泛型
泛型简介
JDK5.0以后新增的新特性
泛型的本质是数据类型的参数化,当处理的数据类型是不固定的时候,可以作为参数传入
数据类型的占位符,告诉编译器,调用泛型时必须传入实际类型,等同于方法定义时的形参
数据类型只能是引用类型
使用泛型的时候可以在编译阶段识别出类型转换的问题,提高了代码的安全性和可读性
泛型类
在类上定义泛型
泛型标记
| E Element | 在容器中使用,表示容器中的元素 |
|---|---|
| T Type | 表示普通的JAVA类 |
| K key | 表示键,Map中的键 |
| V value | 表示值 |
| N Number | 表示数值类型 |
| ? | 表示不确定的JAVA类型 |
语法结构
public class 类名<泛型标识符号>{
}
public class 类名<泛型标识符号1,泛型标识符号2>{
}
public class Generic<T> {
private T flag;
public void setFlag(T flag){
this.flag=flag;
}
public T getFlag(){
return this.flag;
}
public static void main(String[] args) {
Generic<String> generic=new Generic();
generic.setFlag("123");
String flag= generic.getFlag();
System.out.println(flag);
Generic<Integer> generic1=new Generic<>();
generic1.setFlag(123);
Integer flag1=generic1.getFlag();
System.out.println(flag1);
}
}
泛型接口
在接口的所有抽象方法在定义数据类型时可以直接使用泛型
语法结构
public interface 接口名<泛型标识符号>{}
public interface 接口名<泛型标识符号1,泛型标识符号2>
public interface IGeneric <T>{
T getName(T name);
}
//实现泛型接口时指定具体数据类型
public class IGenericImpl implements IGeneric<String>{
@Override
public String getName(String name) {
return name;
}
}
//使用泛型接口时指定具体数据类型
public class IGenericImpl2<T> implements IGeneric<T>{
@Override
public T getName(T name) {
return name;
}
}
public class Test {
public static void main(String[] args) {
//实现泛型接口时指定具体数据类型
IGeneric<String> iGeneric=new IGenericImpl();
String oldlu = iGeneric.getName("oldlu");
System.out.println(oldlu);
//使用泛型接口时指定具体数据类型
IGeneric<String> iGeneric1=new IGenericImpl2<>();
String itbz=iGeneric1.getName("ITBZ");
System.out.println(itbz);
}
}
泛型方法的使用
类上定义的泛型,在方法中可以使用,但是特殊时候仅仅只需要在方法上使用泛型,就可以使用泛型方法
语法结构
//无返回值方法
public<泛型标识符号> void getName(泛型标识符号 name){}
//有返回值方法
public<泛型标识符号> 泛型标识符号 getName(泛型标识符号 name){}
非静态方法
public class MethodGenenric {
public <T> void setName(T name){
System.out.println(name);
}
public <T> T getAge(T age){
//<>内是定义泛型,T是使用泛型
return age;
}
}
public class test2 {
public static void main(String[] args) {
MethodGenenric methodGenenric=new MethodGenenric();
methodGenenric.setName("oldlu");
Integer age=methodGenenric.getAge(23);
System.out.println(age);
}
}
静态方法
静态方法无法访问类上定义的泛型,必须要将泛型定义在方法上
public class MethodGenenric {
public <T> void setName(T name){
System.out.println(name);
}
public <T> T getAge(T age){
//<>内是定义泛型,T是使用泛型
return age;
}
//静态方法
public static<T> T aa(int num){
return num;
}
}
泛型方法与可变参数
在泛型方法中,泛型也可以定义可变参数类型
语法结构
public <泛型标识符号> void showMsg(泛型标识符号…args){}
public class MethodMsg {
public <T> void method(T ... args){
for(T t:args){
System.out.print(t+"\t");
}
}
}
public class test2 {
public static void main(String[] args) {
MethodMsg methodMsg=new MethodMsg();
String[] arr=new String[]{"a","b","c"};
Integer[] arr2=new Integer[]{1,2,3};
methodMsg.method(arr);
methodMsg.method(arr2);
}
}
泛型中的通配符
"?“表示类型通配符,用于代替具体的类型,只能在”<>"中使用,可以解决当具体类型不确定的问题
语法结构
public void showFlag(Generic<?> generic){
}
public class Generic<T> {
private T flag;
public void setFlag(T flag){
this.flag=flag;
}
public T getFlag(){
return this.flag;
}
public class ShowMsg {
public void showFlag(Generic<?> generic){
System.out.println(generic.getFlag());
}
}
public class test3 {
public static void main(String[] args) {
ShowMsg showMsg = new ShowMsg();
Generic<Integer> generic = new Generic<>();
generic.setFlag(20);
showMsg.showFlag(generic);
Generic<Number> generic1 = new Generic<>();
generic1.setFlag(34);
showMsg.showFlag(generic1);
Generic<String> generic2 = new Generic<>();
generic2.setFlag("oldlu");
showMsg.showFlag(generic2);
}
}
通配符的上下限限定
通配符的上限限定
含义:?实际类型可以是上限限定中所约定的类型,也可以是约定类型的子类型或子接口,但是不能是约定类型的父类型或者父接口
语法结构
public void showFlag(Generic<? extends Number> generic){
}
public class ShowMsg {
//实际类型可以是上限限定中所约定的类型,也可以是约定类型的子类型或子接口,但是不能是约定类型的父类型或者父接口
public void showFlag(Generic<? extends Number> generic){
System.out.println(generic.getFlag());
}
}
public class test3 {
public static void main(String[] args) {
ShowMsg showMsg = new ShowMsg();
//Integer是Number的子类
Generic<Integer> generic = new Generic<>();
generic.setFlag(20);
showMsg.showFlag(generic);
//Number是Number本类
Generic<Number> generic1 = new Generic<>();
generic1.setFlag(34);
showMsg.showFlag(generic1);
//Number是Number本类
Generic<Number> generic2 = new Generic<>();
generic2.setFlag(111);
showMsg.showFlag(generic2);
}
}
通配符的下限限定
?实际类型可以是下限限定中所约定的类型,可以是约定类型的父类型或者父接口
语法结构
public void showFlag(Generic<? super Integer>){
}
public class ShowMsg {
public void showFlag(Generic<? super Integer> generic){
System.out.println(generic.getFlag());
}
}
public class test3 {
public static void main(String[] args) {
ShowMsg showMsg = new ShowMsg();
//Integer是Number的子类
Generic<Integer> generic = new Generic<>();
generic.setFlag(20);
showMsg.showFlag(generic);
//Number是Number本类
Generic<Number> generic1 = new Generic<>();
generic1.setFlag(34);
showMsg.showFlag(generic1);
//Number是Number本类
Generic<Number> generic2 = new Generic<>();
generic2.setFlag(111);
showMsg.showFlag(generic2);
}
}
泛型总结
主要用于编译阶段,编译后生成的字节码class文件不包含泛型中的类型信息,类型参数在编译后会被替换成Object.
