前言
不得不承认,2014年ImageNet挑战赛的获奖论文真的都很优秀,这次是分类问题的第一名:GoogLeNet。本来打算通过阅读一些网络结构方面的论文,了解一下网络设计和优化的原理,能够自己设计出更合理的网络。但是读完这篇GoogLeNet论文后,我完全被其理论深度吓退了。本文网络设计的核心理论来源于S.Arora的Provable bounds for learning some deep representation,数学性实在太强了,暂时不打算啃了。
老规矩,给出一些对我理解GoogLeNet帮助很大的资料:
独家 |《TensorFlow实战》作者黄文坚:四大经典CNN网络技术原理
这篇博客讲解得很深入,我的理解和评价部分大都是从这里搬运过来的。
深入理解GoogLeNet结构(原创)
Inception V1
这两篇博客讲解还是很细致的
GoogLeNet的心路历程(二)
经典论文阅读(3)-GoogLeNet-InceptionV1及其tensorflow实现
[DL-CV]浅谈GoogLeNet(咕咕net)
这三篇博客讲解也很不错。
GoogLeNet论文下载传送门
最后是GoogLeNet论文下载链接。
下面全文梳理一下GoogLeNet,然后写一些对于论文的理解(其实主要也是看别人的理解然后搬运过来)。
GoogLeNet论文阅读笔记
Abstract
提到了本文模型的优势是在有限的计算资源条件下增加了网络的深度和宽度。为了优化网络的性能,网络设计基于了Hebbian principle,还采用了多尺度的处理过程。
1.Introduction
阐述了最近以来,深度学习和卷积神经网络取得了很多成就。这些成就不仅仅是因为硬件技术的进步、更大的数据集、更大的网络,还有很多是因为有更新更好的idea、算法和更好的网络结构。
随着移动设备和嵌入式计算的发展,不能再单一地追求检测的准确率,还要考虑算法的效率(要又准又快)。本文设计的网络,在大多数实验中都保持在15亿次的乘法-加法次数,因此不仅仅是在学术研究上有贡献,而且也是能落地的。
总体来说,我们可以把Inception模型视为受到了Provable bounds for learning some deep representations启发的Network In Network逻辑顶点。
2. Related Work
提到了自LeNet后,卷积神经网络的标准结构是:卷积层的堆叠(而且经常卷积后加上归一化层和池化层)加上一层或多层全连接层。
受到神经科学中灵长类动物视觉皮层发现的影响,Serre使用了一系列不同尺寸的固定Gabor滤波器来处理多尺度问题,本文采用了类似的策略。与他们的技术相比,本文所有Inception网络中的滤波器都是网络学习得到的。而且Inception层重复堆叠多次,最终达到了22层的深度。
特别提到了Network-in-Network的做法,本文大量地采用了1*1大小的卷积核。1*1卷积核主要作用是降维,减小计算量。因此采用1*1的卷积核可以在不影响网络性能的前提下增加网络的深度和宽度。
目前目标检测技术的state-of-the-art技术是RCNN。RCNN将检测问题拆解成两个子问题:利用low-level的特征(如颜色或纹理)来确定物体的大概位置(此时只是认为这个位置可能有物体,但是不知道是什么物体);然后用CNN分类器去确定这个位置的物体是什么。这个方法其实是low-level特征和high-level特征相结合的做法。收到RCNN的启发,我们采用了和他们类似的技术,但是在两个子问题上都做了改进。
