:数字,用作行索引的列
index_col=0 文件中的数据的位置下标为0的那一列为数据的行索引- names:列表,定义列索引,默认文件中第一行是列索引
- skiprows:整数或列表,需要忽略的行数或需要跳过的行号列表
文件内数据读取
data=pd.read_csv(‘E:\data\student1.csv’, index_col=0)
data[-a:]—显示最后a行数据
data[:a]—显示前a行数据
data[a:b]—显示第(a+1)~b行数据
data[-a:-b]—显示倒数第a行至倒数第b+1行数据
import pandas as pd
#读取文件,并以文件中位置下标为0的那一列作为行索引
qwe=pd.read_csv('E:\data\student1.csv', index_col=0,header= 'infer')
a0= qwe[-3:]#读取文件中的最后三行数据
qwe[-4:]#读取最后4行数据
>>>
性别 年龄 身高 体重 省份 成绩
序号
2 male 22 180 71 GuangXi 77
3 male 22 180 62 FuJian 57
4 male 20 177 72 LiaoNing 79
5 male 20 172 74 ShanDong 91
特殊csv文件读取
pd.read_table((file,sep=‘,’,header=‘infer’,index_col=None,names=None,skiprows,nrows…))
适用于.csv文件的每行的内容数据均在一个方格内,如下所示:
执行代码:
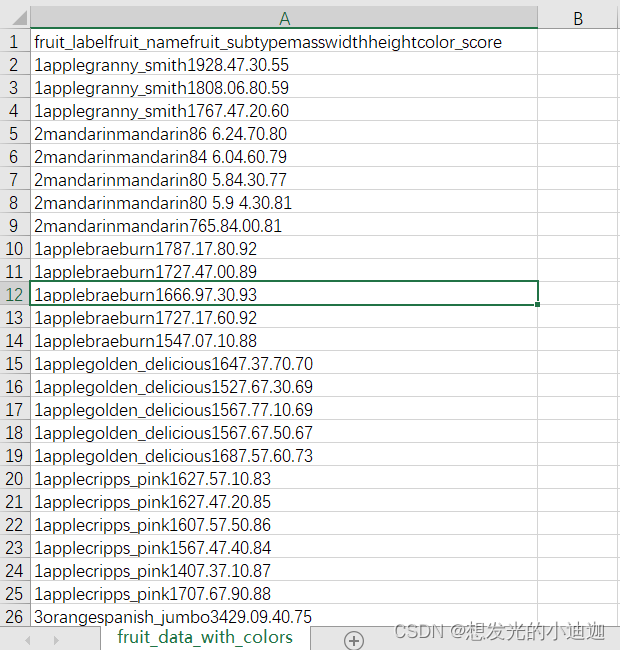
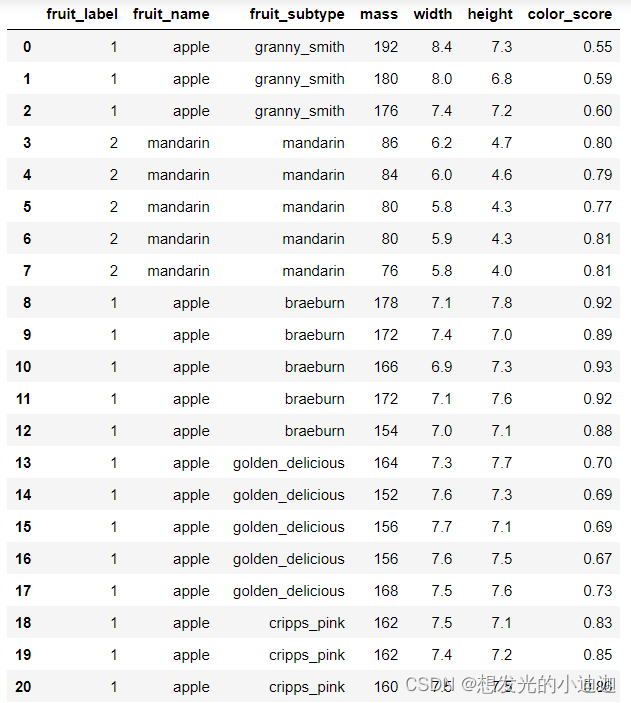
fruit_data= pd.read_table(r'E:\fruit_data_with_colors.csv')
(display)fruit_data
运行结果显示为:
保存CSV文件
obj.to_csv(file,sep,mode,index,header,…)
- file:保存的路径及文件名
sep:分隔符,默认为’,’
mode:导出模式,w为导出到新文件,a为将需要保存的文件数据追加到现有文件数据的最后 mode=‘w’ mode=‘a’
index:是否导出文件数据自带的行索引,默认为True,若为False则系统自动匹配行索引
header:是否导出文件数据自带的列索引,默认为True,若为False则系统自动匹 配列索引注意:mode='a’将文件数据追加到另一个文件中时,必须保证另一个文件是未被打开的状态,否则会报错
import pandas as pd
from pandas import DataFrame, Series
data = [[19,68,170],[20,65,165],[18,65,175]]
students =DataFrame( data,index=[1,2,3],columns=['age','weight','height'] )
#将.csv文件保存到在E盘新创建的qwe.csv文件中
students.to_csv('E:\qwe.csv',mode= 'w')
#将.csv文件追加到qwe.csv文件的末尾
students.to_csv('E:\qwe.csv',mode= 'a')
读取文本文件
pd.read_csv(file,sep=‘,’,header=‘infer’, index_col=None, names=None,skiprows,…)
与读取CSV文件一样,都是利用该函数
不是以逗号隔开的文本文件,读取时需要设置分隔参数sep
分隔符既可以是指定字符串,也可以是正则表达式
常用的通配符如下:
\s------空格等空白字符
\S------非空白字符
\t------制表符
\n------换行符
\d------数字
\D------非数字字符
当.txt文件内容是按表格形式编排的,且该文件内容之间不是以逗号隔开,此时就
可以加上sep='\t’将.txt文件变为以表格形式呈现出其内容,详情请见例子
colNames= ['性别', '年龄', '身高', '体重', '省份', '成绩']
student=pd.read_csv('E:\data\student2.txt', sep= '\t', header= None, index_col=0, names=colNames)
student
>>>
性别 年龄 身高 体重 省份 成绩
1 male 20 170 70 LiaoNing 71.0
2 male 22 180 71 GuangXi NaN
3 male 22 180 62 FuJian 57.0
4 male 20 177 72 LiaoNing 79.0
5 male 20 172 74 ShanDong 91.0
读取Excel文件
pd.read_excel(file, sheetname,index_col, header,names,skiprows,…)—与pd.read_csv()函数内的参数相同
读取Excel文件中也无header= True
注意:从Excel文件中读取数据的函数类似CSV文件,需要给出数据所在的Sheet表单名即sheetname
student1=pd.read_excel('E:\data\student3.xlsx', 'Group1', index_col=0, skiprows=3, header= 'infer')
读取xml文件(特殊)
import xml.etree.ElementTree as ET------导入相应的包
tree= ET.parse(xmlFile_path)------xml文件读取
root = tree.getroot() # 获取根节点
相关例子详见文本数据处理–>朴素贝叶斯模型–>实例:新闻分类(2)
思考与练习2

#第1题:
import pandas as pd
from pandas import DataFrame
import numpy as np
data5=DataFrame(np.random.randint(10,100,(50,7)), columns=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
data5.to_csv('E:\qwe.csv', mode='w')
#第2题
import pandas as pd