基本类型不能用于泛型
Test t; 应该使用Test t;
不能通过泛型创建对象
T elm=new T();
容器
一般通过容器容纳和管理数据,数组就是一种容器,可在其中放置对象或者基本类型数据
容器结构介绍
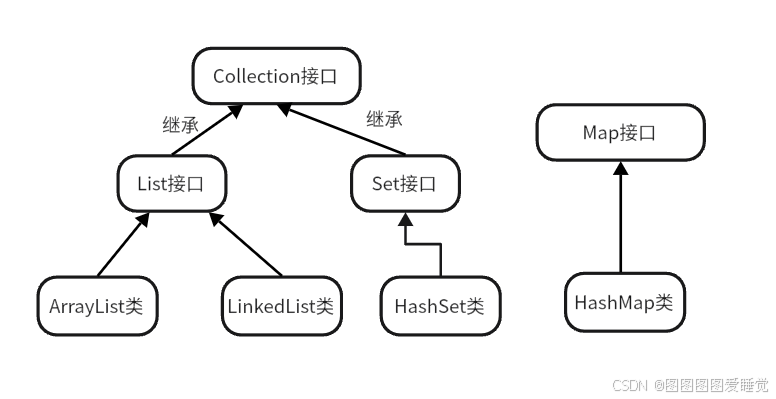
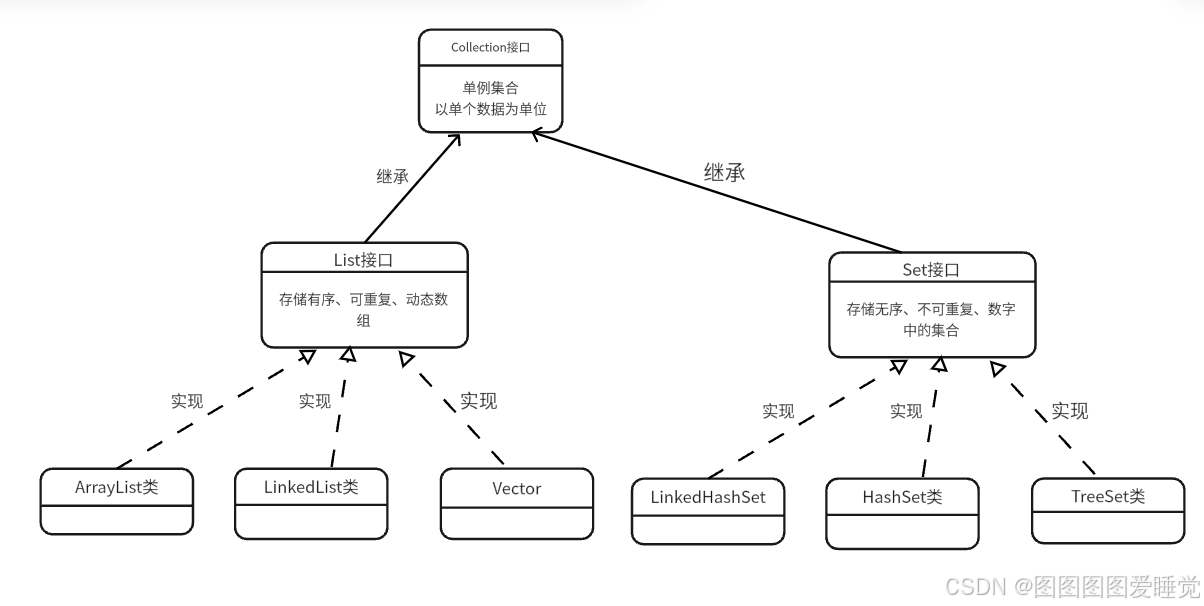
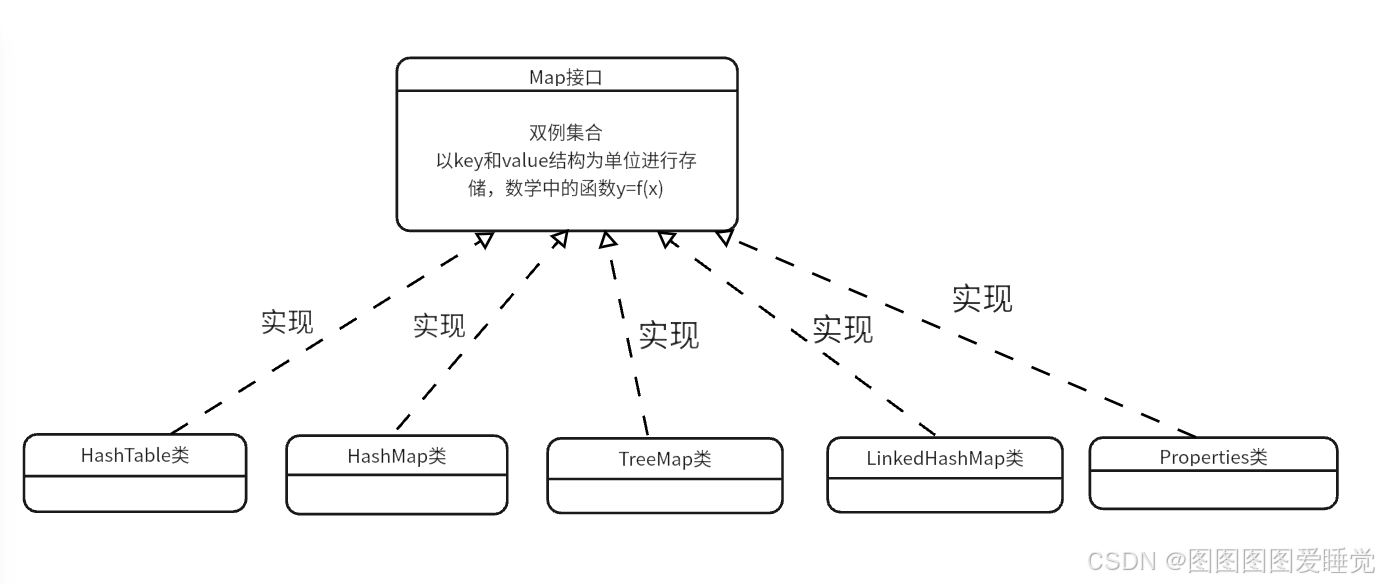
Collection接口介绍
Collection表示一组对象,它是集中、收集的意思,有两个子接口分别是List、Set接口。
| 方法 | 说明 |
|---|---|
| boolean add(Object element) | 增加元素到容器中 |
| boolean remove(Object element) | 从容器中移除元素 |
| boolean contains(Object element) | 容器中是否包含该元素 |
| int size() | 容器中元素的数量 |
| boolean isEmpty() | 容器是否为空 |
| void clear() | 清空容器中所有元素 |
| Iterator iterator() | 获得迭代器,用于遍历所有元素 |
| boolean containsAll(Collection c) | 本容器是否包含c容器中的所有元素 |
| boolean addAll(Collection c) | 将容器c中所有元素增加到本容器 |
| boolean removeAll(Collection c) | 移除本容器和容器c中都包含的元素 |
| boolean retainAll(Collection c) | 取本容器和容器c中都包含的元素,移除非交集元素 |
| Object[] toArray() | 转化成Object数组 |
由于List、Set是Collection的子接口,意味着所有List、Set的实现类都有上面的方法
List介绍
有序、可重复的容器
有序: List中每个元素都有索引标记。可以根据元素的索引标记(在List中的位置)访问元素,从而精确控制这些元素。
可重复: List允许加入重复的 元素,List通常允许满足e1.equals(e2)的元素重复加入容器
| 方法 | 说明 |
|---|---|
| void add (int index, Object element) | 在指定位置插入元素,以前元素全部后移一位 |
| Object set (int index,Object element) | 修改指定位置的元素 |
| Object get (int index) | 返回指定位置的元素 |
| Object remove (int index) | 删除指定位置的元素,后面元素全部前移一位 |
| int indexOf (Object o) | 返回第一个匹配元素的索引,如果没有该元素,返回-1. |
| int lastIndexOf (Object o) | 返回最后一个匹配元素的索引,如果没有该元素,返回-1 |
ArrayList的基本使用
ArrayList底层是使用数组来存储元素,是List接口的实现类,是List存储特征的具体实现,查询效率高,增删效率低,线程不安全。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class ArrayListTest {
public static void main(String[] args) {
//实例化ArrayList容器
List<String> list=new ArrayList<>();
//添加元素
boolean flag1=list.add("oldlu");
boolean flag2=list.add("itbz");
boolean flag3=list.add("sxt");
boolean flag4=list.add("sxt");
System.out.println(flag1+"\t"+flag2+"\t"+flag3+"\t"+flag4);
//删除元素
boolean flag5=list.remove("oldlu");
System.out.println(flag5);
//获取容器中元素的个数
int size=list.size();
System.out.println(size);
//判断容器是否为空
boolean empty=list.isEmpty();
System.out.println(empty);
//容器中是否包含指定的元素
boolean value=list.contains("itbz");
System.out.println(value);
//清空容器
list.clear();
Object[] objects=list.toArray();
System.out.println(Arrays.toString(objects));
}
}
ArrayList的索引操作
ArrayList可以根据索引位置操作元素
import java.util.ArrayList;
import java.util.List;
public class ArrayListTest2 {
public static void main(String[] args) {
//实例化容器
List<String> list=new ArrayList<>();
//添加元素
list.add("oldlu");
list.add("itbz");
//向指定位置添加元素
list.add(0,"sxt");
System.out.println("获取元素");
String value1=list.get(0);
System.out.println(value1);
System.out.println("获取元素的方式一");
//使用普通for循环
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("获取元素的方式二");
//使用Foreach循环
for(String str:list){
System.out.println(str);
}
System.out.println("元素替换");
list.set(1,"kevin");
for(String str:list){
System.out.println(str);
}
System.out.println("根据索引位置删除元素");
String value2=list.remove(1);
System.out.println(value2);
System.out.println("----------------");
for(String str:list){
System.out.println(str);
}
System.out.println("查找元素第一次出现的位置");
int value3=list.indexOf("sxt");
System.out.println(value3);
System.out.println("查找元素最后一次出现的位置");
list.add("sxt");
for(String str:list){
System.out.println(str);
}
int value4=list.lastIndexOf("sxt");
System.out.println(value4);
}
}
ArrayList的并集、交集、差集
import java.util.ArrayList;
import java.util.List;
public class ArrayListTest3 {
