UNI-MOL: A UNIVERSAL 3D MOLECULAR REPRESENTATION LEARNING FRAMEWORK
Neurips23
推荐指数:#paper/⭐⭐⭐#(工作量不小)
动机
在大多数分子表征学习方法中,分子被视为 1D 顺序标记或2D 拓扑图,这限制了它们为下游任务整合 3D 信息的能力,这使得 3D几何预测/生成几乎不可能。为此,作者提出了一种3D分子表征学习方法
模型框架
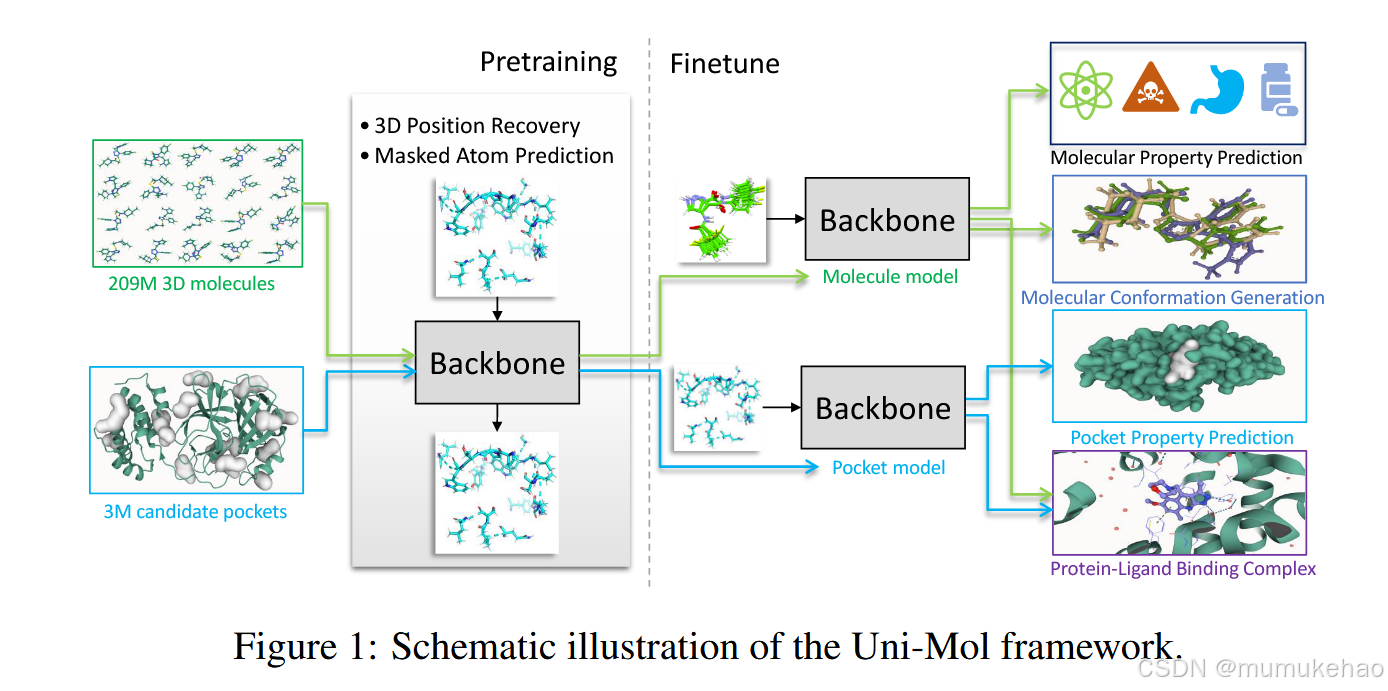
贡献:
- backborn:基于 Transformer 的模型,可以有效地捕获输入的 3D 信息,并直接预测 3D 位置。
- 预训练。两个大规模数据集:一个 209M 分子构象数据集和一个 3M 候选蛋白质口袋数据集,分别用于分子和蛋白质口袋的预训练 2 个模型。以及两个预训练任务:3D 位置恢复和掩蔽原子预测,用于有效学习 3D 空间表示。
- 微调。适用于各种下游任务的多种微调策略。例如,如何在分子性质预测任务中使用预训练的分子模型;如何在蛋白质-配体结合姿势预测中结合两个预训练模型。
backborn的设计:
常用有两种的设计:GNN与transformer
由于GNN在捕获领域信息有优势,而局部连接的图缺乏捕捉原子之间长距离相互作用的能力。作者认为长距离信息更有用,因此选择Transformer 作为 Uni-Mol 中的主干模型。因为它完全连接了节点/原子,因此可以学习可能的长程相互作用。
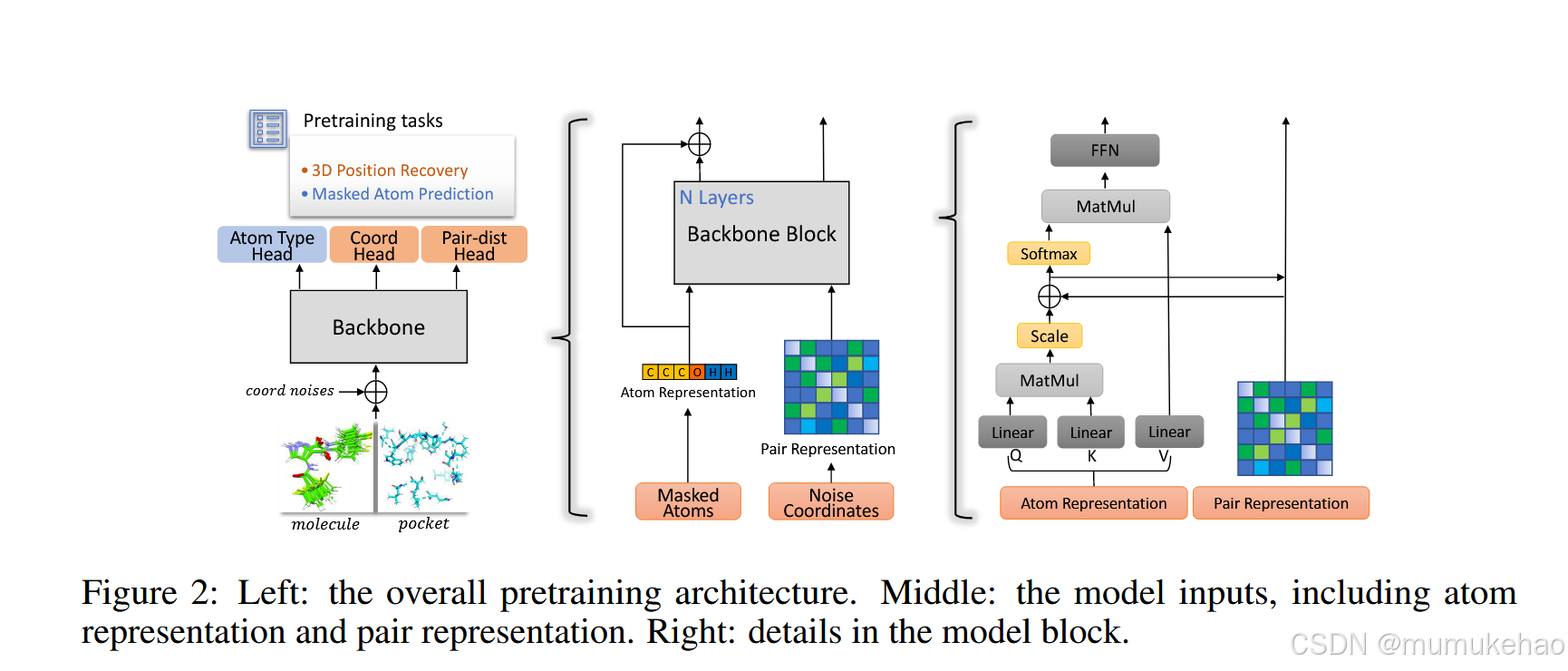
整体结构概述
如图 2 所示,Uni-Mol 主干是基于 Transformer 的模型。它有两个输入,原子类型和原子坐标。模型中维护了两种表示形式(atom 和 pair)。原子表示由 Embedding 层从 atom 类型初始化;对表示由原子坐标计算的不变空间位置编码初始化。特别是,基于原子之间的成对欧几里得距离,对表示对全局旋转和平移是不变的。这两种表示在 self-attention 模块中相互通信。
