本文主要推导高斯分布(正态分布)的乘积,以便能更清楚的明白Kalman滤波的最后矫正公式。
Kalman滤波主要分为两大步骤:
1.系统状态转移估计,2.系统测量矫正;
在第2步中的主要理论依据就是两个独立高斯分布的乘积如何计算的问题,即如何融合 估计值 和 观测值 得到系统状态的最优估计。
高斯分布的概率密度函数:
f
(
x
)
=
1
2
π
δ
e
−
(
x
−
u
)
2
2
δ
2
(1)
f(x) = \frac{1}{\sqrt{2\pi}\delta}{e^{-\frac{(x-u)^2}{2\delta^2}}} \tag{1}
f(x)=2πδ1e−2δ2(x−u)2(1)
其本质问题可抽象为:已知两个独立高斯分布
N
1
∼
(
u
1
,
δ
1
2
)
N_1∼(u_1, \delta_1^2)
N1∼(u1,δ12),
N
2
∼
(
u
2
,
δ
2
2
)
N_2∼(u_2, \delta_2^2)
N2∼(u2,δ22),求新的概率分布
N
=
N
1
×
N
2
∼
(
?
,
?
)
N =N_1\times N_2∼(?,?)
N=N1×N2∼(?,?)
在进行理论推导之前,我们先通过Matlab数值计算看看两独立概率分布的乘积情况:
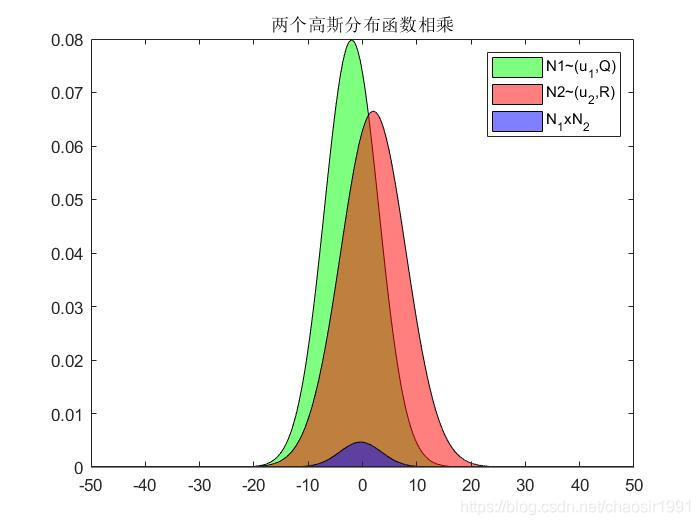
N
1
N_1
N1 的概率分布函数为
f
1
(
x
)
f_1(x)
f1(x),
N
2
N_2
N2 的概率分布函数为
f
2
(
x
)
f_2(x)
f2(x), 则:
f
1
(
x
)
f
2
(
x
)
=
1
2
π
δ
1
e
−
(
x
−
u
1
)
2
2
δ
1
2
⋅
1
2
π
δ
2
e
−
(
x
−
u
2
)
2
2
δ
2
2
=
1
2
π
δ
1
δ
2
e
−
(
(
x
−
u
1
)
2
2
δ
1
2
+
(
x
−
u
2
)
2
2
δ
2
2
)
(2)
\begin{aligned} f_1(x)f_2(x) &=\frac{1}{\sqrt{2\pi}\delta_1}{e^{-\frac{(x-u_1)^2}{2\delta_1^2}}}\cdot\frac{1}{\sqrt{2\pi}\delta_2}{e^{-\frac{(x-u_2)^2}{2\delta_2^2}}}\\\\ &=\frac{1}{2\pi \delta_1\delta_2}{e^{-\bigg(\frac{(x-u_1)^2}{2\delta_1^2}+\frac{(x-u_2)^2}{2\delta_2^2}\bigg)}} \end{aligned} \tag{2}
f1(x)f2(x)=2πδ11e−2δ12(x−u1)2⋅2πδ21e−2δ22(x−u2)2=2πδ1δ21e−(2δ12(x−u1)2+2δ22(x−u2)2)(2)
可以直接先单独分析指数部分,设:
β
=
(
x
−
u
1
)
2
2
δ
1
2
+
(
x
−
u
2
)
2
2
δ
2
2
=
(
δ
1
2
+
δ
2
2
)
x
2
−
2
(
u
2
δ
1
2
+
u
1
δ
2
2
)
x
+
(
u
1
2
δ
2
2
+
u
2
2
δ
1
2
)
2
δ
1
2
δ
2
2
=
x