from pandas import DataFrame
colNames=['flymiles', 'videogame', 'icecream', 'type']
data0= pd.read_excel('E:\data\datingTestSet.xls', skiprows= 2, header= None, names=colNames )
#以下代码省略运行结果展示
data0[:5]
data0[data0['type']== 'largeDoses']
data0[data0['videogame'] > 10]= 10
data0
数据文件的清洗
数据滤除
obj.dropna(axis, how, thresh,…)
obj.dropna() 参数缺省则为删除含有缺失值的行
axis= 0 按行滤除 axis=1 按列滤除 默认为axis= 0
how=‘all’ 滤除全部值均为NaN的行或列
thresh 只留下有效数据大于或等于thresh值的行或列
import pandas as pd
stu= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group1', index_col=0)
stu.dropna()#删除带有缺失值的行
stu.dropna(thresh= 8)#保留有效数据大于等于8的行
缺失数据列监测
若any函数缺失则会以表的形式显示检测中是否存在NaN,得到布尔型DataFrame对象,详见例子
stu.isnull().any()------以每个列标签为基本单位查找列标签所在列是否有空值
stu.isnull().any()
>>>
性别 False
年龄 True
身高 False
体重 True
省份 False
成绩 True
月生活费 True
课程兴趣 False
案例教学 False
dtype: bool
stu.isnull()------查看表格的每个数据是否有空值
stu.isnull()
>>>
性别 年龄 身高 体重 省份 成绩 月生活费 课程兴趣 案例教学
序号
1 False False False False False True False False False
2 False False False False False False False False False
3 False True False False False False False False False
4 False False False False False False False False False
5 False False False True False False True False False
6 False False False False False False False False False
7 False False False False False False False False False
8 False False False False False False False False False
9 False False False False False False False False False
10 False False False False False False False False False
数据去重
obj.drop_duplicates(inplace,…)
将完全相同的两行或多行数据删除至一行
stu0 = pd.read_excel('E:\data\studentsInfo.xlsx','Group1',index_col=0)
stu0.drop_duplicates()#序号为9的那一行被删除
数据填充
obj.fillna (value, method, inplace…)
value 填充值,可以是标量、字典、Series、DataFrame
method= ‘ffill’:同列前一行数据填充缺失值
method= ‘bfill’:用同列后一行数据填充缺失值
inplace 是否修改原始数据的值,默认为False,产生一个新的数据对象
以上三个参数均是产生新的数据对象,原始数据不会被修改,除非加上inplace=True
注意: obj.fillna(a)即缺失数据全部填充为a
obj.fillna(0)------缺失数据全部填充为0
- 数据填充四种方式:
(1)用默认值填充
(2)用已有数据的平均值/中位数填充
(3)用NaN填充整列或整行–需导入numpy库 eg: obj[col]= np.nan
(4)列填充:构造{‘列索引名’:值}形式的字典对象作为实际参数,详见例子
#年龄用默认值20填充,体重用平均值填充
stu.fillna({'年龄':20, '体重':stu['体重'].mean()})
#用同列的前一行填充
stu.fillna(method='ffill')
思考与练习3

import pandas as pd
from pandas import DataFrame
import numpy as np
#第1题:
data= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group1')
data['案例教学']=np.nan
data.dropna(thresh= 8 ,axis=0)
data.dropna(how='all', axis= 1, inplace= True)
#第2题:
data.fillna({'体重': data['体重'].mean(), '成绩': data['成绩'].mean()}, inplace= True)
data['年龄'].fillna(method= 'ffill', inplace= True)
data.fillna({'月生活费': data['月生活费'].median()}, inplace= True)
数据规整化
数据合并
行数据追加
将两个完全相同的表合并到一块
pd.concat([obj1, obj2], axis= 0 )
将obj2的所有行追加到obj1的最后
注意: pd.concat()也可以进行列数据追加,详见列数据连接—>注意。
import pandas as pd
from pandas import DataFrame
colName = ['学号','姓名','专业']