public static void main(String[] args) {
//并集操作:将另一个容器中的元素添加到当前容器中
List<String> a=new ArrayList<>();
a.add("a");
a.add("b");
a.add("c");
List<String> b=new ArrayList<>();
b.add("a");
b.add("b");
b.add("c");
//a并集b
a.addAll(b);
for(String str:a){
System.out.println(str);
}
System.out.println();
//交集:保留相同事物,删除不同的
List<String> a1=new ArrayList<>();
a1.add("a");
a1.add("b");
a1.add("c");
List<String> b1=new ArrayList<>();
b1.add("a");
b1.add("b");
b1.add("c");
//交集操作
a1.retainAll(b1);
for(String str:a1){
System.out.println(str);
}
System.out.println();
//差集操作:保留不同的,删除相同的
List<String> a2=new ArrayList<>();
a2.add("a");
a2.add("b");
a2.add("c");
List<String> b2=new ArrayList<>();
b2.add("b");
b2.add("c");
b2.add("d");
a2.removeAll(b2);
for(String str:a2){
System.out.println(str);
}
}
}
Vector的基本使用
Vector底层使用数组实现的,相关方都加了同步检查,因此“线程安全,效率低”,比如indexOf方法就增加了synchronized同步标记。
public synchronized int indexOf(Object o,int index){
}
Vector的使用与ArrayList是相同的,因为都具体实现了List接口,对List接口中的抽象方法做了具体的实现。
import java.util.List;
import java.util.Vector;
public class VectorTest {
public static void main(String[] args) {
//实例化Vector
List<String> v=new Vector<>();
v.add("a");
v.add("b");
v.add("c");
for (int i = 0; i < v.size(); i++) {
System.out.print(v.get(i)+"\t");
}
for(String str:v){
System.out.print(str+"\t");
}
}
}
LinkedList容器介绍
LinkedList底层用双向链表实现的存储,查询效率低,增删效率高,线程不安全。
双向链表也叫双链表,是链表的一种,它的每个数据节点中都有两个指针,分别指向前一个节点和后一个节点。从双向链表中的任意一个节点开始,都可以方便的找到所有节点。
每个节点都应该有3部分内容:
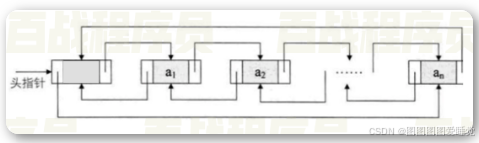
class Node<E>{
Node<E> previous;//前一个节点
E element;//本节点保存的数据
Node<E> next;//后一个结点
}
如何选用ArrayList、LinkedList、Vector
需要线程安全时用Vector
不存在线程安全问题时,并且查找较多用ArrayList(一般使用)
不存在线程安全问题时,增删元素较多用LinkedList
LinkedList容器的使用(List标准)
LinkedList实现了List接口,所以LinkedList是具备List存储特征的(有序、可重复)
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
public class LinkedListTest {
public static void main(String[] args) {
//实例化LiNkedList容器
List<String> list=new LinkedList<>();
//添加元素
boolean a=list.add("a");
boolean b=list.add("b");
boolean c=list.add("c");
list.add(3,"a");
System.out.print(a+"\t"+b+"\t"+c);
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
LinkedList容器的使用(非List标准)
| 方法 | 说明 |
|---|---|
| void addFirst(E e) | 将指定元素插入到开头 |
| void addLast(E e) | 将指定元素插入到结尾 |
| getFirst() | 返回此链表的第一个元素 |
| getLast() | 返回此链表的最后一个元素 |
| removeFirst() | 移除此链表中的第一个元素,并返回这个元素 |
| removeLast() | 移除此链表中的最后一个元素,并返回这个元素 |
| E pop() | 从此链表所表示的堆栈处弹出一个元素,等效于removeFirst |
| void push(E e) | 将元素推入此链表所表示的堆栈 这个等效于addFisrt(E e) |
import java.util.LinkedList;
public class LinkedListTest2 {
public static void main(String[] args) {
System.out.println("-----------LinkedList-------------");
//将指定元素插入到链表开头
LinkedList<String> linkedList1=new LinkedList<>();
linkedList1.addFirst("a");
linkedList1.addFirst("b");
linkedList1.addFirst("c");
for(String str:linkedList1){
System.out.println(str);
}
System.out.println("----------------------");
//将指定元素插入到链表结尾
LinkedList<String> linkedList2=new LinkedList<>();
linkedList2.addLast("a");
linkedList2.addLast("b");
linkedList2.addLast("c");
for (String str:linkedList2){
System.out.println(str);
}
System.out.println("--------------------------");
//返回此链表的第一个元素
System.out.println(linkedList2.getFirst());
//返回此链表的最后一个元素
System.out.println(linkedList2.getLast());
System.out.println("-----------------------");
//移除此链表中的第一个元素,并返回这个元素
linkedList2.removeFirst();
//移除此链表中的最后一个元素,并返回这个元素