2
−
2
u
2
δ
1
2
+
u
1
δ
2
2
δ
1
2
+
δ
2
2
x
+
u
1
2
δ
2
2
+
u
2
2
δ
1
2
δ
1
2
+
δ
2
2
2
δ
1
2
δ
2
2
δ
1
2
+
δ
2
2
构造新的正态分布
=
(
x
−
u
2
δ
1
2
+
u
1
δ
2
2
δ
1
2
+
δ
2
2
)
2
+
u
1
2
δ
2
2
+
u
2
2
δ
1
2
δ
1
2
+
δ
2
2
−
(
u
2
δ
1
2
+
u
1
δ
2
2
δ
1
2
+
δ
2
2
)
2
2
δ
1
2
δ
2
2
δ
1
2
+
δ
2
2
=
(
x
−
u
2
δ
1
2
+
u
1
δ
2
2
δ
1
2
+
δ
2
2
)
2
2
δ
1
2
δ
2
2
δ
1
2
+
δ
2
2
⏟
γ
+
u
1
2
δ
2
2
+
u
2
2
δ
1
2
δ
1
2
+
δ
2
2
−
(
u
2
δ
1
2
+
u
1
δ
2
2
δ
1
2
+
δ
2
2
)
2
2
δ
1
2
δ
2
2
δ
1
2
+
δ
2
2
⏟
λ
(3)
\begin{aligned} \beta &=\frac{(x-u_1)^2}{2\delta_1^2}+\frac{(x-u_2)^2}{2\delta_2^2}\\\\ &=\frac{(\delta_1^2+\delta_2^2)x^2-2(u_2\delta_1^2+u_1\delta_2^2)x+(u_1^2\delta_2^2+u_2^2\delta_1^2)}{2\delta_1^2\delta_2^2}\\\\ &=\frac{x^2-2\frac{u_2\delta_1^2+u_1\delta_2^2}{\delta_1^2+\delta_2^2}x+\frac{u_1^2\delta_2^2+u_2^2\delta_1^2}{\delta_1^2+\delta_2^2}}{\frac{2\delta_1^2\delta_2^2}{\delta_1^2+\delta_2^2}}\\\\ \text{构造新的正态分布}&=\frac{\bigg(x-\frac{u_2\delta_1^2+u_1\delta_2^2}{\delta_1^2+\delta_2^2}\bigg)^2+\frac{u_1^2\delta_2^2+u_2^2\delta_1^2}{\delta_1^2+\delta_2^2}-\bigg(\frac{u_2\delta_1^2+u_1\delta_2^2}{\delta_1^2+\delta_2^2}\bigg)^2}{\frac{2\delta_1^2\delta_2^2}{\delta_1^2+\delta_2^2}}\\\\ &=\underbrace{\frac{\bigg(x-\frac{u_2\delta_1^2+u_1\delta_2^2}{\delta_1^2+\delta_2^2}\bigg)^2}{\frac{2\delta_1^2\delta_2^2}{\delta_1^2+\delta_2^2}}}_{\gamma}+\underbrace{\frac{\frac{u_1^2\delta_2^2+u_2^2\delta_1^2}{\delta_1^2+\delta_2^2}-\bigg(\frac{u_2\delta_1^2+u_1\delta_2^2}{\delta_1^2+\delta_2^2}\bigg)^2}{\frac{2\delta_1^2\delta_2^2}{\delta_1^2+\delta_2^2}}}_{\lambda} \end{aligned} \tag{3}