编码3D位置:
编码 3D 位置 由于其排列不变性,Transformer 在没有位置编码的情况下无法区分输入的位置。与 NLP/CV 中使用的离散位置不同 ,3D 空间中的位置(坐标)是连续值。此外,位置编码过程在全局旋转和平移下需要保持不变。已经提出了几种 3D 空间位置编码来解决这个问题,我们没有兴趣重新发明一种新的编码。因此,我们对现有的编码进行了基准测试,并使用了一个简单而有效的编码:原子对的欧几里得距离,然后是一个对类型感知的高斯核。
此外,由于不变的 3D 空间位置编码是在对级编码的,作者还在 Transformer 中维护了对级表示,以增强 3D 空间表示。具体来说,对表示被初始化为上述空间位置编码。
然后,为了更新对表示,作者通过 self-attention 中的多头Query-Key 产品的结果使用atom到pair 通信。形式上,ij 对表示的更新表示为
q i j l + 1 = q i j l + { Q i l , h ( K j l , h ) T d ∣ h ∈ [ 1 , H ] } , \boldsymbol{q}_{ij}^{l+1}=\boldsymbol{q}_{ij}^l+\{\frac{\boldsymbol{Q}_i^{l,h}(\boldsymbol{K}_j^{l,h})^T}{\sqrt{d}}|h\in[1,H]\}, qijl+1=qijl+{dQil,h(Kjl,h)T∣h∈[1,H]},(多头注意力,H是通道数)
从形式上讲,具有对原子通信的自我注意表示为:
A t t e n t i o n ( Q i l , h , K j l , h , V j l , h ) = s o f t m a x ( Q i l , h ( K j l , h ) T d + q i j l − 1 , h ) V j l , h , \mathrm{Attention}(\boldsymbol{Q}_i^{l,h},\boldsymbol{K}_j^{l,h},\boldsymbol{V}_j^{l,h})=\mathrm{softmax}(\frac{\boldsymbol{Q}_i^{l,h}(\boldsymbol{K}_j^{l,h})^T}{\sqrt{d}}+\boldsymbol{q}_{ij}^{l-1,h})\boldsymbol{V}_j^{l,h}, Attention(Qil,h,Kjl,h,Vjl,h)=softmax(dQil,h(Kjl,h)T+qijl−1,h)Vjl,h,
其中 V l V_l Vl, h j h_j hj是第l层第h个头中第 j 个原子的值。
预测位置编码
x ^ i = x i + ∑ j = 1 n ( x i − x j ) c i j n , c i j = R e L U ( ( q i j L − q i j 0 ) U ) W , \hat{\boldsymbol{x}}_i=\boldsymbol{x}_i+\sum_{j=1}^n\frac{(\boldsymbol{x}_i-\boldsymbol{x}_j)c_{ij}}{n},\quad c_{ij}=\mathrm{ReLU}((\boldsymbol{q}_{ij}^L-\boldsymbol{q}_{ij}^0)\boldsymbol{U})\boldsymbol{W}, x^i=xi+∑j=1nn(xi−xj)cij,cij=ReLU((qijL−qij0)U)W,
此外,为了与 delta 位置预测保持一致,Uni-Mol 使用 delta 对表示来更新坐标,而 EGNN 直接使用对表示。我们在附录 D.3 中的基准测试表明 Uni-Mol 中的那个更好。
预训练策略
由于目的是预测位置信息,因此像bert一样的mask操作实际上是不可行的。因此,作者设计了一种新的mask策略。