linkedList2.removeLast();
for(String str:linkedList2){
System.out.println(str);
}
System.out.println("-------------------------");
linkedList2.addLast("c");
//从此链表所表示的堆栈处弹出一个元素,等效于removeFirst
linkedList2.pop();
for(String str:linkedList2){
System.out.println(str);
}
System.out.println("-------------------------");
//将元素推入此链表所表示的堆栈 这个等效于addFisrt(E e)
linkedList2.push("h");
for(String str:linkedList2){
System.out.println(str);
}
}
}
Set接口介绍
Set接口继承自Collection接口,Set接口中没有新增方法,它和Collection接口保持完全一致,前面学习的List接口的使用方式在Set中仍然适用。
特点:无序、不可重复
无序指Set中的元素没有索引,只能遍历查找,不可重复指不允许加入重复的元素
常用实现类用:HashSet、TreeSet等,一般使用HashSet
HashSet容器的使用
HashSet是Set接口的实现类,是Set存储特征的具体实现。
import java.util.*;
public class HashSetTest {
public static void main(String[] args) {
//实例化HashSet
Set<String> set = new HashSet<>();
//添加元素
set.add("a");
set.add("b1");
set.add("c2");
set.add("e");
set.add("a");
//获取元素,在Set容器中没有索引,所以没有对应的get(int index)方法
for(String str:set){
System.out.println(str);
}
System.out.println("------------------");
//删除元素
boolean flag= set.remove("c2");
System.out.println(flag);
for(String str:set){
System.out.println(str);
}
System.out.println("--------------");
int size=set.size();
System.out.println(size);
}
}
HashSet存储特征分析
HashSet底层是使用HashMap存储元素的
无序: 在HashSet中底层是使用HashMap存储元素的,HashMap底层使用的是数组与链表实现元素的存储,元素在数组中存放时,对元素的哈希值进行运算决定元素在数组中的位置。
不重复: 当两个元素的哈希值进行运算后得到相同的在数组中的位置时,会调用元素的equals()方法判断两个元素是否相同。
通过HashSet存储自定义对象
import java.util.Objects;
public class Users {
private String username;
private int userage;
public Users() {
}
public Users(String username, int userage) {
this.username = username;
this.userage = userage;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Users users = (Users) o;
if(userage!=users.userage)return false;
return username!=null?username.equals(users.username):users.username==null;
}
@Override
public int hashCode() {
int result=username!=null?username.hashCode():0;
result=31*result+userage;
return result;
}
/**
* 获取
* @return username
*/
public String getUsername() {
return username;
}
/**
* 设置
* @param username
*/
public void setUsername(String username) {
this.username = username;
}
/**
* 获取
* @return userage
*/
public int getUserage() {
return userage;
}
/**
* 设置
* @param userage
*/
public void setUserage(int userage) {
this.userage = userage;
}
public String toString() {
return "Users{username = " + username + ", userage = " + userage + "}";
}
}
import java.util.HashSet;
import java.util.Set;
public class HashSetTest2 {
public static void main(String[] args) {
//实例化HashSet
Set<Users> set=new HashSet<>();
Users u=new Users("oldlu",18);
Users u1=new Users("oldlu",18);
set.add(u);
set.add(u1);
System.out.println(u.hashCode());
System.out.println(u1.hashCode());
for (Users users:set){
System.out.println(users);
}
}
}
TreeSet容器的使用
TreeSet实现了Set接口,可以对元素进行排序的容器,底层是用TreeMap实现的,内部维持了一个简化版的TreeMap,通过key来存储元素。TreeSet内部需要对存储的元素进行排序,排序规则实现方式:
- 通过元素自身实现比较规则
- 通过比较器指定比较规则
import java.util.Set;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
//实例化TreeSet
Set<String> set=new TreeSet<>();
//添加元素
set.add("c");
set.add("a");
set.add("d");
set.add("b");
set.add("a");
//打印元素
for(String str:set){
System.out.println(str);
}
}
}
TreeSet通过元素自身实现比较规则
在元素自身实现比较规则时,需要实现Comparable接口中的compareTo方法,该方法中用来定义比较规则。TreeSet通过调用该方法来完成对元素的排序处理。
public class Users implements Comparable<Users>{
private String username;
private int userage;
