文章目录
1.MySQL中的日志文件
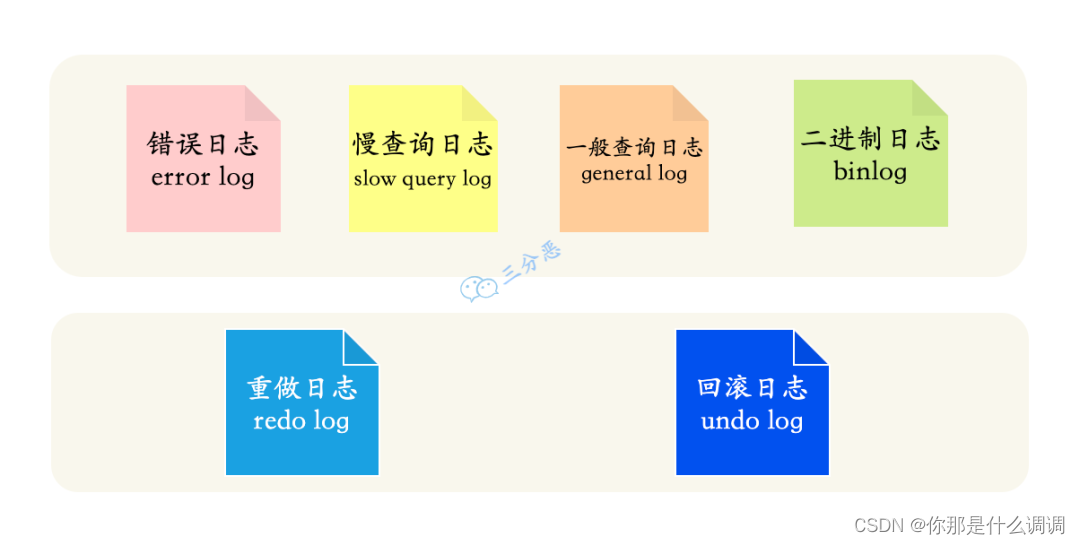
- 错误日志(error log):对MySQL的启动、运行、关闭过程进行了记录,能帮助定位MySQL问题。
- 慢查询日志(slow query log):用来记录执行时间超过 long_query_time 这个变量定义的时长的查询语句。通过慢查询日志,可以查找出哪些查询语句的执行效率很低,以便进行优化。
- 一般查询日志(general log):记录了所有对MySQL数据库请求的信息,无论请求是否正确执行。
- 二进制日志(bin log):记录了数据库所有执行的DDL和DML语句(除了数据查询语句select、show等),以事件形式记录并保存在二进制文件中。
InnoDB存储引擎特有的日志文件:
- 重做日志(redo log):记录了对于InnoDB存储引擎的事务日志。
- 回滚日志(undo log):回滚日志的作用就是对数据进行回滚。当事务对数据库进行修改,InnoDB引擎不仅会记录redo log,还会生成对应的undo log日志;如果事务执行失败或调用了rollback,导致事务需要回滚,就可以利用undo log中的信息将数据回滚到修改之前的样子。
show variables like '%log%'; 查看上述日志是否开启,以及日志的地址
2.bin log的作用
主要有两个作用:主从复制 和 恢复数据
- MySQL在公司使用的时候往往都是一主多从结构的,从服务器需要与主服务器的数据保持一致,这就是通过binlog来实现的。
- 数据库的数据被干掉了,我们可以通过binlog来对数据进行恢复。
3.redo log的作用
假设有一条sql语句:
update user_table set name='java3y' where id = '3'
MySQL执行这条SQL语句,是先把id=3的这条记录查出来,然后将name字段给改掉。
实际上Mysql的基本存储结构是页(记录都存在页里边),所以MySQL是先把这条记录所在的页找到,然后把该页加载到内存中,将对应记录进行修改。
现在就可能存在一个问题:如果在内存中把数据改了,还没来得及落磁盘,而此时的数据库挂了怎么办?显然这次更改就丢了。
如果每个请求都需要将数据立马落磁盘之后,那速度会很慢,MySQL可能也顶不住。所以MySQL是怎么做的呢?
