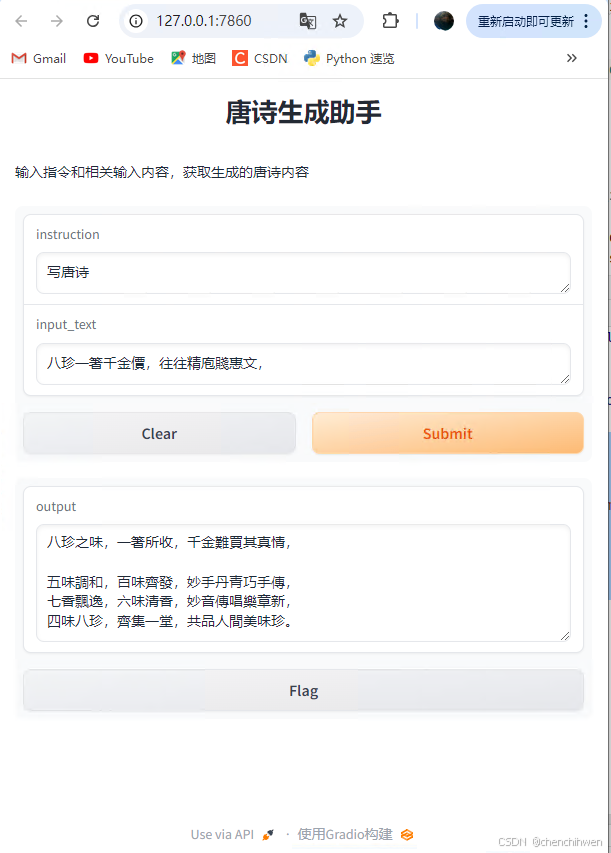
以下代码示范如何调用已经微调后的大语言模型,调用本地模型
先决条件
已经有了本地训练好的大语言模型,如何训练可以参考我的博文
 https://blog.csdn.net/chenchihwen/article/details/144000079?sharetype=blogdetail&sharerId=144000079&sharerefer=PC&sharesource=chenchihwen&spm=1011.2480.3001.8118
https://blog.csdn.net/chenchihwen/article/details/144000079?sharetype=blogdetail&sharerId=144000079&sharerefer=PC&sharesource=chenchihwen&spm=1011.2480.3001.8118代码解释
- 路径相关设置调整:
- 我的代码工作目录(
E:\hw2024\hw5),明确指定了work_dir变量的值,后续加载模型、分词器等相关的路径都基于这个工作目录来进行合理设置,确保能正确找到对应的文件。例如,模型所在目录指定为训练代码中保存模型检查点的checkpoint目录(通过os.path.join(work_dir, "checkpoint")构建路径),分词器加载路径根据模型名称及训练代码中的相关设置进行调整(os.path.join(work_dir, "TAIDE-LX-7B-Chat")),使其与训练时的配置相对应,保证可以准确加载到合适的模型和分词器。
- 我的代码工作目录(
- 加载模型和分词器步骤:
- 首先通过
AutoTokenizer.from_pretrained按照调整后的路径加载分词器,用于将用户输入的文本转换为模型可处理的令牌形式,添加结束令牌(eos_token)以符合模型输入的格式要求。 - 接着使用
AutoModelForCausalLM.from_pretrained结合量化配置从指定的模型目录(model_path)加载预训练模型,这个配置与训练时保持一致,便于模型能正确地加载到内存中,特别是在涉及到量化存储(如 4 位量化等情况)的模型时,确保加载过程不出错。由于训练时使用了PEFT(这里是LORA微调),再通过PeftModel.from_pretrained从同样的模型路径加载对应的PEFT模型,进一步将PEFT相关配置应用到已加载的模型上。最后可以选择执行model = model.merge_and_unload(),将PEFT适配器合并到模型主体中,使模型成为一个独立完整的结构,方便后续的使用和部署(这一步是否执行取决于实际需求,比如是否希望模型以一个完整独立的状态进行推理等情况)。
- 首先通过
- 生成回复函数:
generate_response函数的功能与之前训练代码中的逻辑类似,用于根据用户输入的指令以及可选的输入文本生成唐诗内容。它先构建符合模型输入格式要求的提示文本(prompt),通过分词器将其转换为张量形式的输入(input_ids),在无梯度计算(torch.no_grad())的环境下调用模型的generate方法,传入如生成最大新令牌数、采样策略、温度等生成参数来控制生成唐诗的具体表现(比如长度、多样性等方面),最后对模型生成的输出进行解码和格式处理(去除一些辅助标记等),返回最终的唐诗文本内容作为函数结果。 - 创建并启动 Gradio 界面:
- 使用
gr.Interface创建一个Gradio界面,指定了调用的函数(generate_response),输入组件设置为两个文本输入框,分别用于接收用户输入的指令和相关输入文本,输出组件为一个文本输出框,用于展示模型生成的唐诗内容。同时设置了界面的标题("唐诗生成助手")和描述信息(说明功能是输入指令和相关内容获取唐诗内容),方便用户清晰地了解界面用途和操作方法。 - 最后通过
iface.launch()启动Gradio服务,启动后在浏览器中打开对应的地址(终端会显示相关提示信息告知地址)就可以进行交互操作,输入相应的指令和文本内容,获取模型生成的唐诗了。
- 使用
你可以根据实际需求对代码中的一些参数进行适当调整,比如 max_new_tokens 可以控制生成唐诗的长度,生成相关的其他参数(如 temperature、top_p 等)可以影响唐诗的风格和多样性等特性,使其更符合你的期望和实际使用场景。同时,也要确保运行环境中相应的硬件资源(如 GPU,如果使用的话)配置正确,以保障模型推理过程的效率和稳定性。
代码
import gradio as gr
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
import os
# 工作目录(根据你提供的训练代码中的设置,修改为实际的工作目录路径)
work_dir = "E:\\hw2024\\hw5"
