二叉树搜索树(下)

二叉搜索树key和key/value使用场景
key搜索场景
只有key作为关键码,结构中只需要存储key即可,关键码即为需要搜索到的值,搜索场景只需要判断 key在不在。key的搜索场景实现的二叉树搜索树支持增删查,但是不支持修改,修改key破坏搜索树结构了。
场景1:⼩区无⼈值守⻋库,⼩区⻋库买了⻋位的业主⻋才能进⼩区,那么物业会把买了⻋位的业主的⻋牌号录⼊后台系统,⻋辆进⼊时扫描⻋牌在不在系统中,在则抬杆,不在则提⽰⾮本⼩区⻋辆,⽆法进⼊。
场景2:检查⼀篇英⽂⽂章单词拼写是否正确,将词库中所有单词放⼊二叉搜索树,读取文章中的单词,查找是否在二叉搜索树中,不在则波浪线标红提示。
可以通俗地说,只有key作为关键码,就是判断在不在的问题。
key/value搜索场景
每⼀个关键码key,都有与之对应的值value,value可以任意类型对象。树的结构中(结点)除了需要存储key还要存储对应的value,增/删/查还是以key为关键字⾛二叉搜索树的规则进⾏⽐较,可以快速查找到key对应的value。key/value的搜索场景实现的二叉树搜索树⽀持修改,但是不⽀持修改key,修改key破坏搜索树结构了,可以修改value。
场景1:简单中英互译字典,树的结构中(结点)存储key(英⽂)和vlaue(中⽂),搜索时输⼊英⽂,则同时查找到了英⽂对应的中⽂。
场景2:商场⽆⼈值守⻋库,⼊⼝进场时扫描⻋牌,记录⻋牌和⼊场时间,出⼝离场时,扫描⻋牌,查找⼊场时间,⽤当前时间-⼊场时间计算出停⻋时⻓,计算出停⻋费⽤,缴费后抬杆,⻋辆离场。
场景3:统计⼀篇⽂章中单词出现的次数,读取⼀个单词,查找单词是否存在,不存在这个说明第⼀次出现,(单词,1),单词存在,则++单词对应的次数。
我们可以用命名空间将我们之前写的只有key的搜索二叉树的代码进行隔离,再用另一个命名空间将接下来要写的key/value二叉搜索树的代码进行隔离。
参考代码:
namespace key
{
//之前写的只有key的二叉搜索树结构和方法定义代码
}
namespace key_value
{
template<class K,class V>
struct BSTNode
{
K _key;
V _value;
BSTNode<K,V>* _left;
BSTNode<K,V>* _right;
BSTNode(const K& key,const V& value)
:_key(key)
,_value(value)
, _left(nullptr)
, _right(nullptr)
{}
};
template<class K,class V>
class BSTree
{
using Node = BSTNode<K,V>;
public:
bool Insert(const K& key,const V& value)
{
if (_root == nullptr)
{
_root = new Node(key,value);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
return false;//避免冗余
}
//到这里说明cur已经找到空位置了,但是不知道是从右走的还是往左走的,得再比一次
cur = new Node(key,value);
if (key < parent->_key)
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
Node* Find(const K& key)//不再是返回布尔值
{
Node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
cur = cur->_left;
}
else if (key > cur->_key)
{
cur = cur->_right;
}
else
{
return cur;//返回结点指针,方便以后修改value
}
}
return nullptr;
}
bool Erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
if (cur->_left == nullptr)
{
//父为空,也就是说要删的是头结点
if (parent == nullptr)
{
_root = cur->_right;
}
else
{
//要判断父节点的左还是右指针指向cur的孩子
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_right;
}
}
delete cur;
return true;
}
//cur的右孩子为空,把cur的左孩子给父
else if (cur->_right == nullptr)
{
if (parent == nullptr)
{
_root = cur->_left;
}
else
{
//判断父节点的左还是右指针指向cur孩子
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
return true;
}
else//现在是cur的左右孩子都不为空
{
//第一步,找R(这里采用cur的右子树的最小结点/也就是最左结点)
Node* p = cur;//这里如果初始给空,后面如果不进循环,会造成对空指针的解引用
Node* r = cur->_right;
while (r->_left)
{
p = r;
r = r->_left;
}
//第二步,进行交换(但不用真的把cur的值再去给r)
cur->_key = r->_key;
//第三步,删除R——很容易考虑不全面!!删除R又要把删除的问题考虑全面,但这里不能用递归,会找不到
//在删除R时要把R的右孩子(只可能是右孩子)给给父,但是父的左还是右指针不确定
if (p->_right == r)
{
p->_right = r->_right;
}
else
{
p->_left = r->_right;
}
delete r;
return true;
}
}
}
return false;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_InOrder(root->_right);
}
Node* _root = nullptr;
};
}
词典
然后我们再通过一段程序来测试一下key_value版本二叉搜索树的代码是否有误:
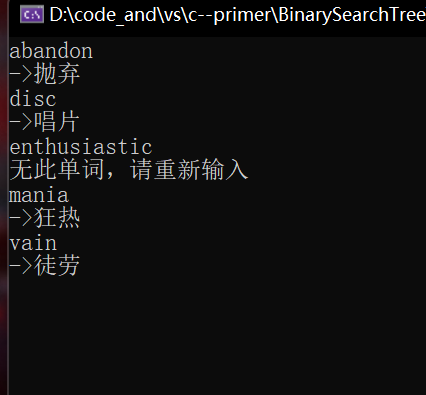
key_value::BSTree<string, string> dict;
dict.Insert("abandon", "抛弃");
dict.Insert("mania", "狂热");
dict.Insert("disc", "唱片");
dict.Insert("vain", "徒劳");
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << "->" << ret->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
这段程序里,我们通过key_value版本的二叉搜索树创建除了一个词典,然后while(cin>>str)里,cin>>str的返回值是istream类型的,可以通过operator bool转化成布尔类型(大致如此)。
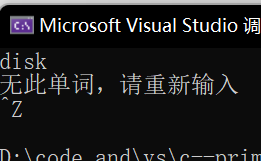
总之,效果是我们可以输入多个(个数不确定)string类型的数据,然后程序在这棵树(这本词典)里查找,如果找到了,就把它的value值也就是中文名打印出来,如果找不到会提示,想要退出就按ctrl+z(相当于给流设置了一个错误标志)。
统计次数
然后我们再来一段程序,来用key_value版本的二叉搜索树进行次数的统计:
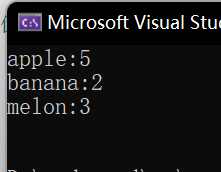
string arr[] = {"apple","melon","apple","melon","apple","apple","melon","banana","apple","banana"};
key_value::BSTree<string, int> countTree;
for (const auto& str : arr)//通过使用引用,减少赋值消耗
{
//先查找水果在不在搜索树
//1.不在,说明水果第一次出现,则插入<水果,1>
//2.在,则查找到的结点中水果对应的次数++
auto ret = countTree.Find(str);
if (ret == __nullptr)
{
countTree.Insert(str, 1);
}
else
{
//修改value
ret->_value++;
}
}
countTree.InOrder();
搜索二叉树的拷贝问题
key_value::BSTree<string, int> copy = countTree;
copy.InOrder();
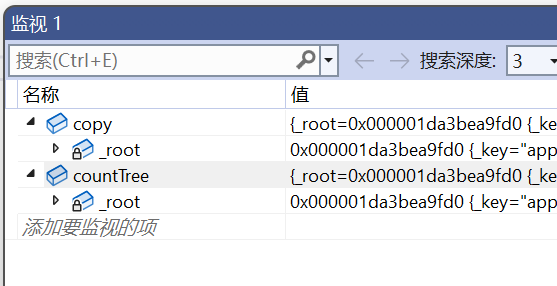
可以看到,copy和countTree里面的_root地址是一样的,说明是浅拷贝,而浅拷贝析构时会出问题(崩溃),我们需要的是深拷贝。
搜索树的析构有很多种写法,可以用循环去层序遍历地析构,但比较麻烦(析构一层的时候还得保存它的孩子)。
递归析构会简单一些。
public:
~BSTree()
{
Destroy(_root);
_root = nullptr;//别忘了
}
private:
void Destroy(Node* root)
{
if (root == nullptr)
return;
//后序析构
Destroy(root->_left);
Destroy(root->_right);
delete root;
}
这样写完析构之后,我们可以看看,在这样浅拷贝的情况下,析构时会崩溃:

要实现深拷贝,这里借助拷贝构造不好搞。
老老实实使用前序进行拷贝。
一个个插入不行,如果使用中序遍历一个个插入,形状就变了。
BSTree(const BSTree& t)
{
_root = Copy(t._root);
}
Node* Copy(Node* root)
{
if (root == nullptr)
return nullptr;
//前序
Node* newRoot = new Node(root->_key, root->_value);
newRoot->_left = Copy(root->_left);
newRoot->_right = Copy(root->_right);
return newRoot;
}
这时我们还有一个报错:没有合适的默认构造可以用。因为默认构造生成的前提是我们没有写任何的构造,而现在我们写了拷贝构造。
C++11为我们提供了关键字default:
BSTree() = default;
然后是赋值重载,这我们就可以考虑用现代写法了:
BSTree& operator=(BSTree tmp)
{
swap(_root, tmp._root);
return *this;
}
这里我们将要赋的值传值传参给tmp,传值传参会调用拷贝构造,tmp就是我们要的,我们将其root与 *this的root直接交换,在这个函数结束后tmp会自动销毁,把tmp现在的root也就是 *this原本的root带走。最后我们选择返回引用类型,减少消耗。