public Users(String username, int userage) {
this.username = username;
this.userage = userage;
}
public Users() {
}
@Override
public boolean equals(Object o) {
System.out.println("equals...");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Users users = (Users) o;
if (userage != users.userage) return false;
return username != null ? username.equals(users.username) : users.username == null;
}
@Override
public int hashCode() {
int result = username != null ? username.hashCode() : 0;
result = 31 * result + userage;
return result;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getUserage() {
return userage;
}
public void setUserage(int userage) {
this.userage = userage;
}
@Override
public String toString() {
return "Users{" +
"username='" + username + '\'' +
", userage=" + userage +
'}';
}
//定义比较规则
//正数:大,负数:小,0:相等
@Override
public int compareTo(Users o) {
if(this.userage > o.getUserage()){
return 1;
}
if(this.userage == o.getUserage()){
return this.username.compareTo(o.getUsername());
}
return -1;
}
}
TreeSet通过比较器实现比较规则
通过比较器定义比较规则时,需要单独创建一个比较器,比较器需要实现Comparator接口中的compare方法来定义比较规则,在实例化TreeSet时将比较器对象交给TreeSet来完成元素的排序处理,此时元素自身不需要实现比较规则。
import java.util.Objects;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if(age!=student.age) return false;
return name!=null?name.equals(student.name):student.name==null;
}
@Override
public int hashCode() {
int result=name!=null?name.hashCode():0;
result=31*result+age;
return result;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
import java.util.Comparator;
public class StudentComparator implements Comparator<Student>
{
//定义比较规则
@Override
public int compare(Student o1, Student o2) {
if(o1.getAge()>o2.getAge()){
return 1;
}
if(o1.getAge()==o2.getAge()){
return o1.getName().compareTo(o2.getName());
}
return -1;
}
}
import java.util.Set;
import java.util.TreeSet;
public class TreeSetTest3 {
public static void main(String[] args) {
//创建TreeSet容器,并给定比较器对象
Set<Student> set=new TreeSet<>(new StudentComparator());
Student s=new Student("oldlu",18);
Student s1=new Student("admin",22);
Student s2=new Student("sxt",22);
set.add(s);
set.add(s1);
set.add(s2);
for(Student student:set){
System.out.println(student);
}
}
}
单例集合案例–List类型容器
需求:产生1-10之间的随机数([1,10]闭区间),将不重复的10个随机数放到容器中。
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class ListDemo {
public static void main(String[] args) {
List<Integer> list=new ArrayList<>();
Random r=new Random();
while(true){
//产生随机数
//int num=(int)(Math.random()*10+1);
int num=r.nextInt(10)+1;
//判断当前元素在容器中是否存在
if(!list.contains(num)){
list.add(num);
}
//结束循环
if(list.size()==10){
break;
}
}
for(Integer in:list){
System.out.println(in);
}
}
}
单例集合案例–Set类型容器
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
public class SetDemo {
public static void main(String[] args) {
Set<Integer> set=new HashSet<>();
Random r=new Random();
while (true){
int num=r.nextInt(10)+1;
//将元素添加到容器中,由于Set类型容器是不允许有重复元素的。所以不需要判断
set.add(num);
//结束循环
if(set.size()==10){
break;
}
}
for(Integer in:set){
System.out.print(in+"\t");
}
}
}
Map接口介绍
Map接口定义了双例集合的存储特征,它并不是Collection接口的子接口,双例集合的存储特征是以key和value结构为单位进行存储,体现的是数学函数"y=f(x)"。
Map与Collection的区别:
- Collection中的容器,元素是孤立存在的,向集合中存储元素采用一个个元素的方式存储。
- Map中的容器,元素是成对存在的,每个元素由键和值两部分组成,通过键可以找到所对应的值。
- Collection中的容器称为单列集合,Map中容器称为双列集合。
- Map中的集合不能包含重复的键,值可以重复,但是每一个键只能对应一个值。
- Map中常用的容器为HashMap,TreeMap等
Map接口中常用方法表
| 方法 | 说明 |
|---|---|
| V put (K key,V value) | 把key与value添加到Map集合中 |