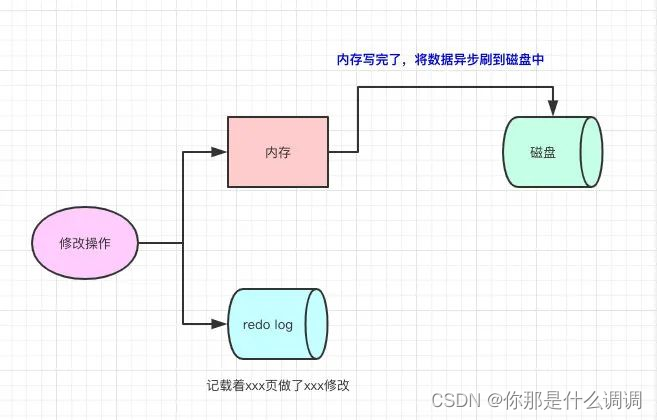
MySQL引入了redo log,内存写完了,然后会写一份redo log,这份redo log记载着这次在某个页上做了什么修改。
其实写redo log的时候,也会有buffer,是先写buffer,再真正落到磁盘中的。至于从buffer什么时候落磁盘,会有配置供我们配置。
写redo log也是需要写磁盘的,但它的好处就是顺序IO(我们都知道顺序IO比随机IO快非常多)。
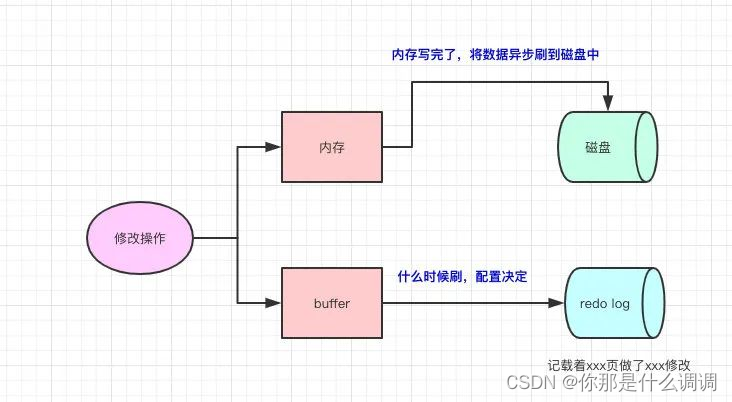
所以,redo log的存在为了:当我们修改的时候,写完内存了,但数据还没真正写到磁盘的时候。此时我们的数据库挂了,我们可以根据redo log来对数据进行恢复。因为redo log是顺序IO,所以写入的速度很快,并且redo log记载的是物理变化(xxxx页做了xxx修改),文件的体积很小,恢复速度很快。
4.bin log和redo log的区别
(1)存储的内容
- bin log记录InnoDB、MyISAM等存储引擎的日志。记载的是数据的逻辑变化,所有执行的DDL和DML语句(除了数据查询语句select、show等)。
- redo log记录InnoDB存储引擎的日志。记载的是数据的物理变化,物理修改内容(xxxx页修改了xxx)。
(2)功能
- bin log:主从复制和恢复
- 主从服务器需要保持数据的一致性,通过bin log来同步数据。
- 如果整个数据库的数据都被删除了,bin log存储着所有的数据变更情况,那么可以通过bin log来对数据进行恢复。
- redo log:持久化
- 写完内存,如果数据库挂了,那我们可以通过redo log来恢复内存还没来得及刷到磁盘的数据,将redo log加载到内存里边,那内存就能恢复到挂掉之前的数据了。
- 如果整个数据库的数据都被删除了,那我可以用redo log的记录来恢复吗?
