From Paper 《Is Long Context All You Need? Leveraging LLM’s Extended Context for NL2SQL》
实验、分析和基准论文
| Yeounoh Chung | Gaurav T. Kakkar | Yu Gan | Brenton Milne | Fatma Özcan |
| | | | | |
摘要
大型语言模型(LLMs)在一系列自然语言处理任务中展示了令人印象深刻的能力。特别是在推理能力和上下文窗口扩展方面的改进,为利用这些强大模型开辟了新的途径。NL2SQL具有挑战性,因为自然语言问题本身是模糊的,而生成SQL需要对复杂的数据模式和语义有精确的理解。解决这种语义模糊问题的一种方法是提供更多的上下文信息。
在这项工作中,我们探索了Google最先进的LLM(Gemini-1.5-Pro)提供的扩展上下文窗口(即长上下文)的性能和延迟权衡。我们研究了各种上下文信息的影响,包括列示例值、问题和SQL查询对、用户提供的提示、SQL文档和模式。据我们所知,这是首次研究扩展上下文窗口和额外上下文信息如何在准确性和延迟成本方面帮助NL2SQL生成的工作。我们表明,长上下文LLM是稳健的,并且不会在扩展的上下文信息中迷失方向。此外,基于Google的Gemini-1.5-Pro的长上下文NL2SQL管道在多个基准数据集上实现了强大的性能,无需微调或昂贵的自一致性技术。
1 引言
最近在LLM方面的进展特别集中在增强其检索和推理能力以及扩展其上下文窗口,从而拓宽了其潜在应用的范围。处理并在上下文窗口内保留更长的信息序列的能力使LLM能够捕捉输入数据中的细微依赖关系和复杂关系,为改进语言理解和生成提供了前所未有的可能性。一个可以从这些进步中显著受益的领域是自然语言到SQL(NL2SQL)。NL2SQL是一项具有挑战性的任务,它涉及将自然语言问题翻译成可以在数据库上执行的结构化SQL查询。自然语言问题的固有模糊性,加上对复杂数据库模式和语义的深刻理解的必要性,使得NL2SQL成为一个非常具有挑战性的问题 [9]。最近的工作 [5, 11, 27, 29] 创建了涉及模式链接、自一致性和自我纠正的NL2SQL管道,使用多次LLM调用。这些解决方案精心创建包含各种上下文信息的提示,并使用思维链(CoT)[26, 44] 推理和/或上下文学习。
在本文中,我们探讨了利用Google的长上下文LLM(Gemini-1.5)提供的扩展上下文窗口来提高NL2SQL性能的潜力。假设是,具有增强检索和推理能力的长上下文LLM可以通过额外和适当的上下文信息来解决语义模糊的挑战。为了研究这一假设,我们对这些技术与长上下文模型结合使用时的影响进行了详细研究。
表1:不同已发布的NL2SQL方法在BIRD开发集上的性能比较。这不包括排行榜上未公开的方法。
| 方法 | 准确率 (%) | 微调 | 自一致性 |
| CHASE-SQLa[29] | 74.46 | ✓ | ✓ |
| XiYan-SQL | 73.34 | ✓ | ✓ |
| 长上下文(我们的) | 67.41 | ✗ | ✗ |
| Distilleryc[27] | 67.21 | ✓ | ✓ |
| E-SQL[5] | 65.58 | ✗ | ✗ |
| CHESS[34] | 65.00 | ✓ | ✓ |
| MCS-SQL[17] | 63.36 | ✗ | ✓ |
| SuperSQL[20] | 58.5 | ✗ | ✓ |
a 截至2024年12月17日,在排行榜上排名第二。长上下文NL2SQL管道被用作其调优自一致性(多选并选择)的三个候选生成器之一。
c截至2024年12月17日,在排行榜上排名第六。
表1比较了使用BIRD基准测试[22]发布的NL2SQL方法的执行结果准确性(Ex Acc),这是最流行的NL2SQL测试基准。我们的长上下文管道在没有任何微调和不生成多个答案候选(自一致性)的情况下,取得了非常有竞争力的结果。研究表明,尤其是较小容量的模型,从微调中受益匪浅,因为微调有助于模型专注于特定数据域中的相关模式和SQL生成[7, 25]。虽然微调一直是主导方法,但使用最新LLM的上下文学习(ICL)作为一种更可取的替代方案正在获得关注,其性能与微调模型相匹配[28, 30]。ICL不需要重新训练或更新模型参数,并且避免了对特定数据域的过拟合。这对于服务于许多专业领域的生产型NL2SQL系统尤其具有吸引力。
自一致性是目前最先进的NL2SQL系统中使用的另一种流行技术[8, 10, 11, 29, 34, 37]。其思想是生成多个输出候选,并根据某些规则(例如多数投票)或微调的选择模型来选择最可能的一个。由于LLM的随机性,不同的模型(甚至是同一模型)对于相同的输入会生成不同的输出,因此这种方法效果很好。自一致性与我们的工作正交,可以将两者结合以提高准确性(详见第6.2节)。在这项工作中,我们专注于识别并提供额外的上下文信息,利用长上下文LLM的扩展上下文窗口进行ICL。
E-SQL是另一种不采用微调或自一致性的方法。相反,E-SQL专注于改进用户问题与相关模式元素之间的映射(即模式链接)。它通过显式地修改/丰富原始问题,添加相关的模式元素(表名和列名、值)和条件,从而使模型在生成过程中避免隐式的从问题到相关模式元素的映射。我们的假设是,通过传递额外的上下文信息,可以减少对传统检索步骤的依赖,并通过调用LLM代理来生成、修复和重写以及验证SQL查询,从而提高整个流程的准确性。
长上下文的优势
长上下文LLM能够处理数百万个令牌的输入,这为NL2SQL任务提供了前所未有的机会。通过包含更多的上下文信息,如完整的数据库模式、相关示例和用户提示,我们可以显著提升模型的性能。具体来说,我们探索了以下几种上下文信息:
- SQLite文档:提供详细的数据库文档,帮助模型更好地理解表结构和列信息。
- 用户提示:允许用户在问题中添加额外的信息或澄清,以提高模型的理解能力。
- 额外的列样本值:提供列的具体示例值,帮助模型更准确地映射自然语言到SQL。
- 多示例上下文学习(ICL):使用多个相关示例来指导模型生成SQL查询,而不仅仅是少数几个示例。
实验结果与分析
我们在已建立的NL2SQL基准测试(如BIRD和SPIDER数据集)上进行了广泛的实证评估,以研究长上下文对NL2SQL性能的影响。实验结果表明,长上下文确实可以作为增强典型基于LLM的NL2SQL管道的强大工具,无需微调。通过使用Google的gemini-pro-1.5及其长上下文功能,我们的NL2SQL管道在BIRD-Bench开发数据集上实现了67.41%的准确性,展示了这种方法的潜力。
通过详细的分析,我们得出了以下几点关键观察:
- 表和列的召回率:在上下文中拥有正确的表和列(即100%的召回率)是高质量SQL生成所必需的。长上下文模型不会因额外的表信息而分心,即使在上下文中包含大量无关表时(低精度)。
- 相关示例的选择:仅仅添加许多相关示例(通过问题相似性)并不一定显著提高NL2SQL的准确性。相反,使用与开发数据集中的SQL结构相似的例子(但不查看这些数据集)以及来自同一目标数据库的相关模式元素可以提高准确性。基于这一观察,我们为NL2SQL生成了许多合成示例,用于多示例的上下文学习。
- 提示的重要性:在我们的消融研究中,提示对NL2SQL准确性的提升最大,其次是列样本值和自校正。虽然高质量的上下文示例可以提高准确性,但它们并不能解决NL2SQL生成中的所有问题。
- 不同类型的查询:不同类型的查询受益于不同的上下文信息。对于简单的问题,使用合成示例的多示例上下文学习有效,但对于具有挑战性的BIRD开发集问题则无效。在像BEAVER dw(企业数据仓库)这样涉及更多连接和复杂SQL的复杂数据集上,合成示例实际上会平均降低性能。
- SQL文档的影响:在长上下文中提供SQL文档并不会显著提高准确性,因为模型在训练过程中已经见过这些文档。
- 延迟与准确性之间的权衡:延迟随着上下文大小的增加而近乎线性增长,因此在延迟和更好的准确性之间存在明显的权衡。
结论与未来工作
在本文的其余部分,我们在第2节中全面概述了相关工作,随后在第3节中详细描述了我们的基于长上下文的NL2SQL方法。在第4节中,我们提供了各种技术及其对NL2SQL准确性影响的详细分析,以及消融研究。最后,我们总结了我们的发现的意义,并讨论了未来研究的方向。
2 相关工作
早期的NL2SQL方法主要集中在基于规则和语义解析的方法上。随着深度学习的发展,基于神经网络的模型在NL2SQL研究中占据了主导地位。这些模型通过大量的问题-查询对数据集学习将自然语言问题映射到SQL查询。最近,具有类似人类理解能力和文本生成能力的大规模语言模型在NL2SQL和其他类似任务中显著提高了准确性和效率。
大规模语言模型还可以从推理时提供的少数示例中学习(少样本上下文学习)。在NL2SQL领域,先前的研究集中在利用这种少样本上下文学习方法来指导SQL生成。NL2SQL的少样本示例由问题和SQL配对组成,通常通过问题嵌入相似度筛选以适应有限的上下文大小。在其他问题领域,由于新扩展的上下文窗口,多示例上下文学习被证明始终优于少样本方法。
一个新的长上下文基准测试表明,最新的长上下文大规模语言模型可以匹配最先进的检索系统的能力,但在组合推理任务(如针对专门微调模型的NL2SQL)上表现不佳。该基准测试涵盖了NL2SQL,并使用了未经调优的gemini-1.5-pro长上下文大规模语言模型。他们通过包含所有数据库表和固定的少样本示例来利用长上下文。尽管他们的NL2SQL管道在SPIDER 1.0基准测试中不如原始的微调模型,但我们的长上下文策略通过更好地利用适当的上下文信息超过了两者。其他非NL2SQL领域的研究也探讨了长上下文的上下文学习。这些研究表明,许多商用长上下文大规模语言模型在处理长上下文中的所有信息时存在困难,其中存在对某些位置(例如窗口末尾)的偏见。我们的经验表明,gemini-1.5-pro没有表现出这种强烈的偏见,并且在更大的上下文窗口中表现更好。截至本文撰写时,Google Cloud gemini-1.5-pro通过Vertex AI API支持最多2百万个令牌的上下文,而OpenAI GPT-4o通过API支持8k至128k个令牌。