β构造新的正态分布=2δ12(x−u1)2+2δ22(x−u2)2=2δ12δ22(δ12+δ22)x2−2(u2δ12+u1δ22)x+(u12δ22+u22δ12)=δ12+δ222δ12δ22x2−2δ12+δ22u2δ12+u1δ22x+δ12+δ22u12δ22+u22δ12=δ12+δ222δ12δ22(x−δ12+δ22u2δ12+u1δ22)2+δ12+δ22u12δ22+u22δ12−(δ12+δ22u2δ12+u1δ22)2=γ
δ12+δ222δ12δ22(x−δ12+δ22u2δ12+u1δ22)2+λ
δ12+δ222δ12δ22δ12+δ22u12δ22+u22δ12−(δ12+δ22u2δ12+u1δ22)2(3)
设
λ
\lambda
λ 如上所示,则
β
=
γ
+
λ
\beta=\gamma+\lambda
β=γ+λ ,其中
γ
\gamma
γ 为一个
N
∼
(
u
,
δ
2
)
N∼(u, \delta^2)
N∼(u,δ2) 的正态分布,
λ
\lambda
λ 为一个常数值。继续简化
λ
\lambda
λ ,如下:
λ
=
u
1
2
δ
2
2
+
u
2
2
δ
1
2
δ
1
2
+
δ
2
2
−
(
u
2
δ
1
2
+
u
1
δ
2
2
δ
1
2
+
δ
2
2
)
2
2
δ
1
2
δ
2
2
δ
1
2
+
δ
2
2
=
(
u
1
2
δ
2
2
+
u
2
2
δ
1
2
)
(
δ
1
2
+
δ
2
2
)
−
(
u
2
δ
1
2
+
u
1
δ
2
2
)
2
2
δ
1
2
δ
2
2
(
δ
1
2
+
δ
2
2
)
=
(
u
1
2
δ
2
2
δ
1
2
+
u
2
2
δ
1
4
+
u
2
2
δ
2
2
δ
1
2
+
u
1
2
δ
2
4
)
−
(
u
2
2
δ
1
4
+
2
u
1
u
2
δ
1
2
δ
2
2
+
u
1
2
δ
2
4
)
2
δ
1
2
δ
2
2
(
δ
1
2
+
δ
2
2
)
=
δ
1
2
δ
2
2
(
u
1
2
+
u
2
2
−
2
u
1
u
2
)
2
δ
1
2
δ
2
2
(
δ
1
2
+
δ
2
2
)
=
(
u
1
−
u
2
)
2
2
(
δ
1
2
+
δ
2
2
)
(4)
\begin{aligned} \lambda &=\frac{\frac{u_1^2\delta_2^2+u_2^2\delta_1^2}{\delta_1^2+\delta_2^2}-\bigg(\frac{u_2\delta_1^2+u_1\delta_2^2}{\delta_1^2+\delta_2^2}\bigg)^2}{\frac{2\delta_1^2\delta_2^2}{\delta_1^2+\delta_2^2}}\\\\ &=\frac{(u_1^2\delta_2^2+u_2^2\delta_1^2)(\delta_1^2+\delta_2^2)-(u_2\delta_1^2+u_1\delta_2^2)^2}{2\delta_1^2\delta_2^2(\delta_1^2+\delta_2^2)}\\\\ &=\frac{(u_1^2\delta_2^2\delta_1^2+u_2^2\delta_1^4+u_2^2\delta_2^2\delta_1^2+u_1^2\delta_2^4)-(u_2^2\delta_1^4+2u_1u_2\delta_1^2\delta_2^2+u_1^2\delta_2^4)}{2\delta_1^2\delta_2^2(\delta_1^2+\delta_2^2)}\\\\ &=\frac{\delta_1^2\delta_2^2(u_1^2+u_2^2-2u_1u_2)}{2\delta_1^2\delta_2^2(\delta_1^2+\delta_2^2)}\\\\ &=\frac{(u_1-u_2)^2}{2(\delta_1^2+\delta_2^2)} \end{aligned} \tag{4}
λ=δ12+δ222δ12δ22δ12+δ22u12δ22+u22δ12−(δ12+δ22u2δ12+u1δ22)2=2δ12δ22(δ12+δ22)(u12δ22+u22δ12)(δ12+δ22)−(u2δ12+u1δ22)2=2δ12δ22(δ12+δ22)(u12δ22δ12+u22δ14+u22δ22δ12+u12δ24)−(u22δ14+2u1u2δ12δ22+u12δ24)=2δ12δ22(δ12+δ22)δ12δ22(u12+u22−2u1u2)=2(δ12+δ22)(u1−u2)2(4)
则可得两个高斯分布相乘为:
f
1
(
x
)
f
2
(
x
)
=
1
2
π
δ
1
δ
2
e
−
β
=
1
2
π
δ
1
δ
2
e
−
(
γ
+
λ
)
=
1
2
π
δ
1
δ
2
e
−
γ
⋅
e
−
λ
=
1
2
π
δ
1
δ
2
e
−
(
x
−
u
)
2
2
δ
2
⋅
e
−
(
u
1
−
u
2
)
2
2
(
δ
1
2
+
δ
2
2
)
(5)
\begin{aligned} f_1(x)f_2(x) &=\frac{1}{2\pi \delta_1\delta_2}{e^{-\beta}}=\frac{1}{2\pi \delta_1\delta_2}{e^{-(\gamma+\lambda)}}\\\\ &=\frac{1}{2\pi \delta_1\delta_2}{e^{-\gamma}\cdot e^{-\lambda}}\\\\ &=\frac{1}{2\pi \delta_1\delta_2}{e^{-\frac{(x-u)^2}{2\delta^2}}}\cdot e^{-\frac{(u_1-u_2)^2}{2(\delta_1^2+\delta_2^2)}} \end{aligned} \tag{5}
f1(x)f2(x)=2πδ1δ21e−β=2πδ1δ21e−(γ+λ)=2πδ1δ21e−γ⋅e−λ=2πδ1δ21e−2δ2(x−u)2⋅e−2(δ12+δ22)(u1−u2)2(5)
其中:
u
=
u
2
δ
1
2
+
u
1
