本文是YashanDB共享集群系列文章第二篇文章,上一篇《自研一款共享集群数据库,有多难?》系统讲述了YashanDB共享集群自研架构,本文将深入解析YashanDB共享集群关键组件——高可用机制与核心技术。
共享集群高可用概述
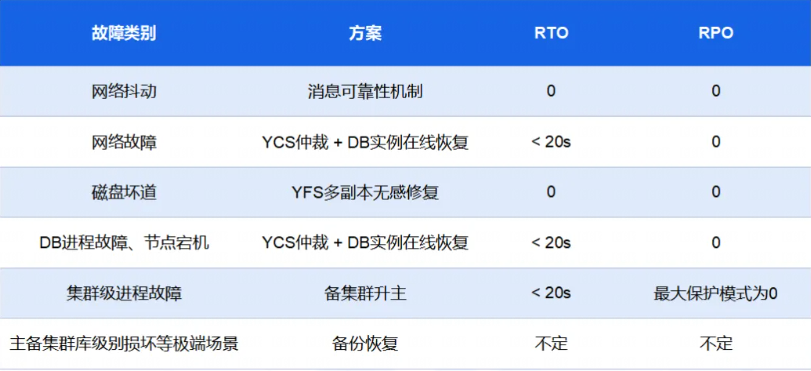
数据库系统运行过程中,经常遇到各种各样的故障情况,如存储故障、计算故障、网络故障、人为错误等等。当故障情况发生时,如何尽可能避免数据库服务受到影响、减小影响范围并快速恢复受影响服务,是数据库系统高可用能力的体现。
衡量数据库高可用能力有两个关键指标:RTO和RPO。RTO描述数据库服务恢复至可用所需时间,RPO描述数据库恢复至可用数据丢失情况。
实例故障RPO对比
常见的高可用架构有两种,一种是主备架构,一种是多活架构。共享集群形态属于后者。
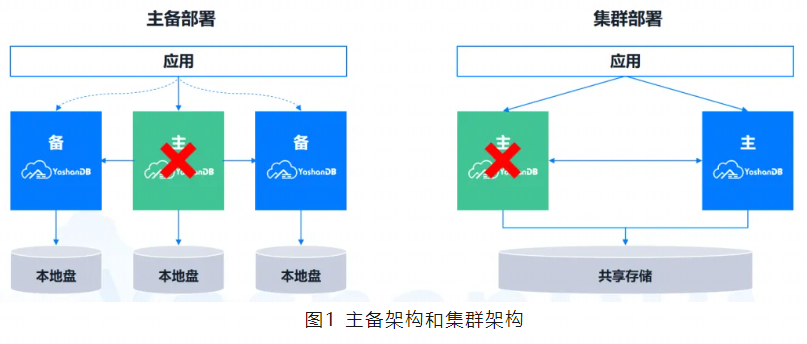
主备架构下,一个实例是主库,其他实例是备库,主库发送日志给备库,备库通过日志回放完成数据同步。主库提供全量读写业务,备库提供只读业务。当主库发生实例故障,数据库业务中断,直到某个备库升主,接管全量读写业务。当数据同步策略为非最大保护模式下,可能存在丢数据的情况。
共享集群架构下,所有实例都是对等的,均可提供全量读写业务。所有实例共享同一数据库,实例之间无需数据同步。某个实例发生实例故障时,其他实例仍可提供读写业务,通过TAF( Transparent Application Failover )能力自动接管故障实例业务,数据库内部自动进行实例恢复。各实例共享同一数据库,因此不存在丢数据的情况。
实例故障RTO对比
集群架构和主备架构下,发生实例故障时,RTO情况有所区别。
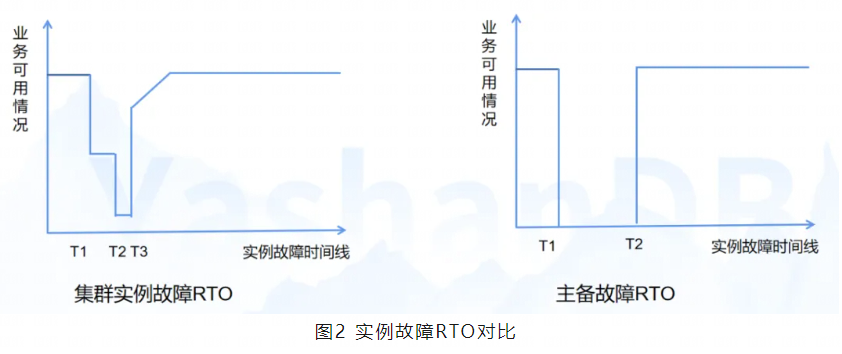
集群架构下,不存在业务不可用情况。实例故障恢复过程中,业务持续部分可用,业务可用情况随阶段变化。T1时刻为某个实例发生故障,该实例连接业务不可用;T2时刻为数据库开始进行实例恢复,因为冻结聚合内存,业务可用情况进一步下降;T3时刻为聚合内存恢复完毕,存活实例接管全量业务,数据库恢复至绝大部分业务可用,此后业务逐步恢复至全量可用。
主备架构下,存在业务不可用情况。实例故障恢复过程中,数据库业务完全不可用。当备库升主后,数据库恢复至业务完全可用状态。
共享集群高可用架构
从部署模式上,YashanDB共享集群支持主备库部署。备库支持多种形态,既可以配置为备集群形态,也可以是单机形态,以满足不同客户需求。主库发送日志给备库,备库回放日志完成数据同步。
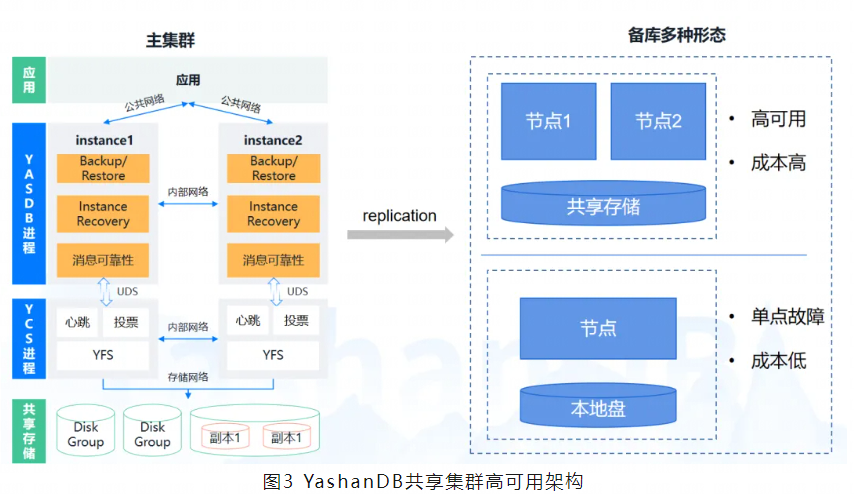
YashanDB共享集群有三大关键组件,设计了多种高可用核心特性,以应对更多故障场景。
-
崖山集群服务(YCS):是YashanDB的一个集群管理组件,提供包括节点管理、资源管理、集群监控、集群高可用等能力,支撑YashanDB共享集群从部署到启停的完整形态的稳定运行。YCS采用了多种心跳机制,来确保及时感知节点和资源的状态变化,在资源异常时进行资源处理,或在集群异常时进行脑裂仲裁。
-
崖山文件系统(YFS):是YashanDB自研的一个用户态存储服务组件,提供了文件系统以及磁盘组管理能力,用于管理共享磁阵。通过YFS可实现共享磁阵上基本的文件/文件夹创建、删除、浏览等功能。此外,YFS还提供了管理diskgroup(磁盘组)、failuregroup(故障组)等重要特性,以支持共享集群的存储高可用。
-
DB组件:是YashanDB数据库服务的核心组件,集群内多个DB实例通过内部通信完成业务交互。DB组件设计了集群级备份恢复、实例故障在线恢复、消息可靠性机制等特性,提高数据库高可用性。
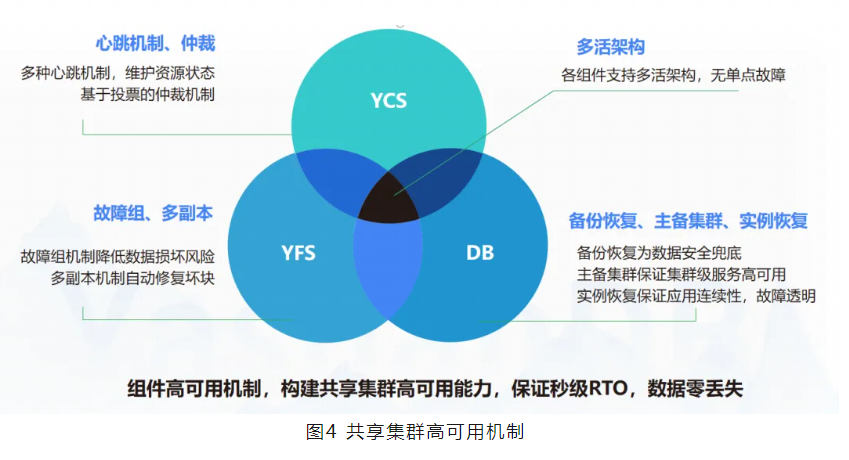
共享集群高可用核心技术
下面分别对三大组件的高可用机制展开描述。
YCS高可用机制
崖山集群服务YCS的高可用机制设计主要分为三种:心跳机制、故障仲裁机制、FENCE机制。
心跳机制
YashanDB共享集群内部设计了多种心跳机制,总体分为两类。
-
一类是,实例之间的心跳。若内部通信网络出现故障,实例之间的心跳无法完成,触发集群节点仲裁,按照仲裁策略进行节点剔除,完成集群重组恢复。
-
另一类是节点和共享磁阵的心跳。若节点与共享磁阵的网络出现故障,节点的磁盘心跳无法进行,YCS组件发现某些节点磁盘心跳更新超时,触发故障重组,剔除心跳超时节点以恢复集群。
故障仲裁机制
YCS组件为多活架构,如果遇到YCS组件故障,可通过其他存活节点完成集群仲裁重组。
FENCE机制
YCS设计了FENCE机制避免集群出现被剔除节点脑裂双写的问题。
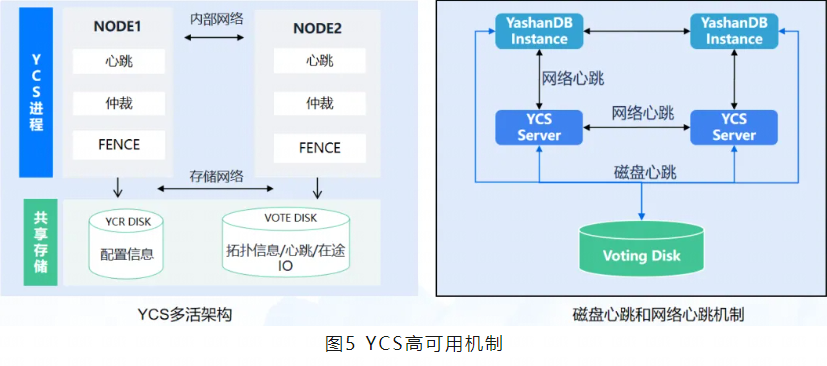
下面详细阐述一下集群部署下脑裂问题和解决方案。基于共享存储的集群系统,当发生集群节点脑裂仲裁时,如果不加以控制,会导致踢除集群的存活节点仍然不受控地读写共享存储,造成数据损坏;常见的故障如内部网络故障和存储网络故障都会触发集群进行在线的仲裁。
举个例子,当出现集群3实例部署情况如下:
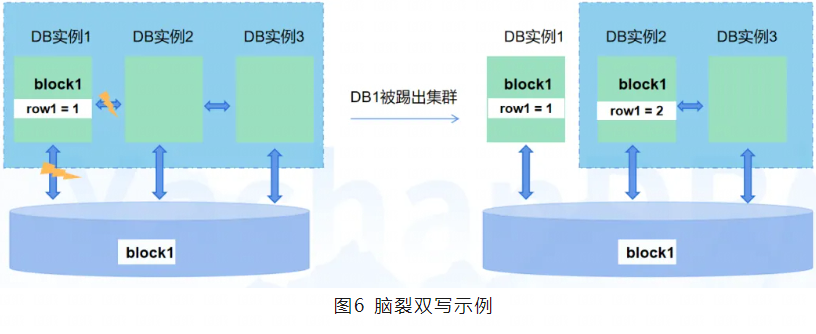
DB实例1正在更新block1的row1,DB实例1所在环境出现网络故障,YCS仲裁重组集群,节点1被剔除集群,节点2、3重组新的集群。DB实例2此时也更新block1的row1,于是出现被踢出集群的节点与重组后的集群产生双写冲突,导致数据更新错误。
针对以上脑裂双写问题,业内常用解决方案有两种:一是从数据访问端去隔离,确保节点真的故障,可以采用IPMI强制关机,强制关闭进程的方法;二是从IO侧去阻止该节点访问共享资源,可以采用SCSI-3 persistent reservations方法。
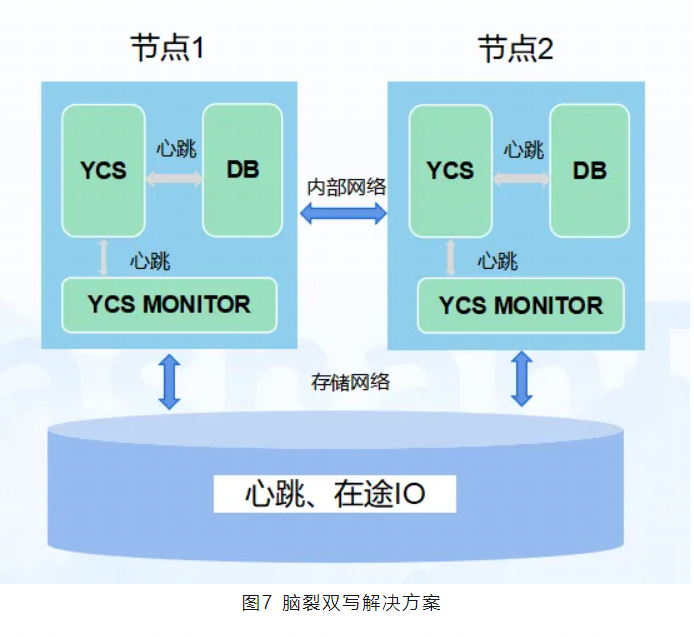
YashanDB基于第一种方案做了优化,集群节点会定期维护自身的在途IO信息、心跳信息策略。
若在途IO信息数由0变为非0时,则同步维护;若在途IO信息数为非0到非0的变化,则异步维护。
此外,节点内的YCS、DB组件设计有心跳机制。如果心跳超时,DB会自杀;在极端情况下,YCS进程卡住,无法自杀,此时需要靠YCS看护进程(YCS MONITOR)杀死YCS进程。
YashanDB对于常见的存储网络故障和内部网络故障,解决方案如下:
对于存储网络故障:
-
若节点1的存储网络异常,节点2的YCS进程感知到节点1磁盘心跳维护发生超时,触发集群仲裁;
-
节点1的YCS进程感知磁盘心跳维护超时,KILL节点1的DB进程,DB进程自杀;
-
集群仲裁重组后,节点1被剔除集群,新集群只有节点2;
-
新集群重组对外提供服务前,如果被踢出节点的在途IO大于0,等待一个磁盘心跳超时周期后,方可提供服务;
-
心跳超时默认为30S,存储网络延时为毫秒级,可以保证集群重组后,不存在被踢出节点的在途IO与新集群产生双写问题。
对于内部网络故障:
-
节点1与节点2的内部网络异常时,节点间的心跳超时后,节点1将节点2的磁盘信息修改为离线状态;
-
节点2的存储网络正常,感知自身被修改为离线状态,KILL节点2的DB进程后,DB进程自杀;
-
后续流程同存储网络故障的3、4、5步骤。
YFS高可用机制
崖山文件系统YFS的高可用机制也分为三种。
数据高可用
YFS通过磁盘组(diskgroup)的方式管理磁盘设备,内部通过多个故障组和多副本机制,支持数据高可用。可配置的冗余级别,方便用户根据业务特征决定数据冗余度。
服务高可用
当集群节点数发生变化或个别节点异常退出时,YFS可进行自动调整,恢复服务能力。
一致/可靠性
YFS内部采用了与DB相同的redo和checkpoint机制,用于保证YFS状态的一致性和可靠性,因此当整个集群发生异常重启时,系统能够自动从异常中恢复服务。

下面详细说明YFS故障组机制。下图是YFS故障组机制的示意图。
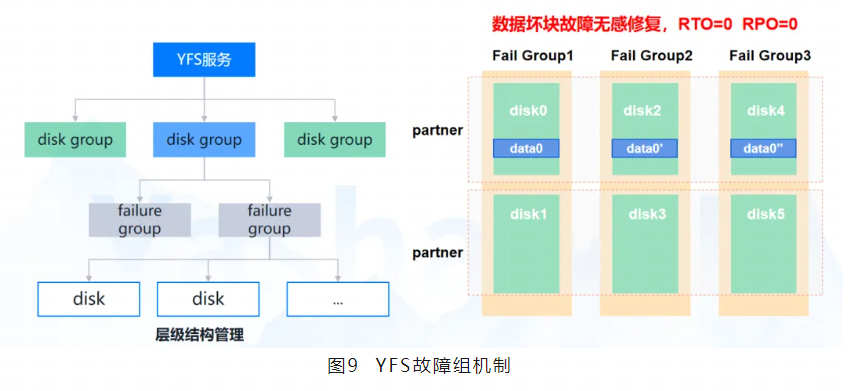
YFS 的 Disk Group 是实现高可用的核心组件,在 Disk Group 内将磁盘按故障概率相关性划分为 Failure Group,提升数据在磁盘故障中的生存率。由 Disk Group 管理的多磁盘共同组成“逻辑卷”,扩大磁盘 IO 带宽。
Failure Group 是YFS高可用的核心概念,配合“多副本”特性共同实现数据冗余(包括元数据以及文件数据)。每个Failure Group可以包含多个disk,这些disk有可能同时故障,例如以下场景:
-
同一磁阵的 LUN;
-
同一机柜的磁盘;
-
同一电源供电的多个存储单元;
-
同一机房的多个存储单元。
Failure Group之间不会同时故障(或者故障概率极低),这样就可以保证数据冗余的有效性。
YFS组件写入DB传入的数据时,根据Disk Group指定的副本数进行数据冗余。当YFS处理读IO调用DB数据校验接口,若发现数据损坏,校验不通过时,可从其他副本读取数据,如果读取到正确数据,自动修复损坏副本,实现数据坏块故障无感修复的能力。
DB高可用机制
多活架构
YashanDB共享集群为多活架构,每个节点都是对等状态,可对外提供全量服务。具备以下优点:
-
无需切换:共享集群中计算节点无状态,任何存活节点均可快速接管业务;
-
数据同步:由于节点访问共享存储中同一份数据,故数据强一致不丢失RPO=0;
-
快速恢复:DB感知实例故障后,自动进行快速恢复,恢复期间,业务持续部分可用,完全可用时间小于20S。
主备集群复制
为了防止集群级实例故障,YashanDB共享集群支持主备集群部署。主集群发送日志至备集群,备集群通过日志回放完成数据同步。
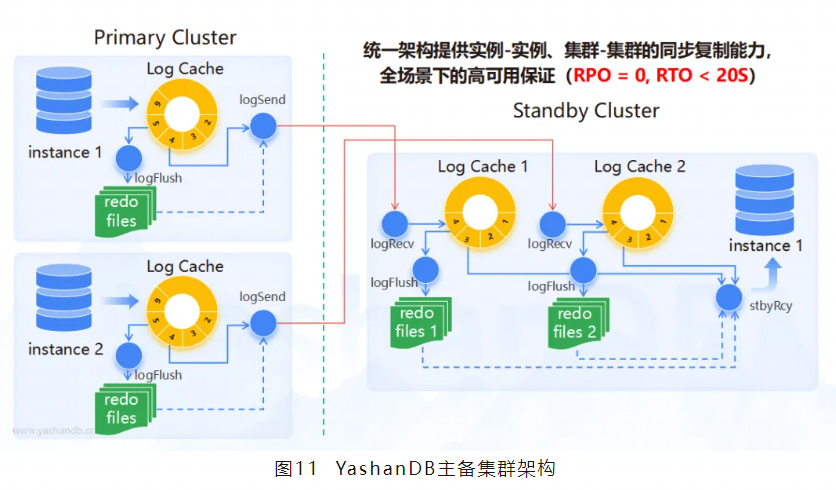
YashanDB的主备集群架构如上图所示,左边为主库组件,右边为备库组件。
各组件解释如下:
-
Log Cache:日志缓存。主库上Redo日志会首先写入日志缓存,备库收到Redo日志后也会写入日志缓存。
-
Log Flush:日志刷盘线程。将日志缓存里的Redo日志持久化到磁盘。
-
LogSend:日志发送线程。依次从日志缓存,Redo文件,归档文件读取Redo日志,发送给备库。
-
LogRecv:日志接收线程。接收来自主库的Redo日志,写入日志缓存。
DB实例恢复
集群形态部署下,每个DB实例均为对等状态,承载部分全局资源,所有DB实例共享数据库,通过聚合内存模块完成业务的并发控制。
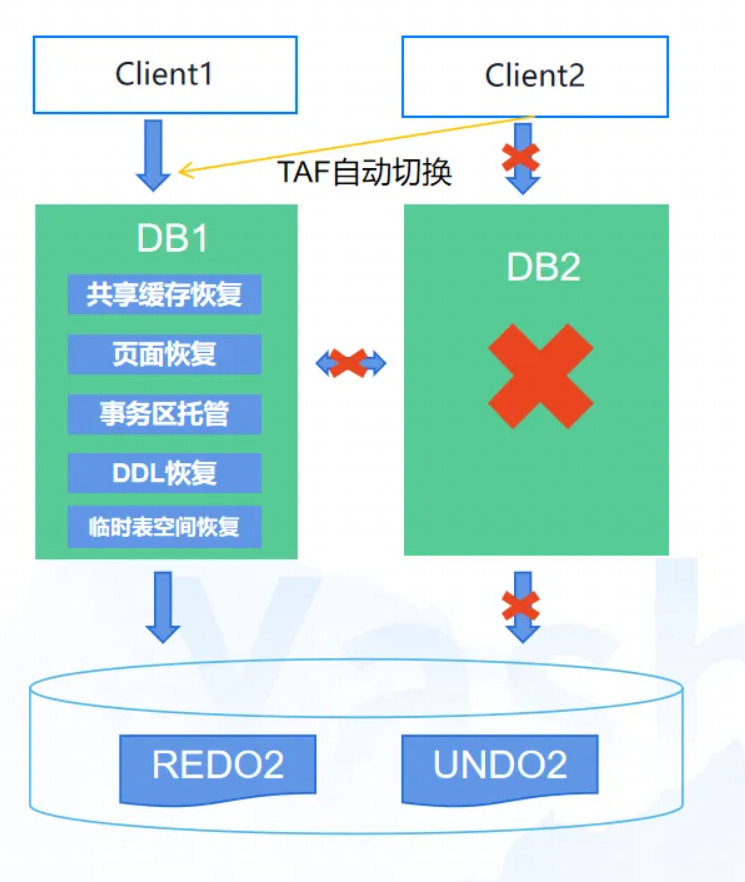
以上图情况为例,集群形态部署下,每个DB实例均为对等状态,承载部分全局资源,所有DB实例共享数据库,通过聚合内存模块完成业务的并发控制。如果部分DB实例异常关闭,导致整个DB集群处于不一致状态,包括数据库物理页面的不一致,共享缓存状态的不一致。
YCS检测到部分DB异常关闭时,通过更新其他DB实例的拓扑状态,DB感知到其他实例的异常,则触发实例故障在线恢复,使DB集群恢复至一致状态。
DB实例故障时,其他活跃实例触发在线恢复,其关键步骤包含:共享缓存恢复、页面恢复、事务区恢复、DDL恢复、临时表空间恢复。在线恢复期间业务持续部分可用,共享缓存恢复后即可恢复绝大部分业务,此步骤耗时为秒级。