data1 = [ ['202003101','赵成','软件工程'], ['202005114','李斌丽','机械制造'], ['202009111','孙武一','工业设计'] ]
stu1 = DataFrame( data1, columns=colName )
data2 = [['202003103','王芳','软件工程'], ['202005116','袁一凡','工业设计']]
stu2 = DataFrame( data2, columns=colName )
print(stu1,stu2)
>>>
学号 姓名 专业
0 202003101 赵成 软件工程
1 202005114 李斌丽 机械制造
2 202009111 孙武一 工业设计
学号 姓名 专业
0 202003103 王芳 软件工程
1 202005116 袁一凡 工业设计
newstu= pd.concat([stu1, stu2], axis= 0)
newstu
>>>
学号 姓名 专业
0 202003101 赵成 软件工程
1 202005114 李斌丽 机械制造
2 202009111 孙武一 工业设计
0 202003103 王芳 软件工程
1 202005116 袁一凡 工业设计
列数据链接
方式1
pd.merge(x, y, how, left_on, right_on,…)
- x 左数据对象
- y 右数据对象
- how 数据对象连接的方式,‘inner’ ‘outer’ ‘left’ ‘right’
默认为how= 'inner’内连接inner 内连接,拼接两个数据对象中键值交集的行,其余忽略
outer 外连接,拼接两个数据对象中键值并集的行
left 左连接,取出x的全部行,拼接y中匹配的键值行
right 右连接,取出y的全部行,拼接x中匹配的键值行
其中’outer’ ‘left’ ‘right’:当某列数据不存在则自动填充为NaN
- left_on 左数据对象用于连接的键
- right_on 右数据对象用于连接的键
import pandas as pd
from pandas import DataFrame
cardcol=['ID', '刷卡地点', '刷卡时间', '消费金额']
data3=[['202003101','一食堂','20180305 1145',14.2], ['104574','教育超市','20180307 1730',25.2],['202003103','图书馆','20180311 1823'],['202005116','图书馆','20180312 0832'],['202005114','二食堂','20180312 1708',12.5],['202003101','图书馆','20180314 1345']]
card= DataFrame(data3, columns= cardcol)
#下标为2的消费金额为NaN的原因是['202003103','图书馆','20180311 1823']列表未列入消费金额
print(card, newstu)#newstu是行数据追加中所生成的表
>>>
ID 刷卡地点 刷卡时间 消费金额
0 202003101 一食堂 20180305 1145 14.2
1 104574 教育超市 20180307 1730 25.2
2 202003103 图书馆 20180311 1823 NaN
3 202005116 图书馆 20180312 0832 NaN
4 202005114 二食堂 20180312 1708 12.5
5 202003101 图书馆 20180314 1345 NaN
学号 姓名 专业
0 202003101 赵成 软件工程
1 202005114 李斌丽 机械制造
2 202009111 孙武一 工业设计
0 202003103 王芳 软件工程
1 202005116 袁一凡 工业设计
将card与newstu列合并
#left_on= '学号', right_on= 'ID' 即:合并到一起
#x表中学号与y表中ID相同的行合并为一行
#how= 'left'---以x表为基准,将右对象的表都拼接到左对象表中,缺失部分用NaN填补
#x= newstu, left_on= '学号',所以含有学号的newstu表在前,card在后
pd.merge(newstu, card, how= 'left', left_on= '学号', right_on= 'ID')
>>>
学号 姓名 专业 ID 刷卡地点 刷卡时间 消费金额
0 202003101 赵成 软件工程 202003101 一食堂 20180305 1145 14.2
1 202003101 赵成 软件工程 202003101 图书馆 20180314 1345 NaN
2 202005114 李斌丽 机械制造 202005114 二食堂 20180312 1708 12.5
3 202009111 孙武一 工业设计 NaN NaN NaN NaN
4 202003103 王芳 软件工程 202003103 图书馆 20180311 1823 NaN
5 202005116 袁一凡 工业设计 202005116 图书馆 20180312 0832 NaN
#x= card, left_on= 'ID',所以含有ID的card表在前,newstu表在后
pd.merge(card, newstu,how= 'left', left_on= 'ID', right_on= '学号')
>>>
ID 刷卡地点 刷卡时间 消费金额 学号 姓名 专业
0 202003101 一食堂 20180305 1145 14.2 202003101 赵成 软件工程
1 104574 教育超市 20180307 1730 25.2 NaN NaN NaN
2 202003103 图书馆 20180311 1823 NaN 202003103 王芳 软件工程
3 202005116 图书馆 20180312 0832 NaN 202005116 袁一凡 工业设计
4 202005114 二食堂 20180312 1708 12.5 202005114 李斌丽 机械制造
5 202003101 图书馆 20180314 1345 NaN 202003101 赵成 软件工程
pd.merge(newstu, card, how= 'right', left_on= '学号', right_on= 'ID')
>>>
学号 姓名 专业 ID 刷卡地点 刷卡时间 消费金额
0 202003101 赵成 软件工程 202003101 一食堂 20180305 1145 14.2