3. Motivation and High Level Considerations
最直接的提升网络性能的方法是增加网络的size,包括增加网络的深度和宽度(这里的宽度应该是同一层滤波器的数量),但是这会带来两个问题:参数太多会过拟合,特别是样本少的时候;需要大量的计算资源,而且盲目增加size可能导致一种情况,就是消耗了大量资源去计算结果发现性能只提升了一丢丢,这就极大地浪费了计算资源。
根本的解决方法是在网络结构的设计中引入稀疏性的概念。文章特别提到了Provable bounds for learning some deep representations这篇论文。这篇论文的研究表明,如果数据集的概率分布可以用一个很大的并且很稀疏的网络来表示的话,那么通过分析前一层激活值统计上的相关性,并将输出的高度相关的神经元聚类,可以一层一层地分析得出最优的网络拓扑结构。这与神经学中的Hebbian原则是相呼应的。
这里插一句,Hebbian原则是什么:神经反射活动的持续与重复会导致神经元连接稳定性的持久提升,当两个神经元细胞A和B距离很近,并且A参与了对B重复、持续的兴奋,那么某些代谢变化会导致A将作为能使B兴奋的细胞。总结一下即“一起发射的神经元会连在一起”(Cells that fire together, wire together),学习过程中的刺激会使神经元间的突触强度增加。
然而,对于非均匀的稀疏的数据,现今的计算设备效率不高。因此如果按照Provable bounds for learning some deep representations的原则设计网络,实际上效果不太好(意思就是理论上稀疏网络效果好,但是硬件计算上稀疏网络不好算)。但是稀疏性也不是完全没法用的。
文章提到在空间稀疏性的概念上,目前的技术都采用了卷积操作,这就体现了一种空间上的稀疏性(但是现有技术仅仅是在卷积操作上体现了空间稀疏性的思想,应该也能有别的操作可以更充分地实现空间稀疏)。但是呢在卷积层的连接方面,后一层都是和前一层的所有feature map相连的,这种连接是一种密集的连接而非稀疏的(本来最开始在LeNet中连接还是稀疏的,但是AlexNet中就和前一层全连上了,目的是优化并行运算)。
因此本文考虑是否能有一个更进一步的方案,能够实现filter-level的稀疏性,并且仍然采用密集矩阵,这样硬件计算也不会受影响。大量的文献表明,将稀疏矩阵聚类为相对密集的子矩阵会对于稀疏矩阵乘法更有利。本文就是研究如何用一些密集的、易实现的组件去估计出一个稀疏的网络结构。
4. Architectural Details
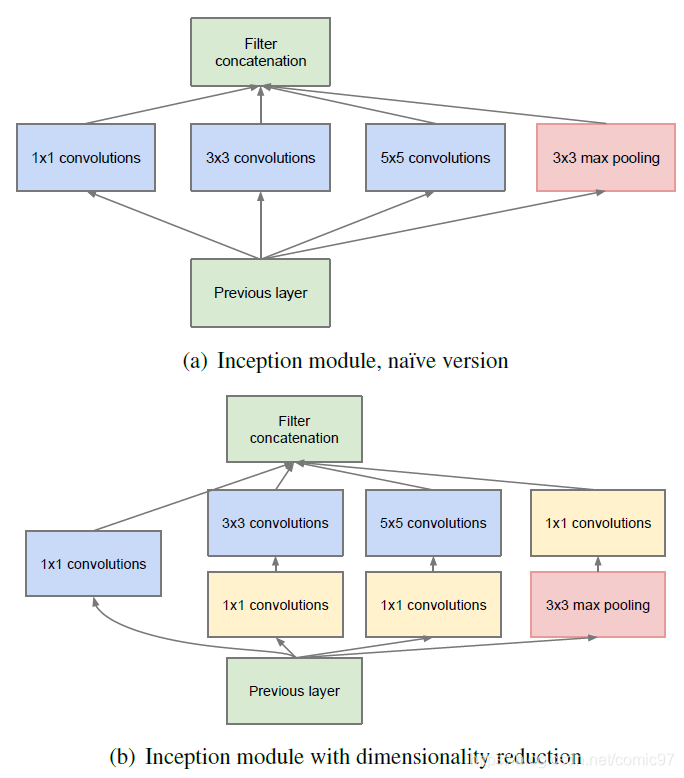
首先文章基于Provable bounds for learning some deep representations的理论提出了一个Inception模块的naïve版本。出于方便对齐的考虑将滤波器的尺寸设计为奇数(1*1、3*3和5*5)。
由于更抽象的特征会被网络的更高层神经元捕获到,因此他们的空间集中度应该降低。这启发我们在更高层的网络中,3*3和5*5的滤波器数量占比应该增加。
