代码以及视频讲解
本文所涉及所有资源均在传知代码平台可获取
概述
本文基于论文 [Simple Baselines for Human Pose Estimation and Tracking[1]](ECCV 2018 Open Access Repository (thecvf.com)) 实现手部姿态估计。
手部姿态估计是从图像或视频帧集中找到手部关节位置的任务。近年来,姿态估计取得了显著进展。同时,姿态估计相关算法和系统的复杂性也在增加,使得算法分析和比较变得更加困难。
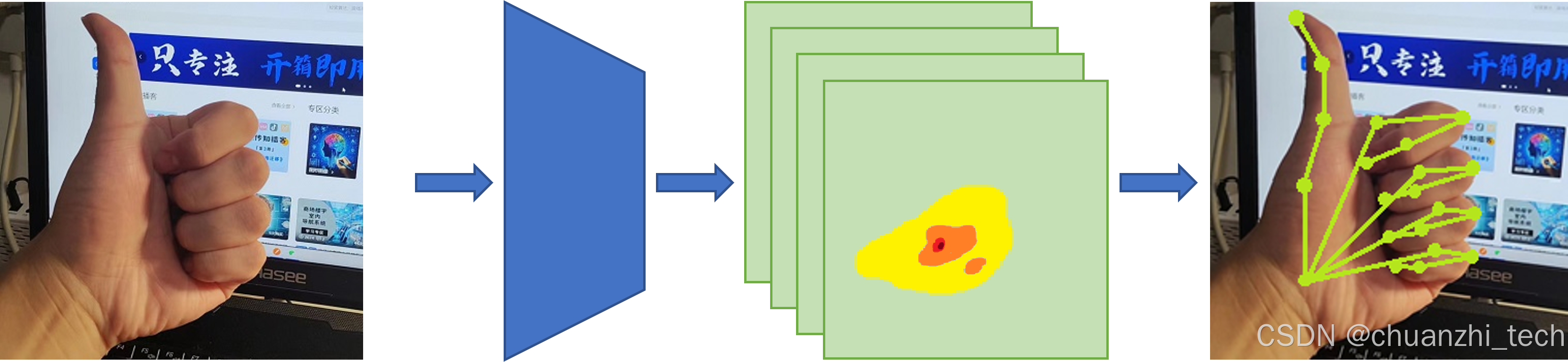
对此,该论文[1]提供了简单且有效的基线方法。具体来说,该论文所提出的姿态估计方法基于在骨干网络 ResNet 上添加的几个反卷积层,以此从深层和低分辨率特征图估计热图(Heatmap)。
算法原理
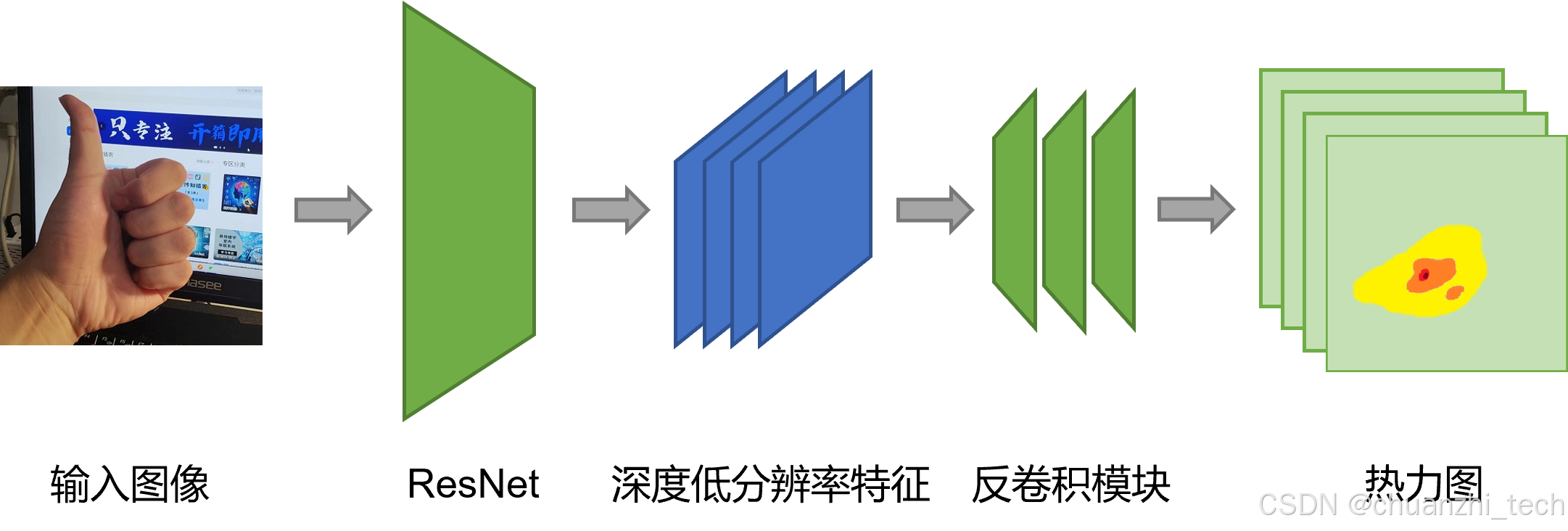
ResNet [2] 是图像特征提取中最常见的骨干网络,也常常被用于姿态估计。本文所使用的模型在 ResNet 的最后一个卷积阶段上简单添加了几个反卷积层。基于这种方式,其可以利用深层和低分辨率的特征生成热图,并基于热图估计关节位置。整个网络结构如图 2 所示,其使用了三个具有批量归一化和 ReLU 激活的反卷积层。每层有256个 4×4 内核的滤波器,步幅为 2。最后添加一个 1×1 的卷积层,以生成所有 k k k 个关键点的预测热图。
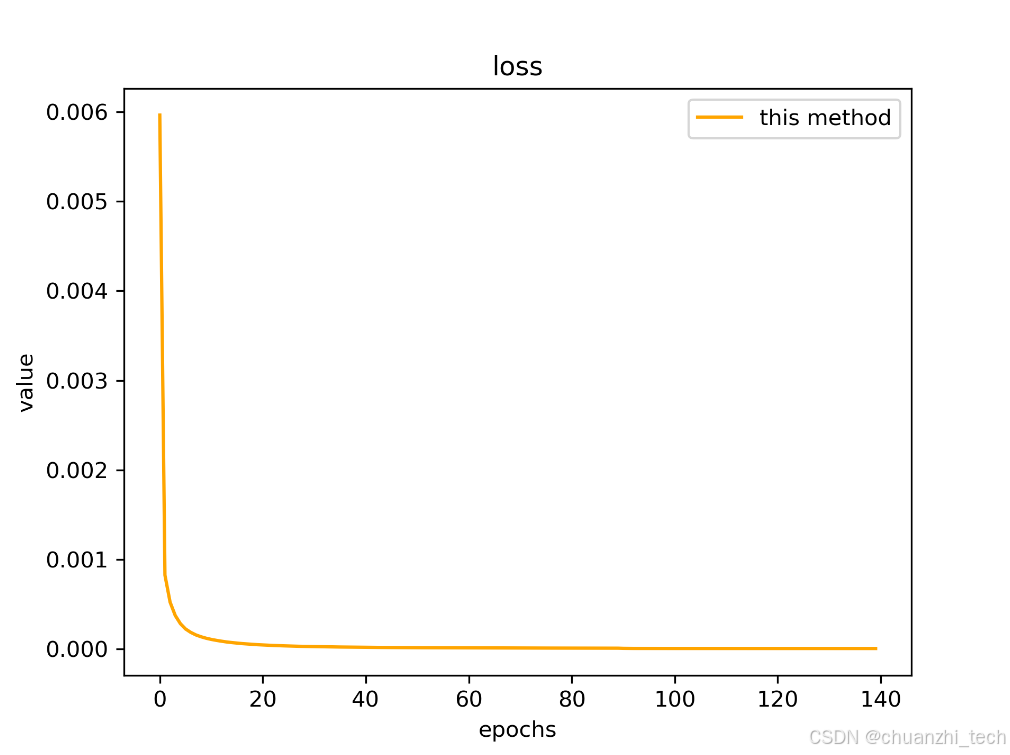
均方误差 (MSE) 被用作预测热图和目标热图之间的损失。关节 k k k 的目标热图是通过在第 k k k 个关节的真实位置上应用二维高斯分布生成的。训练过程中的损失变化如图3所示。我选取了 FreiHand[3] 作为数据集,ResNet-18 作为骨干网络进行训练。FreiHand 的训练集包含 130240 张尺寸为 224 × 224 的RGB图像。