1 NaN NaN NaN 104574 教育超市 20180307 1730 25.2
2 202003103 王芳 软件工程 202003103 图书馆 20180311 1823 NaN
3 202005116 袁一凡 工业设计 202005116 图书馆 20180312 0832 NaN
4 202005114 李斌丽 机械制造 202005114 二食堂 20180312 1708 12.5
5 202003101 赵成 软件工程 202003101 图书馆 20180314 1345 NaN
#how= 'inner'取两表的交集合并
pd.merge(newstu, card, how= 'inner', left_on= '学号', right_on= 'ID')
>>>
学号 姓名 专业 ID 刷卡地点 刷卡时间 消费金额
0 202003101 赵成 软件工程 202003101 一食堂 20180305 1145 14.2
1 202003101 赵成 软件工程 202003101 图书馆 20180314 1345 NaN
2 202005114 李斌丽 机械制造 202005114 二食堂 20180312 1708 12.5
3 202003103 王芳 软件工程 202003103 图书馆 20180311 1823 NaN
4 202005116 袁一凡 工业设计 202005116 图书馆 20180312 0832 NaN
#how= 'outer'取两表的并集合并
pd.merge(newstu, card, how= 'outer', left_on= '学号', right_on= 'ID')
>>>
学号 姓名 专业 ID 刷卡地点 刷卡时间 消费金额
0 202003101 赵成 软件工程 202003101 一食堂 20180305 1145 14.2
1 202003101 赵成 软件工程 202003101 图书馆 20180314 1345 NaN
2 202005114 李斌丽 机械制造 202005114 二食堂 20180312 1708 12.5
3 202009111 孙武一 工业设计 NaN NaN NaN NaN
4 202003103 王芳 软件工程 202003103 图书馆 20180311 1823 NaN
5 202005116 袁一凡 工业设计 202005116 图书馆 20180312 0832 NaN
6 NaN NaN NaN 104574 教育超市 20180307 1730 25.2
方式2
只能用于表的列数据链接,不是表则可以使用pd.concat([obj1, obj2], axis= 1 )来进行列数据的链接。如下:
例1:grouped1、grouped2不是表,如下:
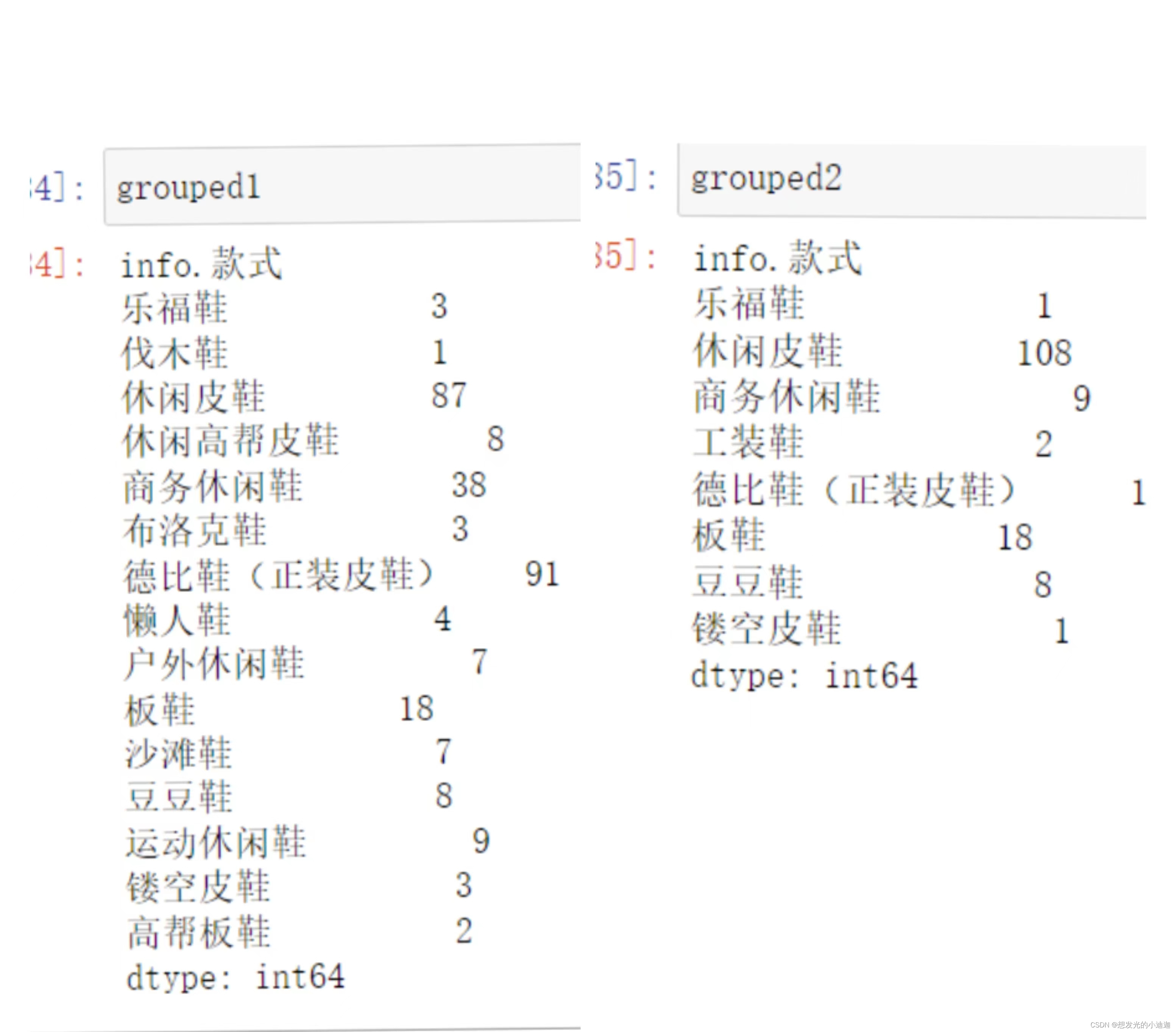
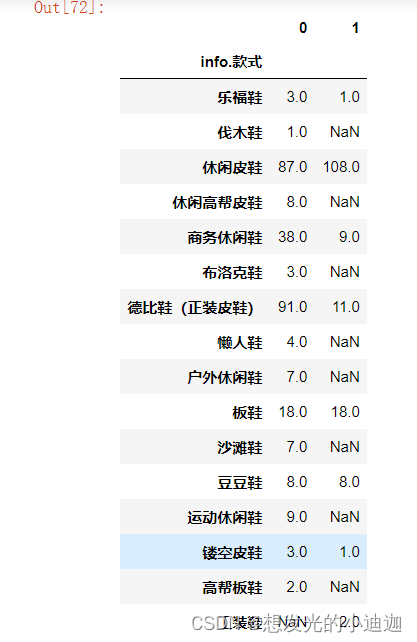
#将grouped2的列追加到grouped1上形成表,空值款式设为0
pd.concat(['grouped1', 'grouped2'], axis= 1 ).fillna(0)
运行结果显示为:
例2:将两个表name1、name2的列合并到一起,name1、name2如下:
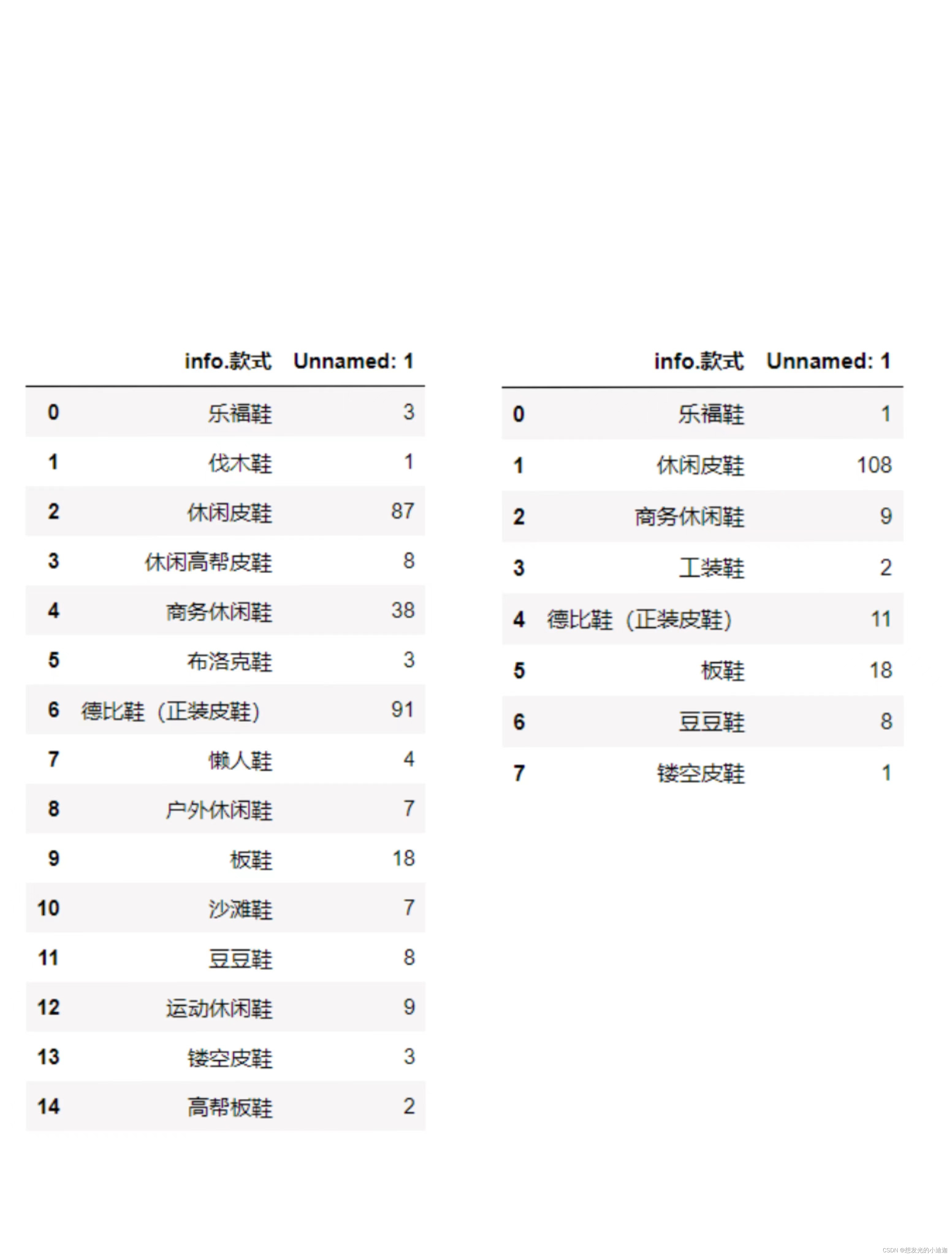
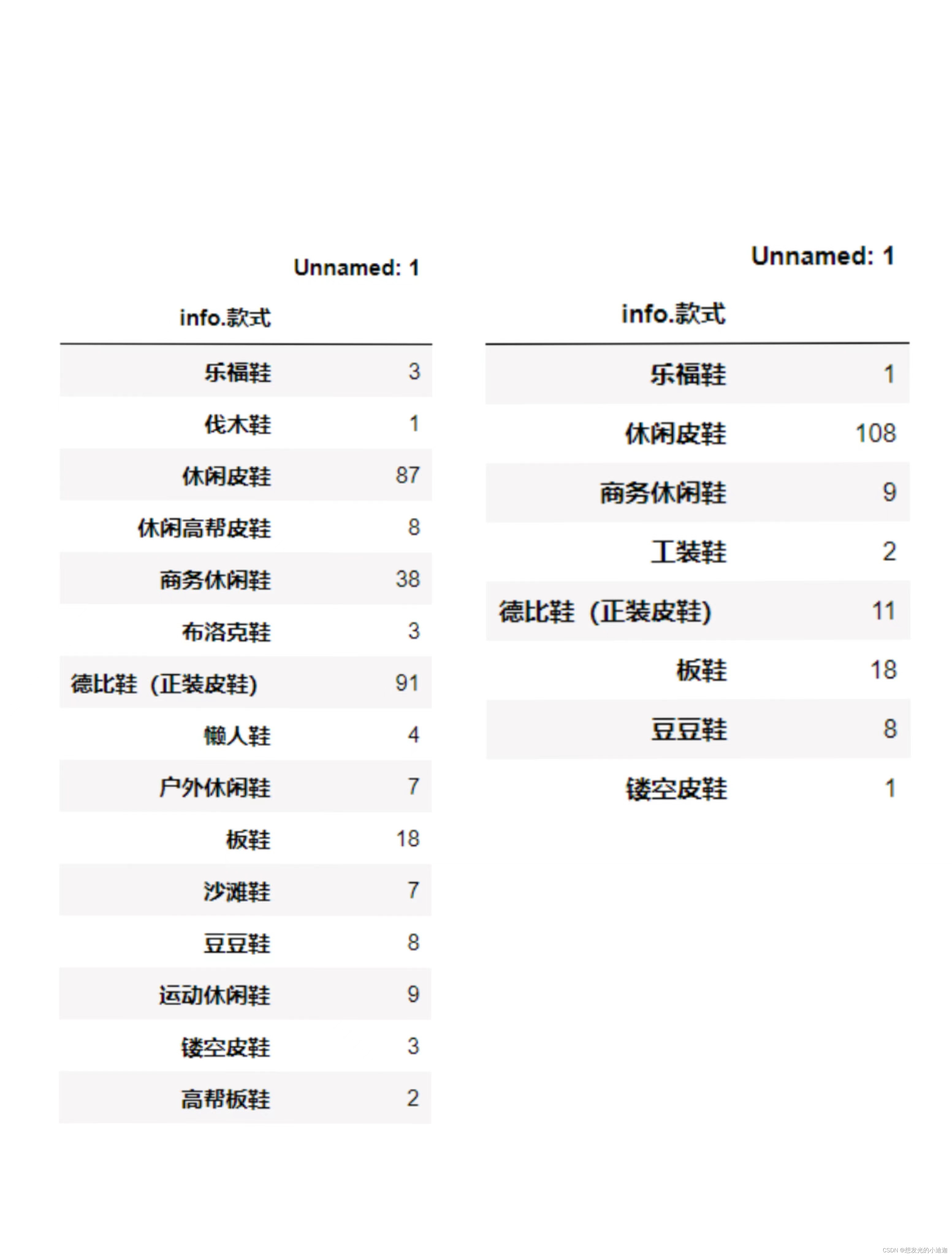
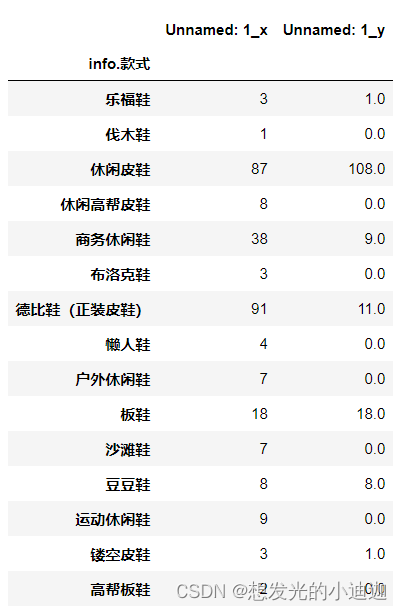
pd.merge(name1, name2, left_on= 'info.款式', right_on= 'info.款式', how= 'left').fillna(0)
运行结果显示为:
方式3
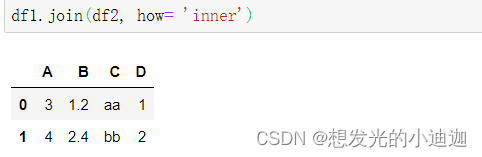
df1.join(df2, how)
df1 = pd.DataFrame({'A': [3, 4, 8, 9], 'B': [1.2, 2.4, 4.5, 7.3], 'C': ["aa", "bb", "cc", "dd"]})
df2 = pd.DataFrame({'D': [1, 2]})
print(df1)
print(df2)
运行结果显示为:

df1.join(df2, how= 'inner')
运行结果显示为:
df1.join(df2, how= 'outer')
运行结果显示为:

df1.join(df2, how= 'left')
运行结果显示为:

df1.join(df2, how= 'right')
运行结果显示为:

数据排序及排名
Series和DataFrame均支持排序、排名
排序
obj.sort_values(by, ascending, inplace,…)
- by 列索引,定义用于排序的列
指定单个列排序:
by=[col]
指定多个列排序:
by=[‘col1’, ‘col2’] 先按col1排序,若某些行col1相同,则这些行再按照col排序- ascending 排序方式,True为升序,False为降序
import pandas as pd
from pandas import DataFrame
stu0= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group3', index_col= 0)
#根据成绩进行降序排序---指定单个列进行排序
stu0.sort_values(by= '成绩', ascending=False)
>>>
性别 年龄 身高 体重 省份 成绩 月生活费 课程兴趣 案例教学
序号
30 female 20 168 52 JiangSu 98 700 5 5
21 female 21 165 45 ShangHai 93 1200 5 5
23 male 21 169 80 GanSu 93 900 5 5
27 female 21 162 49 ShanDong 93 950 4 4
22 female 19 167 42 HuBei 89 800 5 5
29 female 20 161 51 GuangXi 80 1250 5 5
28 female 22 160 52 ShanXi 73 800 3 4
25 female 21 162 54 GanSu 68 1300 4 5
26 male 21 181 77 SiChuan 62 800 2 5
