本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor
项目地址: QwenLM/Qwen2.5: Qwen2.5 is the large language model series developed by Qwen team, Alibaba Cloud.
官网地址: 你好,Qwen2 | Qwen & Qwen2.5: 基础模型大派对! | Qwen
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
Qwen 2系列
截至到2024.11.3 其实Ali 已经推出了Qwen2.5系列,相比于Qwen2系列,2.5只是使用了体量更大、质量更高的数据集继续训练得到的 Qwen2.5 系列模型。 所以先介绍一下Qwen2系列,详情可以参考你好,Qwen2 | Qwen (qwenlm.github.io) 。
Qwen系列包括了5个尺寸的预训练和指令微调的模型,当时在开源的模型里一经推出就达到SOTA的水平。其中全系都使用了GQA(Group-Query Attention)技术,小模型使用了Tie Embedding(共享向量)技术。上下文长度都是基于32K的数据预训练然后拓展的,可以看到最长可以支持到128K。在推出的当时性能还是吊打其他大部分大模型的,尤其是多语言支持以及代码及数学能力显著提升,具体性能指标可以参考其文档。
| 模型 | Qwen2-0.5B | Qwen2-1.5B | Qwen2-7B | Qwen2-57B-A14B | Qwen2-72B |
|---|---|---|---|---|---|
| 参数量 | 0.49B | 1.54B | 7.07B | 57.41B | 72.71B |
| 非Embedding参数量 | 0.35B | 1.31B | 5.98B | 56.32B | 70.21B |
| GQA | True | True | True | True | True |
| Tie Embedding | True | True | False | False | False |
| 上下文长度 | 32K | 32K | 128K | 64K | 128K |
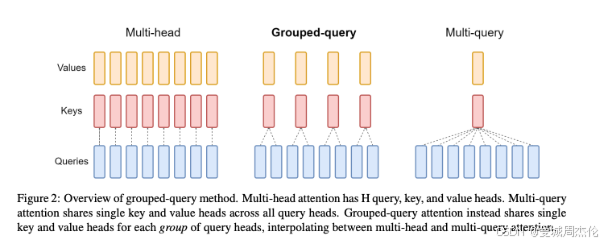
GQA现在基本是大模型的标配,原始的 MHA(Multi-Head Attention),QKV 三部分有相同数量的头,且一一对应。每次做 Attention,head1 的 QKV 就做好自己运算就可以,输出时各个头加起来就行。而 MQA(Multi-query Attention) 则是,让 Q 仍然保持原来的头数,但 KV只有一个,相当于所有的 Q 头共享一组 K 和 V 头,所以叫做 Multi-Query 了。