1,对象在堆内存中的存储格式;
2,数据类型的大小;
3,使用工具获取对象大小;
1,对象在堆内存中的存储格式;
在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。

对象头(Header)
1)MarkWord: 用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为4个字节和8个字节,官方称它为“MarkWord”。
2)klass指针:对象头的另外一部分是klass,类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例.
3)length : 普通对象内存结构和数组对象的内存结构不同,如果对象是java数组,那在对象头中还必须有一块用于记录数组长度的数据。所以会用4个字节的int来记录数组的长度。
实例数据区
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
对齐填充(如何理解对齐填充?)
由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,这就要求当不为8字节整数倍时,就需要填充数据对齐填充。如此规定的原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。

2,数据类型的大小;
在虚拟机中,对象的字段是有基本数据类型和引用数据类型组成的,其所占用的空间大小如下:
如果有字段是引用类型,并且64位开启指针压缩,占用四个字节。
对于引用的大小,不同位数JVM会有区别。在 32 位的 JVM 上,一个对象引用占用 4 个字节;在 64 位上,占用 8 个字节,开启指针压缩情况下占用4个字节。

是否开启指针压缩?
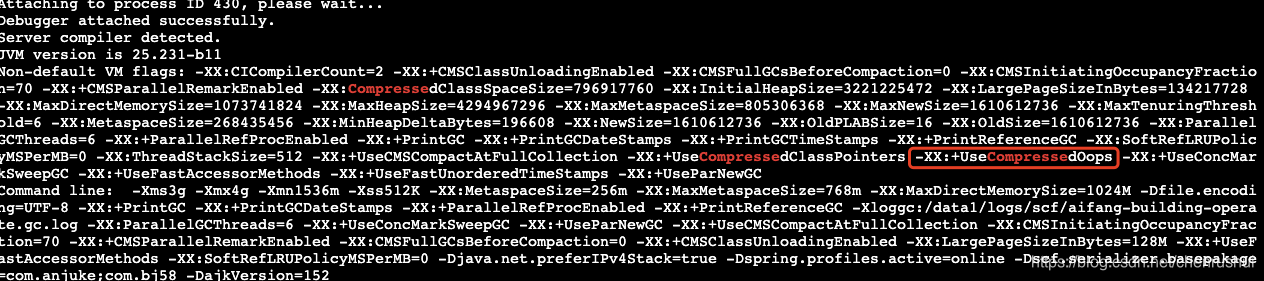
3,使用工具获取对象大小;
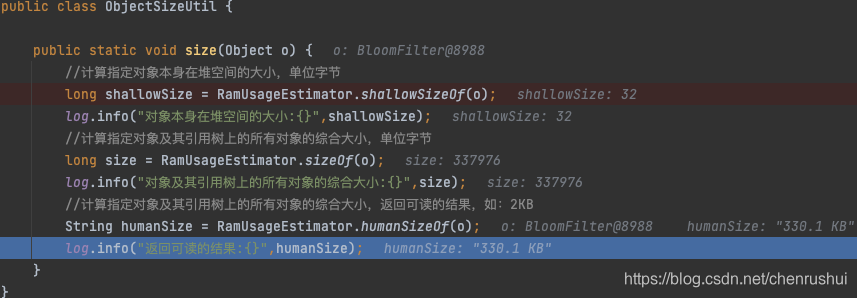
通过计算Java对象头、实例数据、引用等的大小,相加而得,如果有引用,还能递归计算引用对象的大小。
RamUsageEstimator的源码并不多,几百行,清晰可读。这里不进行一一解读了。
它在初始化的时候会根据当前JVM运行环境、CPU架构、运行参数、是否开启指针压缩、JDK版本等综合计算对象头的大小,而实例数据部分则按照java基础数据类型的标准大小进行计算。
public class ObjectSize {
String str; //引用类型 4
int a; //int 4
byte b1; //1
byte b2; //1
int i2; //4
Object obj; //4
byte b3; //1
//总的大小40: 8(对象头)+4(指针)+4(String)+4(int)+1(byte)+1(byte)+2(padding)+4(int)+4(int)+1(byte)+7(padding)
//不足8位,补足8位。
//我们计算的大小是40,但是通过代码测出的是32?
} 我们计算的大小是40,但是通过代码测出的是32?
这是因为hotspot创建对象时进行了排序,HotSpot创建的对象的字段会先按照给定顺序排列,默认的顺序为:从长到短排列,引用排最后:
long/double –> int/float –> short/char –> byte/boolean –> Reference。
我们重新计算对象所占内存大小得:
Size(ObjectA) = Size(对象头(_mark)) + size(oop指针) + size(排序后数据区)
Size(ObjectA) = 8 + 4 + 4(int) + 4(int) + byte(1) + byte(1) + 2(padding) + 4(String) + 4(ObjectB指针)
Size(ObjectA) = 32
与上面计算结果一致。