将训练完成后的模型应用于FreiHAND测试集,得到结果如图4所示

核心逻辑
模型结构如下所示:
import torch
import torch.nn as nn
import torchvision.models as models
class PoseNetwork(nn.Module):
def __init__(self, joints_num=21, depth=50, pretrained=False):
super(PoseNetwork, self).__init__()
if pretrained:
weights = 'DEFAULT'
else:
weights = None
if depth == 18:
resnet = models.resnet18(weights = weights)
elif depth == 34:
resnet = models.resnet34(weights = weights)
elif depth == 50:
resnet = models.resnet50(weights = weights)
elif depth == 101:
resnet = models.resnet101(weights = weights)
elif depth == 152:
resnet = models.resnet152(weights = weights)
else:
resnet = models.resnet50()
self.encoder = nn.Sequential(*list(resnet.children())[:-2])
self.decoder = nn.Sequential(
nn.ConvTranspose2d(resnet.inplanes, 256, kernel_size=4, stride=2, padding=1, output_padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(256, 256, kernel_size=4, stride=2, padding=1, output_padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(256, 256, kernel_size=4, stride=2, padding=1, output_padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, joints_num, kernel_size=1, stride=1)
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
以上代码仅作展示,更详细的代码文件请参见附件。
效果演示
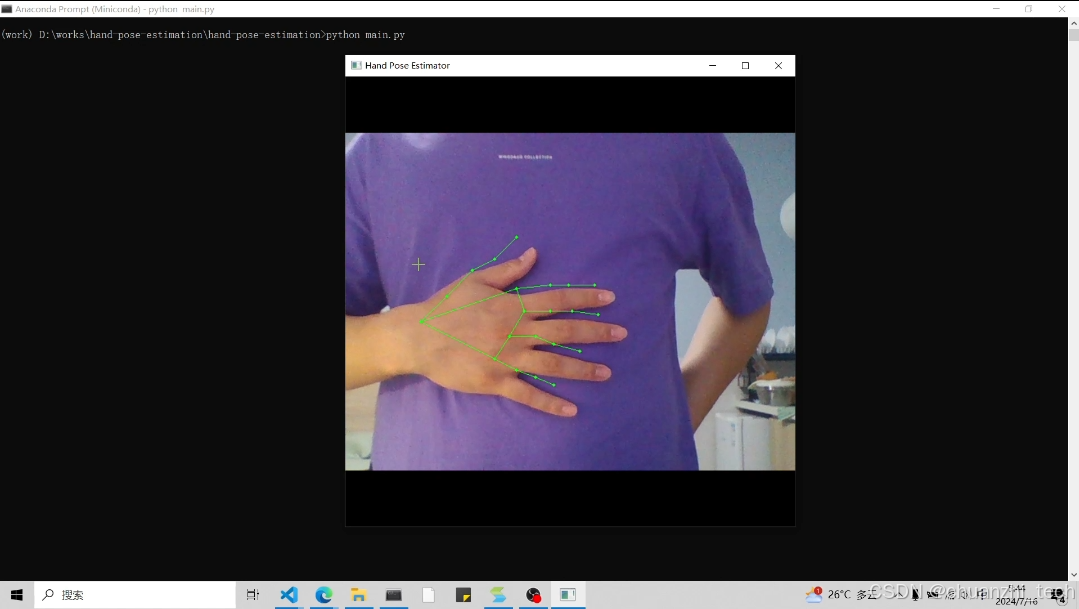
配置环境并运行 main.py脚本,效果如图4所示。
此外,网站还提供了在线体验功能。用户只需要输入一张大小不超过 1MB 的单手 JPG 图像,网站就会标记出图中手的姿势,如图6所示。
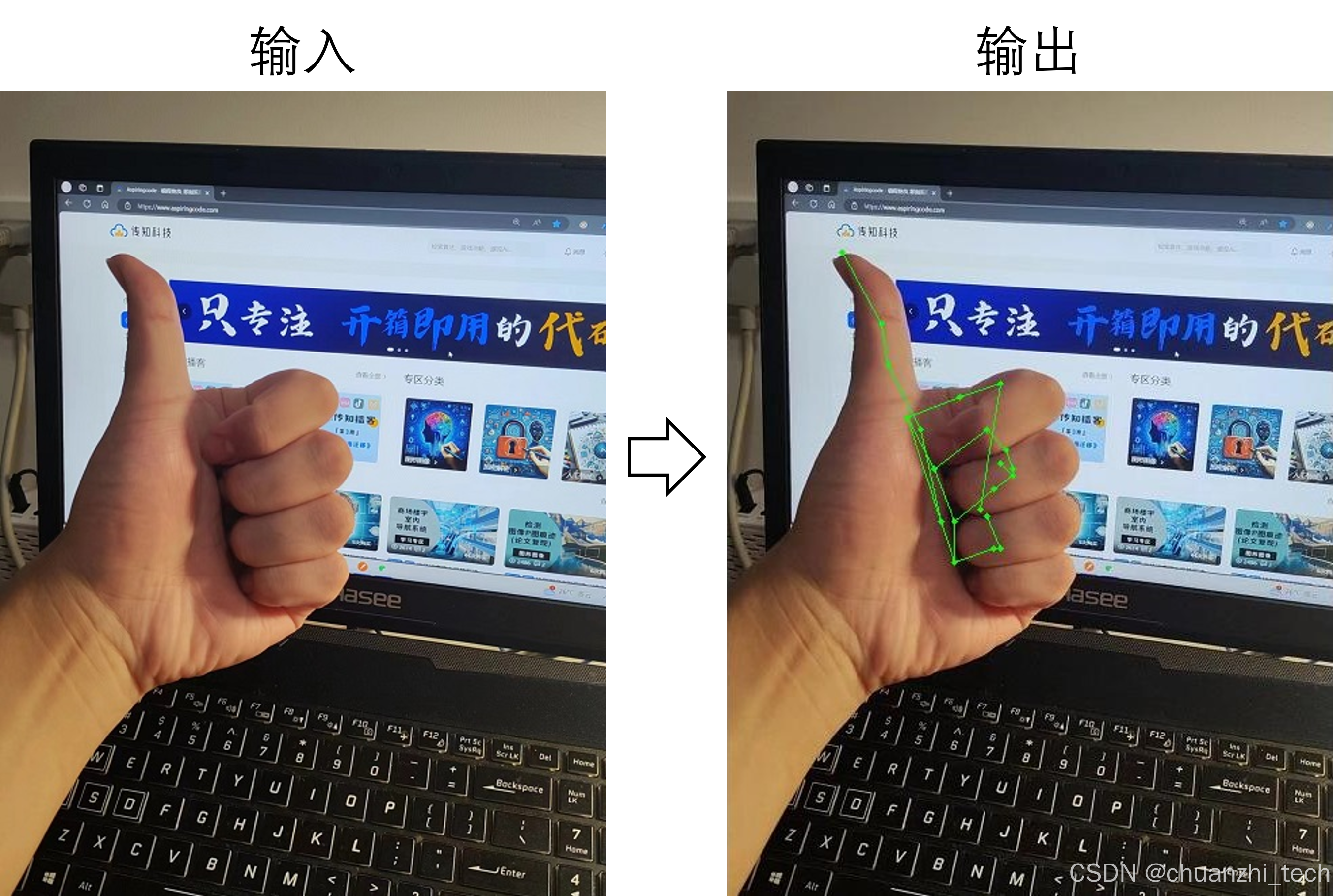
使用方式
- 解压附件压缩包并进入工作目录。如果是Linux系统,请使用如下命令:
unzip hand-pose-estimation.zip
cd hand-pose-estimation
- 代码的运行环境可通过如下命令进行配置:
pip install -r requirements.txt
- 如果希望在本地运行实时手势识别程序,请运行如下命令:
python main.py
- 如果希望在本地运行训练模型,请运行如下命令:
python main.py -r "train"
- 请注意,训练前需要自行制作或下载并处理相关公开数据集,具体格式可以参考我事先基于FreiHAND制作的一个迷你的样例数据集,其位于
data\datasets\mini-example。 - 如果希望在线部署,请运行如下命令:
python main-flask.py
参考文献
[1] Xiao B, Wu H, Wei Y. Simple baselines for human pose estimation and tracking[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 466-481.
[2] Targ S, Almeida D, Lyman K. Resnet in resnet: Generalizing residual architectures[J]. arXiv preprint arXiv:1603.08029, 2016.
[3] Zimmermann C, Ceylan D, Yang J, et al. Freihand: A dataset for markerless capture of hand pose and shape from single rgb images[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 813-822.