虽然MQA一般能提高 30%-40% 的计算性能,但是性能精度会有所降低。而GQA 通过分组一定头数共享一组KV,从而达到性能和计算中的一个trade-off,这样既不像MQA一样降低很多精度,也可以相比于NHA提高速度。针对小模型,由于embedding参数量较大,qwen系列使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比。Tie Embedding技术提出可以将输入和输出的嵌入层参数绑定,即让模型在处理输入词和输出词时使用相同的向量表示。 比如在词嵌入模型(如Word2Vec或GloVe)中,每个词被映射到固定维度的向量空间上。但是tie embedding 通过共享输入和输出层参数,可以使得相似语义的词拥有同样的词向量表示。比如说tie_embedding(‘large’) = tie_embedding('big)。
除了上述两个亮点之外Qwen系列还用了采用了多种先进技术以提升模型性能和效率:
-
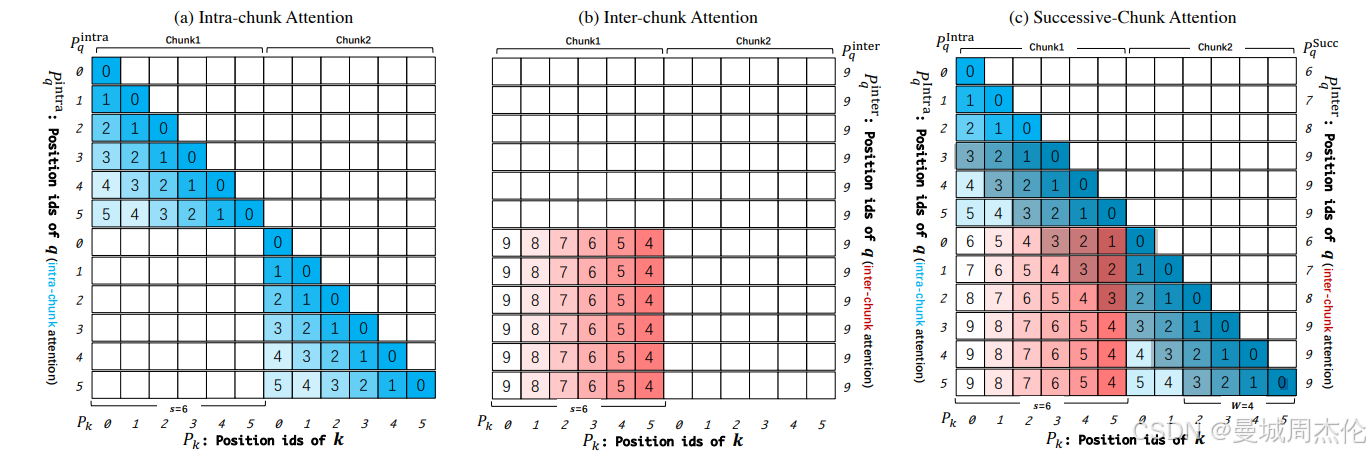
双块注意力(Dual Chunk Attention, DCA) :DCA双块注意力是一种改进的注意力机制。DCA 技术将长序列分割成可管理的块,从而有效捕捉块内和跨块的相对位置信息,提升长上下文处理能力。DCA双块注意力机制是一种无需额外训练即可扩展大型语言模型(LLMs)上下文窗口的新框架, 其避免了线性缩放位置索引或增加RoPE的基频。相反,它选择重用预训练模型中的原始位置索引及其嵌入,但重新设计了相对位置矩阵的构建,以尽可能准确地反映两个标记之间的相对位置。DCA通过将长文本分割成多个较小的“块”(chunks),然后在这些块内和块之间应用注意力机制,有效地处理长文本。DCA的核心思想包括:
- 内块注意力,将长文本分割成若干个小块,每个小块包含一部分文本。
- 间块注意力,用于处理不同块之间的标记 ,对每个小块单独应用注意力机制,减少了计算量。
- 连续块注意力,这些各自的处理帮助模型有效捕捉序列中的长距离和短距离依赖。在计算完块内注意力后,再在这些块之间应用注意力机制,以捕捉整个文本的上下文关系
-
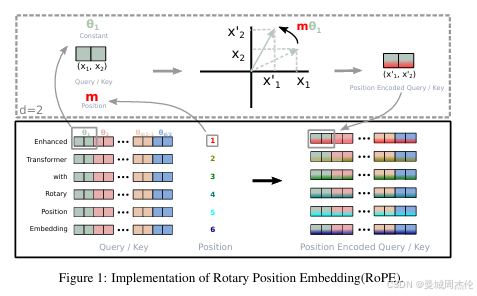
旋转位置嵌入(RoPE) :RoPE 提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。而目前很火的 LLaMA、GLM 模型也是采用该位置编码方式。其核心思想是“通过绝对位置编码的方式实现相对位置编码”,可以说是具备了绝对位置编码的方便性,同时可以表示不同 token 之间的相对位置关系。不同于原始 Transformers 论文中,将 pos embedding 和 token embedding 进行相加,RoPE 是将位置编码和 query (或者 key) 进行相乘。如果深入对RoPE感兴趣,可以参考十分钟读懂旋转编码(RoPE) - 知乎 (zhihu.com) 以及我之前的文章:
-
-
YARN 机制 :YaRN (Yet another RoPE extensioN method)用于重新调整注意力权重,同时相比于rope改成了位置编码差值。YARN的核心思想是对注意力权重进行重新缩放,以便在不牺牲性能的情况下,更好地处理更长的上下文。这种方法通过调整注意力权重,使得模型能够更有效地捕捉长距离依赖关系,同时减少计算复杂度和内存消耗。YARN机制的特点包括:
- 注意力权重重新缩放 :通过调整注意力权重,YARN使得模型在处理长序列时能够保持稳定的性能。
- 长上下文支持 :YARN机制使得模型能够有效处理超过训练时上下文长度的序列,这对于需要处理长文本的应用场景尤为重要。
-
SwiGLU 激活函数 :使用 SwiGLU 作为激活函数,以提高模型的非线性表达能力。SwiGLU 是2019年提出的新的激活函数,它结合了 SWISH 和 GLU 两种者的特点。SwiGLU 主要是为了提升Transformer 中的 FFN(feed-forward network) 层的实现,其公式如:
SwiGLU ( x , W , V , b , c , β ) = Swish β ( x W + b ) ⊗ ( x V + c ) \operatorname{SwiGLU}(x, W, V, b, c,\beta)=\operatorname{Swish}_{\beta}\left(x W+b\right)\otimes(x V+c) SwiGLU(x,W,V,b,c,β)=Swishβ(xW+b)⊗(xV+c)
- RMSNorm 和预归一化 :使用 RMSNorm 和预归一化技术以增强训练稳定性。为了提高训练的稳定性,对每个transformer层的输入进行归一化,而不是输出进行归一化。同时,使用 RMS Norm (Root Mean Square layer normalization) ,与layernorm RMS Norm的主要区别在于去掉了减去均值的部分,RMS Norm 的作者认为这种模式在简化了Layer Norm 的计算,可以在减少约 7%∼64% 的计算时间, 其公式如下:
a ˉ i = a i R M S ( a ) g i , w h e r e R M S ( a ) = 1 n ∑ i = 1 n a i 2 \bar{a}_{i}=\frac{a_{i}}{RMS(a)}g_{i},\quad where RMS(a)=\sqrt{\frac{1}{n}\sum_{i=1}^{n}a_{i}^{2}} aˉi=RMS(a)aigi,whereRMS(a)=n1i=1∑nai2
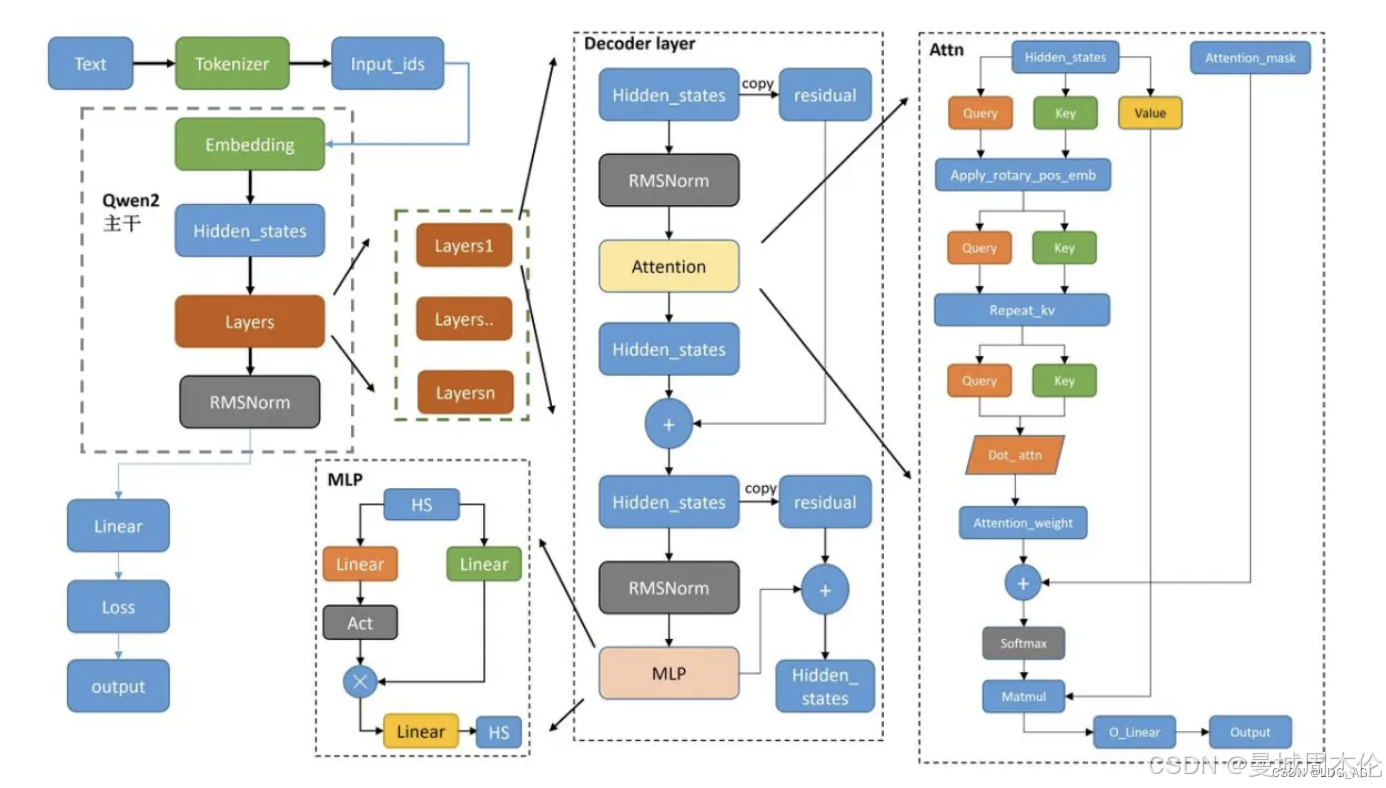