模型的一个重大问题在于,在网络的高层,即使只用很少的滤波器,5*5滤波器的计算代价也会很大。随着Inception模块的一层层堆叠,网络的计算代价会呈现爆炸式的增长。
这就引出了第二个idea,就是1*1卷积核的大量使用。由于低维度的数据也能包含一个很大尺寸的图像的信息,因此可以用1*1的卷积做数据压缩。在3*3和5*5计算之前,先用1*1卷积核对数据做压缩,将feature map的channel数降低。此外,1*1卷积还有一个优点,就是能多引入一个非线性激活,从而增加网络的非线性能力。利用1*1卷积改进原来的naïve版本的Inception,得到最终的Inception模块。
文章还提到,由于技术原因(训练时的内存效率问题),更好的做法是在网络的低层还是使用传统的卷积网络结构,而在高层再开始使用Inception模块,但是这也不是绝对的,这种做法只是反映了我们目前的实现方法还不够有效率。
直观上感受,Inception的设计将不同卷积尺度的特征进行整合,使得下一个模块可以同时从不同尺度的特征中提炼出更加抽象的特征。
由于Inception的设计提升了网络的深度和宽度,同时又有效地利用了计算资源,因此我们可以用Inception模型实现一个性能稍差,但是计算效率更高的模型。
5. GoogLeNet
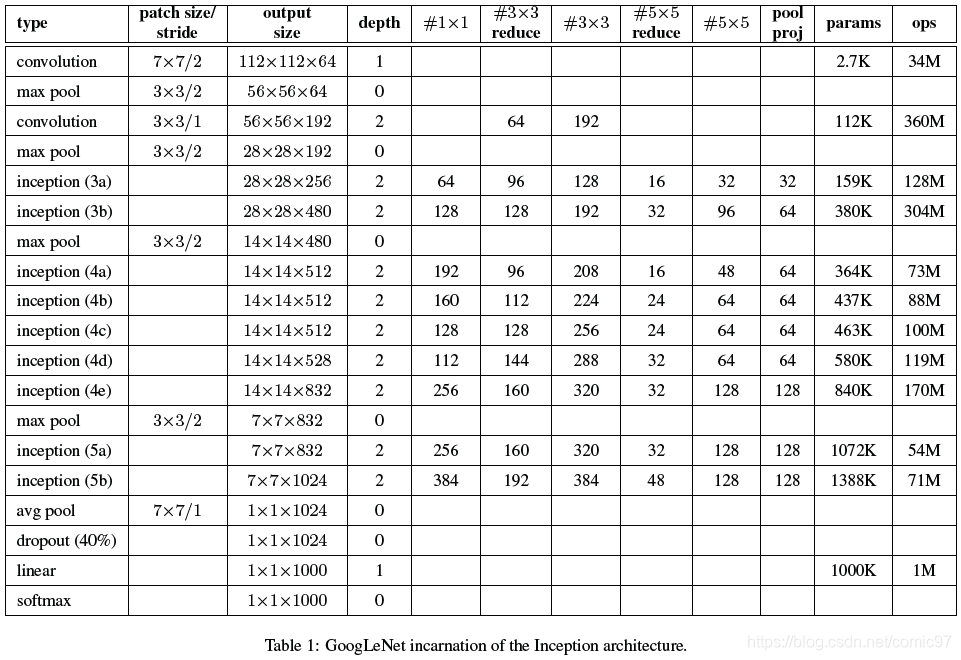
这部分就详细地介绍了以Inception模块为基础的GoogLeNet网络的结构。文中提到,本文其实还测试了一个比这个网络更深更宽的Inception网络,性能提升了一丢丢,但是就没有必要介绍这个网络了(因为模型变大肯定性能会更好)。直接给出一个典型的Inception网络模型;
#3_3 reduce代表3*3卷积核前面的1*1卷积操作,#5_5 reduce同理。pool proj代表max pooling后的1*1卷积。网络中一共有9个Inception模块、22层,所有的激活都是relu。在最后一个Inception模块后,网络使用了avg pooling(Network-in-Network的思想),后面跟了全连接,但是文中说这个全连接目的是使得网络可以适应其他label的数据集,更多是考虑到方便性,作者也没指望这一层能起多大作用。这种用avg pooling代替全连接的做法可以将top-1准确率提高0.6%,但是与此同时尽管全连接被移除了,dropout依然很重要。
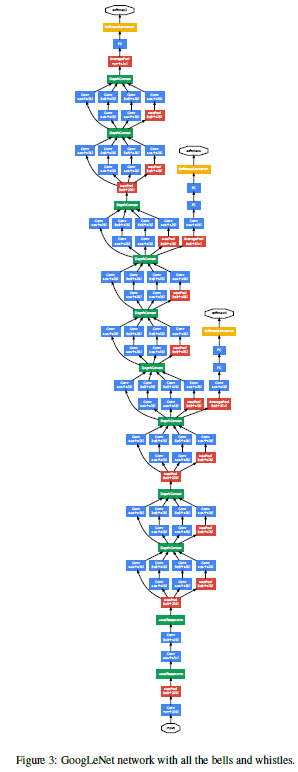
表格只是给出了一个网络的大体框架,一些细节的东西像LRN和多个softmax输出都没有写上去。完整的网络结构见下图:
网络加深了以后,梯度的传播成为了一个难题。由于浅层网络也具有较强的分类性能,这启发我们,网络中间层的信息也具有一定的判别性。通过添加辅助分类器(就是低层网络添加softmax输出),使得网络的中间层也可以输出分类结果。这种方法既能够缓解梯度消失的问题(中间层也能向前传播梯度,而且中间层的深度还不太深,梯度消失问题还不明显),同时也能提供一个正则化作用(不太懂这个正则化作用是怎么来的,感觉上是不是由于低层的网络参数更少,因此用这些网络做预测相当于参数变少了)。在训练时,辅助分类器的loss以一定的权重(权重取0.3)添加到总的loss上;但是在测试时,辅助分类器被移除(所以说辅助分类器的任务应该只是为了帮助训练网络)。
