HuggingFace 模型共有三个部分组成:Tokennizer、Model 和 Post Processing。
1 Tokenizer
把输入的文本做切分,然后变成向量。Tokenizer包含三个文件:参考Tokenizer的分词使用过程
- tokenization_chatglm.py:分词器的 .py 文件,用于模型分词器,加载和使用模型的必要部分(只是处理文本,不涉及任何向量操作)。
- tokenizer.model:包含了训练好的分词模型,用于将输入文本转换为标记序列;二进制使用 pickle 或者其他序列化工具进行存储和读取。
- tokenizer_config.json:分词模型的配置信息,用于指定分词模型的超参和其他的相关信息,例如分词器的类型、词汇表大小、最大序列长度、特殊标记等。
2 Model
根据输入的变量提取语义信息。对不同的NLP任务,需要选取不同的模型。
- Encoder 模型:如 Bert,常用于句子分类、命名实体识别(以及更普遍的单词分类)和抽取式问答;
- Decoder 模型:如GPT,GPT2,常用于文本生成;
- Sequence2Sequence 模型:如 BART,常用于摘要,翻译和生成式问答。
Model 模型导出时将生成 config.json 和 pytorch_model.bin 参数文件:参考config.json参数详解
- config.json:包括模型各种参数,如层数、隐藏层大小、注意力头数以及 Transformers API 的调用关系等,用于加载、配置和使用预训练模型。
- configuration_chatglm.py:针对 ChatGLM 模型配置的 .py 文件。
- modeling_baichuan.py:源码文件,定义了模型的结构和前向传播过程。
- pytorch_model.bin:pytorch 模型的权重文件,保存了模型权重的信息。
{
"_name_or_path": "THUDM/chatglm3-6b-128k", # 模型的名称或路径
"model_type": "chatglm", # 模型类型是 chatglm
"architectures": [
"ChatGLMModel" # 模型所使用的架构
],
"auto_map": { # 自动映射的模块,包括配置、模型和序列分类
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
},
"add_bias_linear": false, # 是否添加偏置线性层
"add_qkv_bias": true, # 是否添加查询-键-值的偏置
"apply_query_key_layer_scaling": true, # 是否应用查询-键层缩放
"apply_residual_connection_post_layernorm": false, # 是否应用残差连接后的层归一化
"attention_dropout": 0.0, # 注意力矩阵中的 dropout 概率
"attention_softmax_in_fp32": true, # 注意力 softmax 是否在 float32 上计算
"bias_dropout_fusion": true, # 是否将偏置 dropout 融合
"ffn_hidden_size": 13696, # FeedForward 网络隐藏层大小
"fp32_residual_connection": false, # 是否在 float32 上计算残差连接
"hidden_dropout": 0.0, # 隐藏层中的 dropout 概率
"hidden_size": 4096, # 隐藏层的大小
"kv_channels": 128, # 键值通道数
"layernorm_epsilon": 1e-05, # layer normalization 中 epsilon 的值
"rope_ratio": 500, # ROPE 比例
"multi_query_attention": true, # 每个隐藏层中的自注意头的数量
"multi_query_group_num": 2, # 多查询组数
"num_attention_heads": 32, # 注意力头数量
"num_layers": 28, # 模型的隐藏层数量
"original_rope": true, # 是否使用原始 ROPE
"padded_vocab_size": 65024, # 填充词汇表大小
"post_layer_norm": true, # 是否使用层归一化
"rmsnorm": true, # 是否使用 RMSNorm
"seq_length": 131072, # 序列长度
"use_cache": true, # 是否使用缓存
"torch_dtype": "float16", # Torch 数据类型
"transformers_version": "4.27.1", # Transformers 库的版本号
"tie_word_embeddings": false, # 是否将编码器和解码器的词嵌入层绑定
"eos_token_id": 2, # 终止标记的 id
"pad_token_id": 0 # 填充标记的 id
}预备知识:
- WarmUp Learning Rate(学习率预热阶段):在优化 Transformer 结构时,除了设置初始学习率和它的衰减策略,往往还需要在训练的初始阶段设置一个非常小(接近0)的学习率,让它经过一定的迭代轮数后逐渐增长到初始的学习率。
- Post-LN:是指 Transformer 架构中传统的 Add&Norm 代表的 Layer Normalization 的方式,即把 Layer Normalization 加在残差连接之后。性能良好请参考 Norm 为什么用 LayerNorm (LN) 不用 BatchNorm(BN)
- Pre-LN:是指把 Layer Normalization 加在残差连接之前。训练稳定
Post-LN 和 Pre-LN 示意图如下所示,参考原文:
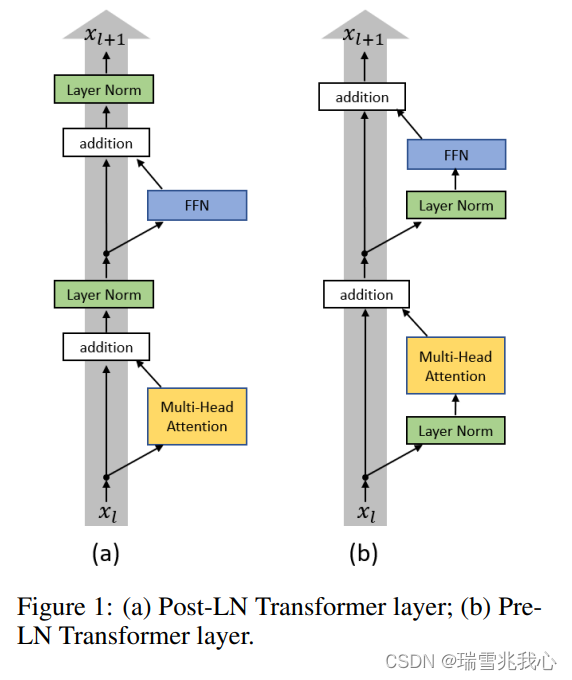
因此,可以得出的一个结论是如果层数少,Post-Norm 的效果其实要好一些,如果要把层数加大,为了保证模型的训练,Pre-Norm 显然更好一些。参考PostNorm/PreNorm的差别
Q1:当前主流大模型使用的 Normalization 主要有几种?
- Layer Normalization:是对特征张量按照某一维度或某几个维度进行 0 均值,1 方差的归一化操作。参考LayerNorm参数详解,计算过程
- RMS Normalization:均方根层归一化(Root Mean Square Layer Normalization)是对 Layer Normalization 的改进,去掉了减去均值的部分,性能基本一致,但运行时间减少了 7%-64%。参考文章。
- Deep Normalization:是对 Post-LN 和 Pre-LN 的综合改进,成功地将 Transformer 扩展到 1000 层(即 2500 个注意力和前馈网络子层)。参考文章。
3 Post Processing
根据模型输出的语义信息,执行具体的 NLP 任务,比如情感分析,文本自动打标签等。
后期处理 Post Processing 通常要根据你选择的模型来确定,一般模型的输出是 logits(可以看作神经网络输出的未经过归一化(softmax 或 sigmoid)的概率),其包含我们需要的语义信息,然后 Post Processing 是经过一个激活函数输出我们可以使用的向量,比如 softmax 层做二分类,会输出对应两个标签的概率值,最后转化为我们需要的信息。
- Logits 可以取任意实数值,正值表示趋向于分类到该类,负值表示趋向于不分类到该类。
- 与之对应的 Probability 是经过 Softmax 或 Sigmoid 归一化到 (0-1)之间,表示属于该类的概率。参考深度学习的logits是什么?