| void putAll(Map m) | 取Map m和当前调用该方法的并集 |
| V remove (Object key) | 删除key对应的value |
| V get (Object key) | 根据指定的key获取对应的value |
| boolean contains Key(Object value) | 判断容器中是否包含指定的value |
| boolean contains Value(Object value) | 判断容器中是否包含指定的value |
| Set keySet() | 获取Map集合中所有的key,存储到Set集合中 |
| Set<Map.Entry<K,V>> entrySet() | 返回一个Set基于Map.Entry类型包含Map中所有键值对 |
| void clear() | 删除Map中所有的键值对 |
HashMap容器的使用
HashMap采用哈希算法实现,是Map接口最常用的实现类。由于底层采用了哈希表存储数据,我们要求键不能重复,如果发生重复,新的键值对会替换旧的键值对,HashMap在查找、删除、修改方面都有非常高的效率。
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class HashMapTest {
public static void main(String[] args) {
//实例化HashMap容器
Map<String,String> map=new HashMap<>();
//添加元素
map.put("a","A");
map.put("b","B");
map.put("c","C");
map.put("d","D");
//获取容器中元素数量
int size= map.size();
System.out.println(size);
System.out.println("=======================");
//获取元素
//方式一
String v=map.get("a");
System.out.println(v);
System.out.println("========================");
//方式二
Set<String> keys=map.keySet();
for(String key:keys){
String value=map.get(key);
System.out.println(key+"========="+value);
}
//方式三
Set<Map.Entry<String,String>> entrySet= map.entrySet();
for(Map.Entry<String,String> entry:entrySet){
String key=entry.getKey();
String value1=entry.getValue();
System.out.println(key+"=========="+value1);
}
System.out.println("=======================");
//Map容器的并集操作
Map<String,String> map2=new HashMap<>();
map2.put("f","F");
map2.put("c","CC");
map.putAll(map2);
Set<String> keys2=map.keySet();
for(String key:keys2){
System.out.println("key:"+key+"\t"+"Value:"+map.get(key));
}
System.out.println("=====================");
//删除元素
String v3=map.remove("a");
System.out.println(v3);
Set<String> keys3=map.keySet();
for(String key:keys3){
System.out.println("key:"+key+"\t"+"Value:"+map.get(key));
}
System.out.println("==========");
//判断Key是否存在
boolean b=map.containsKey("b");
System.out.println(b);
//判断Value是否存在
boolean cc=map.containsValue("CC");
System.out.println(cc);
}
}
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低。
HashMap和HashTable的区别:
1、HashMap:线程不安全,效率高,允许key或者value为null
2、HashTable:线程安全。效率低,不允许key或value为null
TreeMap容器的使用
TreeMap和HashMap同样实现了Map接口,对于API的用法是没有区别的。HashMap效率高于TreeMap;TreeMap是可以对键进行排序的一种容器,在需要对键排序时可选用TreeMap。TreeMap底层是基于红黑树实现的
在使用TreeMap时需要给定排序规则:
- 元素自身实现比较规则
- 通过比较器实现比较规则
元素自身实现比较规则
import java.util.Objects;
public class Users implements Comparable<Users>{
private String username;
private int userage;
public Users() {
}
public Users(String username, int userage) {
this.username = username;
this.userage = userage;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Users users = (Users) o;
if(userage!=users.userage)return false;
return username!=null?username.equals(users.username):users.username==null;
}
@Override
public int hashCode() {
int result=username!=null?username.hashCode():0;
result=31*result+userage;
return result;
}
/**
* 获取
* @return username
*/
public String getUsername() {
return username;
}
/**
* 设置
* @param username
*/
public void setUsername(String username) {
this.username = username;
}
/**
* 获取
* @return userage
*/
public int getUserage() {
return userage;
}
/**
* 设置
* @param userage
*/
public void setUserage(int userage) {
this.userage = userage;
}
public String toString() {
return "Users{username = " + username + ", userage = " + userage + "}";
}
//定义比较规则
//正数:大于 负数:小于 0:相等