具体的是,随机位置被用作损坏的输入 3D 位置,而不是掩码,并且模型经过训练以预测正确的位置。然而,学习从随机位置到真实原子位置的映射是非常具有挑战性的。
- 重新分配,给定 m 个原子和 m 个随机位置,有 m!可能的任务。其中,遵循稳态作用原理 [47],我们可以使用具有最小 delta 位置的那个。由于难以找到最优解,我们使用高效的贪婪算法来找到次优的重新分配。
- 噪声范围,我们可以限制随机位置的空间,只允许具有噪声 (r) 的随机位置围绕真实位置。这里有一个权衡;如果 r 很大,则需要重新分配以使学习可行;如果 r 很小,则可能不需要重新分配
然后,在输入坐标损坏的情况下,使用两个额外的头来恢复正确的位置。1) 配对距离预测。基于对表示,该模型需要预测损坏的原子对的正确欧几里得距离。2) 坐标预测。基于 SE(3)-Equivariant 坐标头,该模型需要预测损坏原子的正确坐标。
最后,mask corrupt原子的原子类型,并使用head来预测正确的原子类型。为了方便微调,与 BERT 类似,使用一个特殊的原子 [CLS],其坐标是所有原子的中心,用于表示整个分子/口袋。
微调阶段
这部分有不同的任务,需要不同的微调。
非 3D 预测任务
我们可以简单地使用 [CLS] 的表示,它代表整个分子/口袋,或者所有原子的平均表示,带有线性头来微调下游任务。在具有口袋-分子对的任务中,我们可以连接它们的 [CLS] 表示,然后用线性头进行微调。
分子或口袋的 3D 预测任务
在 Uni-Mol 中,这个任务直接变成了一个构象优化任务:根据不同的输入构象生成一个新的构象。具体来说,在微调中,模型监督学习从 Uni-Mol 生成的构象到标记构象的映射。此外,输出构象可以通过 SE(3)-Equivariant head 端到端生成
蛋白质-配体对的 3D 预测任务
见论文
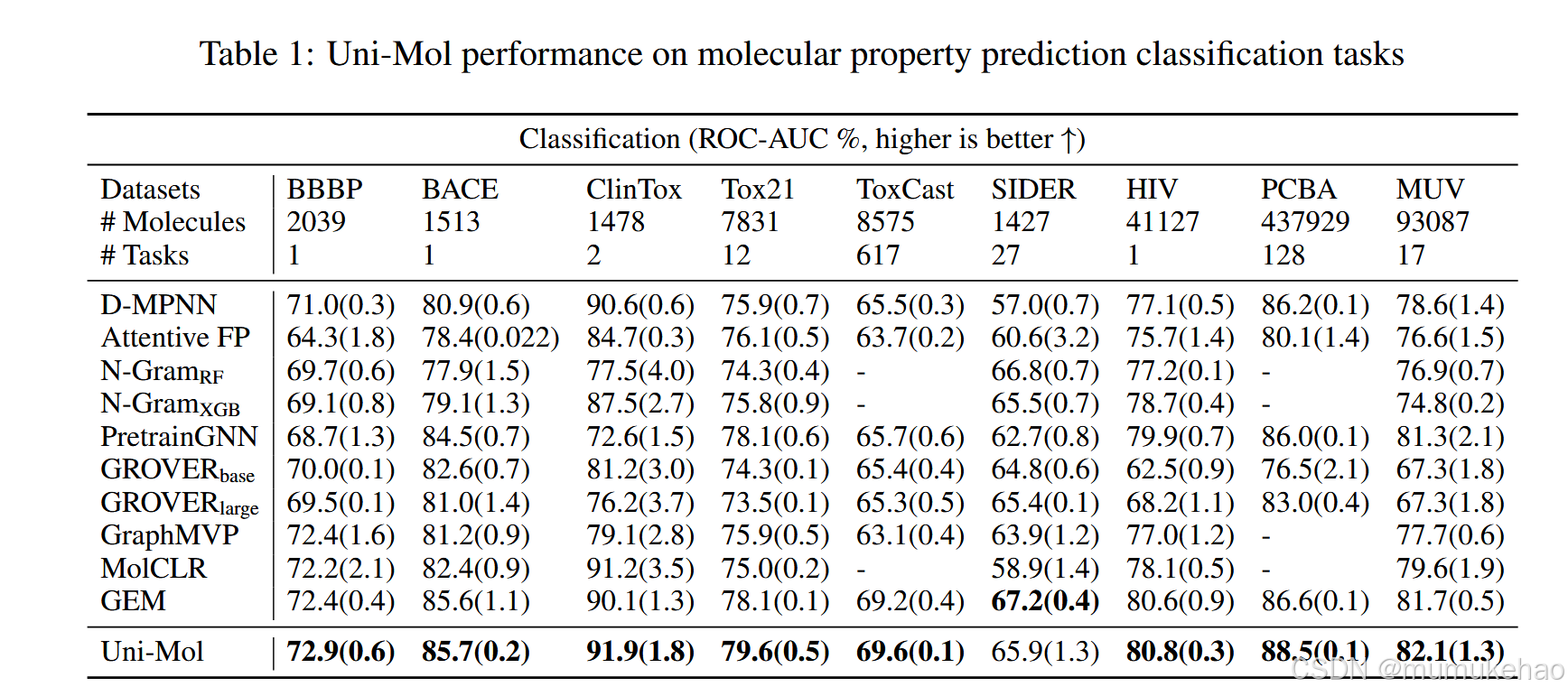
后续内容和这个方向的积累有关,等积累够,重读这篇文章(读前面的文章以及transformer)