辅助分类器部分的网络超参数如下:avg pooling滤波器尺寸5*5,stride 3,输出尺寸是4*4*512(Inception 4a后)和4*4*528(Inception 4d后);1*1卷积滤波器数量是128,relu激活;一层全连接,1024个单元,relu激活;dropout概率70%(这个dropout应该是用在了这个1024个单元的全连接上);一层全连接,1000个单元,之后接softmax激活。
6. Training Methodology
这部分提到的tricks大部分都是在训练中采用的,下一小节用的tricks是在测试时用的,要区分开。
训练时采用异步随机梯度下降,动量参数0.9,学习率有一个微小的衰减(每8个epoch衰减4%)。提到了在测试时使用Polyak averaging(这个方法是什么还不太了解)。
对于图像的裁剪,本文的方法是:首先将原图进行rescale,rescale到原图的8%到100%(在这个范围内随机均匀取值,应该是由于使用了avg pooling,不需要限制输入图像的大小),此外rescale后图像的纵横比被限制到[3/4, 4/3]的区间。此外,文章提到了Some improvements on deep convolutional neural network based image classification论文给出的photometric distortions对于防止过拟合有作用。
7. ILSVRC 2014 Classification Challenge Setup and Results
这部分主要展示了GoogLeNet在分类问题上的表现。除了上文提到的一些训练中用到的tricks,本文在测试时还用了一些其他的tricks,在这里进行说明:
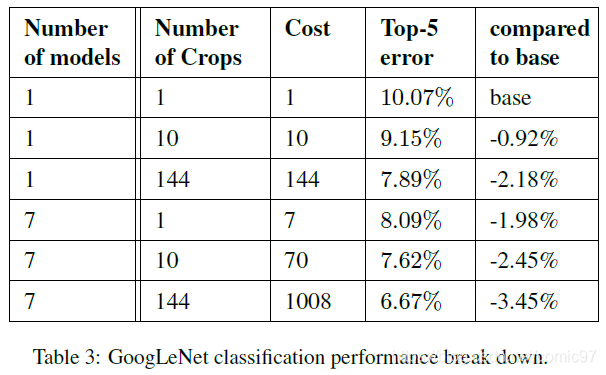
1、训练了7个网络,比较了不同网络数量的预测结果
2、对图像的crop策略是,将图像的短边rescale到四个不同的大小(256、288、320、352),用正方形方框框出rescale后图像的左、中、右三个区域(对于人像等高度比宽度大的图像,框出图像的上、中、下三个区域),对于每一个框出的区域,再用224*224的方框像AlexNet一样框出4个角的区域加上中间区域,此外,再将整个方框rescale到224*224,这样一个方框能得到6张图像,再加上他们的水平翻转版本。这样,对于一张测试图像,一共能扩充出4*3*6*2=144张。这种很aggressive的cropping策略会随着crop总数的增加,对网络性能的提升逐渐减小,因此,在实际运用时,不是很必要去追求极限的cropping数量。
3、每个分类器将所有crop图像的softmax概率求平均,然后再将所有分类器的softmax概率求平均,得到最终的预测结果(这里的分类器应该指的是网络最后的softmax输出,因为辅助分类器在测试的时候被去除了)。
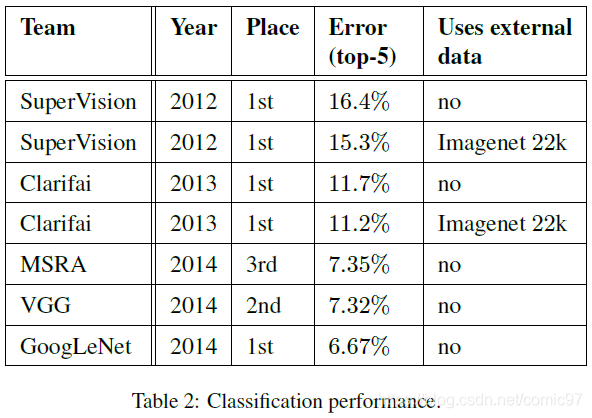
GoogleNet的top-5 error达到了6.67%,性能相比其他方法有了大幅度的提高。不同模型的性能对比和多个GoogLeNet多个crop的性能对比如下:
8. ILSVRC 2014 Detection Challenge Setup and Results
这部分讲的是网络在检测问题上的表现,还没有细看。
9. Conclusions
本文的结果表明,用密集的block去估计得到一个最优的稀疏的网络结构,对于提高网络的性能来说是很有效的。尽管其他方法可以通过加深网络的深度和宽度来得到和本文网络性能差不多的模型,但是使用更稀疏的网络结构依然还是很有效且很可行的。
对GoogLeNet的理解
对于文中反复提到的网络的稀疏性问题,稀疏连接有两种方法:一种是空间(spatial)维度的稀疏连接,也就是传统的CNN卷积结构:只对输入图像的某一部分进行卷积,而不是对整个图像进行卷积,共享参数降低了总参数的数目,减少了计算量;另一种是在特征(feature)维度进行稀疏连接,在多个不同的尺寸上进行卷积再聚合,把相关性强的特征聚集到一起,每一种尺寸的卷积只输出所有特征中的一部分,这也是种稀疏连接。
一个好的稀疏结构,应该是符合Hebbian原理的,我们应该把相关性高的一簇神经元节点连接在一起。在普通的数据集中,这可能需要对神经元节点聚类,但是在图片数据中,天然的就是临近区域的数据相关性高,因此相邻的像素点被卷积操作连接在一起。而我们可能有多个卷积核,在同一空间位置但在不同通道的卷积核的输出结果相关性极高。因此,一个1*1的卷积就可以很自然地把这些相关性很高的、在同一个空间位置但是不同通道的特征连接在一起,这就是为什么1*1卷积这么频繁地被应用到Inception Net中的原因。1*1卷积所连接的节点的相关性是最高的,而稍微大一点尺寸的卷积,比如3*3、5*5的卷积所连接的节点相关性也很高(从VGG论文网络C和网络D的结果中可以看出,将1*1卷积替换成3*3卷积能有更好的性能,但是1*1卷积的降维压缩效果应该是3*3卷积不能比的),因此也可以适当地使用一些大尺寸的卷积,增加多样性(diversity)。最后Inception Module通过4个分支中不同尺寸的1*1、3*3、5*5等小型卷积将相关性很高的节点连接在一起,就完成了其设计初衷,构建出了很高效的符合Hebbian原理的稀疏结构。
对GoogLeNet的评价
GoogLeNet最大的特点是控制了计算量和参数量的同时,获得了非常好的分类性能——top-5错误率6.67%,只有AlexNet的一半不到。Inception V1有22层深,比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率,可以说是非常优秀并且非常实用的模型。
Inception V1参数少但效果好的原因除了模型层数更深、表达能力更强外,还有两点:一是去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。全连接层几乎占据了AlexNet或VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合;二是Inception V1中精心设计的Inception Module提高了参数的利用效率,包括增加了分支网络,以及多个卷积核的使用。我自己认为Inception V1更快且更好的原因还有一点,就是文中反复提到的,采用了稀疏的网络结构。