@Override
public int compareTo(Users o) {
if(this.userage>o.getUserage()){
return 1;
}
if(this.userage==o.getUserage()){
return this.username.compareTo(o.getUsername());
}
return -1;
}
}
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapTest {
public static void main(String[] args) {
//实例化TreeMap
Map<Users,String> map=new TreeMap<>();
Users u1=new Users("oldlu",18);
Users u2=new Users("admin",22);
Users u3=new Users("sxt",22);
map.put(u1,"oldlu");
map.put(u2,"admin");
map.put(u3,"sxt");
Set<Users> keys=map.keySet();
for(Users key:keys){
System.out.println(key+"==="+map.get(key));
}
}
}
通过比较器实现比较规则
import java.util.Objects;
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if(age!=student.age) return false;
return name!=null?name.equals(student.name):student.name==null;
}
@Override
public int hashCode() {
int result=name!=null?name.hashCode():0;
result=31*result+age;
//乘以一个质数(如31)有助于生成均匀的哈希码,减少不同对象产生相同哈希码的机会。31是一个质数,乘以质数可以避免某些模式导致的散列冲突。
return result;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class TreeMapTest {
public static void main(String[] args) {
//实例化TreeMap
Map<Student,String> map=new TreeMap<>(new StudentComparator());
Student s1=new Student("oldlu",18);
Student s2=new Student("admin",22);
Student s3=new Student("sxt",22);
map.put(s1,"oldlu");
map.put(s2,"admin");
map.put(s3,"sxt");
Set<Student> keys=map.keySet();
for(Student key:keys){
System.out.println(key+"==="+map.get(key));
}
}
}
迭代器(Iterator)介绍
Collection接口继承了Iterable接口,在该接口中包含一个名为iterator的抽象方法,所有实现了Collection接口的容器类对该方法进行了具体实现。iterator方法会返回一个Iterator接口类型的迭代器对象,在该对象中包含了三个方法用于实现对单例容器的迭代处理。
Iterator接口定义了如下方法:
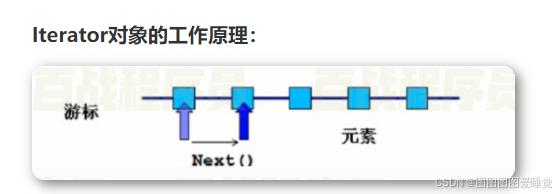
- boolean hasNext();//判断游标当前位置的下一个位置是否还有元素没有被遍历
- Object next();//返回游标当前位置的下一个元素并将游标移动到下一个位置
- void remove();//删除游标当前位置元素,在执行完next后该操作只能执行一次
迭代器(Iterator)的使用
迭代List接口类型容器
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class IteratorListTest {
public static void main(String[] args) {
//实例化容器
List<String> list=new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
//获取元素
//获取迭代器对象
Iterator<String> iterator=list.iterator();
//方式一:在迭代器中通过while循环获取元素
while(iterator.hasNext()){
String value=iterator.next();
System.out.println(value);
}
System.out.println("=========");
//方法二:在迭代器中通过for循环获取元素
for(Iterator<String> it=list.iterator(); it.hasNext();){
String value=it.next();
System.out.println(value);
}
}
}
迭代Set接口类型容器
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class IteratorSetTest {
public static void main(String[] args) {
//实例化Set类型的容器
Set<String> set=new HashSet<>();
set.add("a");
set.add("b");
set.add("c");
//方式一:通过while循环
//获取迭代器对象
Iterator<String> iterator=set.iterator();
while (iterator.hasNext()){
String value=iterator.next();
System.out.println(value);
}
System.out.println("==================");
//方式二:通过for循环
for(Iterator<String> it=set.iterator();it.hasNext();){
String value=it.next();
System.out.println(value);
}
}
}
迭代Map接口类型容器
import javax.swing.text.html.HTMLDocument;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class IteratorMapTest {
public static void main(String[] args) {
//实例化HashMap容器
Map<String,String> map=new HashMap<String,String>();
//添加元素
map.put("a","A");
map.put("b","B");
map.put("c","C");
//遍历容器方式一
Set<String> keySet=map.keySet();
//定义语句;判断条件
for(Iterator<String> it=keySet.iterator();it.hasNext();){
String key=it.next();//自增语句
String value=map.get(key);