同GPT一样,Qwen系列也属于因果语言模型 (causal Language Models),也被称为自回归语言模型 (autoregressive language models) 或仅解码器语言模型 (decoder-only language models) ,是一种机器学习模型,旨在根据序列中的前导 token 预测下一个 token 。换句话说,它使用之前生成的 token 作为上下文,一次生成一个 token 的文本。”因果”方面指的是模型在预测下一个 token 时只考虑过去的上下文(即已生成的 token ),而不考虑任何未来的 token 。Qwen系列 有关于Qwen2-1.5b模型的结构如下:
Ps: 除了GPT 这种自回归的模型 同时还包括序列到序列模型(encoder-decoder model) 以及 仅解码语言模型(encoder-only model)。

其模型结构大致为这样:
对于Qwen的对话模板统一如下,由控制token “<|endoftext|>” 在每个文档后插入,表示文档已经结束,新的文档将开始。Qwen使用以下格式(ChatML[3]),利用控制 token 来格式化对话中的每一轮。
<|im_start|>{{role}}
{{content}}<|im_end|>
用户输入扮演 <span class="pre">user</span> 的 role ,而模型生成则承担 <span class="pre">assistant</span> 的 role 。 Qwen 还支持元消息,该消息指导模型执行特定操作或生成具有特定特性的文本,例如改变语气、风格或内容,这将承担 <span class="pre">system</span> 的 role,且内容默认为 “You are Qwen, created by Alibaba Cloud. You are a helpful assistant.” 。
下面为一个完整示例:
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>
<|im_start|>user
hello<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today? Let me know if you have any questions or need help with something. I'm here to help!<|im_end|>
<|im_start|>user
Explain large language models like I'm 5.<|im_end|>
<|im_start|>assistant
Sure, I'd be happy to explain large language models in a simple way!