24 female 21 160 49 HeBei 59 1100 3 5
#指定多个列排序
stu0.sort_values(by=['身高', '体重'], ascending= False)
>>>
性别 年龄 身高 体重 省份 成绩 月生活费 课程兴趣 案例教学
序号
26 male 21 181 77 SiChuan 62 800 2 5
23 male 21 169 80 GanSu 93 900 5 5
30 female 20 168 52 JiangSu 98 700 5 5
22 female 19 167 42 HuBei 89 800 5 5
21 female 21 165 45 ShangHai 93 1200 5 5
25 female 21 162 54 GanSu 68 1300 4 5
27 female 21 162 49 ShanDong 93 950 4 4
29 female 20 161 51 GuangXi 80 1250 5 5
28 female 22 160 52 ShanXi 73 800 3 4
24 female 21 160 49 HeBei 59 1100 3 5
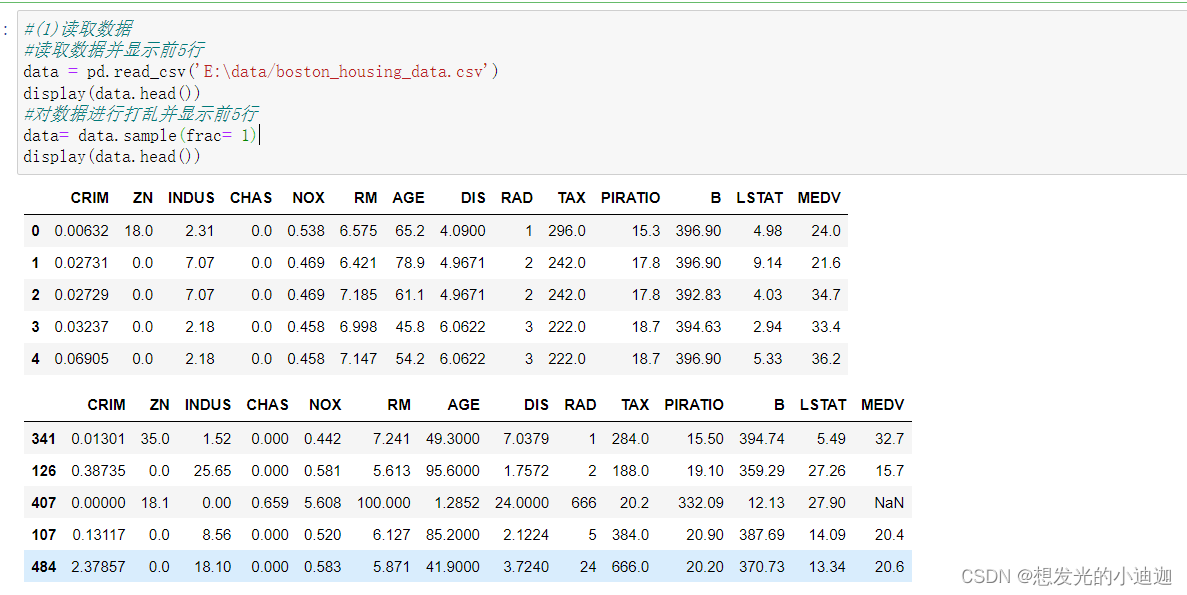
数据打乱
obj= obj.sample(frac= 1)
排名
排名给出每行的名次
obj.rank(axis, method, ascending,…)
axis=0(默认) 按行数据排名 axis=1 按列数据排名
method 并列时取值方式:min,max,average,first,dense
ascending 排序方式,True为升序,False为降序
#axis= 0可省略不写,此处加上时为了让其明白是按行数据进行排名
stu0['成绩排名']= stu0['成绩'].rank(method='dense', ascending= False, axis= 0)
stu0
>>>
性别 年龄 身高 体重 省份 成绩 月生活费 课程兴趣 案例教学 成绩排名
序号
21 female 21 165 45 ShangHai 93 1200 5 5 2.0
22 female 19 167 42 HuBei 89 800 5 5 3.0
23 male 21 169 80 GanSu 93 900 5 5 2.0
24 female 21 160 49 HeBei 59 1100 3 5 8.0
25 female 21 162 54 GanSu 68 1300 4 5 6.0
26 male 21 181 77 SiChuan 62 800 2 5 7.0
27 female 21 162 49 ShanDong 93 950 4 4 2.0
28 female 22 160 52 ShanXi 73 800 3 4 5.0
29 female 20 161 51 GuangXi 80 1250 5 5 4.0
30 female 20 168 52 JiangSu 98 700 5 5 1.0
课后练习2

import pandas as pd
from pandas import DataFrame
#第一题:
data=pd.read_excel('E:\data\studentsInfo.xlsx', 'Group3')
data1= data[['序号', '性别', '年龄']]
data2= data[['序号', '身高', '体重']]
data0=pd.merge(data1, data2, how= 'inner', left_on= '序号', right_on= '序号')
#第二题:
data3= data[['序号', '省份', '成绩', '月生活费', '课程兴趣', '案例教学']]
datafinish= pd.merge(data0, data3, how='inner', left_on='序号', right_on= '序号')
datafinish.sort_values(by=['月生活费'], ascending= True)
datafinish['身高排名']= datafinish['身高'].rank(method= 'min', ascending= False)
统计分析
通用函数与运算
DataFrame、Series、标量之间的算术运算
df.t 即DataFrame转置
df1+df2 按照索引和列相加,得到并集,NaN补充 df1.add(df2, fill_value= 0) 按照索引和列相加,NaN用指定值填充
df1.add/sub//mul/div 四则运算
df-sr 即DataFrame的所有行同时减去Series
df*n 所有元素乘以n
DataFrame元素级的函数运算–import numpy as np
格式均为 np.ufunc(df)
abs、fabs 计算整数、浮点数或复数的绝对值
sqrt 计算各元素的平方根
square 计算各元素的平方
exp 计算各元素的指数
import pandas as pd
from pandas import DataFrame
import numpy as np
qwe= pd.read_excel('E:\data\studentsInfo.xlsx','Group3',index_col=0)
qwe['BMI']= qwe['体重']/np.square(qwe['身高']/100)
pandas常用统计函数
sr.value_counts() Series统计频率
sr.describe() 返回基本统计量和分位数
sr1.corr(sr2) sr1与sr2的相关系数
df.count() 统计每列数据个数
df.max()、df.min() 最大值和最小值
df.idxmax()、df.idxmin() 最大值、最小值对应的索引
df.idxmax()、df.idxmin() 最大值、最小值对应的索引
df.sum() 按行或列求和
df.mean()、df.median() 计算均值、中位数
df.quantile() 计算给定的四分位数
df.var()、df.std() 计算方差、标准差
df.mode() 计算众数
df.cumsum() 从0开始向前累加各元素
df.cov() 计算协方差矩阵
pd.crosstab(df[col1],df[col2]) pandas函数,交叉表,计算分组的频率
