Tesseract-ocr 简介
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护。
Tesseract-ocr 下载地址
大家可以根据自己的需求下载不同的版本,下载网址:https://digi.bib.uni-mannheim.de/tesseract/
,我这里下载的是win10 64位的:tesseract-ocr-w64-setup-v5.0.0.20190623.exe。
安装tesseract-ocr
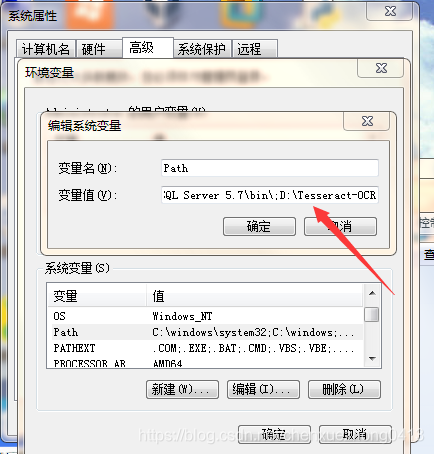
双击tesseract-ocr-w64-setup-v5.0.0.20190623.exe运行即可安装,安装完成后将安装路径配置环境变量,我这里安装路径是在D盘,如下图所示:
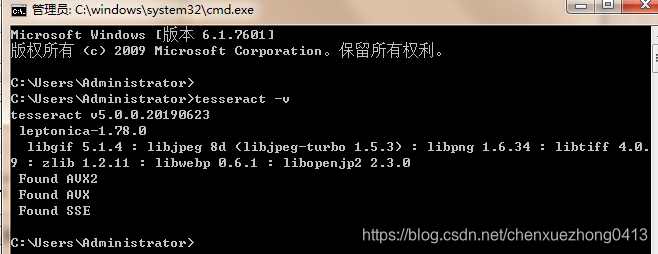
环境变量配置好后,验证是否安装成功,直接cmd输入命令,结果输出如下表示安装OK:
tesseract -v
python环境中使用Tesseract-ocr
需要安装PIL包和Pillow包以及pytesseract模块,使用如下命令安装就好了,
pip install pillow #一个python的图像处理库,pytesseract依赖
pip install pytesseract
Tesseract-ocr的使用
1.测试识别图test2.jpg纯数字,如下:
python代码如下,识别test2.jpg图中数字:
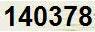
# 导入pytesseract库
import pytesseract
# 导入Image库
from PIL import Image
def OCR_demo():
# 导入OCR安装路径
pytesseract.pytesseract.tesseract_cmd = r"D:\Tesseract-OCR\tesseract.exe"
# 打开要识别的图片
image = Image.open('D:\share\\test2.jpg')
# 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片
text = pytesseract.image_to_string(image)
print(text)
if __name__ == '__main__':
OCR_demo()
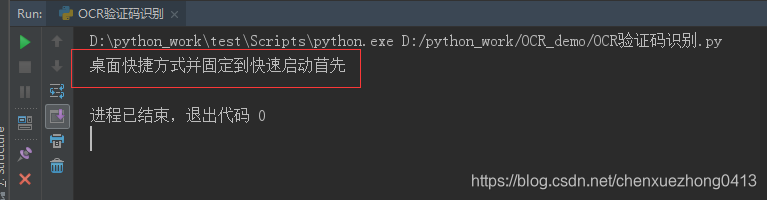
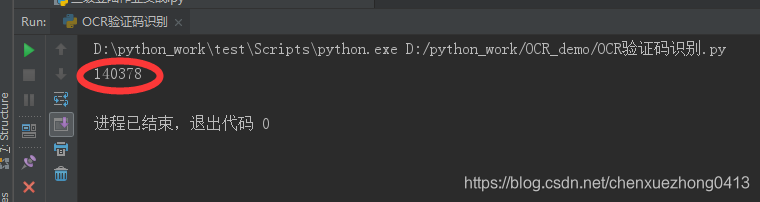
运行以上程序,输出结果如下:
可以看到识别效果还是很不错的,当然手写数字也一样可以识别,相对来说识别效果差一点而已,
2.测试a.png图片中的中文字符,图片如下:
将上述代码稍作修改即可,如下:

#只需要修改如下代码,增加lang='chi_sim_v3'属性值,选择要识别的语言为简体中文数据集
text = pytesseract.image_to_string(image,lang='chi_sim_v3')
程序运行结果如下:
可以看识别效果,识别率在90%以上,当然这里也有调优的余地,比如给图片做灰度,模糊,去燥,二值化等等,识别率会更好一些。