# 模型所在目录(假设训练好的模型保存在训练代码中的检查点目录下,你可根据实际情况调整)
model_path = os.path.join(work_dir, "checkpoint")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
os.path.join(work_dir, "TAIDE-LX-7B-Chat"), # 这里根据你的模型名称及训练代码中的相关路径设置来指定加载路径,确保能正确加载
add_eos_token=True
)
# 加载预训练模型(配置量化相关参数,和训练时加载方式类似,保持一致性确保模型能正确加载)
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
),
low_cpu_mem_usage=True
)
# 加载对应的PEFT模型(因为训练时使用了LORA微调,这里按相应方式加载)
model = PeftModel.from_pretrained(model, model_path)
# 合并并卸载PEFT相关的适配器,使得模型成为一个独立的完整模型(可选操作,根据实际需求决定是否执行)
model = model.merge_and_unload()
# 定义生成回复的函数
def generate_response(instruction, input_text=""):
prompt = f"""\
[INST] <<SYS>>
You are a helpful assistant and good at writing Tang poem. 你是一个乐于助人的助手且擅长写唐诗。
<</SYS>>
{instruction}
{input_text}
[/INST]"""
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"].cuda() if torch.cuda.is_available() else inputs["input_ids"]
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=128, # 可根据需要调整生成的唐诗长度
do_sample=True,
temperature=0.1,
num_beams=1,
top_p=0.3,
no_repeat_ngram_size=3,
pad_token_id=tokenizer.pad_token_id
)
output = tokenizer.decode(generation_output[0])
output = output.split("[/INST]")[1].replace("</s>", "").replace("<s>", "").replace("Assistant:", "").replace("Assistant", "").strip()
return output
# 创建Gradio界面
iface = gr.Interface(
fn=generate_response,
inputs=["text", "text"], # 两个文本输入框,分别对应指令和输入文本
outputs="text",
title="唐诗生成助手",
description="输入指令和相关输入内容,获取生成的唐诗内容"
)
# 启动Gradio服务
iface.launch()代码执行结果
PyDev console: starting.
Python 3.9.17 (main, Jul 5 2023, 20:47:11) [MSC v.1916 64 bit (AMD64)] on win32
runfile('E:/hw2024/hw5/Use_Local_LLM.py', wdir='E:/hw2024/hw5')
You set `add_prefix_space`. The tokenizer needs to be converted from the slow tokenizers
Loading checkpoint shards: 100%|██████████| 3/3 [00:35<00:00, 11.88s/it]
C:\ProgramData\anaconda3\envs\pytorch\lib\site-packages\peft\tuners\lora\bnb.py:272: UserWarning: Merge lora module to 4-bit linear may get different generations due to rounding errors.
warnings.warn(
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
IMPORTANT: You are using gradio version 3.41.2, however version 4.44.1 is available, please upgrade.点击链接地址就可以调用本地的大模型了