模式链接对于准确的NL2SQL生成至关重要,因为它将模糊的用户问题映射到相关的模式元素。模式链接通常依赖于相关表和列的仔细选择[5, 34],而最近的一项研究[27]表明,最新的大规模语言模型可以在推理时从未过滤的数据库模式(即传递所有数据库表而不进行选择)中检索相关的模式元素。我们也在长上下文中包含了整个数据库模式,并观察到了类似的趋势。
可以通过多次调用大规模语言模型来细化输出,验证、修复和重写SQL输出。通常还会采样多个答案候选并选择(自一致性)最可能或最一致的输出以提高质量[8, 10, 11, 29, 34, 37]。在本工作中,我们专注于利用长上下文ICL进行典型的NL2SQL流程——这与自一致性方法是正交的,可以一起使用。[29]使用我们的长上下文流程生成候选结果,并结合一个微调的选择器。
我们没有使用更复杂的提示策略,如思维链(CoT)[26, 33, 38, 44],因为它的贡献微乎其微(详见第5节的讨论)。研究表明,CoT提示可以提高大规模语言模型在算术和常识推理任务中的性能。它通常涉及提供一些中间推理步骤的示例,以指导模型生成自己的推理链。
3 利用长上下文进行NL2SQL
图1:长上下文NL2SQL流程。利用长上下文的大规模语言模型可以使检索步骤变得不那么关键,并且通过额外的上下文信息使代理工作流(生成→修复和重写→验证)更加准确。
在本工作中,我们专注于可以传递到扩展上下文窗口的额外上下文信息。我们假设,利用扩展的上下文窗口和长上下文大规模语言模型的强大检索能力可以使NL2SQL流程中的检索步骤变得不那么关键;我们还可以通过调用大规模语言模型代理来生成、修复和重写以及验证,从而使其更加准确。我们探索了各种上下文信息,如SQLite文档、用于澄清的用户提示、额外的列样本值和多示例上下文学习(ICL)的例子。
图2:Top K相关表检索模拟。
通过上述方法和技术,我们不仅提高了NL2SQL的准确性,还为未来的研究提供了新的方向和见解。根据问题嵌入相似度从BIRD开发集中选择Top-K相关表,无需特定的目标数据库,正如某些生产RDBMS所支持的那样。
本节分为三个子部分:生成→修复和重写→验证,对应于生成和优化输出SQL的三个代理工作流调用,如图1所示。每个子部分详细介绍了相应的代理调用所需的适当上下文信息和技术。
3.1 生成
我们关注的是信息的价值,而不是将其挤进有限的上下文窗口中,因此我们可以提供更多上下文信息来解决模式链接和由于模糊的用户问题及复杂数据模式引起的语义错误。我们探索了以下内容以辅助SQL生成。
所有数据库表以实现高召回率的模式链接
在典型的NL2SQL流程中,相关模式元素(表列名和值)是基于问题嵌入相似性检索的。准确的模式链接对于准确的SQL生成至关重要[9]。先前的研究工作集中在通过更准确的表和列选择来提高模式链接的准确性[5, 34]。尽管准确的模式检索可以提升NL2SQL的性能,但仍有很大的改进空间(详见附录A.2的更多讨论)。实际上,表模式检索可能会遗漏表和列——这会阻止大规模语言模型生成正确的SQL查询。
图2展示了模仿生产环境中表检索设置的表模式检索模拟结果。请注意,召回率并未达到100%,并且随着K的增加稳定在约82%。在某些生产环境中,用户可能会询问任何数据库而不指定他们指的是哪个数据库,从而使表检索变得更加困难(有关模拟设置的更多细节,请参见附录A.1)。在这种模拟设置中,当K≥13时,检索服务未能实现完美召回,这是BIRD开发集中每个数据库的最大表数。这是因为表是从所有数据库(100个表)中检索的,而没有指定目标数据库。在第4.3节中,我们将探讨包含每个数据库及其跨数据库的所有表以确保完美召回的影响,尽管代价是降低了精度。在这里,我们通过包含所有数据库表来改进模式链接,以确保提供所有相关元素以及大量无关的元素。这引发了模型可能在大上下文窗口中感到困惑或“迷失”的担忧[9, 24]。然而,我们观察到最新的长上下文大规模语言模型gemini-1.5并没有表现出这个问题,并且展示了“近乎完美”的检索能力[31]。在第4.3节中,我们将我们的长上下文模式链接方法与使用Top-K相关表的基线进行比较,并在第5节中研究增加上下文大小和延迟的影响。
列描述和样本值以改进列选择
先前的研究[36]表明,作为提示的一部分的列描述符和值可以提高模式链接和列选择的准确性。[27]在输入提示中使用了列描述符、数据类型和一些样本列值。这些额外信息被证明有助于大规模语言模型推理列引用。在这项工作中,对于任何非平凡的“文本”列,我们提供的不仅仅是几个样本列值。在第4.6节中,我们展示了这种暴力方法如何充分利用模型的“近乎完美”的检索能力[31]来解决模糊的列引用和字面错误。
用户提供的提示以进一步澄清
扩展的上下文窗口允许除了数据库模式和其他列元数据之外,还包括用户的附加指令和澄清。例如:
问题:洛杉矶县有多少所非特许学校,其1至12年级符合条件的免费餐比例(%)低于0.18%?
证据:非特许学校指的是Charter = 0的学校;K-12表示1至12年级;K-12符合条件的免费餐比例 = ‘Free Meal Count (K-12)’ * 100 / ‘Enrollment (K-12)’
SQL:
SELECT COUNT(T2.School)
FROM frpm AS T1
INNER JOIN schools AS T2 ON T1.CDSCode = T2.CDSCode
WHERE T2.County = 'Los Angeles' AND T2.Charter = 0
AND CAST(T1.'Free Meal Count (K-12)' AS REAL) * 100 / T1.'Enrollment (K-12)' < 0.18
图3展示了一个带有提示的问题示例,该提示规定了复杂的列引用和回答BIRD开发集中的一个挑战性问题所需的数学表达式。BIRD基准测试包括用于准确生成SQL的提示,明确指出需要哪些列和/或如何计算值。并非所有BIRD开发集问题都有提示。在实际的NL2SQL服务中,提示可能通过与用户的多轮交互获得。如果可用,我们会将提示作为用户问题的一部分提供。在第5节中,我们讨论了提示的影响。
多示例ICL的合成示例
虽然先前关于NL2SQL的ICL工作集中在选择少量示例(3-5个)进行ICL[28, 30],但我们为多示例ICL生成了许多示例。多示例ICL已被证明可以在许多不同领域提高大规模语言模型的生成质量[2]。在这里,我们利用扩展的上下文窗口生成并使用数十甚至数百个示例。示例也是在推理时生成的,如[29]所述。在线生成允许绕过示例检索过程,并使用与用户问题更相关的模式元素生成示例(我们传递给定数据库的整个模式以及基于大规模语言模型的相关列选择结果)。模型生成的合成示例包括输出SQL和输入自然语言问题。生成的SQL查询遵循目标基准数据集的常见SQL特性。结构上的相似性可以帮助指导模型生成具有类似SQL结构和特性的查询。
在第4.5节中,我们展示了基于多示例ICL的合成示例如何提高性能,并在第5节中讨论了示例生成的性能和成本权衡。
相关的SQLite文档部分
扩展的大上下文窗口允许传递大块、章节和/或部分的SQLite文档。文档编写通常较长,并包含一些说明性示例。我们在第4.7节中探讨了文档对性能和成本的影响及其可行性。
3.2 修复与重写
我们允许模型根据执行情况修复其错误并重写SQL输出。如果生成的SQL查询在执行时返回错误,它会触发校正模块[5, 35],并在固定次数内重试,直到返回有效的SQL。[30]表明大规模语言模型可以纠正SQL中的小语法错误。虽然现有的自我修正机制和最新的大语言模型本身在修复SQL语法错误方面是有效的,但它们并不能解决更细微的语义错误,如无效的字面引用和错误的连接路径。在语法错误修正后,语义错误可能仍然存在(例如,为错误的列引用了一个有效的字面值),并且在没有真实查询结果的情况下很难检测到这些错误。如果查询返回空结果,我们会检查潜在的语义错误;我们通过提供更广泛的样本列值列表来要求模型重写这样的查询。依赖于空结果来检测语义错误有可能产生假阳性。如果正确的真实结果是空的,这可能会由于不必要的重试而增加额外的计算成本。如果问题不模糊,即使包含更多的样本列值,模型也应该返回相同的正确空结果。然而,如果问题是模糊的,并且模型重新生成了非空结果,那么我们更倾向于选择非空结果并进入下一个验证步骤。查看完整的列值列表使模型能够选择正确的关键字和列,并推理出更准确的替代连接路径。传递完整的样本列值列表会显著增加上下文大小,并需要能够在这种长上下文中准确检索的大规模语言模型。我们在第4.6节中评估了这种长上下文消歧策略的影响。这项技术成本高昂,但它可以补充不完美的表和列选择以及模式链接,这些通常会导致次优的自然语言到SQL性能。
3.3 验证
我们使用未经调优的gemini-1.5-pro大规模语言模型来验证最终输出的正确性。我们认为,对验证器或选择器进行微调以实现自一致性[29, 37, 42]可以进一步提高准确性。尽管我们的重点是利用长上下文ICL简化自然语言到SQL流水线(自我修正且无需微调的验证),上述技术是正交的,可以结合使用。我们在第5节中展示了这个验证步骤如何影响最终性能和生成成本。
4 长上下文自然语言到SQL技术的详细分析
4.1 评估设置
我们在所有实验中使用公开的Google Cloud (GCP) Vertex AI gemini API,这有助于确保实验和分析的可重复性。我们采用最新公开可用的gemini-1.5-pro-002和gemini-1.5-flash-002检查点。gemini-1.5属于长上下文的大规模语言模型类别,其中pro版本支持最多2百万个令牌的上下文,flash版本支持最多1百万个令牌的上下文。我们的测试虚拟机和Vertex AI端点位于同一个GCP区域(us-central1-b)。
在第4.2节中,我们将报告各种自然语言到SQL基准数据集(BIRD [22],SPIDER 1.0 [40],KaggleDBQA [16] 和 BEAVER [6])上的完整流水线性能。我们使用两个广泛使用的基准数据集BIRD开发集和KaggleDBQA测试集运行我们的微基准实验。BIRD目前是最流行的自然语言到SQL基准,有一个排行榜,所有最近的自然语言到SQL研究出版物都使用该数据集来比较其性能,它包含了涉及多个表格和不同模式复杂度的各种难度的问题。KaggleDBQA是另一个针对文本到SQL任务的基准数据集,专注于现实世界中的跨领域数据源。
对于性能和成本指标,我们使用常用的执行准确性(Ex Acc)和每次请求的累积令牌数(T单位/请求),以及每次请求的归一化延迟(单位延迟)作为绝对延迟度量,因为公共API端点背后的绝对延迟会随时间变化——一个8k令牌的单个gemini-1.5-pro请求延迟用作参考单位(=1.0)。我们报告小数点后一位的浮点值,忽略低于10%的差异。同样,我们避免直接报告货币成本,因为它取决于定价模型[12],而定价模型可能会发生变化。相反,我们报告每次请求的累积令牌数,这与总货币成本高度相关,并且不受定价模型变化的影响。
正如在第4.8节中讨论的那样,累积令牌数和归一化延迟之间存在强烈的正相关关系,我们在消融研究中报告了这两个指标。我们报告低方差(误差范围/变异性小于2%)的请求平均指标;如果观察到的方差较大,我们报告均值加一个标准差(例如,¯ +)以涵盖大多数请求。我们的“完整”流水线在各个实验中采用了第3节和第5节讨论的所有上下文信息和技术;对于特定问题的研究,我们使用“基线”流水线。基线流水线包括整个数据库模式、样本列值、指令和提示,但不包括自我修正、消歧、合成示例和验证。
4.2 基准评估
表2:使用完整的长上下文NL2SQL流水线和gemini-1.5模型的基准性能和生成延迟。测量每次请求的SQL输出生成时间,包括自我修正和重试所花费的时间。
| gemini-1.5-pro | gemini-1.5-flash | ||||
| Ex Acc (%) | 𝑇¯𝑔 (T单位/请求) | Ex Acc (%) | 𝑇¯𝑔 (T单位/请求) | ||
| BIRD dev | 67.41 | 12.3 | 66.49 | 8.6 | |
| SPIDER 1.0 test | 87.10 | 1.5 | 84.60 | 1.1 | |
| KaggleDBQA test | 61.10 | 2.7 | 58.40 | 1.8 | |
| BEAVER dwa | 60.41 | 506.1 | 50.00 | 506.1 |
a截至2025年1月7日,只有数据仓库1(dw)数据集公开可用,包含48个问题。
表2显示了各种基准数据集上的完整流水线评估结果。流行的基准数据集(BIRD开发集、SPIDER 1.0测试集、KaggleDBQA测试集)提供了跨多个领域的不同难度的问题集,使我们能够将我们的性能与其他最先进的方法进行比较。利用gemini-1.5模型扩展上下文的方法可以在所有基准上产生具有竞争力的结果,而无需使用微调和自一致性等技术(表1)。新的企业仓库数据基准(BEAVER dw)特别值得注意,因为其面向业务的问题和真实的企业表格显著更复杂且更大。在三个广泛使用的基准中,BIRD是最复杂的,每个数据库平均有0.918个JOIN,涉及6.82张表。相比之下,BEAVER的问题涉及每个数据库105.0张表中的4.25个JOIN,使其更具挑战性。BEAVER作为基准仍处于早期阶段。我们使用的dw数据集存在一些问题,例如主键上的UNIQUE约束违反,对此我们忽略了并允许重复。我们的长上下文流水线在不使用黄金表的情况下,仅使用整个数据库表和列映射(类似于BIRD基准中的提示),实现了60.41%的执行准确性(忽略空黄金查询的问题为48.64%)。[6]报告的BEAVER(dw + 45个额外问题)的最佳单次执行准确性是使用gpt-4o和相关表模式检索在PL/SQL中达到2.0,而在没有检索的情况下为0.0。
归一化生成延迟随着上下文大小和任务难度(问题和模式复杂性)的增加而增加,因为它包括自我修正和重试(使用指数退避,每个请求最多5次重试)。例如,BEAVER的平均生成时间显著更长,因为我们的长上下文流水线生成的上下文大小超过了限制(pro版本为2百万个令牌,flash版本为1百万个令牌),或者生成语义无效(空)的输出,在这种情况下,模型会重试固定次数直到找到更好的答案。
表3展示了基线流水线在表检索(TBR)性能和执行准确性方面的表现。放置所有表(无论是数据库中的所有表还是数据集中的所有表)可以确保完美的召回率。
| (a) BIRD dev | |||||||
| # tables (k) | k=1 | k=7 | all tables / DB | all tables / dataset | |||
| Ex Acc (%) | 38.01 | 54.69 | 62.32 | 62.58 | |||
| TBR Recall (%) | 45 | 82 | 100 | 100 | |||
| TBR Precision (%) | 77 | 23 | Low (< 35%) | Low (< 2%) | |||
| 𝐿¯ (tok/req) | 2002.54 | 4627.68 | 7380.86 | 72619.96 | |||
| (b) KaggleDBQA test | |||||||
| # tables (k)k=1k=2all tables / DBall tables / dataset | |||||||
| Ex Acc (%) | 43.24 | 50.27 | 56.75 | 60.54 | |||
| TBR Recall (%) | 81.53 | 91.26 | 100 | 100 | |||
| TBR Precision (%) | 90.27 | 53.51 | 68.86 | 7.44 | |||
| 𝐿¯ (tok/req) | 922.29 | 1731.64 | 1485.45 | 26087.86 |
总体而言,gemini-1.5-pro在复杂的推理任务(如NL2SQL)上表现更为出色,而gemini-1.5-flash则更具成本效益(每令牌价格更低)。我们注意到,最新发布的gemini模型(于2024年9月24日公开发布)显示出显著的性能改进,尤其是flash版本现在在某些基准测试中与pro版本的表现更为接近。这使得更具成本效益的flash版本成为生产环境中NL2SQL应用的非常有吸引力的选择。
4.3 使用整个数据库表进行模式链接
我们探讨了传递从整个数据库收集的完整表模式集的影响。模式链接是一个至关重要的组件,我们在生产环境中力求实现高召回率。借助长上下文模型,我们可以包含大量表定义和模式,而不是仅限于最相关的前K个表。借助长上下文模型,我们可以包含大量表定义和模式,而不是仅限于最相关的前K个表。
按照标准做法,我们根据自然语言问题和表DDL语句之间的嵌入相似性来检索最相关的表。跨所有表和数据库进行前K个表的检索,类似于图2所示的生产设置。或者,我们提供来自给定目标数据库的所有表(基准数据集指定了问题所涉及的数据库)或来自数据集中所有表(跨所有数据库),而不进行前K个表的检索。目的是通过提供更多表(如果不是全部的话)来确保近乎完美的(更高的)召回率,尽管精度较低。
表3中的结果显示,尽管上下文中存在大量无关的表定义,模型并不会感到困惑。因此,如果上下文大小允许,提供更多的表而不是仅仅依赖不完善的表检索机制是有益的。结果(对于k=1)也再次证实了模式链接的重要性,因为在提示中没有所有真实表的情况下(k=1),模型无法生成高质量的SQL输出。相反,提供来自目标数据库的所有表可以确保完美的TBR召回率,并在BIRD开发集和KaggleDBQA测试集中获得更高的执行准确性。这意味着TBR召回率比精度或准确性更重要,因为模型生成质量在存在许多无关表时不会显著下降(BIRD开发集平均68.18个无关表,KaggleDBQA为14.875个)。所有表/数据库设置每次请求最多使用13个表(KaggleDBQA为5个表),具体取决于BIRD开发集中的目标数据库;不同数据库的平均表数为6.82(KaggleDBQA为2.125)。值得注意的是,所有表/数据集的执行准确性略高于所有表/数据库。这种差异在KaggleDBQA测试集中更为明显(几乎+3.8%的执行准确性),而在BIRD开发集中则在5%的误差范围内(我们使用中等温度进行LLM生成,每次运行的执行准确性略有变化)。
这表明模型的输出质量至少是可比较的,包含额外的无关模式信息不会降低生成质量。一方面,包括尽可能多的表(例如用户历史记录、目标数据库中的所有其他表)可以确保高TBR召回率,这是长上下文LLM可以容纳的。另一方面,随着上下文大小的增加,延迟成本也会增加(见图5),超过某个点后,添加更多无关表不会带来额外的好处以证明增加的成本是合理的。此外,某些生产环境需要处理数百个非常宽的表,这使得将所有表包含在上下文中变得极其昂贵(有关更多讨论,请参见第6.3节)。因此,准确的检索和过滤仍然是可取的,利用长上下文模型可以作为一种补偿机制,以弥补不完美的检索从而提高召回率。
4.4 使用示例选择的多示例ICL
在这里,我们评估了使用从BIRD训练数据集中选择的示例进行多示例上下文学习(ICL)的影响。这些示例是根据问题嵌入相似性检索的。
表4(a)显示,训练示例并没有提供太多提升,反而导致了更差的表现。这意味着模型从BIRD训练集中的类似示例中学习的能力相当有限,甚至可能会被它们分散注意力。同时注意到,分心的影响似乎是有限的,例如从1个类似的示例(11k令牌)增加到100个类似的示例(50k令牌)。为了进一步检查模型对许多无关训练示例的敏感性,我们在示例块的“中间”注入了一个来自BIRD开发集的真实示例(平均上下文大小省略,因为它应该与前一个表几乎相同)。虽然模型可以在许多其他无关示例中选择真实示例,但那些无关训练示例的存在仍然会混淆模型,而不是仅仅拥有那个真实示例。召回率比精度更重要,但模型对坏示例(低精度)的敏感度仍然有限——注意,有100个随机示例和1个真实示例的准确性远高于完全没有示例的情况。
还需要注意的是,模型对真实示例的位置和顺序具有鲁棒性。[24]表明,LLM倾向于强调上下文窗口开始和结束处的信息,突出了适当排序和排序对于检索增强生成(RAG)的重要性。如表4(b-c)所示,其中在上下文窗口的不同位置注入了GT,我们观察到,对于gemini-pro-1.5,示例的顺序(以及由示例重新定位而重新定位的模式信息)影响很小,长上下文LLM可以从其上下文窗口内的任何位置检索相关的真实示例。
表4:基线管道及从训练数据集中选择的相似示例(train)和真实示例(+ GT)的执行准确性(%)
- 变化数量的相似训练示例和插入中间的GT
| 训练示例数量 | 0 | 5 | 20 | 50 | 100 | |
| BIRD 开发集 | 𝜎(train) | 61.60 | 63.17 | 62.71 | 62.58 | 62.52 |
| 𝜎(train) + GT | 78.68 | 77.18 | 77.84 | 77.51 | 78.81 | |
| 𝐿¯ (tok/req) | 7380.86 | 8000.67 | 9927.24 | 13808.71 | 20358.30 | |
| KaggleDBQA 测试集 | 𝜎(train) | 57.83 | 65.40 | 79.45 | 64.32 | 65.94 |
| 𝜎(train) + GT | 80.50 | 81.62 | 78.91 | 81.08 | 80.50 | |
| 𝐿¯ (tok/req) | 922.29 | 1753.64 | 2550.10 | 4191.18 | 6266.45 |
- 在上下文窗口内不同位置(归一化)插入GT,带有选择的100个(train)+ GT
| GT 位置 | 0.1 | 0.25 | 0.50 | 0.75 | 0.9 |
| BIRD 开发集 | 77.77 | 78.29 | 78.1 | 78.42 | 78.16 |
| KaggleDBQA 测试集 | 81.62 | 81.62 | 80.00 | 80.00 | 80.08 |
- 改变上下文中的示例块(100个(train)+ GT)的顺序:开头(指令之前),中间(模式细节之前),结尾(模式细节之后)
| 块位置 | 开头 | 中间 | 结尾 |
| BIRD 开发集 | 80.44 | 78.23 | 78.29 |
| KaggleDBQA 测试集 | 78.91 | 79.45 | 80.— |
| BIRD 开发集 | 80.44 | 78.23 | 78.29 |
| KaggleDBQA 测试集 | 78.91 | 79.45 | 80.00 |
模型从随机示例中学习和泛化的能力是有限的:单个相关示例远胜于许多随机示例。虽然在上下文中捕获相关示例至关重要(相关示例可以提高生成质量),但基于用户问题捕捉相关示例也非常具有挑战性。在下一节中,我们将分享我们为每个问题生成多个合成示例的经验,以跳过示例选择步骤。
4.5 合成示例生成与示例选择
图4说明了合成示例如何提高生成SQL查询的质量,并与其他从不同示例池中检索到的示例类型进行了比较。按照惯例,示例检索是通过使用gecko1嵌入模型的问题嵌入相似性完成的。请注意,使用来自开发数据集的真实SQL查询提供了性能上限((dev)和(train + GT)),但在没有先验知识的情况下是不允许的(即,使用评估数据集中的真实查询)。虽然开发集排除了给定问题的具体真实查询,但它仍然可以直接从开发数据集中的真实数据库中检索到类似的示例。(dev)和(train + GT)之间的差距表明,将真实示例作为众多示例之一提供比检索与真实示例相似的开发集示例更好。(train)是一种常见做法,从可用数据集中选择相关示例,例如训练数据集(train)。在BIRD开发集(a)的情况下,提供相关的训练示例至少与基线(无示例)一样好,并且当提供的示例少于200个时略有改进。然而,合成示例((synthetic)和在线合成)相比(train)提供了显著提升。(synthetic)和原始合成之间的差距表明,通过过滤相关合成示例可以更经济地利用上下文大小(用较少的示例实现更高的性能)。对于KaggleDBQA测试集(b),训练和合成示例都提高了Ex Acc,而训练示例的表现远优于合成示例。这是因为BIRD训练集和开发集是从不同的数据库领域采样的,而KaggleDBQA训练集和测试集是从相同领域采样的。需要注意的是,使用合成示例的多示例ICL可以帮助进一步提高Ex Acc,尤其是在跨领域情况下(例如BIRD开发集),其中可用的训练示例相关性较低。

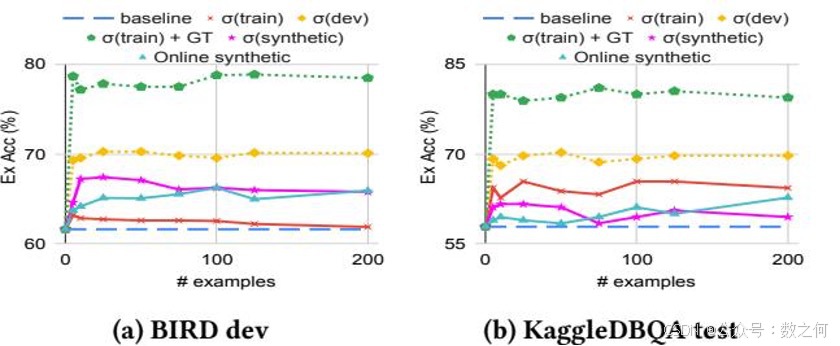
图4:基于问题相似性的示例选择()与在线示例生成。基线不使用任何示例;示例是从BIRD训练数据集、开发数据集(不包括真实示例)和合成生成的示例中检索的。train + GT使用检索到的训练示例和来自开发集的真实SQL。
4.6 使用完整模式和更多列值进行自我修正
表5显示了LLM的自我修正如何帮助SQL生成及其优化。我们将基于LLM的自我修正(SC)与两种更高级的技术进行了比较:消歧和过滤模式。消歧是一种长上下文支持的技术,在检测到语法正确的SQL返回空结果时向模型展示扩展的样本列值列表;过滤模式则根据列选择结果为每个用户问题过滤相关的模式元素,遵循[34]的方法。消歧和过滤模式都可以帮助LLM纠正任何无效的文字和列引用。消歧的一个潜在问题是额外的列值可能会分散模型的注意力,特别是在误报检测的情况下(例如,正确答案为空)。然而,实证结果显示它通常会提高性能,表现略好或至少与SC相当。尽管性能相当,但这些技术在成本方面有所不同。用于修正的累积平均提示令牌数量显著增加。
表5:Ex Acc (%)和用于修正的额外累积令牌。评估基线管道不包括自我修正(SC);消歧是指如第3.2节所述提供广泛的样本列值;过滤模式是指提供过滤后的相关列和值以重写。
| 修正后的SQL | 用于修正的令牌 | |||||
| Ex Acc (%) | 𝐿¯ (tok/req) | 𝐿¯ + 𝜎 (tok/req) | ||||
| BIRD 开发集 | ||||||
| 基线(无SC) | 61.6 | - | - | |||
| SC | 64.80 | 3632.77 | 6631.60 | |||
| SC + 消歧 | 65.51 | 15754.64 | 334999.28 | |||
| SC + 过滤模式 | 65.84 | 3930.55a | 7001.89 | |||
| KaggleDBQA 测试集 | ||||||
| 基线(无SC) | 58.91 | - | - | |||
| SC | 59.45 | 2211.34 | 34573.67 | |||
| SC + 消歧 | 61.08 | 111238.44 | 205852.86 | |||
| SC + 过滤模式 | 59.45 | 2335.9a | 35475.69 |
a 这不包括运行基于LLM的列选择的成本,其中需要多次LLM调用来提取给定请求的相关列。
准确的列选择对于提高NL2SQL性能至关重要,而过滤模式在修正过程中不会增加上下文大小。然而,准备过滤模式需要一个额外的检索步骤,这会产生成本(有关更多讨论,请参见附录A.2)。
准确的列选择对于提高NL2SQL性能至关重要,而过滤模式在修正过程中不会增加上下文大小。然而,准备过滤模式需要一个额外的检索步骤,这会产生成本(有关更多讨论,请参见附录A.2)。如果能够实现精确的列选择过程,过滤模式将是一个有效的策略。但在我们的最终长上下文管道中,我们采用了SC + 消歧的方法来避免额外的检索/选择步骤,并确保所有操作都在上下文中完成。由于令牌使用量存在较大差异,我们报告了每次请求的平均令牌数加上一个标准差(1-S.D.),以覆盖大多数请求使用的范围(68%)。
4.7 使用SQLite文档进行上下文学习
我们测试了模型是否能够有效地从SQLite文档中学习并提升其SQL生成质量。我们从其官方网站下载了完整的SQLite文档[1]。原始文档包含792个HTML文件,共计1600万个令牌,每个文件涵盖不同的主题。我们应用了两种策略将整个文档拆分为块,以便可以用相关的信息增强提示以进行ICL。粗粒度拆分策略按HTML文件拆分文档,而细粒度拆分策略进一步将每个文件按部分拆分,最终得到总共4125个小块。类似于示例检索,我们将自然语言问题和文档块嵌入到向量中,使用Gecko文本嵌入模型[19],并通过最近邻搜索来识别与给定问题最相关的文档块。尽管可以通过摘要进一步压缩上下文,但我们决定不这样做,因为这可能会丢失重要的细节,如语法规则和示例。
表6:使用SQLite文档块的Ex Acc,使用基线管道测量。
| (a) 粗粒度文档块 | |||||||
| # 块数 | 01 | 2 | 3 | ||||
| BIRD 开发集 | Ex Acc (%)𝐿¯ (tok/req) | 61.847380.87 | 61.5432703.21 | 61.0842087.60 | 61.6751308.69 | ||
| KaggleDBQA 测试集 | Ex Acc (%)𝐿¯ (tok/req) | 57.83922.29 | 57.835224.18 | 59.4511441.86 | 60.0017209.37 | ||
| (b) 细粒度文档块 | |||||||
| # 块数0151015 | |||||||
| BIRD 开发集 | Ex Acc (%)𝐿¯ (tok/req) | 61.847380.87 | 60.437610.66 | 61.8610115.78 | 61.5414244.70 | 61.1517560.80 | |
| KaggleDBQA 测试集 | Ex Acc (%)𝐿¯ (tok/req) | 57.83922.29 | 59.452187.10 | 57.296202.0 | 58.377240.81 | 57.299545.82 |
表7:使用gemini-1.5-pro和gemini-1.5-flash的基线管道在BIRD开发集上的平均归一化生成和验证延迟。归一化延迟时间单位设置为BIRD开发集上的平均生成延迟。
| gemini-1.5-pro | gemini-1.5-flash | |
| 单次生成延迟(单位/请求) | 1.0 | 0.8 |
| 单次验证延迟(单位/请求) | 0.9 | 0.2 |
我们在表6中展示了文档检索的执行准确性和上下文大小。检索具有挑战性,因为自然语言问题并未揭示相应SQL查询的完整结构和特性;此外,编写正确的SQL查询需要结合文档多个部分的概念。然而,我们认为检索不完善并不是文档对生成几乎没有价值的原因。实际上,大模型所犯的错误主要是语义错误(例如,可执行查询返回语义上无关的结果)。
Gemini-1.5-Pro 模型已经非常熟悉文档中说明的 SQLite 语法和功能细节。SQLite 文档很可能已经在预训练数据集中。此外,该模型可以根据错误信息自行纠正语法错误,而无需任何文档或示例。实际上,大模型所犯的错误主要是语义错误(例如,可执行查询返回语义上无关的结果)。
Gemini-1.5-Pro 模型已经非常熟悉文档中说明的 SQLite 语法和功能细节。SQLite 文档很可能已经在预训练数据集中。此外,该模型可以根据错误信息自行纠正语法错误,而无需任何文档或示例。最近基于 GPT-4 的一项工作 [34] 也指出,错误并非源于简单的语法误用(例如函数名称),而是更微妙的格式问题(例如不符合所需的日期格式)和语义错误(输出的 SQL 可执行但与请求不符)。阅读 SQLite 文档对此类语义错误没有帮助——因为模型已经生成了语义上不正确的可执行查询。虽然没有准确性提升,但添加文档块会显著增加上下文大小,从而增加延迟。
4.8 长上下文与延迟的关系
在本节中,我们研究上下文大小(令牌数)与延迟之间的关系。Google 的 Gemini-1.5 生成 API 中上下文大小与延迟之间的关系主要取决于令牌数量,并且与基准数据集无关。我们使用从 BIRD 开发集中采样的不同上下文大小的请求来评估这种关系。图 5 表明存在近乎线性的关系(强正相关 R²=92.6)。值得注意的是,当上下文大小超过 32k 时,延迟和方差开始显著增加。较大的上下文 LLM 需要在多个主机和加速器上分散推理计算,引入额外的排队延迟。尽管我们预计较小的 Gemini-1.5-flash 变体会表现出更低的延迟,但由于排队延迟和资源分配差异,它在长尾部分也会出现延迟增加。随着上下文大小的增加(>32k 令牌),生成延迟显著增加(>> 4 秒),因此只有在生成质量有明显提升的情况下才应增加上下文。幸运的是,上下文大小与延迟之间的平均关系仍然是线性的,这使得建模变得容易。
表 7 展示了两种 Gemini-1.5 模型变体的平均延迟差异:更大、更昂贵的 Pro 和更小、更具成本效益的 Flash。BIRD 开发集上的平均生成延迟被用作归一化延迟的单位。验证延迟的差异更为明显,因为上下文大小较小,而具有较大上下文的 Pro 和 Flash 生成需要更多的预填充计算,导致增加且相似的排队延迟。两种模型都经历了增加且相似的平均生成延迟。对于单次验证延迟(指示较小上下文的延迟),Flash 比 Pro 快近 75%。
5 剥离研究
总体而言,我们专注于识别有助于提高 NL2SQL 性能的有用信息——并衡量上下文信息在性能和成本方面的影响。由于规则和 SQLite 文档块的单独贡献微乎其微,我们在剥离研究中排除了它们。规则是固定的,并作为指令的一部分包含在内。我们还省略了一些流行的技术,如思维链 (CoT) 提示和自我一致性。CoT 通过将复杂任务分解为子任务,使 LLM 能够进行多步推理,以解决像 NL2SQL 这样的结构化问题 [26, 33]。然而,我们的观察表明,CoT 并未提高最终输出质量,同时显著增加了上下文大小——通常增加了数千个令牌。
表 8 报告了使用 BIRD 开发集的生成性能(Ex Acc)、累积上下文大小(每请求令牌数)和延迟(每请求秒数)——这是最常用的 NL2SQL 基准测试,包含跨多个领域的多样化问题和表格。我们还在表 9 中报告了使用其他基准数据集进行的小型剥离研究的结果。该研究采用增量方法,一次添加一种技术或上下文信息元素。更常用于 NL2SQL 的技术和信息较早添加(模式、提示、列样本和自我纠正),而我们的长上下文管道特定组件则稍后添加(消歧和合成示例)。
由于最新的长上下文 LLM,Gemini-Pro-1.5 具有强大的检索能力,我们观察到随着包含更多的上下文信息,整体性能有所提高。然而,当我们根据难度级别对 BIRD 开发集中的问题进行分类时,发现不同类型的问题从不同类型的上下文信息中受益。例如,提供额外的样本列值(或全部提供以消除歧义)对于复杂的问题更有帮助,这些问题更加微妙和/或模糊,允许模型利用确切的列值来选择正确的列和连接路径。合成示例则相反,它有助于简单和中等难度的问题,但对于复杂问题反而有害。合成示例是使用目标数据库的模式元素生成的,用以说明常见的 SQL 特性和子句 [29]。它们往往更简单,涉及自然语言问题与 SQL 查询之间较少的模糊映射。提示也很有趣,因为它似乎是准确生成 SQL 的关键成分之一,并且对中等难度的问题帮助最大。BIRD 数据集中包含提示,用于澄清细微的概念(例如,“K-12 的合格免费率”),并给出正确的表达式(“K-12 的合格免费率 = ‘免费餐数 (K-12)’ / ‘入学人数 (K-12)’”),而中等难度的查询通常包含需要这种澄清的更多细微概念。
利用长上下文的一个关键方面是成本。表 8 展示了每个长上下文信息或技术如何贡献于总体上下文大小和延迟,这两者高度相关(我们在第 [4.8] 节讨论了上下文大小与延迟之间的近乎线性关系)。对于上下文大小和延迟,我们报告平均值加上 1 个标准差,因为由于重试和自我纠正机制导致方差很高。这样,报告的度量值可以涵盖大多数评估请求。请注意,跟踪每个请求的累积令牌数和延迟,直到返回最终输出。自我纠正(重试)可能因各种原因触发,从简单的语法错误到空结果不等。管道最多重试 5 次,应用适当的修复/修改并增加温度。由于其递归性质,自我纠正显著增加了延迟(和累积令牌数);在消除歧义(包括附加列值示例)的情况下,成本甚至呈指数级增长。在线合成示例生成也显著增加了运行时延迟,因为生成过程涉及一个长序列的自回归。
表 8:长上下文 NL2SQL 管道的消融分析。即使没有微调和/或多候选生成(即自我一致性),该管道在 BIRD 开发集上也表现出色。每个请求的上下文大小也显著增加,我们测量了给定用户请求下的任何细化迭代(自我纠正)的总累积令牌数。我们报告均值加 1 个标准差的统计值,以涵盖大多数请求。每个请求的上下文大小显著增加,我们测量了给定用户请求下的任何细化迭代(自我纠正)的总累积令牌数。我们报告均值加 1 个标准差的统计值,以涵盖大多数请求。
| BIRD Dev Ex Acc (%) | Context Size (tok/req) | Latency (𝑇 units/req) | ||||
| Long Context NL2SQL | Simple | Moderate | Challenging | Overall | 𝐿¯ + 𝜎 | 𝑇¯ + 𝜎 |
| + All DB table schema | 52.22 ( - ) | 30.82 ( - ) | 32.41 ( - ) | 43.87 ( - ) | 10772.77 ( - ) | 1.0 ( - ) |
| + Hints | 67.35 ( ↑ 15.13 ) | 51.08 ( ↑ 20.26 ) | 44.14 (↑ 11.73) | 60.23 (↑ 16.36) | 10796.12 (↑ 23.35) | 1.0 ( - ) |
| + Sample column values | 68.11 ( ↑ 0.76) | 53.66 ( ↑ 2.58) | 49.66 ( ↑ 5.52 ) | 61.99 (↑ 1.76) | 15568.47 ( ↑ 4772.35) | 1.0 ( - ) |
| + Self-correction | 71.03 ( ↑ 2.92) | 56.25 ( ↑ 2.59 ) | 52.41 (↑ 2.75) | 64.80 ( ↑ 2.81) | 50142.14 ( ↑ 34573.67) | 2.5 (↑ 1.5) |
| + Disambiguation | 71.14 ( ↑ 0.11) | 57.54 ( ↑ 1.29 ) | 55.17 ( ↑ 2.76 ) | 65.51 ( ↑ 0.71) | 385141.42 ( ↑ 334999.28) | 33.5 (↑ 32) |
| + Synthetic examples | 72.32 ( ↑ 1.18) | 59.05 ( ↑ 1.51 ) | 53.79 (↓ 1.38 ) | 66.56 (↑ 1.05) | 390413.05 (↑ 5271.62902) | 35.8 + 90.8a(↑ 93.1) |
| + Verify & retryb | 72.65 ( ↑ 0.33) | 59.70 ( ↑ 0.65 ) | 55.86 ( ↑ 2.07 ) | 67.14 (↑ 0.58 ) | 399229.81 (↑ 8816.75) | 37.1 + 90.8 (↑ 1.3) |
a 我们单独测量在线示例生成延迟,如果预先生成并检索,则可以隐藏/减少。
b 平均尝试次数为 1.01,其中大多数情况下接受第一次输出,除了少数具有挑战性的案例。
表 9:一项小型消融研究,分析了消除歧义和使用合成示例的多示例 ICL 在长上下文 NL2SQL 中的有效性。括号中的差异是从表 2 中的完整管道结果测量的。
| 无消除歧义 | 无合成示例 | ||||
| 准确率 (%) | 𝑇¯𝑔 (T单位/请求) | 准确率 (%) | 𝑇¯𝑔 (T单位/请求) | ||
| SPIDER 1.0 测试 | 87.1 ( - ) | 1.3 ( ↓ 0.2) | 86.3 ( ↓ 0.8) | 1.4 ( ↓ 0.1) | |
| KaggleDBQA 测试 | 60.5 ( ↓ 0.6) | 2.5 ( ↓ 0.2) | 60.5 ( ↓ 0.6) | 2.3 ( ↓ 0.4) | |
| BEAVER 数据仓库 | 52.1 ( ↓ 8.3) | 22.5 ( ↓ 467.3) | 60.4 ( -) | 595.5 ( ↑ 25.5) |
表 10:进一步细分的小型消融研究结果,准确率(%)。如表 8 所示,消除歧义(无合成示例)对具有挑战性或特别难的问题更有帮助,而使用合成示例的多示例 ICL(无消除歧义)对简单问题更有帮助。
| 问题难度 | 简单 | 中等 | 困难 | 特别难 | |
| SPIDER 1.0 | 无消除歧义 | 67.56 | 61.62 | 64.86 | 43.24 |
| 测试 | 无合成示例 | 65.94 | 57.83 | 64.86 | 50.81 |
| KaggleDBQA | 无消除歧义 | 92.09 | 89.59 | 87.00 | 74.19 |
| 测试 | 无合成示例 | 92.79 | 86.79 | 86.79 | 75.89 |
解码过程中的运行时延迟有所增加,因为生成过程涉及一个长序列的自回归。然而,如果合成示例是在离线生成并在运行时检索,如第[4]节所述,这种延迟可以被显著降低。例如,“验证与重试”每请求增加8816个令牌,仅使延迟增加了1.3个标准化延迟单位(均值加1个标准差)。
表9报告了小型消融研究的结果,该研究分析了最具争议(昂贵)的长上下文技术——消除歧义和使用合成示例的多示例ICL在其他基准数据集上的有效性。不使用上述任何一种技术运行完整管道会同时降低准确性和延迟(或上下文大小)。跳过消除歧义(无消除歧义)对SPIDER和KaggleDBQA基准的影响有限,但在BEAVER数据集上更为明显。这是因为消除歧义仅在返回空结果集的可执行SQL查询时触发。这种无效预测在BEAVER数据仓库(dw)数据集中更频繁发生,因为其模式显著更复杂,需要更多的连接(平均4.25个),相比之下其他数据集较少。同样,跳过多示例ICL与合成示例(无合成示例)会同时降低准确性和延迟,但对SPIDER和KaggleDBQA的影响有限。相反,在BEAVER上不使用合成示例不会改变准确性,但由于更频繁的消除歧义尝试,延迟显著增加。这表明,总体而言,生成的示例比有帮助更具误导性,但导致空结果较少。这是预期的,因为合成示例生成主要针对较简单的查询结构[29],而不是涉及许多连接的星型模式(数据仓库)查询。还值得注意的是,消除歧义和合成示例具有非常不同的性能特征。如BIRD开发集的完整消融研究(表8)所示,消除歧义对具有挑战性的问题更有帮助,而合成示例则对解决简单问题贡献更多。我们在其他基准数据集中也观察到了相同趋势,如表10所示。
6. 讨论和限制
6.1 错误分析
为了更深入地了解生成的SQL与真实SQL之间的差异,我们随机抽取了BIRD开发集中基线输出与提供的黄金SQL不符的20%实例。图6展示了这些抽样子集中观察到的错误类别及其各自的比例。
错误是分层分类的。图表的内环描绘了三个高层次的分类:“模糊问题”代表生成的SQL大致正确但由于相应自然语言问题的模糊性而被标记为不正确的情况;“生成的SQL错误”,表示生成的SQL包含根本性错误的情况;以及“提供的黄金SQL错误”,涵盖提供的黄金SQL本身不正确的情况。
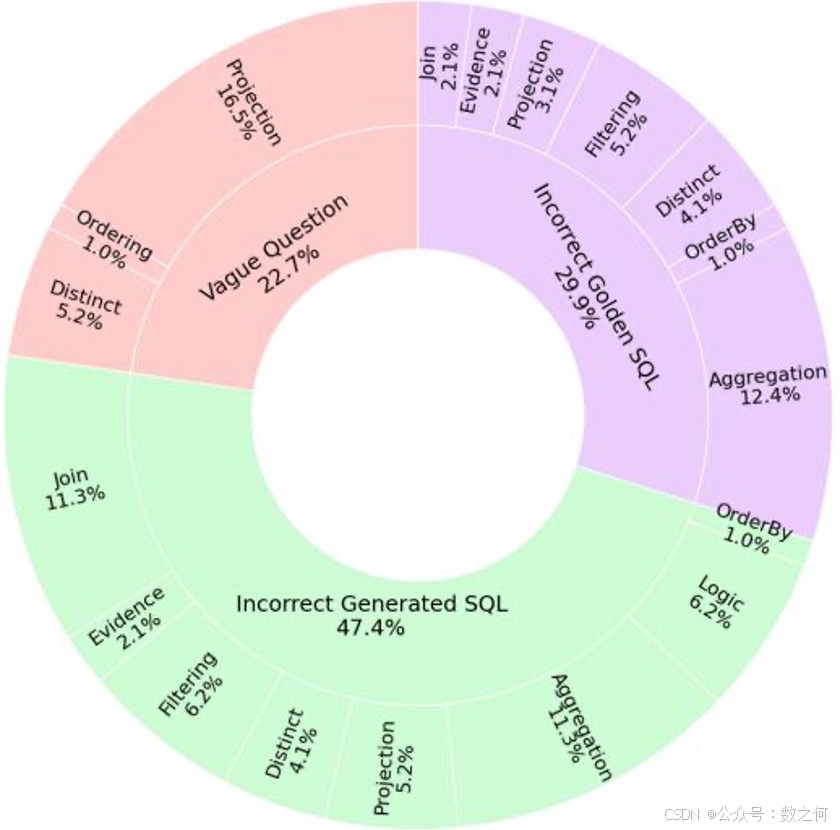
图6:观察到的错误类别的细分
表11:长上下文NL2SQL BIRD开发集上的准确率上限(至少有一个候选是正确的)与多个候选生成。
| 候选数量 | 1 | 3 | 5 | 7 | 9 |
| 准确率 (%) | 65.97 | 68.84 | 68.97 | 69.69 | 70.60 |
外环提供了每个高层次类别中错误类型的更细粒度的细分。例如,在“生成的SQL错误”类别中,我们观察到了如“连接”、“逻辑”和“聚合”等子类别,每个子类别都突出了生成的SQL中的特定类型的问题。“逻辑”指的是生成的查询未能逻辑上理解用户问题意图的情况。这些子类别中的错误分布揭示了与连接、过滤和聚合相关的问题对总体错误率有显著贡献。
6.2 通过自一致性进一步提高性能
自一致性是另一种非常流行的NL2SQL技术 [8, 10, 11, 29, 34, 37],其中生成多个候选,并由微调的选择器选择最一致的答案或最佳答案。正如最近最先进的方法 [11, 29] 在BIRD排行榜上所展示的那样,自一致性已成为实现高精度NL2SQL的关键技术。这涉及使用不同的生成器(即NL2SQL管道)生成多个候选,并且每个生成器尝试多次,然后选择最佳的一个。表1中的一个最先进的方法CHASE-SQL使用我们的长上下文管道作为三个候选生成器之一,为其在BIRD排行榜上的顶级表现做出了贡献。自一致性的缺点是它在延迟和大模型调用次数方面可能会迅速变得昂贵。自一致性与我们的工作正交,如果与我们的管道一起使用,可以进一步提高NL2SQL的性能。表11展示了使用0.5的生成温度从我们的长上下文管道生成多个输出候选的影响。使用神谕选择器(即每个问题至少有一个候选是正确的),我们可以将准确率提升到70%以上。在 [11, 29] 中,候选集合是使用多个管道生成的,因为不同的策略会产生更多样化的输出,从而进一步提高自一致性的最终准确性。
自一致性与使用长上下文正交,不在本文的研究范围内。在这项工作中,我们专注于生成一个高质量的候选,并研究利用长上下文(即额外的上下文信息)对性能的影响,这是以前在NL2SQL中未探索过的。
6.3 生产环境中的长上下文及其限制
我们的研究表明(表8),来自BIRD开发集的大约68%的请求可以达到40万个累积令牌,并需要高达130个单位的时间。这对大多数生产服务来说可能是不可接受的。如果使用自一致性等技术,成本会更高。长上下文是一种添加更多信息的好方法,但必须谨慎使用。为了在生产环境中正确利用长上下文,可以根据我们的分析选择合适的额外信息和技术。例如,可以跳过消除歧义和在线示例生成,以将大多数请求的延迟控制在大约1.5个标准化秒以内。示例可以在离线时生成,如第4.5节所示,示例选择与合成示例配合得很好。使用闪存可以进一步降低成本,根据当前定价和观察到的延迟,每请求的延迟减少约20%,费用减少约94%。
我们研究的一个局限性是在分析长上下文和额外上下文信息对NL2SQL的影响时,缺乏准确模拟企业用例的基准数据集。这类情况通常涉及数百个非常宽的表格,每个表格有数千列,以及描述较少且名称相似的模式,使得模式链接变得更加具有挑战性。这些场景不仅对模式链接提出了固有的困难,而且由于模式信息量的增加,进一步加剧了长上下文技术的成本。为了解决这个问题,我们整合了多个具有挑战性的NL2SQL基准数据集,并评估了在信息密度非常低的情况下(例如,提供来自数十个无关表格和数据库的完整模式细节和示例值,而只有少数列是相关的,如表3所示),长上下文模型的表现。我们观察到,额外的信息通常不会造成干扰,长上下文技术的表现与没有这些信息的基线相当。我们预计这些见解将在更极端的用例中成立,并且随着长上下文大语言模型的不断改进,这些见解将变得越来越明显。例如,我们的长上下文NL2SQL管道在企业数据仓库基准BEAVER上的表现显著优于[6]中的基线结果(见表[2])。
尽管这项工作重点在于评估在LLM的扩展上下文窗口内直接提供各种形式的上下文信息的影响,但我们承认所探索的信息并不全面。特别是,我们没有研究利用知识图谱来增强NL2SQL性能。虽然为特定领域构建一个全面的知识图谱成本很高,但最近的工作[3, 32]已经展示了使用基于知识图谱的问题回答在企业数据集上的有希望的结果。在未来的工作中,我们有兴趣探索集成其他上下文来源,如业务本体和知识图谱,以进一步利用长上下文大语言模型的能力。
7 结论
在这项工作中,我们探索了利用Google的gemini-1.5-pro提供的扩展上下文窗口进行NL2SQL的潜力。我们的研究结果表明,长上下文大语言模型可以有效地利用额外的上下文,在多个基准测试中实现了强大的性能(表[2]),包括在BIRD基准上达到67.41%的执行准确率——无需微调或计算昂贵的自一致性技术。这种性能突显了长上下文模型在检索和推理大量上下文信息方面的稳健性。具体来说,我们分析了包含整个数据库模式细节、用户提供的提示、样本列值以及许多示例ICL合成示例对提高SQL生成准确性的影响。我们还表明,自我纠正和验证可以进一步提高准确性,尽管会增加延迟和累积令牌数。总体而言,我们观察到gemini-1.5-pro在扩展上下文窗口中表现出强大的检索能力,即使存在不相关信息也是如此。此外,我们的研究结果表明,长上下文模型更为稳健,不会出现“中间迷失”[24]的问题。
我们的研究是一个独特的例子,展示了大语言模型增强能力(在这种情况下是扩展的大上下文大小)如何影响我们处理NL2SQL问题的方式。与之前专注于将过滤后的信息压缩到有限上下文窗口中的工作不同,我们探索了向模型提供额外有用信息的潜力。我们展示了额外的信息可以通过帮助解决语义问题(通用SQL方言的语法问题已由基础模型很好地解决)而在NL2SQL中有用。此外,我们调查了使用长上下文技术的成本影响,并得出结论,当与准确的模式和示例检索结合时,它们可以互补且更高效,重点在于召回率。实际上,完美的表模式检索将通过缩小SQL生成期间的模式链接搜索空间来实现更强的性能[6, 9, 34](附录[A.2])。然而,在实践中实现完美检索是非常具有挑战性的(附录[A.1])。
在实际场景中,当检索和排名次优时,提供更多信息并依赖长上下文模型的强大检索能力可以提供一种可行但更昂贵的替代策略。提高长上下文模型服务的成本效率将是使长上下文更加实用的重要研究领域。
参考文献
[1] 2024.SQLite Home Page
Yeounoh Chung, Gaurav T.Kakkar, 余甘, Brenton Milne 和 Fatma Özcan
- [2] Rishabh Agarwal, Avi Singh, Lei M Zhang, Bernd Bohnet, Luis Rosias, Stephanie C.Y. Chan, Biao Zhang, Aleksandra Faust, 和 Hugo Larochelle. 2024. 多样本情境学习. 在 ICML 2024 情境学习研讨会. Many-shot In-Context Learning | OpenReview
- [3] Dean Allemang 和 Juan Sequeda. 2024. 提高大语言模型在问答中的准确性:本体来救援! arXiv 预印本 arXiv:2405.11706 (2024).
- [4] 于诗白, 吕欣, 张家杰, 吕宏昌, 唐建凯, 黄志典, 杜正晓, 刘小, 曾傲寒, 侯磊 等. 2023. Longbench: 一个用于长上下文理解的双语多任务基准. arXiv 预印本 arXiv:2308.14508 (2023).
- [5] Hasan Alp Caferoğlu 和 Özgür Ulusoy. 2024. E-SQL: 通过问题丰富进行直接模式链接的文本到 SQL. arXiv 预印本 arXiv:2409.16751 (2024).
- [6] Peter Baile Chen, Fabian Wenz, Yi Zhang, Moe Kayali, Nesime Tatbul, Michael Cafarella, Çağatay Demiralp, 和 Michael Stonebraker. 2024. BEAVER: 企业级文本到 SQL 基准. arXiv 预印本arXiv:2409.02038 (2024).
- [7] José Manuel Domínguez, Benjamín Errázuriz, 和 Patricio Daher. 2024. Blar-SQL: 更快、更强、更小的 NL2SQL. arXiv 预印本 arXiv:2401.02997 (2024).
- [8] 董雪梅, 张超, 葛宇航, 毛宇然, 高云军, 林金书, 楼东芳 等. 2023. C3: 使用 ChatGPT 的零样本文本到SQL. arXiv 预印本 arXiv:2307.07306 (2023).
- [9] Avrilia Floratou, Fotis Psallidas, Fuheng Zhao, Shaleen Deep, Gunther Hagleither, Wangda Tan, Joyce Cahoon, Rana Alotaibi, Jordan Henkel, Abhik Singla, Alex Van Grootel, Brandon Chow, Kai Deng, Katherine Lin, Marcos Campos, K. Venkatesh Emani, Vivek Pandit, Victor Shnayder, Wenjing Wang, 和 Carlo Curino. 2024. NL2SQL 是一个已解决的问题… 不是!. 在创新数据系统研究会议. [PDF] NL2SQL is a solved problem... Not! | Semantic Scholar
- [10] 高大卫, 王海斌, 李亚良, 孙秀玉, 钱一辰, 丁波林, 和 周景仁. 2023. 由大型语言模型赋能的文本到SQL: 基准评估. CoRR abs/2308.15363 (2023).
- [11] 高英琪, 刘一夫, 李晓霞, 施晓蓉, 朱茵, 王一鸣, 李世奇, 李伟, 洪云涛, 罗子玲, 高金阳, 牟立宇, 和 李宇. 2024.
润色后的文本:
尽管过滤和排名最相关的信息对于准确性和成本都至关重要,但我们的研究结果表明,除非检索非常准确,否则通过包含更多信息来提高召回率——即使是以较低的精度为代价——也是一种有益的策略。我们预计这些见解将在更极端的用例中成立,并且随着长上下文大语言模型的不断改进,这些见解将变得越来越明显。例如,我们的长上下文NL2SQL管道在企业数据仓库基准BEAVER上的表现显著优于[6]中的基线结果(见表[2])。
尽管这项工作重点在于评估在LLM的扩展上下文窗口内直接提供各种形式的上下文信息的影响,但我们承认所探索的信息并不全面。特别是,我们没有研究利用知识图谱来增强NL2SQL性能。虽然为特定领域构建一个全面的知识图谱成本很高,但最近的研究[3, 32]已经展示了基于知识图谱的问题回答在企业数据集上的有希望的结果。在未来的工作中,我们有兴趣探索集成其他上下文来源,如业务本体和知识图谱,以进一步利用长上下文大语言模型的能力。
7 结论
在这项工作中,我们探索了利用Google的gemini-1.5-pro提供的扩展上下文窗口进行NL2SQL的潜力。我们的研究结果表明,长上下文大语言模型可以有效地利用额外的上下文,在多个基准测试中实现了强大的性能(表[2]),包括在BIRD基准上达到67.41%的执行准确率——无需微调或计算昂贵的自一致性技术。这种性能突显了长上下文模型在检索和推理大量上下文信息方面的稳健性。具体来说,我们分析了包含整个数据库模式细节、用户提供的提示、样本列值以及许多示例ICL合成示例对提高SQL生成准确性的影响。我们还表明,自我纠正和验证可以进一步提高准确性,尽管会增加延迟和累积令牌数。总体而言,我们观察到gemini-1.5-pro在扩展上下文窗口中表现出强大的检索能力,即使存在不相关信息也是如此。此外,我们的研究结果表明,长上下文模型更为稳健,不会出现“中间迷失”[24]的问题。
我们的研究是一个独特的例子,展示了大语言模型增强能力(在这种情况下是扩展的大上下文大小)如何影响我们处理NL2SQL问题的方式。与之前专注于将过滤后的信息压缩到有限上下文窗口中的工作不同,我们探索了向模型提供额外有用信息的潜力。我们展示了额外的信息可以通过帮助解决语义问题(通用SQL方言的语法问题已由基础模型很好地解决)而在NL2SQL中有用。此外,我们调查了使用长上下文技术的成本影响,并得出结论,当与准确的模式和示例检索结合时,它们可以互补且更高效,重点在于召回率。实际上,完美的表模式检索将通过缩小SQL生成期间的模式链接搜索空间来实现更强的性能[6, 9, 34](附录[A.2])。然而,在实践中实现完美检索是非常具有挑战性的(附录[A.1])。
在实际场景中,当检索和排名次优时,提供更多信息并依赖长上下文模型的强大检索能力可以提供一种可行但更昂贵的替代策略。提高长上下文模型服务的成本效率将是使长上下文更加实用的重要研究领域。
参考文献
[1] 2024.SQLite Home Page
Yeounoh Chung, Gaurav T. Kakkar, 余甘, Brenton Milne 和 Fatma Özcan
- [2] Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie C. Y. Chan, Biao Zhang, Aleksandra Faust, 和 Hugo Larochelle. 2024. 多样本情境学习. 在 ICML 2024 情境学习研讨会. Many-shot In-Context Learning | OpenReview
- [3] Dean Allemang 和 Juan Sequeda. 2024. 提高大语言模型在问答中的准确性:本体来救援! arXiv 预印本 arXiv:2405.11706 (2024).
- [4] 于诗白, 吕欣, 张家杰, 吕宏昌, 唐建凯, 黄志典, 杜正晓, 刘小, 曾傲寒, 侯磊 等. 2023. Longbench: 一个用于长上下文理解的双语多任务基准. arXiv 预印本 arXiv:2308.14508 (2023).
- [5] Hasan Alp Caferoğlu 和 Özgür Ulusoy. 2024. E-SQL: 通过问题丰富进行直接模式链接的文本到 SQL. arXiv 预印本 arXiv:2409.16751 (2024).
- [6] Peter Baile Chen, Fabian Wenz, Yi Zhang, Moe Kayali, Nesime Tatbul, Michael Cafarella, Çağatay Demiralp, 和 Michael Stonebraker. 2024. BEAVER: 企业级文本到 SQL 基准. arXiv 预印本arXiv:2409.02038 (2024).
- [7] José Manuel Domínguez, Benjamín Errázuriz, 和 Patricio Daher. 2024. Blar-SQL: 更快、更强、更小的 NL2SQL. arXiv 预印本 arXiv:2401.02997 (2024).
- [8] 董雪梅, 张超, 葛宇航, 毛宇然, 高云军, 林金书, 楼东芳 等. 2023. C3: 使用 ChatGPT 的零样本文本到SQL. arXiv 预印本 arXiv:2307.07306 (2023).
- [9] Avrilia Floratou, Fotis Psallidas, Fuheng Zhao, Shaleen Deep, Gunther Hagleither, Wangda Tan, Joyce Cahoon, Rana Alotaibi, Jordan Henkel, Abhik Singla, Alex Van Grootel, Brandon Chow, Kai Deng, Katherine Lin, Marcos Campos, K. Venkatesh Emani, Vivek Pandit, Victor Shnayder, Wenjing Wang, 和Carlo Curino. 2024. NL2SQL 是一个已解决的问题… 不是!. 在创新数据系统研究会议. [PDF] NL2SQL is a solved problem... Not! | Semantic Scholar
- [10] 高大卫, 王海斌, 李亚良, 孙秀玉, 钱一辰, 丁波林, 和 周景仁. 2023. 由大型语言模型赋能的文本到 SQL: 基准评估. CoRR abs/2308.15363 (2023).
- [11] 高英琪, 刘一夫, 李晓霞, 施晓蓉, 朱茵, 王一鸣, 李世奇, 李伟, 洪云涛, 罗子玲, 高金阳, 牟立宇, 和 李宇. 2024.周景仁. 2023. 由大型语言模型赋能的文本到 SQL: 基准评估. CoRR abs/2308.15363 (2023).
- [11] 高英琪, 刘一夫, 李晓霞, 施晓蓉, 朱茵, 王一鸣, 李世奇, 李伟, 洪云涛, 罗子玲, 高金阳, 牟立宇, 和 李宇. 2024. XiYan-SQL: 一个多生成器集成框架用于文本到 SQL. arXiv 预印本 arXiv:2411.08599 (2024). [2411.08599] A Preview of XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
- [12] Google Cloud. 2024. Gemini API 定价. https://ai.google.dev/pricing#1_5pro 访问日期: 2025年1月7日.
- [13] Google Cloud. 2024. BigQuery 中的 Gemini. https://cloud.google.com/bigquery/docs/write-sql-gemini访问日期: 2024年10月15日.
- [14] George Katsogiannis-Meimarakis 和 Georgia Koutrika. 2023. 文本到 SQL 的深度学习方法综述. VLDB J. 32, 4 (2023), 905–936. A survey on deep learning approaches for text-to-SQL | The VLDB Journal
- [15] George Katsogiannis-Meimarakis, Mike Xydas, 和 Georgia Koutrika. 2023. 具有深度学习的数据库自然语言接口. Proc. VLDB Endow. 16, 12 (2023), 3878–3881. Natural Language Interfaces for Databases with Deep Learning | Proceedings of the VLDB Endowment
- [16] Chia-Hsuan Lee, Oleksandr Polozov, 和 Matthew Richardson. 2021. KaggleDBQA: 文本到 SQL 解析器的真实评估. 在第59届计算语言学协会年会和第11届国际自然语言处理联合会议(第一卷:长论文). 计算语言学协会, 在线, 2261–2273. KaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers - ACL Anthology
- [17] Dongjun Lee, Choongwon Park, Jaehyuk Kim, 和 Heesoo Park. 2024. Mcssql: 利用多个提示和多项选择进行文本到 SQL 生成. arXiv 预印本 arXiv:2405.07467 (2024).
- [18] Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, Sébastien MR Arnold, Vincent Perot, Siddharth Dalmia, 等. 2024. 长上下文语言模型能否取代检索、RAG、SQL 等? arXiv 预印本 arXiv:2406.13121 (2024).
- [19] Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R. Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, Yi Luan, Sai Meher Karthik Duddu, Gustavo Hernández Abrego, Weiqiang Shi, Nithi Gupta, Aditya Kusupati, Prateek Jain, Siddhartha R. Jonnalagadda, Ming-Wei Chang, 和 Iftekhar Naim. 2024. Gecko: 从大型语言模型中提炼出的多功能文本嵌入. ArXiv abs/2403.20327 (2024). [PDF] Gecko: Versatile Text Embeddings Distilled from Large Language Models | Semantic Scholar
- [20] Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, 和 Nan Tang. 2024. 自然语言到 SQL 的黎明:我们完全准备好了吗?arXiv 预印本 arXiv:2406.01265 (2024).
- [21] Haoyang Li, Jing Zhang, Cuiping Li, 和 Hong Chen. 2023. Resdsql: 解耦模式链接和骨架解析以实现文本到 SQL. 在人工智能促进协会会议论文集,第 37 卷. 13067–13075.
- [22] Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo 等. 2024. 大型语言模型能否作为数据库接口?大规模数据库基础文本到 SQL 的大基准. 神经信息处理系统进展 36 (2024).
- [23] Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, 和 Wenhu Chen. 2024. 长上下文的语言模型难以进行长上下文学习. arXiv 预印本 arXiv:2404.02060 (2024).
- [24] Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, 和Percy Liang. 2024. 迷失在中间:语言模型如何使用长上下文. 计算语言学协会会刊 12 (2024), 157–173. https://doi.org/10.1162/tacl_a_00638
- [25] Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, 和 Yuyu Luo. 2024. 基于大型语言模型的 NL2SQL 综述:我们在哪里,我们要去哪里?arXiv 预印本arXiv:2408.05109 (2024).
通过这些参考文献,我们可以看到当前在文本到 SQL 转换领域的最新研究和发展趋势。这些研究不仅涵盖了新的方法和技术,还探讨了现有技术的改进和应用。
以下是相关文献的具体引用:
- [26] Xiping Liu 和 Zhao Tan. 2023. 分而提示:用于文本到 SQL 的链式思维提示。arXiv 预印本arXiv:2304.11556 (2023)。
- [27] Karime Maamari, Fadhil Abubaker, Daniel Jaroslawicz, 和 Amine Mhedhbi. 2024. 模式链接的终结?在合理推理的语言模型时代中的文本到 SQL。arXiv 预印本 arXiv:2408.07702 (2024)。
- [28] Linyong Nan, Yilun Zhao, Weijin Zou, Narutatsu Ri, Jaesung Tae, Ellen Zhang, Arman Cohan, 和Dragomir Radev. 2023. 提升大型语言模型的少量样本文本到 SQL 能力:关于提示设计策略的研究。arXiv 预印本 arXiv:2305.12586 (2023)。
- [29] Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Özcan, 和 Sercan Ö Arık. 2024. CHASE-SQL:多路径推理和优化候选选择的文本到 SQL。arXiv 预印本 arXiv:2410.01943 (2024)。
- [30] Mohammadreza Pourreza 和 Davood Rafiei. 2024. Din-sql:具有自我纠正功能的分解上下文学习文本到 SQL。神经信息处理系统进展 36 (2024)。
- [31] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser 等。2024. Gemini 1.5:解锁跨数百万标记上下文的多模态理解。arXiv 预印本 arXiv:2403.05530 (2024)。
- [32] Juan Sequeda, Dean Allemang, 和 Bryon Jacob. 2024. 一个基准来理解知识图谱在企业 SQL 数据库问题回答中的作用。在第七届图数据管理经验与系统联合研讨会(GRADES)和网络数据分析(NDA)论文集。1–12。
- [33] Chang-You Tai, Ziru Chen, Tianshu Zhang, Xiang Deng, 和 Huan Sun. 2023. 探索链式思维风格提示用于文本到 SQL。arXiv 预印本 arXiv:2305.14215 (2023)。
- [34] Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, 和 Amin Saberi. 2024. CHESS:高效 SQL 合成的上下文利用。arXiv 预印本 arXiv:2405.16755 (2024)。
- [35] Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, 和 Zhoujun Li. 2024. MAC-SQL:一个多智能体协作框架用于文本到 SQL。arXiv:cs.CL/2312.11242。
- [36] Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, 和 Matthew Richardson. 2020.
- [44] Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le 等。2022. 从最简单到最复杂的提示使大型语言模型能够进行复杂推理。arXiv 预印本 arXiv:2205.10625 (2022)。
A 附录
A.1 表检索模拟
为了进行真实的表检索模拟,我们使用 BigQuery 的 SQL 代码辅助功能运行了 BIRD 基准测试[13]。结果与标准的 BIRD 基准设置不同,因为它反映了为 BigQuery 生产用户服务时所面临的挑战。通常在运行 BIRD 基准时,每个查询都链接到一个包含最多 13 个表的单一数据库。BigQuery 的操作方式不同;用户可以询问他们有权访问的任何表,而 BigQuery 的检索系统利用用户交互历史来缩小搜索范围。为了获得真实的结果,用户交互被设定为匹配 BigQuery 生产流量中的查询分布,并且偏向于会话开始时的查询(较少重复查询),因为这些查询提出了更难的检索问题。
对于基准测试中的每个示例,表检索按以下步骤进行:1)模拟的用户视图和查询交互将搜索范围缩小到 1-100 个候选者;2)候选者通过 Gecko [19] 进行嵌入并重新排序,以确定与用户查询的相关性;3)固定数量的 top-k 候选者被传递到 NL2SQL 阶段。在测试时,第一阶段的召回率为 82%。因此,82% 是可达到的最大端到端召回率,并代表了重新排序阶段的近乎完美的结果。
A.2 良好列选择的影响
表 12:相关模式元素过滤(TBR:表检索,CR:列检索)和 BIRD 开发集上的 Ex Acc
| 过滤后的模式 | 真实模式 | |
| Ex Acc (%) | 64.08 | 72.43 |
| TBR 召回率 (%) | 97.69 | 100 |
| TBR 精确度(%) | 89.72 | 100 |
| CR 召回率(%) | 97.69 | 100 |
这些数据表明,良好的列选择对提高准确性和召回率具有显著影响。69 | 100 | | 列检索召回率 (%) | 97.69 | 100 | | 表检索精确度 (%) | 89.72 | 100 | | 列检索精确度 (%) | 69.43 | 100 |
我们使用 BIRD 开发集评估了模式选择对执行准确性的影响。具体来说,我们将过滤后的模式与完美的真实模式进行了比较。过滤后的模式类似于 CHESS [34] 构建,包含相关表和列、它们的描述以及相关的示例值。12 报告了执行准确性(Ex Acc)以及表检索(TBR)和列检索(CR)的召回率和精确度。虽然真实模式在所有指标上都达到了完美性能(100%),但过滤后的模式也表现出高召回率,能够正确识别大多数相关的模式元素(表检索召回率为 97.69%,列检索召回率为 97.69%)。然而,其精确度较低(表检索为 89.72%,列检索为69.43%),这表明过滤后的模式中包含了一些不相关的列或表。需要注意的是,模式过滤算法的成本较高,在BIRD 开发集上每次请求平均需要 78 次大语言模型调用和 339,965 个令牌。