Imagine that you have a friend who is really good at playing with words. This friend has read so many books and talked to so many people that they know how to use words in all sorts of different ways. They can tell stories, answer questions, and even make up new words if they need to.
Now imagine that this friend is actually a computer program, called a "large language model". It's been trained on lots and lots of text, like books, articles, and conversations, so it knows how to use words just like your word-loving friend does. When you ask the model a question or give it a task, it uses all the knowledge it's learned to come up with a response that makes sense.
Just like your friend might sometimes make mistakes or say things in a funny way, the large language model isn't perfect either. But it's still really impressive, because it can understand and generate human language in a way that was once thought impossible for machines!<|im_end|><|endoftext|>
Qwen2.5系列
Qwen2.5 相比 Qwen2 主要做了以下 改进 :
- 全面性能提升 :Qwen2.5 在 Qwen2 的基础上进行了大幅度升级,包括从 1.5B 到 72B 参数规模的不同版本,每个版本都针对特定需求进行了优化。特别是 14B/32B 版本,是最适合单卡部署的大小。Qwen2.5 在自然语言理解、代码编写、数学解题以及多语言处理等多个方面都有显著增强。
- 更大的训练数据集 :Qwen2.5 的所有尺寸都在最新的大规模数据集上进行了预训练,该数据集包含多达 18T tokens。与 Qwen2 相比,Qwen2.5 获得了显著更多的知识(MMLU:85+),并在编程能力(HumanEval 85+)和数学能力(MATH 80+)方面有了大幅提升。
- 更强的指令遵循能力 :新模型在指令执行、生成长文本(超过 8K 标记)、理解结构化数据(例如表格)以及生成结构化输出特别是 JSON 方面取得了显著改进。Qwen2.5 模型总体上对各种 system prompt 更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。
- 长文本支持能力 :与 Qwen2 类似,Qwen2.5 语言模型支持高达 128K tokens,并能生成最多 8K tokens 的内容。
- 强大的多语言能力 :Qwen2.5 同样保持了对包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等 29 种以上语言的支持。
- 专业领域的专家语言模型能力增强 :即用于编程的 Qwen2.5-Coder 和用于数学的 Qwen2.5-Math,相比其前身 CodeQwen1.5 和 Qwen2-Math 有了实质性的改进。具体来说,Qwen2.5-Coder 在包含 5.5 T tokens 编程相关数据上进行了训练,使即使较小的编程专用模型也能在编程评估基准测试中表现出媲美大型语言模型的竞争力。同时,Qwen2.5-Math 支持中文和英文,并整合了多种推理方法,包括 CoT(Chain of Thought)、PoT(Program of Thought)和 TIR(Tool-Integrated Reasoning)。
- 全面开源 :Qwen2.5 系列在原有开源同尺寸(0.5/1.5/7/72B)基础上,还新增了 14B、32B 以及 3B 的模型。同时,通义还推出了 Qwen-Plus 与 Qwen-Turbo 版本,可以通过阿里云大模型服务平台的 API 服务进行体验。
- 预训练数据集更大更高质量 :从原本 7 万亿个 token 扩展到最多 18 万亿个 token,成为目前训练数据最多的开源模型之一。
- 多方面的能力增强 :比如获得更多知识、数学编码能力以及更符合人类偏好。在指令跟踪、长文本生成(从 1k 增加到 8K 以上 token)、结构化数据理解(如表格)和结构化输出生成(尤其是 JSON)方面均有显著提升。
注:Qwen2.5 模型结构是和 Qwen2 一致的,从 下面的配置文件里面就知道了。对源码感兴趣的可以跟读下面两篇文章: