ZooKeeper简介
什么是ZooKeeper
官方文档上这么解释ZooKeeper,它是一个分布式协调框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
ZooKeeper主要有如下两个核心的概念:文件系统数据结构 + 监听通知机制。
文件系统数据结构
ZooKeeper维护一个类似文件系统的数据结构:每个子目录项都被称作为 znode(目录节点),和文件系统类似,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode。同级节点名称都是唯一的
- 有 七种 类型的znode:
- PERSISTENT(持久化目录节点) :客户端与ZooKeeper断开连接后,该节点依旧存在,只要不手动删除该节点,他将永远存在;
- PERSISTENT_SEQUENTIAL(持久化顺序编号目录节点) :客户端与ZooKeeper断开连接后,该节点依旧存在,只是ZooKeeper给该节点名称进行 顺序编号
这里注意只是将节点名字顺序编号,所以咱们通过方法获取所有子节点时,返回的节点集并非有序的,需要自己排序; - EPHEMERAL(临时目录节点):客户端与ZooKeeper断开连接后,该节点被删除;
- EPHEMERAL_SEQUENTIAL(临时顺序编号目录节点):客户端与ZooKeeper断开连接后,该节点被删除,只是ZooKeeper会给该节点名称进行顺序编号
这里注意只是将节点名字顺序编号,所以咱们通过方法获取所有子节点时,返回的节点集并非有序的,需要自己排序; - Container(容器节点):3.5.3版本新增,如果Container节点下面没有子节点,则Container节点 在未来会被ZooKeeper的定时任务自动清除。
定时任务默认每60S检测一次; - TTL(Time To Life节点) :3.5.5版本新增,默认禁用,需要通过在zoo.cfg中新增配置 extendedTypesEnabled=true 开启。可指定节点存活时间,当该节点下面没有子节点的话,超过了 TTL 指定时间后就会被自动删除,特性跟上面的 容器节点 很像,只是 容器节点 没有超时时间而已;
- TTL顺序节点(Time To Life顺序节点节点) :和普通TTL节点类似,只是ZooKeeper会给该节点名称进行 顺序编号
这里注意只是将节点名字顺序编号,所以咱们通过方法获取所有子节点时,返回的节点集并非有序的,需要自己排序;
监听通知机制
客户端注册监听它关心的任意节点,或者目录节点及递归子目录节点
- 如果注册的是对某个节点的监听,则当这个节点被删除,或者被修改时,对应的客户端将被通知;
- 如果注册的是对某个目录的监听,则当这个目录有子节点被创建,或者有子节点被删除,对应的客户端将被通知 ;
- 如果注册的是对某个目录的递归子节点进行监听,则当这个目录下面的任意子节点有目录结构 的变化(有子节点被创建,或被删除)或者根节点有数据变时,对应的客户端将被通知;
注意:所有的通知都是一次性的,及无论是对节点还是对目录进行的监听,一旦触发,对应的监听即被移除。递归子节点,监听是对所有子节点的,所以,每个子节点下面的事件同样只会被触发一次。
分布式锁实现
互斥锁
非公平锁
利用 ZooKeeper的同级节点的唯一性特性,在需要获取排他锁时,所有的客户端试图通过调用 create() 接口,在 指定父节点 假定父节点名字为 /exclusive_lock下创建临时子节点 /exclusive_lock/lock,最终只有一个客户端能创建成功,那么此客户端就获得了分布式锁。同时,所有没有获取到锁的客户端可以在 /exclusive_lock 上注册一个子节点变更或监听 /exclusive_lock/lock 节点删除的 watcher 监听事件,以便重新争取获得锁。
如上实现方式在并发问题比较严重的情况下,性能会下降的比较厉害,主要原因是,所有的连接都在对同一个节点进行监听,当服务器检测到删除事件时,要通知所有的连接,所有的连接同时收到事件,再次并发竞争,这就是 惊群效应 。 所以需谨慎使用该方法,也可以使用临时顺序节点来实现公平锁解决该问题
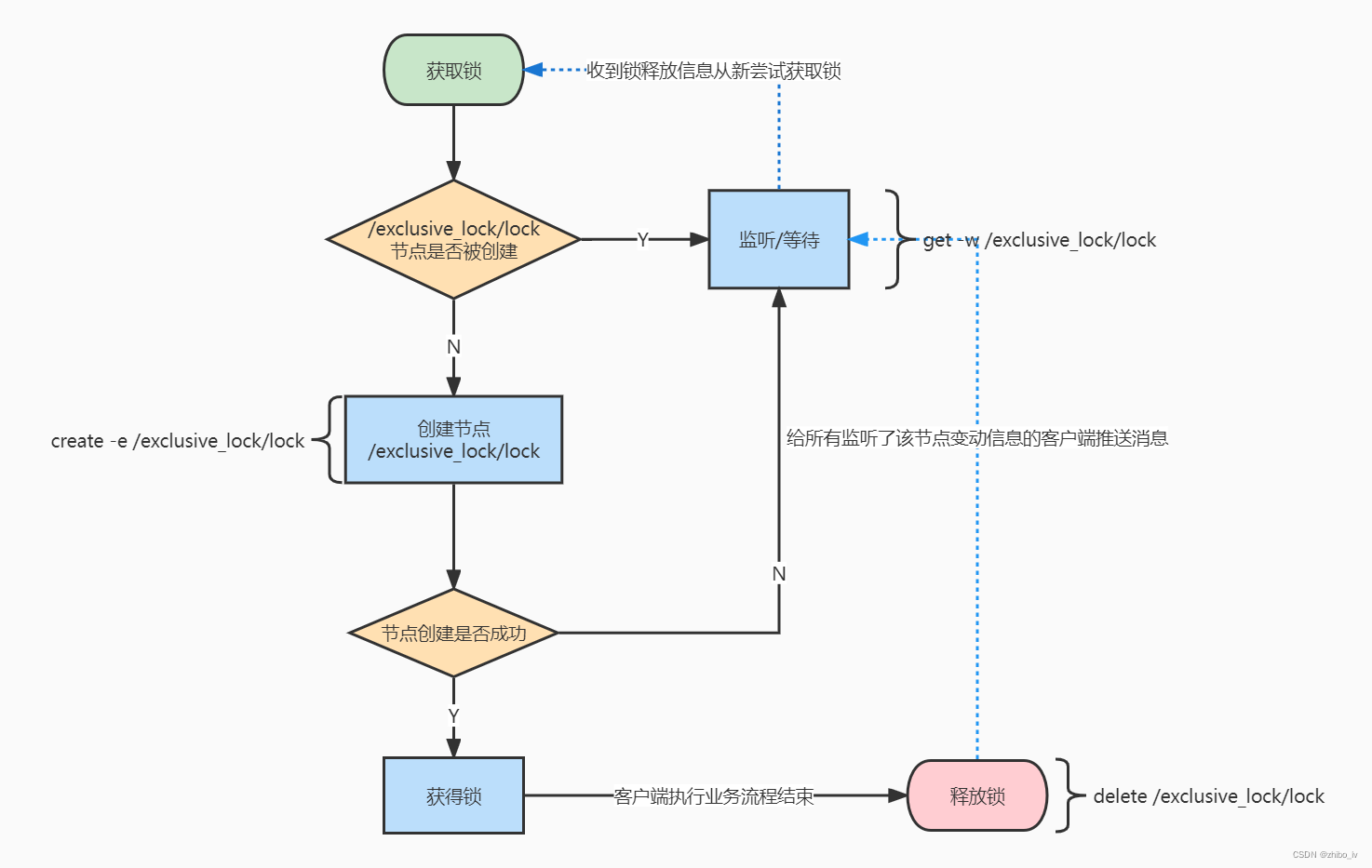
公平锁
- 每个客户端都往指定的节点下注册一个临时有序节点;
- 判断自己是不是指定节点下,最小的节点
越早创建的节点,节点的顺序编号就越小;
2.1 如果是最小的则获取锁;
2.2 如果不是最小的,则对排在自己前面的最近的节点进行监听; - 获得锁的客户端处理完业务释放锁,其后继的第一个节点将会收到通知,然后重复 流程 2 的判断;
Curator 简介
Curator 是一套由netflix 公司开源的,Java 语言编程的 ZooKeeper 客户端框架,Curator项目是现在ZooKeeper 客户端中使用最多,对ZooKeeper 版本支持最好的第三方客户端,并推荐使用,Curator 把我们平时常用的很多 ZooKeeper 服务开发功能做了封装,例如 Leader 选举、分布式计数器、分布式锁。这就减少技术人员在使用 ZooKeeper 时的大部分底层细节开发工作。在会话重新连接、Watch 反复注册、多种异常处理等使用场景中,用原生的 ZooKeeper 处理比较复杂。而在使用 Curator 时,由于其对这些功能都做了高度的封装,使用起来更加简单,不但减少了开发时间,而且增强了程序的可靠性。 下面的源码部分将会采用Curator的实现来解读
Maven pom依赖引入
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.2.0</version>
</dependency>
Curator互斥锁加解锁Demo
package com.zhibo.zookeeper;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ZookeeperMutexDemo {
@Autowired
private CuratorFramework curatorFramework;
/**
* 减少库存方法 公平锁
* @param id 需要被上锁的业务主键ID
*/
public void reduceStock(Integer id) throws Exception{
//基于临时有序节点来实现的分布式锁.
InterProcessMutex lock = new InterProcessMutex(curatorFramework, "/Locks_" + id);
try {
lock.acquire(); //抢占分布式锁资源(阻塞的)
//加锁成功后的业务逻辑....
} finally {
lock.release(); //释放锁
}
}
}
源码解读
InterProcessMutex构造函数解析
// 注意这里的 new StandardLockInternalsDriver 这个对象是核心会赋值给org.apache.curator.framework.recipes.locks.LockInternals#driver
public InterProcessMutex(CuratorFramework client, String path) {
this(client, path, new StandardLockInternalsDriver());
}
acquire() 加锁方法解析
加锁方法的核心就是 org.apache.curator.framework.recipes.locks.InterProcessMutex#internalLock
private boolean internalLock(long time, TimeUnit unit) throws Exception {
//得到当前线程
Thread currentThread = Thread.currentThread();
//使用threadData存储线程重入的情况
InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread);
if (lockData != null) {
//同一线程再次acquire,首先判断当前的映射表内(threadData)是否有该线程的锁信息,如果有则原子+1,然后返回
lockData.lockCount.incrementAndGet();
return true;
} else {
// 映射表内没有对应的锁信息,尝试通过LockInternals获取锁
// 核心方法咱们继续往下解读
String lockPath = this.internals.attemptLock(time, unit, this.getLockNodeBytes());
if (lockPath != null) {
// 成功获取锁,记录信息到映射表
InterProcessMutex.LockData newLockData = new InterProcessMutex.LockData(currentThread, lockPath);
this.threadData.put(currentThread, newLockData);
return true;
} else {
return false;
}
}
}
org.apache.curator.framework.recipes.locks.LockInternals#attemptLock 创建临时顺序节点并获取锁方法解析
实际上是向zookeeper注册一个临时有序节点,并且判断当前创建的节点的顺序是否是最小节点。如果是则表示获得锁成功,如果不是最小节点那就对最近的前驱节点进行监听
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception {
long startMillis = System.currentTimeMillis();
Long millisToWait = unit != null ? unit.toMillis(time) : null;
byte[] localLockNodeBytes = this.revocable.get() != null ? new byte[0] : lockNodeBytes;
// 当前已经重试次数,与CuratorFramework的重试策略有关
int retryCount = 0;
String ourPath = null;
boolean hasTheLock = false;
boolean isDone = false;
while(!isDone) {
isDone = true;
try {
// 在Zookeeper中创建临时顺序节点
// 注意上面有说InterProcessMutex的构造函数this.driver 其实就是 StandardLockInternalsDriver
ourPath = this.driver 就是 .createsTheLock(this.client, this.path, localLockNodeBytes);
// 循环等待来获取分布式锁,实现锁的公平性
// 核心方法咱们继续往下解读
hasTheLock = this.internalLockLoop(startMillis, millisToWait, ourPath);
} catch (NoNodeException var14) {
if (!this.client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper())) {
throw var14;
}
isDone = false;
}
}
// 成功获得分布式锁,返回临时顺序节点的路径
return hasTheLock ? ourPath : null;
}
org.apache.curator.framework.recipes.locks.LockInternals#internalLockLoop 锁获取
这里注意了为什么每一次被唤醒都需要从新排序且判断自身节点是否为当前最小节点呢?
因为上一个节点有可能因为超时、客户端连接中断等异常情况导致节点删除,所以当收到节点删除通知后不能直接默认可以拿到锁资源,而需要从新判断。
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception {
boolean haveTheLock = false;
boolean doDelete = false;
try {
if (this.revocable.get() != null) {
((BackgroundPathable)this.client.getData().usingWatcher(this.revocableWatcher)).forPath(ourPath);
}
//在没有获得锁的情况下,直到超时或成功获取锁
while(this.client.getState() == CuratorFrameworkState.STARTED && !haveTheLock) {
//获取所有子节点路径,并且进行排序,上面有说通过网络获取到的节点信息是无序的所以需要手动排序
List<String> children = this.getSortedChildren();
//获取自己创建的临时顺序节点名称
String sequenceNodeName = ourPath.substring(this.basePath.length() + 1);
//去获取锁 核心逻辑咱们继续往下解读
PredicateResults predicateResults = this.driver.getsTheLock(this.client, children, sequenceNodeName, this.maxLeases);
if (predicateResults.getsTheLock()) {
// 获得了锁,中断循环,继续返回上层
haveTheLock = true;
} else {
// 没有获得到锁,获取getsTheLock方法返回的节点名称
String previousSequencePath = this.basePath + "/" + predicateResults.getPathToWatch();
synchronized(this) {
try {
// 因exists()可以监听不存在的 ZNode,所以这里如果使用exists()会导致导致资源泄漏,因此采用getData() ,对节点进行监听
((BackgroundPathable)this.client.getData().usingWatcher(this.watcher)).forPath(previousSequencePath);
if (millisToWait == null) {
//未设置超时时间则不限时等待
this.wait();
} else {
millisToWait = millisToWait - (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if (millisToWait > 0L) {
// 有设置超时时间则指定等待时间
this.wait(millisToWait);
} else {
// 等待超时标记 后续会判断doDelete对节点进行删除
doDelete = true;
break;
}
}
} catch (NoNodeException var19) {
}
}
}
}
} catch (Exception var21) {
ThreadUtils.checkInterrupted(var21);
doDelete = true;
throw var21;
} finally {
if (doDelete) {
//删除当前节点
this.deleteOurPath(ourPath);
}
}
return haveTheLock;
}
org.apache.curator.framework.recipes.locks.StandardLockInternalsDriver#getsTheLock 尝试获取锁
public PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception {
//获取创建的锁节点在排序后的锁集合中的索引
int ourIndex = children.indexOf(sequenceNodeName);
//验证ourIndex是否为-1 如果为-1则说明之前创建的锁节点不存在 是无效的
validateOurIndex(sequenceNodeName, ourIndex);
//当前创建的锁节点位置< 1,也就是第0个。则当前线程获取到锁,maxLeases这个是写死的1.
boolean getsTheLock = ourIndex < maxLeases;
//如当前节点索引!=0 则获取 当前索引-1 也就是自身前一个节点的名字,用于外层做监听,这里就可以有效避免惊群效应
String pathToWatch = getsTheLock ? null : (String)children.get(ourIndex - maxLeases);
return new PredicateResults(pathToWatch, getsTheLock);
}
release()释放锁方法详解
public void release() throws Exception {
Thread currentThread = Thread.currentThread();
InterProcessMutex.LockData lockData = (InterProcessMutex.LockData)this.threadData.get(currentThread);
if (lockData == null) {
throw new IllegalMonitorStateException("You do not own the lock: " + this.basePath);
} else {
// 锁是可重入的,初始值为1,原子-1到0,锁才释放
int newLockCount = lockData.lockCount.decrementAndGet();
if (newLockCount <= 0) {
if (newLockCount < 0) {
throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + this.basePath);
} else {
try {
// 释放锁资源
this.internals.releaseLock(lockData.lockPath);
} finally {
// 从映射表中移除当前线程的锁信息
this.threadData.remove(currentThread);
}
}
}
}
}
共享锁
读写锁
读写锁 ,也可以说是 共享锁 主要是解决部分场景下读写一致问题,同时相比 互斥锁 提高整体效率。比如如果数据没有进行任何修改的话,是不需要加锁的,但是如果读数据的请求还没读完,这个时候来了一个写请求,怎么办呢?有人已经在读数据了,这个时候是不能写数据的,不然数据就不正确了。直到前面读锁全部释放掉以后,写请求才能执行,以所有的读请求都需要加一个 读锁 ,让写请求知道,这个时候是不能修改数据的。不然数据就不一致了。如果已经有人在写数据了,再来一个请求写数据,也是不允许的,这样也会导致数据的不一致,所以所有的写请求都需要加一个 写锁 ,是为了避免同时对共享数据进行写操作。
Curator读写锁加解锁Demo
package com.zhibo.zookeeper;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.locks.InterProcessReadWriteLock;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ZookeeperReadWriteLockDemo {
@Autowired
private CuratorFramework curatorFramework;
/**
* 查询库存方法 读锁
* @param id 需要被上锁的业务主键ID
* @return 库存
*/
public Integer getStock(Integer id)throws Exception{
InterProcessReadWriteLock lock = new InterProcessReadWriteLock(curatorFramework, "/Locks_" + id);
try {
// 获取读锁
lock.readLock().acquire();
// 加锁成功后的业务逻辑....
} finally {
lock.readLock().release();
}
return 0;
}
/**
* 减少库存方法 写锁
* @param id 需要被上锁的业务主键ID
*/
public void reduceStock(Integer id) throws Exception{
InterProcessReadWriteLock lock = new InterProcessReadWriteLock(curatorFramework, "/Locks_" + id);
try {
// 获取写锁
lock.writeLock().acquire();
// 加锁成功后的业务逻辑....
} finally {
lock.writeLock().release();
}
}
}
逻辑解析
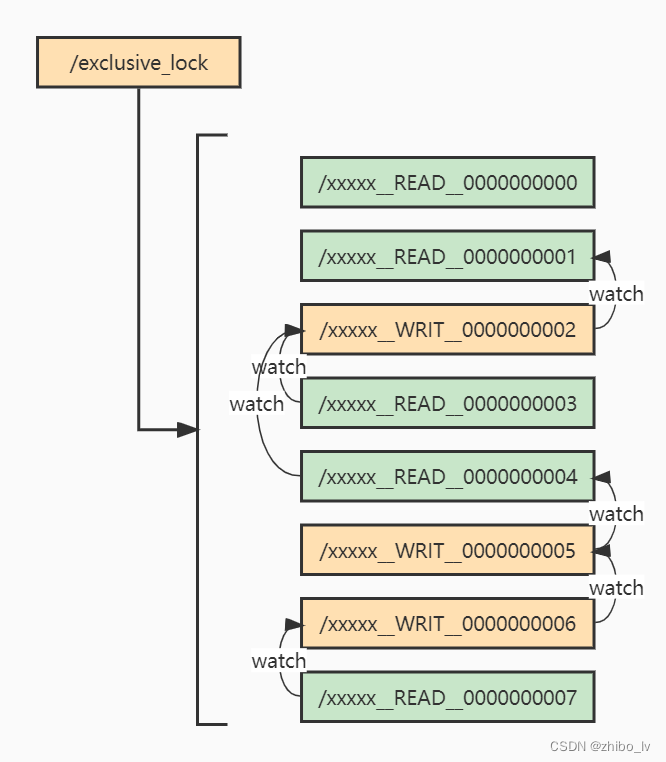
读锁写锁都是基于 InterProcessMutex 实现的,所以基本都和 InterProcessMutex 没有区别。不过这里生成的锁名字不再是 -lock- 而是换成了 __WRIT__ 和 __READ__
- __READ__(读锁):如果前面比自己小的节点都是读锁,则直接获取锁,如果前面有写锁
也就是节点排序编号前是__WRIT__,则需要对前面的写节点监听,如果存在多个写锁,对最后一个写节点进行监听; - __WRIT__(写锁):和 互斥锁 逻辑一致,只要前面有序号更小的节点,则对排序后的自身索引 - 1的节点进行监听;
你的点赞就是我创作的最大动力,如果写的不错,来个三连行不行