- 不能。因为功能的不同,redo log 存储的是物理数据的变更,如果我们内存的数据已经刷到了磁盘了,那redo log的数据就无效了。所以redo log不会存储着历史所有数据的变更,文件的内容会被覆盖的。
(3)写入时间
- bin log:仅在事务提交前进行提交,也就是只写磁盘一次。
- redo log:事务进行的过程中不断写入。
(4)写入方式
- bin log:追加写入,不会覆盖已经写的文件。
- redo log:循环写入和擦除。
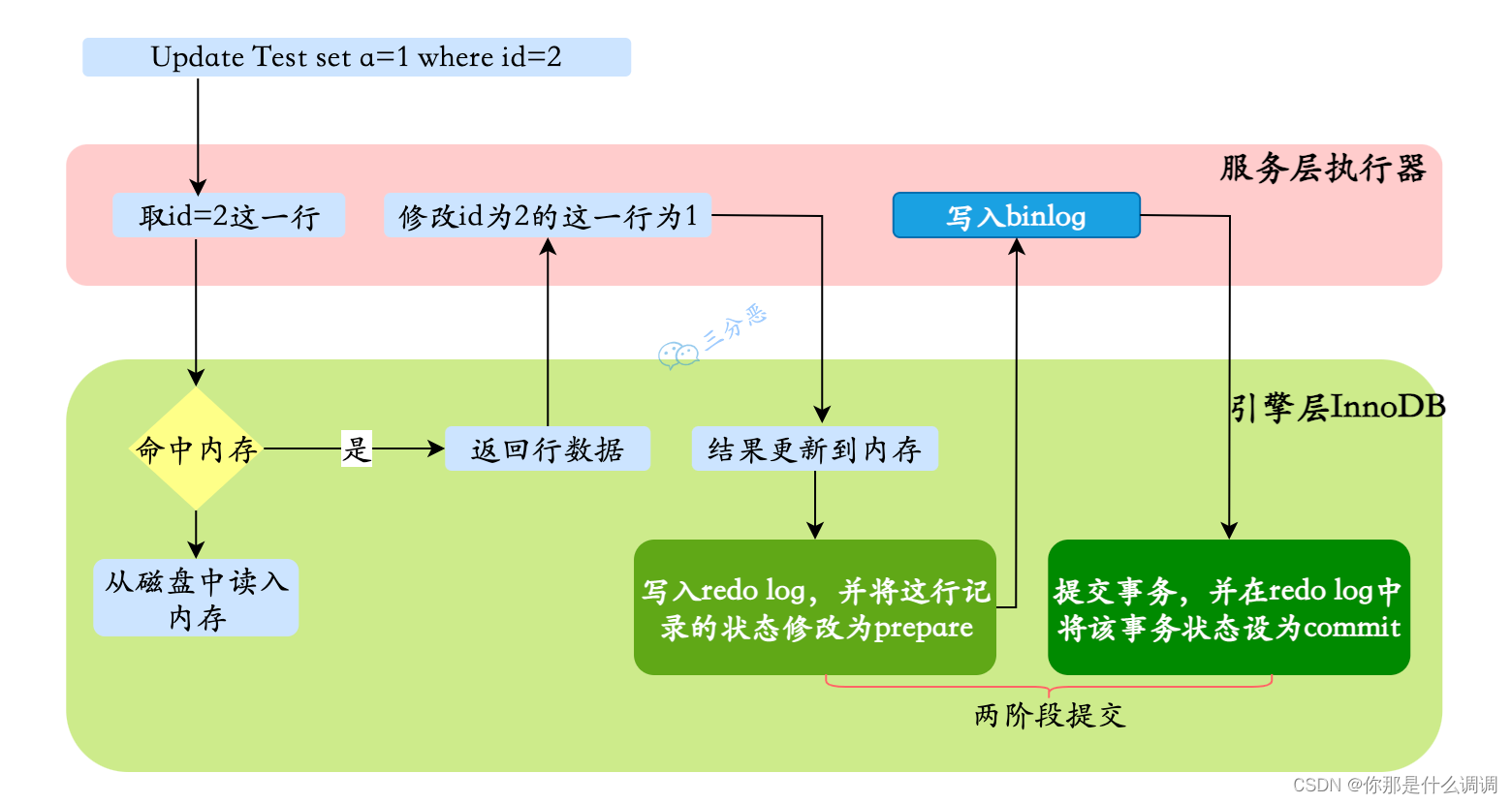
5.两阶段提交
- 执行器先找引擎获取ID=2这一行。ID是主键,存储引擎检索数据,找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的binlog,并把binlog写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
从上图可以看出,MySQL在执行更新语句的时候,在服务层进行语句的解析和执行,在引擎层进行数据的提取和存储;同时在服务层对binlog进行写入,在InnoDB内进行redo log的写入。
不仅如此,在对redo log写入时有两个阶段的提交,一是binlog写入之前prepare状态的写入,二是binlog写入之后commit状态的写入。
6.undo log的作用
undo log主要有两个作用:
- 回滚
- 多版本控制(MVCC)
在数据修改的时候,不仅记录了redo log,还记录undo log,如果因为某些原因导致事务失败或回滚了,可以用undo log进行回滚
undo log主要存储的也是逻辑日志,比如我们要insert一条数据了,那undo log会记录的一条对应的delete日志。我们要update一条记录时,它会记录一条对应相反的update记录。
这也应该容易理解,毕竟回滚嘛,跟需要修改的操作相反就好,这样就能达到回滚的目的。因为支持回滚操作,所以我们就能保证:“一个事务包含多个操作,这些操作要么全部执行,要么全都不执行”。【原子性】
因为undo log存储着修改之前的数据,相当于一个前版本,MVCC实现的是读写不阻塞,读的时候只要返回前一个版本的数据就行了。