df.reset_index(inplace=True) 重新按照顺序设置index
df.head(num) ------参数为空(即n=0)则为显示前5行数据
display(df.head(num))------以df的原格式显示文件数据的前num行
df.shape------查看文件数据是几行几列
qwe['成绩'].mean()
>>> 80.8
qwe['成绩'].median()#计算成绩的均值
>>> 84.5
qwe['月生活费'].quantile([.25, .75])
#等同于qwe['月生活费'].quantile([0.25, 0.75])
>>>
0.25 800.0
0.75 1175.0
Name: 月生活费, dtype: float64
#sr.describe()返回基本统计量和分位数
qwe[['身高','体重','成绩']].describe()
>>>
身高 体重 成绩
count 10.000000 10.0000 10.000000
mean 165.500000 55.1000 80.800000
std 6.381397 12.8448 14.389811
min 160.000000 42.0000 59.000000
25% 161.250000 49.0000 69.250000
50% 163.500000 51.5000 84.500000
75% 167.750000 53.5000 93.000000
max 181.000000 80.0000 98.000000
#sr.value_counts()Series统计频率
qwe['成绩'].value_counts()
>>>
93 3
89 1
59 1
68 1
62 1
73 1
80 1
98 1
Name: 成绩, dtype: int64
分组(分组并统计个数)
根据某些索引将数据对象划分为多个组
对每个分组进行排序或统计计算
分组方式1:
grouped = obj.groupby(col) 或 grouped = obj.groupby(colList)
grouped.aggregate({‘col1’:f1, ‘col2’:f2,…})
col 统计列索引名
fi(i=1,2,…) numpy的聚合函数名,eg:sum、mean、std
grouped = stu.groupby(['性别', '年龄'])
grouped.aggregate( {'身高':np.mean, '月生活费':np.max})
>>>
身高 月生活费
性别 年龄
female 19.0 163.000000 1100.0
20.0 164.000000 1400.0
21.0 162.333333 1500.0
22.0 160.000000 800.0
male 19.0 171.250000 1100.0
20.0 173.555556 1300.0
21.0 174.900000 1300.0
22.0 180.000000 1300.0
numpy的聚合函数名
np.sum 计算元素的和
np.prod 计算元素的积
np.mean 计算元素的平均值
np.std 计算元素的标准差
np.var 计算元素的方差
np.median 计算元素的中位数
np.percentile 计算基于元素排序的统计值
np.min 找出最小值
np.max 找出最大值
np.argmin 找出最小值的索引
np.argmax 找出最大值的索引
np.any 验证任何一个元素是否为真
np.all 验证所有元素是否为真
注意:已经说了是使用聚合函数 名,所以在使用这些函数时不用加括号(),直接使用即可,eg: np.sum
分组方式2:
grouped=obj.groupby(col1)
grouped[col2].unique()
先根据col1进行分组,然后得出各col1中col2的分类
#分析各二级实验室能够支持的实验类型
support_grouped= df.groupby('二级实验室名称')
support_grouped['实验类型'].unique()
>>>
二级实验室名称
人工智能实验室 [验证型, 设计型, 综合型]
基础实验室 [验证型, 综合型]
数据科学实验室 [验证型, 设计型, 综合型, 实训]
Name: 实验类型, dtype: object
分组方式3:
根据col或colList分组后,统计每个分组的行数
Step1:grouped = obj.groupby(col) 或 grouped =obj.groupby(colList)
Step2:grouped.count()
解释:根据分组,统计每个列索引的内容所占的行数,若列索引的某一行中对应位置处的值为NaN,则不统计改行,详见例题
data01= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group1')
data01
>>>
序号 性别 年龄 身高 体重 省份 成绩 月生活费 课程兴趣 案例教学
0 1 male 20.0 170 70.0 LiaoNing NaN 800.0 5 4
1 2 male 22.0 180 71.0 GuangXi 77.0 1300.0 3 4
2 3 male NaN 180 62.0 FuJian 57.0 1000.0 2 4
3 4 male 20.0 177 72.0 LiaoNing 79.0 900.0 4 4
4 5 male 20.0 172 NaN ShanDong 91.0 NaN 5 5
5 6 male 20.0 179 75.0 YunNan 92.0 950.0 5 5
6 7 female 21.0 166 53.0 LiaoNing 80.0 1200.0 4 5
7 8 female 20.0 162 47.0 AnHui 78.0 1000.0 4 4
8 9 female 20.0 162 47.0 AnHui 78.0 1000.0 4 4
9 10 male 19.0 169 76.0 HeiLongJiang 88.0 1100.0 5 5
#先根据性别对数据进行分组
grouped= data01.groupby('性别')
#统计在性别的分组下每个列索引的行数,列索引的某一行若未赋值即NaN,则不统计
grouped.count()
>>>
序号 年龄 身高 体重 省份 成绩 月生活费 课程兴趣 案例教学
性别
female 3 3 3 3 3 3 3 3 3
male 7 6 7 6 7 6 6 7 7
另一种用法:(详见数据可视化知识点归纳总结中的课后作业第(5)问)
sex_grouped= data.groupby('sex')#将表根据sex性别进行分组
data1= sex_grouped['sex'].count()#统计不同性别的人数
#连在一块即为:
data.groupby('sex')['sex'].count()
#等同于
sex_grouped= data.groupby('sex')
sex_grouped.size()
#连在一块即为:
data.groupby('sex').size()
分组方式4:
obj.groupby(‘col’).size()
根据col对obj进行分组,并统计col的个数
grouped= data.groupby('Gender').size()
grouped
>>>
Gender
female 25
male 25
dtype: int64
obj.groupby([‘col1’, ‘col2’]).size()
先根据col1进行分组,再根据col2进行分组,并统计各个分组后的总数
grouped= data.groupby(['Gender', 'Province']).size()
grouped
>>>
Gender Province
female AnHui 2
ChongQing 1
GanSu 1
GuangXi 2
GuiZhou 2
male AnHui 1
BeiJing 1
ChongQing 2
FuJian 1
GanSu 2
分组方式5:
pd.crosstab(obj[col1], obj[col2])
统计col1的col2分布或现根据col1分组,然后对col2进行计数
#先根据性别将表分为两组,然后对月生活费进行计数,统计不同生活费的人数有多少
pd.crosstab(asd['性别'], asd['月生活费'])
>>>
月生活费 700 800 900 950 1100 1200 1250 1300
性别
female 1 2 0 1 1 1 1 1
male 0 1 1 0 0 0 0 0
分组方式6(补充):
value_counts(values,sort=True, ascending=False, normalize=False,bins=None,dropna=True)
统计数据表中指定的列里有多少个不同的数据值,并计算每个不同值有在该列中的个数,同时还能根据指定得参数返回排序后结果
- sort=True: 是否要进行排序;默认进行排序
- ascending=False: 默认降序排列;
- normalize=False: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。
- bins=None: 可以自定义分组区间,默认是否
- dropna=True:是否删除缺失值nan,默认删除
部分数如下:

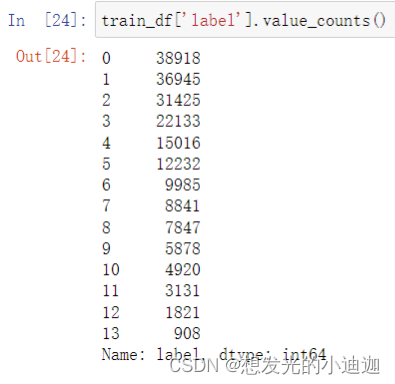
train_df['label'].value_counts()
运行结果显示为:
相关性分析 DataFrame相关性分析函数:DataFrame.corr()
只能分析列索引所引导的这列元素为数字的索引,详见例子
研究不同总体之间是否存在依存关系
绘制散点图矩阵给观察列之间的相关性
pd.plotting.scatter_matrix(data, diagonal=‘kde’, color= ‘k’)
计算样本之间的相关系数r推断总体的相关程度
相关系数r(-1<=r<=1)的特征如下:
r=-1:两个总体负相关 r=0:不相关 r=1:正相关
|r|<0.3:低度相关 0.3<=|r|<0.8:中等相关 0.8<=|r|<1:高度相关
样本容量>=30时,相关性分析判断的准确性较高
相关性分析方式1:
obj[‘col1’].corr(obj[‘col2’])即求col1和col2之间的相关性
#体重和成绩的列中的元素均为数字,所以可以进行相关性分析
qwe['体重'].corr(qwe['成绩'])
>>> -0.17541241713010963
相关性分析方式2:
obj[colList].corr()即求不同列索引之间的相关性
统计案例分析
import pandas as pd
from pandas import DataFrame, Series
import numpy as np
df1= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group1', index_col=0)
df2= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group2', index_col=0)
df3= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group3', index_col=0)
df4= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group4', index_col=0)
df5= pd.read_excel('E:\data\studentsInfo.xlsx', 'Group5', index_col=0)
stu= pd.concat([df1,df2,df3,df4,df5], axis=0)
stu.drop_duplicates(inplace= True)#去除重复的行
stu.dropna(thresh=8,inplace= True)#去除含有缺失数据的行
stu.isnull().any()#查看列索引所引导的列中是否含有NaN空值
stu.fillna({'成绩':stu['成绩'].mean(), '年龄':20}, inplace= True)#有空值,填补含有空值的列索引
stu.isnull().any()#再次判断是否有空值
#分析成绩和课程兴趣的相关性,因为成绩和课程兴趣的列元素均为数字,所以可以直接用DataFrame.corr()来分析
stu_grade= stu.sort_values(by= ['成绩'], ascending= False)
ex= (stu_grade['成绩']>=90).sum()
fail= (stu_grade['成绩']>60).sum()
print("Excellent:{},Fail:{}".format(ex, fail))
>>> Excellent:10,Fail:44
ex_mean= stu_grade[0:10][['成绩', '课程兴趣']].mean()
total_mean= stu_grade[['成绩', '课程兴趣']].mean()
fail_mean= stu_grade[-4:][['成绩', '课程兴趣']].mean()
print("ex_mean:{},total_mean:{},fail_mean:{}".format(ex_mean, total_mean, fail_mean))
print("成绩与课程兴趣的相关度为:{}".format(stu_grade['成绩'].corr(stu_grade['课程兴趣'])))
>>>
ex_mean:成绩 93.7
课程兴趣 4.9
dtype: float64,
total_mean:成绩 76.934783
课程兴趣 4.208333
dtype: float64,
fail_mean:成绩 46.0
课程兴趣 3.0
dtype: float64
成绩与课程兴趣的相关度为:0.4803582640854468
#分析性别、省份与成绩是否存在相关性,由于性别和省份数据均为字符型,所以无法用DataFrame.corr()来计算相关性,所以方法为:分组计算均值,例子如下
sex_grouped= stu.groupby(['性别'])
sex_counts= sex_grouped.count()
sex_mean= stu.groupby('性别').aggregate({'成绩':np.mean})
pro_grouped= stu.groupby('省份')
pro_counts= pro_grouped.count()
pro_mean= stu.groupby('省份').aggregate({'成绩':np.mean})
print(sex_counts,'\n',sex_mean)
print(pro_counts,'\n',pro_mean)
>>> 此处成略运行结果展示
#计算同学的BMI值,找出各个四分位数
stu['BMI']=stu['体重']/np.square(stu['身高']/100)
stu['BMI'].quantile([.25,.5,.75])
>>>
0.25 18.609210
0.50 20.450285
0.75 23.431521
Name: BMI, dtype: float64
课后作业3

import pandas as pd
import numpy as np
from pandas import Series, DataFrame
df= pd.read_excel('E:\data\DataScience.xls',header= 'infer')
df.shape
>>> (96,11)
df.index
>>> RangeIndex(start=0, stop=96, step=1)
df.columns
>>>
Index(['周次', '星期', '节次', '课程名称', '实验项目名称', '实验课时数', '实验类型', '班级'
, '班级人数','二级实验室名称', '实验地点门牌号'],dtype='object')
df.isnull().any()#查询df中是否含有NaN数据
#将含有NaN数据的行导出为数据文件pre.csv
df[df.isnull().any(axis=1)].to_csv('E:\pre.csv', mode= 'w')
#
df.drop_duplicates(inplace= True)#去除重复的行
df.fillna(method='ffill', inplace= True)#将缺失的数据用该列的上一行数据填充
df1= df[['课程名称', '实验项目名称', '实验类型', '二级实验室名称']]
#统计每一门课程的实验课时数
project_grouped= df.groupby('课程名称')
project_grouped.aggregate({'实验课时数':np.sum})
>>>
实验课时数
课程名称
Python语言程序设计 68.0
商务数据分析 24.0
大数据技术 32.0
数据挖掘与机器学习 64.0
数据科学导论 48.0
数据结构 21.0
重庆市 3.0
#统计每周开设所有实验课时数
week_grouped= df.groupby('周次')
week_grouped.aggregate({'实验课时数':np.sum})
#统计每门课程的实验类型分布(crosstab)
pd.crosstab(df['课程名称'], df['实验类型'])
#统计每个班级的实验课课表
asd= df[['班级','班级人数','周次','星期','节次','课程名称','实验项目名称','实验课时数','实验类型','二级实验室名称','实验地点门牌号']]
asd.sort_values(by = ['班级','周次','星期','节次'],ascending = True)
#分析各二级实验室承担的实验课时量
sdroom_grouped= df.groupby(['二级实验室名称','周次'])
sdroom_grouped.aggregate({'实验课时数':np.sum})
pd.crosstab(df['二级实验室名称'], df['实验课时数'])
#分析各二级实验室能够支持的实验类型
#方式一:
support_grouped= df.groupby('二级实验室名称')
support_grouped['实验类型'].unique()
>>>
二级实验室名称
人工智能实验室 [验证型, 设计型, 综合型]
基础实验室 [验证型, 综合型]
数据科学实验室 [验证型, 设计型, 综合型, 实训]
Name: 实验类型, dtype: object
#方式二:
pd.crosstab(df['二级实验室名称'], df['实验类型'])
>>>
实验类型 实训 综合型 设计型 验证型
二级实验室名称
人工智能实验室 0 2 10 20
基础实验室 0 3 0 22
数据科学实验室 6 7 11 14
#统计每个班级的实验课课表-------------知道就行,但不会用,因为这种方式显示出来的太乱了
grouped= df.groupby(['班级', '周次', '二级实验室名称', '实验类型', '星期', '实验项目名称', '节次', '实验课时数', '实验地点门牌号'])
grouped['课程名称'].unique()