System.out.println(key+"========"+value);
System.out.println("=============");
//遍历Map容器方式二
Set<Map.Entry<String,String>> entrySet=map.entrySet();
Iterator<Map.Entry<String,String>> iterator=entrySet.iterator();
while(iterator.hasNext()){
Map.Entry entry=iterator.next();
System.out.println(entry.getKey()+"===="+entry.getValue());
}
}
}
}
迭代器(Iterator)删除元素
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class IteratorRemoveTest {
public static void main(String[] args) {
List<String> list=new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
Iterator<String> iterator=list.iterator();
while(iterator.hasNext()){
//不要在一次循环中多次调用next方法
String value=iterator.next();
iterator.remove();
}
System.out.println("==============");
for(Iterator<String> it=list.iterator();it.hasNext();){
System.out.println(it.next());
list.add("dddd");
}
}
}
迭代器----遍历集合的方法总结
遍历List方式一:普通for循环
for(int i=0;i<list.size();i++){
String temp=(String)list.get(i);
System.out.println(temp);
}
遍历List方法二:增强for循环(使用泛型)
for(String temp:list){
System.out.println(temp);
}
遍历List方法三:使用Iterator迭代器(1)
for(Iterator iter=list.iterator();iter.hasNext();){
String temp=(String)iter.next();
System.out.println(temp);
}
遍历List方法四:使用Iterator迭代器(2)
Iterator iter=list.Iterator();
while(iter.hasNext()){
Object obj=iter.next();
iter.remove();//如果要边遍历边删除集合中的元素,建议使用该方式
System.out.println(obj);
}
遍历Set方法一:增强for循环
for(String temp:set){
System.out.println(temp);
}
遍历Set方法二:使用Iterator迭代器
for(Iterator iter=set.iterator();iter.hasNext();){
String temp=(String)iter.next();
System.out.println(temp);
}
遍历Map方法一:根据key获取value
Map<Integer,Man> maps=new HashMap<Integer,Man>();
Set<Integer> keySet=maps.keySet();
for(Integer id:keySet){
System.out.println(map.get(id).name);
}
遍历Map方法二:使用entrySet
Set<Map.Entry<Integer,Man>> ss=maps.entrySet();
for(Iterator<Map.Entry<Integer,Man>> iter=ss.iterator();iter.hasNext();){
Map.Entry e=iter.next();
System.out.println(e.getKey()+"--"+e.getValue());
}
Collections工具类的使用
类java.util.Collections提供了对Set、List、Map进行排序、填充、查找元素的辅助方法
| 方法名 | 说明 |
|---|---|
| void sort(List) | 对List容器内的元素进行排序,排序的规则是升序 |
| void shuffle(List) | 对List容器内的元素进行随机排列 |
| void reverse(List) | 对List容器内的元素进行逆序排列 |
| void fill(List,Object) | 用一个特定的对象重写整个List容器 |
| int binarySearch(List,Object) | 对于顺序的List容器,折半查找特定对象 |
Collections工具类常用方法
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsTest {
public static void main(String[] args) {
List<String> list=new ArrayList<>();
list.add("c");
list.add("b");
list.add("a");
//对元素排序
Collections.sort(list);
for(String str:list){
System.out.println(str);
}
System.out.println("========");
List<Users> list2=new ArrayList<>();
Users u=new Users("oldlu",18);
Users u2=new Users("sxt",22);
Users u3=new Users("admin",22);
list2.add(u);
list2.add(u2);
list2.add(u3);
//对元素排序
Collections.sort(list2);
for(Users users:list2){
System.out.println(users);
}
System.out.println();
List<Student> list3=new ArrayList<>();
Student s=new Student("oldlv",18);
Student s1=new Student("sxt",20);
Student s2=new Student("admin",20);
list3.add(s);
list3.add(s1);
list3.add(s2);
Collections.sort(list3,new StudentComparator());
for(Student student:list3){
System.out.println(student);
}
System.out.println();
List<String> list4=new ArrayList<>();
list4.add("a");
list4.add("b");
list4.add("c");
list4.add("d");
//随机打乱顺序
Collections.shuffle(list4);
for(String str:list4){
System.out.println(str);
}
}
}