δ
2
2
δ
1
2
+
δ
2
2
,
δ
2
=
δ
1
2
δ
2
2
δ
1
2
+
δ
2
2
(6)
u=\frac{u_2\delta_1^2+u_1\delta_2^2}{\delta_1^2+\delta_2^2},\ \ \ \ \ \ \delta^2=\frac{\delta_1^2\delta_2^2}{\delta_1^2+\delta_2^2}\tag{6}
u=δ12+δ22u2δ12+u1δ22, δ2=δ12+δ22δ12δ22(6)
把常数项综合为
S
g
S_g
Sg 可得其直观表达方式:
f
1
(
x
)
f
2
(
x
)
=
S
g
⋅
1
2
π
δ
e
−
(
x
−
u
)
2
2
δ
2
(7)
\begin{aligned} f_1(x)f_2(x) &=S_g\cdot\frac{1}{\sqrt{2\pi} \delta}{e^{-\frac{(x-u)^2}{2\delta^2}}} \end{aligned} \tag{7}
f1(x)f2(x)=Sg⋅2πδ1e−2δ2(x−u)2(7)
S
g
=
1
2
π
(
δ
1
2
+
δ
2
2
)
e
−
(
u
1
−
u
2
)
2
2
(
δ
1
2
+
δ
2
2
)
(8)
S_g=\frac{1}{\sqrt{2\pi(\delta_1^2+\delta_2^2)}}e^{-\frac{(u_1-u_2)^2}{2(\delta_1^2+\delta_2^2)}}\tag{8}
Sg=2π(δ12+δ22)1e−2(δ12+δ22)(u1−u2)2(8)
到此,两个高斯分布相乘的分布函数即推导出来,即相乘后的分布函数为一个被压缩或者放大的高斯分布,
S
g
S_g
Sg 为缩放因子,相乘后的概率密度的积分不等于1,但其方差和均值性质不变,所以
N
=
N
1
×
N
2
∼
(
u
,
δ
2
)
N =N_1\times N_2∼(u,\delta^2)
N=N1×N2∼(u,δ2),也就是我们常说两个高斯分布相乘同样服从高斯分布。
在Kalman滤波中的系统矫正环节中,实际是融合估计值和观测值,使用Kalman滤波都是假设这两者的分布服从高斯分布,各有各的期望和方差。计算Kalman的最优估计的本质就是在计算合成的 u u u。
这里我们再研究一下缩放因子 S g S_g Sg。可以看出,
- ① 当 S g < 1 S_g<1 Sg<1 时,概率分布被压缩;
- ② 当 S g > 1 S_g>1 Sg>1 时,概率分布被放大;
平时我们大多数情况下会看到情况①,那什么情况下才能出现情况②呢???
进行如下分部分析:
S
g
=
1
2
π
(
δ
1
2
+
δ
2
2
)
e
−
(
u
1
−
u
2
)
2
2
(
δ
1
2
+
δ
2
2
)
=
p
(
x
)
q
(
x
)
(9)
S_g=\frac{1}{\sqrt{2\pi(\delta_1^2+\delta_2^2)}}e^{-\frac{(u_1-u_2)^2}{2(\delta_1^2+\delta_2^2)}}=\frac{p(x)}{q(x)}\tag{9}
Sg=2π(δ12+δ22)1e−2(δ12+δ22)(u1−u2)2=q(x)p(x)(9)
其中:
p
(
x
)
=
e
x
p
(
−
(
u
1
−
u
2
)
2
2
(
δ
1
2
+
δ
2
2
)
)
,
q
(
x
)
=
2
π
(
δ
1
2
+
δ
2
2
)
(10)
p(x)=exp\bigg(-\frac{(u_1-u_2)^2}{2(\delta_1^2+\delta_2^2)}\bigg),\ \ \ q(x)=\sqrt{2\pi(\delta_1^2+\delta_2^2)}\tag{10}
p(x)=exp(−2(δ12+δ22)(u1−u2)2), q(x)=2π(δ12+δ22)(10)
可以很容易的得到 p ( x ) > 0 p(x)>0 p(x)>0 , q ( x ) > 0 q(x)>0 q(x)>0 ,当 S g < 1 S_g<1 Sg<1 时, p ( x ) < q ( x ) p(x)<q(x) p(x)<q(x) , 当 S g > 1 S_g>1 Sg>1 时, p ( x ) > q ( x ) p(x)>q(x) p(x)>q(x) , 因此这里问题转化为判断 p ( x ) , q ( x ) p(x),q(x) p(x),q(x) 的大小。
设自变量
x
=
δ
1
2
+
δ
2
2
x=\delta_1^2+\delta_2^2
x=δ12+δ22 ,
N
=
(
u
1
−
u
2
)
2
N=(u_1-u_2)^2
N=(u1−u2)2 ,则
x
>
0
x>0
x>0 ,
N
>
0
N>0
N>0
p
(
x
)
=
e
x
p
(
−
N
2
x
)
,
q
(
x
)
=
2
π
x
(11)
p(x)=exp\bigg(-\frac{N}{2x}\bigg),\ \ \ q(x)=\sqrt{2\pi x}\tag{11}
p(x)=exp(−2xN), q(x)=2πx(11)
如下是仿真计算 :
q
(
x
)
q(x)
q(x) 是条固定的曲线,
p
(
x
)
p(x)
p(x) 是根据N移动的曲线蔟,大多数情况会出现
p
(
x
)
<
q
(
x
)
p(x)<q(x)
p(x)<q(x)(情况①)
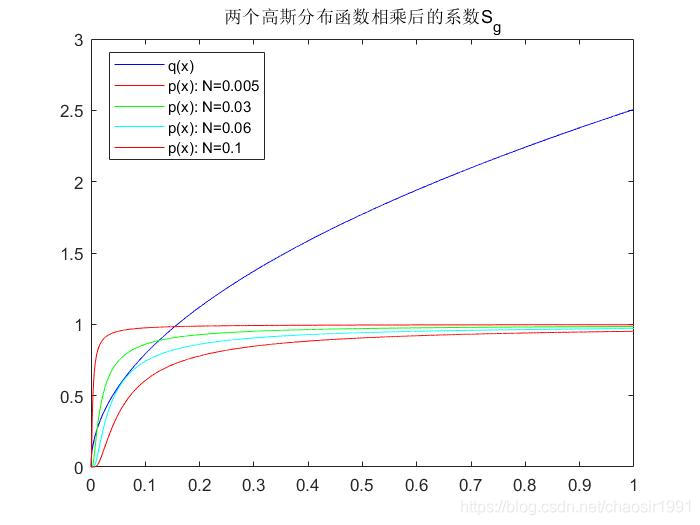
可以得出如下结论:
- 当 N > 0.06 N>0.06 N>0.06 时,不可能出现情况②
- 当
0
<
N
<
0.06
0<N<0.06
0<N<0.06 时,且
a
<
x
<
b
a<x<b
a<x<b(其中
a
,
b
a,b
a,b为两交点,
a
>
0
,
b
<
1
2
π
a>0,b<\frac{1}{2\pi}
a>0,b<2π1),出现情况②
我们手动仿真了一些情况,如下
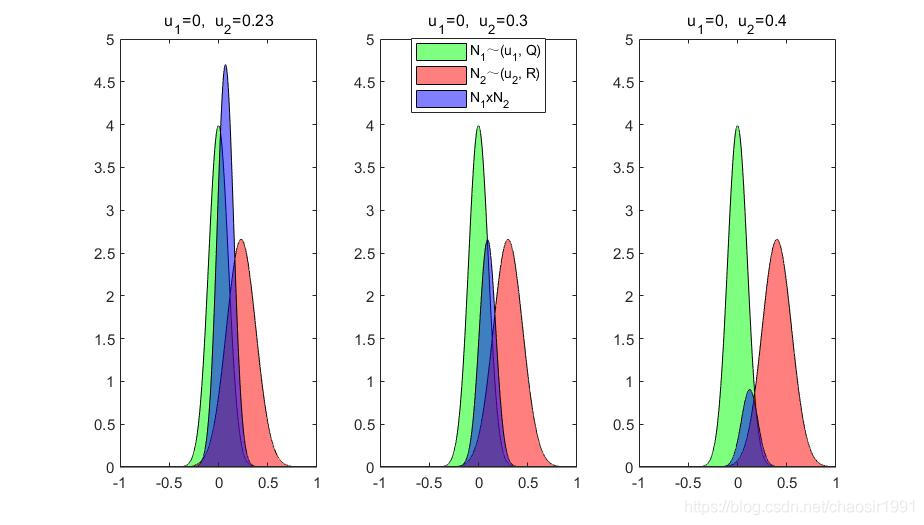
当可以通过 S g S_g Sg 来判断当前的融合概率是否是被增强还是削弱时,我们是否也可以同时用来判断融合的有效性。在机器人定位中,利用Kalman融合后,可以利用 S g S_g Sg 判断定位融合是否有效。
- 预测和测量相差很远时, S g S_g Sg 就变小,融合分布概率分散,真实位置概率变小;
- 预测和测量相差很近时,且方差很小时,融合分布概率更集中,真实位置概率变大
如此我们可以设置一个阈值来判断当前融合的有效性。