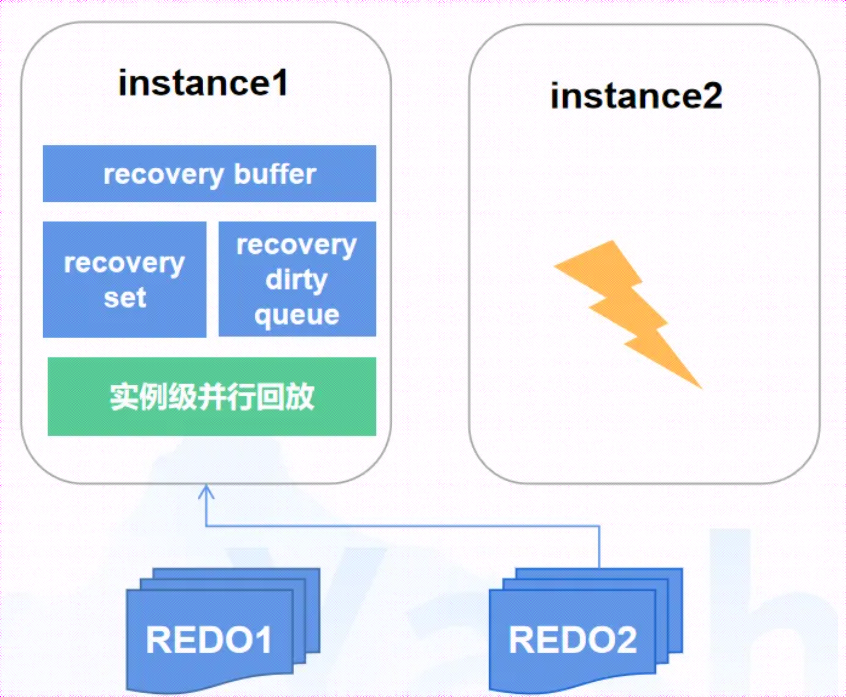
实例故障恢复处理页面恢复时,活跃实例通过读取故障实例日志文件,回放需要重演的日志,完成故障实例页面恢复。通过构造恢复集精准识别需要恢复的页面,减少无效的资源访问,采用并行回放机制,提高页面恢复效率。
在共享存储集群中,事务的管理通常有两种方式:集中式事务管理和分布式事务管理。
集中式事务管理,即所有实例的事务都集中到一个实例上管理,事务的分发、同步、启停等对性能有着比较大的影响,但实例故障时,故障实例的事务可以由事务管理实例直接管理。
分布式事务管理,即事务在每个实例上是独立管理的,根据一定的算法,每个实例的事务ID具有集群全局唯一性。其优点为,节省事务跨实例分发、同步的性能开销,同时事务可根据ID定位到其属于哪个实例管理的事务。
YashanDB集群使用的是分布式事务管理,托管事务机制。主要解决两个问题,故障实例上正常结束事务的访问,故障实例上未结束事务的回滚。
当集群中某个实例意外故障时,集群会根据一定的算法选出若干个在线实例,叫托管实例,该实例会接管故障实例的全部事务,此时其他实例访问故障实例上的事务,将会转到托管实例上,这就不会阻塞事务的查询。同时,托管实例会回滚故障实例上未完成的事务,进而提升故障实例重启的速度。
高可用机制总结
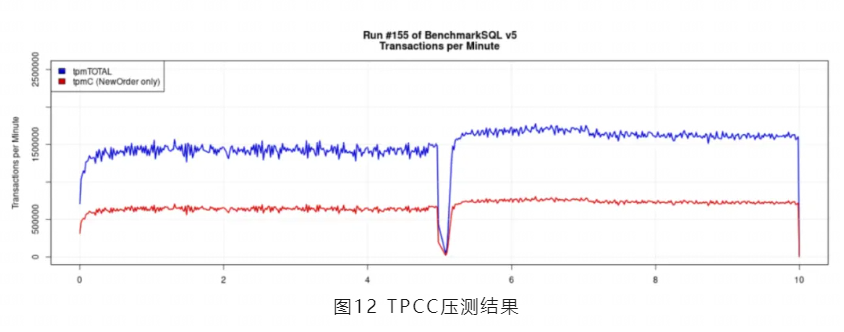
YashanDB共享集群的高可用表现究竟如何?选取TPCC业务模型,采取两实例集群部署,进行TPCC压测,压力为60万TPMC,持续压测五分钟后,kill某个DB实例。结果表明,实例故障恢复期间业务持续部分可用。从实例故障到数据库服务恢复至业务完全可用耗时为8秒。
此外,针对各种故障场景,梳理前文所述集群高可用关键设计和RTO/RPO表现,可总结如下表格: