13 迭代器与闭包
Rust 的设计灵感来源于很多现存的语言和技术。其中一个显著的影响就是 函数式编程(functional programming)。函数式编程风格通常包含将函数作为参数值或其他函数的返回值、将函数赋值给变量以供之后执行等等。
- 闭包(Closures),一个可以储存在变量里的类似函数的结构
- 迭代器(Iterators),一种处理元素序列的方式
闭包
闭包:可以捕获其所在环境的匿名函数
-
是匿名函数
-
保存为变量、作为参数
-
可在一个地方创建闭包,然后在另一个上下文中调用闭包来完成运算
-
可从其定义的作用域捕获值
闭包类型推断和注解
闭包并不总是要求像 fn 函数那样在参数和返回值上注明类型。函数中需要类型注解是因为它们是暴露给用户的显式接口的一部分。严格定义这些接口对保证所有人都对函数使用和返回值的类型理解一致是很重要的。与此相比,闭包并不用于这样暴露在外的接口:它们储存在变量中并被使用,不用命名它们或暴露给库的用户调用。
闭包通常很短,并只关联于小范围的上下文而非任意情境。在这些有限制的上下文中,编译器能可靠地推断参数和返回值的类型,类似于它是如何能够推断大部分变量的类型一样(同时也有编译器需要闭包类型注解的罕见情况)。
函数和闭包对比
fn add_one_v1 (x: u32) -> u32 { x + 1 } // 函数定义
let add_one_v2 = |x: u32| -> u32 { x + 1 }; // 完整标注的闭包定义
let add_one_v3 = |x| { x + 1 }; // 闭包定义中省略了类型注解
let add_one_v4 = |x| x + 1 ; // 只有一个表达式的时候,{}也可以省略
编译器会为闭包定义中的每个参数和返回值推断一个具体类型
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5); // error
}
第一次使用 String 值调用 example_closure 时,编译器推断这个闭包中 x 的类型以及返回值的类型是 String 。接着这些类型被锁定进闭包 example_closure 中,如果尝试对同一闭包使用不同类型则就会得到类型错误。
捕获引用或者移动所有权(move)
闭包可以通过三种方式捕获其环境,它们直接对应到函数获取参数的三种方式:不可变借用,可变借用和获取所有权。闭包会根据函数体中如何使用被捕获的值决定用哪种方式捕获。
与函数获得参数的三种方式一样,闭包捕获引用的方式如下:
- 取得所有权:FnOnce,这个闭包只能被调用一次,并且在调用时会消耗掉其环境中的值
- 可变借用:FnMut
- 不可变借用:Fn
创建闭包时,通过闭包对**环境值(闭包的参数,外部变量)**的使用,Rust 能推断出此闭包具体使用哪个 trait
- 所有的闭包都实现了 FnOnce
- 没有移动捕获变量的实现了 FnMut
- 无需可变访问捕获变量的闭包实现了 Fn
文件名:src/main.rs
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {:?}", list);
let only_borrows = || println!("From closure: {:?}", list); // 定义闭包,推断为不可变引用的闭包,因为只需不可变引用就能打印其值
println!("Before calling closure: {:?}", list);
only_borrows(); // 闭包名+() 即可调用闭包
println!("After calling closure: {:?}", list);
// 因为同时可以有多个 list 的不可变引用,所以在闭包定义之前,闭包定义之后调用之前,闭包调用之后代码仍然可以访问 list
}
修改闭包体让它向 list vector 增加一个元素。闭包现在捕获一个可变引用:
fn main() {
let mut list = vec![1, 2, 3];
println!("Before defining closure: {:?}", list);
let mut borrows_mutably = || list.push(7);
borrows_mutably();
println!("After calling closure: {:?}", list);
}
注意在 borrows_mutably 闭包的定义和调用之间不再有 println! ,当 borrows_mutably 定义时,它捕获了 list 的可变引用。因为当可变借用存在时不允许有其它的借用,所以在闭包定义和调用之间不能有不可变引用来进行打印。闭包在被调用后就不再被使用,这时可变借用结束。
move
在参数列表前使用 move 关键字,可以强制闭包取得它所使用的环境值的所有权,当将闭包传递给新线程以移动数据使其归新线程所有时,此技术最为有用。
在 16 章将会频繁使用该关键字和闭包结合
这个例子并没有强制移动 x ,但是被rust推断为取得所有权了
fn main() {
let x = vec![1, 2, 3];
let closure = || {
let y = x; // 移动 x 的所有权到闭包内部
println!("{:?}", x);
};
closure(); // 调用闭包
println!("{:?}", x); // 这里编译会报错,因为 x 的所有权已经被移动到闭包内部了
}
迭代器
迭代器模式:对一系列项执行某些任务
迭代器负责:遍历每个项;决定序列(遍历)何时完成的逻辑
Rust 的迭代器:
- 懒惰的:除非调用消费迭代器的方法,否则迭代器本身没有任何效果
我们使用 for 循环来遍历一个数组时,在底层它隐式地创建并接着消费了一个迭代器。 可参见博客第 8 章,遍历 vector 中的元素 这块内容,与 vector 的区别。
Iterator trait 和 next 方法
迭代器都实现了一个叫做 Iterator 的定义于标准库的 trait。这个 trait 的定义看起来像这样:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// 此处省略了方法的默认实现
}
Iterator trait 仅要求实现一个方法:next
next:
- 每次返回迭代器的一项
- 返回结果包裹在 Some 里
- 迭代结束,返回 None
可直接在迭代器上调用 next 方法
文件名:src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}
注意 v1_iter 需要是可变的:在迭代器上调用 next 方法改变了迭代器中用来记录序列位置的状态,换句话说,代码消费(consume)了。使用 for 循环时无需使 v1_iter 可变因为 for 循环会获取 v1_iter 的所有权并在后台使 v1_iter 可变。
几个迭代方法
iter方法:在不可变引用上创建迭代器into_iter方法:创建的迭代器会获得所有权iter_mut方法:迭代可变的引用
消费/产生 迭代器
调用 next 方法的方法被称为 消费适配器(consuming adaptors),因为调用它们会消耗迭代器。一个消费适配器的例子是 sum 方法。这个方法获取迭代器的所有权并反复调用 next 来遍历迭代器,因而会消费迭代器。当其遍历每一个项时,它将每一个项加总到一个总和并在迭代完成时返回总和。
文件名:src/lib.rs
# #[cfg(test)]
# mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum(); // 调用 sum 之后不再允许使用 v1_iter 因为调用 sum 时它会获取迭代器的所有权
assert_eq!(total, 6);
}
# }
Iterator trait 中定义了另一类方法,被称为 迭代器适配器(iterator adaptors),它们允许我们将当前迭代器变为不同类型的迭代器。可以链式调用多个迭代器适配器。不过因为所有的迭代器都是惰性的,必须调用一个消费适配器方法以便获取迭代器适配器调用的结果。
调用迭代器适配器的例子(map),该 map 方法使用闭包来调用每个元素以生成新的迭代器。这里的闭包创建了一个新的迭代器,对其中 vector 中的每个元素都被加 1 :
文件名:src/main.rs
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
// 不调用collect()方法会产生警告,Vec<_> 里使用 _ 就是让编译器推断该类型具体是什么
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); // collect 方法`消费`(这里的消费是动词)迭代器并将结果收集到一个数据结构中
assert_eq!(v2, vec![2, 3, 4]);
}
调用 map 方法创建一个新迭代器,接着调用 collect 方法消费新迭代器并创建一个 vector。因为 map 获取一个闭包,可以指定任何希望在遍历的每个元素上执行的操作。这是一个展示如何使用闭包来自定义行为同时又复用 Iterator trait 提供的迭代行为的绝佳例子。
可以链式调用多个迭代器适配器来以一种可读的方式进行复杂的操作。不过因为所有的迭代器都是惰性的,你需要调用一个消费适配器方法从迭代器适配器调用中获取结果。
使用闭包来捕获环境
filter 方法:
- 接收一个闭包
- 这个闭包在遍历迭代器的每个元素时,返回 bool 类型
- 如果闭包返回 true:当前元素将会包含在 filter 产生的迭代器中
- 如果闭包返回 false:当前元素将不会包含在 filter 产生的迭代器中
文件名:src/lib.rs
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
// into_iter() 创建的迭代器会获得所有权
// 将filter闭包参数返回true时的元素包含在迭代器里
// 然后时候collect()方法消费迭代器,产生一个vecotr集合
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}
使用 Iterator trait 来创建自定义迭代器
实现 next 方法
文件名:src/lib.rs
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter {count : 0}
}
}
// 实现一个 Iterator trait
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}
#[test]
fn calling_next_directly() {
let mut counter = Counter::new();
assert_eq!(counter.next(), Some(1));
assert_eq!(counter.next(), Some(2));
assert_eq!(counter.next(), Some(3));
assert_eq!(counter.next(), Some(4));
assert_eq!(counter.next(), Some(5));
assert_eq!(counter.next(), None);
}
#[test]
fn using_other_iterator_trait_methods() {
let sum: u32 = Counter::new()
.zip(Counter::new().skip(1))
.map(|(a, b)| a * b) // zip得到的元素是元组,因此这里的参数是元组的形式
.filter(|x| x % 3 == 0)
.sum();
assert_eq!(18, sum);
}
- map(): 对迭代器产生的每个元素应用一个函数,并返回新的迭代器,其中每个元素都是原始元素经过函数转换后的结果。
- filter(): 根据给定的闭包条件,过滤出符合条件的元素,返回一个新的迭代器,其中只包含符合条件的元素。
- take(): 从迭代器中取出指定数量的元素,返回一个新的迭代器,其中包含取出的元素。
- skip(): 跳过指定数量的元素,返回一个新的迭代器,其中不包含跳过的元素。
- enumerate(): 将迭代器产生的元素和它们的索引组合成一个元组,返回一个新的迭代器,其中每个元素是一个包含索引和原始元素的元组。
- zip(): 将两个迭代器按照索引位置一一组合成元组,返回一个新的迭代器,其中每个元素是两个迭代器对应位置上的元素组成的元组。
- fold(): 从迭代器中累积值,每次迭代都会更新累积值,最终返回最终的累积结果。
- any() 和 all(): 检查迭代器中的元素是否满足某个条件,返回一个布尔值表示检查结果。
- collect(): 将迭代器中的元素收集到一个集合中,例如 Vec、HashMap 等。
- sum(): 对迭代器中的所有元素进行求和。
改进 I/O 项目
文件名:src/main.rs
use std::env;// 一般只引入至父模块即可,使用时,env::args()
use std::process;
use _016_miniGrep::Config;
use _016_miniGrep::run;
fn main() {
// // 使用collect函数产生集合,但需要显示指明变量的集合类型,这里为Vec<String>
// let args: Vec<String> = env::args().collect();
// // env::args()函数无法处理非法的unicode字符,可以使用args_os()
// // println!("{:?}", args); // 打印输入的参数列表
// 直接将参数产生的迭代器传入new函数
let config = Config::new(env::args()).unwrap_or_else(|err| {
// 标准错误输出函数,会将错误输出到终端上,而不是output.txt文件里,这样就将错误和输出分开了
eprintln!("Problem parsing arguments: {}", err);
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
文件名:src/lib.rs
use std::error::Error;
use std::fs;// 处理文件相关的事务
use std::env;
// ()表示空元组,什么都不返回
// 否则返回一个实现了 error 这个trait的类型,可以理解为 “任何类型的错误”
pub fn run(config: Config) -> Result<(), Box<dyn Error> > {
// 使用 ? 运算符传播错误,当Err发生时,会return Err,否则会返回()空元组
let contents = fs::read_to_string(config.filename)?;
let res = if config.case_sensitive {
search_case_sensitive(&config.query, &contents)
} else {
search_case_insensitive(&config.query, &contents)
};
for line in res {
println!("{line}");
}
Ok(())
}
// 改进模块
pub struct Config {
pub query: String,
pub filename: String,
pub case_sensitive: bool,
}
impl Config {
// 原参数:args: &[String],这里的 args 是指向 Vec<String> 的切片
pub fn new(mut args: std::env::Args) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
// // 这里使用clone,是因为new()的参数是引用,并不持有所有权,传进来的仅仅是切片
// // 为了在下方把所有权转移给Config,因此这里使用了 clone 克隆了一份内容
// let query = args[1].clone();
// let filename = args[2].clone();
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let filename = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file name"),
};
// env::var()函数检测环境变量,并返回result<>,调用 is_err() 检查该环境变量是否被设置
// 如果没有被设置,就是err,函数即为返回true,true 对应的是调用 case_sensitive
let case_sensitive = env::var("CASE_INSENSITIVE").is_err();
Ok(Config {query, filename, case_sensitive})
}
}
// 使用search在contents中寻找包含duct字符串的行,并返回所有行
pub fn search_case_sensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
// let mut res = Vec::new();
// for line in contents.lines() {
// if line.contains(query) {
// res.push(line);
// }
// }
// res
// 优势:1.代码简单易读,减少了一些临时变量
// 2.消除res这个可变状态,可以在并行化提高搜索效率时,无需考虑并发访问res这个vector的安全问题
contents.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
// let mut res = Vec::new();
// let query = query.to_lowercase();
// for line in contents.lines() {
// if line.to_lowercase().contains(&query) {
// res.push(line);
// }
// }
// res
contents.lines()
.filter(|line| line.to_lowercase().contains(&query.to_lowercase()))
.collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search_case_sensitive(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUst";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents));
}
}
性能比较:循环 VS 迭代器
迭代器,作为一个高级的抽象,被编译成了与手写的底层代码大体一致性能的代码。迭代器是 Rust 的 零成本抽象(zero-cost abstractions)之一,它意味着抽象并不会引入运行时开销。
14 cargo,crates.io
如下是 dev 和 release 配置的 opt-level 设置的默认值:
文件名:Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
opt-level 设置控制 Rust 会对代码进行何种程度的优化。这个配置的值从 0 到 3。越高的优化级别需要更多的时间编译
crates.io
- 可以通过发布包来共享你的代码
- crate 的注册表在 crates.io 网站,它会分发已注册的包的源码,主要用于托管开源的代码
文档注释
用于生成文档:
- 生成 HTML 文档
- 显式公共 API 的文档注释:如何使用 API
- 使用
/// - 支持 markdown
- 放置在被说明条目之前
下面展示了一个 my_crate crate 中 add_one 函数的文档注释
文件名:src/lib.rs
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
生成 HTML 文档的命令:cargo doc --open,构建当前 crate 的文档,在浏览器打开文档
常用章节
# Examples
其他常用章节:
- Panics:函数可能发生 panic 的场景
- Errors:如果函数返回 Result,描述可能的错误种类,以及可导致错误的条件
- Safety:如果函数处于 unsafe 调用,就应该解释函数 unsafe 的原因,以及调用者确保的使用前提
文档注释作为测试
运行 cargo test,把文档注释中的示例代码作为测试来运行
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
为包含注释的项添加文档注释
文档注释风格 //! 为包含注释的项,而不是位于注释之后的项增加文档。这通常用于 crate根文件(通常是 src/lib.rs)或模块的根文件为 crate 或模块整体提供文档
作为一个例子,为了增加描述包含 add_one 函数的 my_crate crate 目的的文档,可以在 src/ lib.rs 开头增加以 //! 开头的注释
文件名:src/lib.rs
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
如果运行 cargo doc --open ,将会发现这些注释显示在 my_crate 文档的首页,位于 crate 中公有项列表之上
pub use(重新导出)
问题:crate 的程序结构在开发时对于开发者合理,但对于它的使用者不够方便,因为开发者会把程序结构分很多层,使用者想找到这种深层结构中的某个类型很费劲。
例如
- 麻烦:
my_crate::some_module::another_module::UsefulType; - 方便:
my_crate::UsefulType;
解决办法:使用 pub use,可以重新导出,创建一个与内部结构不同的对外公共结构,不需要重新组织内部代码结构。
cargo 工作空间
cargo 工作空间:帮助管理多个相互关联且需要协同开发的 crate
cargo 工作空间是一套共享一个 Cargo.lock 和输出文件夹的包
# 1.先创建出工作空间的目录
mkdir add
# 2.在add目录中添加一个用于配置工作空间的 Cargo.toml 文件
15 智能指针
在拥有所有权和借用概念的 Rust 中,引用和智能指针之间还有另外一个差别:引用是只借用数据的指针;而与之相反地,大多数智能指针本身就拥有它们指向的数据。
我们通常会使用结构体来实现智能指针,但区别于一般结构体的地方在于它们会实现Deref与Drop这两个trait。Deref trait 使得智能指针结构体的实例拥有与引用一致的行为,它使你可以编写出能够同时用于引用和智能指针的代码。Drop trait 则使你可以自定义智能指针离开作用域时运行的代码。
常见的那些智能指针上:
- Box,可用于在堆上分配值。
- Rc,允许多重所有权的引用计数类型。
- Ref和RefMut,可以通过RefCell访问,是一种可以在运行时而不是编译时执行借用规则的类型。
Box< T >
装箱 (box)是最为简单直接的一种智能指针,它的类型被写作 Box<T>。装箱使我们可以将数据存储在堆上,并在栈中保留一个指向堆数据的指针。
常见场景
- 在编译时,某类型的大小无法确定。但使用该类型时,上下文却需要知道它的确切大小。
- 当你有大量数据,想移交所有权,但需要确保在操作时数据不会被复制。
(转移大量数据的所有权可能会花费较多的时间,因为这些数据需要在栈上进行逐一复制。为了提高性能,你可以借助装箱将这些数据存储到堆上。通过这种方式,我们只需要在转移所有权时复制指针本身即可,而不必复制它指向的全部堆数据。) - 使用某个值时,你只关心它是否实现了特定的 trait,而不关心它的具体类型
-
- 例如:
Box<dyn Error>意味着Box指针只能指向实现了Errortrait 的类型,无需指定具体类型。这提供了在不同的错误场景可能有不同类型的错误返回值的灵活性。这也就是dyn,它是“动态的”(“dynamic”)的缩写。
- 例如:
使用装箱定义递归类型
Rust必须在编译时知道每一种类型占据的空间大小,但有一种被称作递归 (recursive)的类型却无法在编译时被确定具体大小。递归类型的值可以在自身中存储另一个相同类型的值,因为这种嵌套在理论上可以无穷无尽地进行下去,所以Rust根本无法计算出一个递归类型需要的具体空间大小。但是,装箱有一个固定的大小,我们只需要在递归类型的定义中使用装箱便可以创建递归类型了。
Box<T> 是一个指针,Rust 知道它需要多少空间,因为指针的大小不会基于它指向的数据大小变化而变化。
Box<T> :
- 只提供了 “间接” 存储和 heap 内存分配的功能
- 没有其他额外功能
- 没有性能开销
- 适用于需要 “间接” 存储的场景,例如 Cons List
- 实现了 Deref trait 和 drop trait
Deref trait
实现 Deref Trait 使我们可以自定义解引用运算符 * 的行为
通过实现 Deref,智能指针可像常规引用一样来处理
fn main() {
let x = 5;
let y = Box::new(x); // 把Box<T>当成引用来操作
let z = &x;
assert_eq!(x, 5);
assert_eq!(*y, 5);
assert_eq!(*z, 5); // Box<T>指针也能像引用一样操作
}
接下来,实现一个自定义的装箱类型,并借此来研究为什么Box<T>能够进行解引用操作。
定义我们自己的智能指针
实现 Deref trait:该方法借用 self;返回一个指向内部数据的引用
use std::ops::Deref;
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
// 为MyBox结构体实现 deref trait
impl<T> Deref for MyBox<T> {
type Target = T;
// 1. 示例写法
// fn deref(&self) -> &T {
// &self.0
// }
// 2. 自动弹出的写法
fn deref(&self) -> &Self::Target {
&self.0
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
let z = &x;
assert_eq!(x, 5);
assert_eq!(*y, 5); // 实现了该trait的类型,rust会隐式的展开为 *(y.deref())
assert_eq!(*z, 5);
}
函数和方法的隐式解引用转换(Deref Conercion)
隐式解引用转化(Deref Conercion) 是为函数和方法提供的一种便捷特性。
假设类型 T 实现了 Deref trait:Deref Conercion 可以把 T 的引用转化为 T 经过 Deref 操作后生成的引用。也就是说,当把某类型的引用传递给函数或方法时,但它的类型与定义的参数不匹配:Deref Conercion 就会自动发生。
编译器会对 deref 进行一系列调用,来把它转为所需的参数类型:在编译时完成,没有额外的性能开销
例子:
use std::ops::Deref;
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
// 为MyBox结构体实现 deref trait
impl<T> Deref for MyBox<T> {
type Target = T;
// 1.
// fn deref(&self) -> &T {
// &self.0
// }
// 2. 编译器自动弹出的写法
fn deref(&self) -> &Self::Target {
&self.0
}
}
// 接收一个类型为&str的参数
fn hello(name: &str) {
println!("Hello, {}!", name);
}
fn main() {
let m = MyBox::new(String::from("Rust"));
// &m ---> &MyBox<String>
// 由于MyBox类型实现了deref, 因此会将 &MyBox<String> 类型转换为 &String 类型
// String 类型也实现了deref,且返回值为 &str,因此最后变成了 &str 类型
hello(&m);
hello("Rust");
}
解引用和可变性
可使用 DerefMut trait 重载可变引用的 * 运算符
在类型和 trait 在下列三种情况发生时:Rust 会执行 deref coercion :
- 当 T:
Deref<Target=U>,允许&T转换为&U - 当 T:
DerefMut<Target=U>,允许&mut T转换为&mut U - 当 T:
Deref<Target=U>,允许&mut T转换为&U(反过来不行)
Drop trait
实现 Drop trait,可以让我们自定义当值要离开作用域时发生的动作。
- 例如:文件、网络资源释放等
- 任何类型都可以实现 Drop trait
Drop trait 只要求你实现 drop 方法,其在预导入模块中,无需手动引入。实际上,任何你想要在类型实例离开作用域时运行的逻辑都可以放
在 drop 函数体内。
Rust 并不允许我们手动调用 Drop trait 的 drop 方法;但是,可以调用标准库中的 std::mem::drop 函数来提前清理某个值。提前清理值也不会导致二次释放这种错误,因为 rust 的所有权系统会保证引用的有效,drop 只会在确定不使用这个值的时候被调用一次。
RC< T > : 引用计数智能指针
Rust提供了一个名为 Rc<T> 的类型来支持多重所有权,它名称中的 Rc 是 Reference counting(引用计数)的缩写。
Rc<T> 类型的实例会在内部维护一个用于记录值引用次数的计数器,从而确认这个值是否仍在使用。如果对一个值的引用次数为零,那么就意味着这个值可以被安全地清理掉,而不会触发引用失效的问题。(类似于c++ 的 shared_ptr)
使用场景:需要在 heap 上分配数据,这些数据被程序的多个部分读取,但在编译时无法确定哪个部分最后使用完这些数据。需要注意的是,Rc<T> 只能被用于单线程场景中。
通过不可变引用,实现程序不同部分之间共享只读数据
例子:
考虑这样一个场景,这样链表的结构我们会想到使用 Box<T>
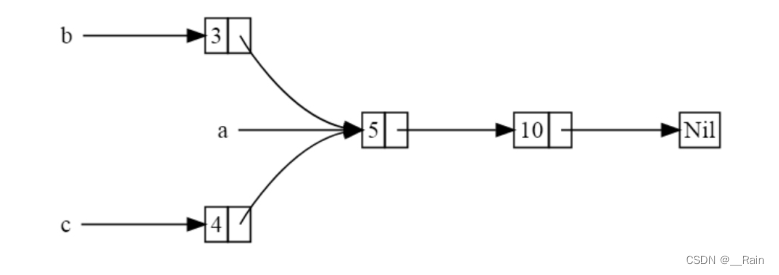
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil}; // 这样引用,在使用Cons创建时,不需要写成 List::Cons
fn main() {
let a = Cons(5,
Box::new(Cons(10,
Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}
// 错误实现的代码
但其实基于Box<T>实现的 List 无法实现这样的场景,Box<T>无法让两个列表同时持有另一列表的所有权。
因为Cons变体持有它存储的数据。因此,整个a列表会在我们创建b列表时被移动至b中。换句话说,b列表持有了a列表的所有权。当我们随后再次尝试使用a来创建c列表时就会出现编译错误,因为a已经被移走了。
我们当然可以改变 Cons 的定义来让它持有一个引用而不是所有权,并为其指定对应的生命周期参数。但这个生命周期参数会要求列表中所有元素的存活时间都至少要和列表本身一样长。换句话说,借用检查器最终会阻止我们编译类似于 let a = Cons(10, &Nil); 这样的代码,因为此处临时创建的Nil 变体值会在 a 取得其引用前被丢弃。
另外一种解决方案是,我们可以将List中的Box<T>修改为Rc<T>。每个Cons 变体都会持有一个值及一个指向List的Rc<T>。我们只需要在创建b的过程中克隆a的Rc<List>智能指针即可,而不再需要获取a的所有权。这会使a和b可以共享Rc<List>数据的所有权,并使智能指针中的引用计数从1 增加到 2。随后,我们在创建 c 时也会同样克隆 a 并将引用计数从 2 增加到 3。每次调用 Rc::clone 都会使引用计数增加,而 Rc<List> 智能指针中的数据只有在引用计数器减少到 0 时才会被真正清理掉。
use crate::List::{Cons, Nil};
use std::rc::Rc;
enum List {
Cons(i32, Rc<List>),
Nil,
}
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}
Rc::clone 不会执行数据的深度拷贝操作,这与绝大多数类型实现的 clone方法(clone trait)明显不同。调用 Rc::clone 只会增加引用计数,而这不会花费太多时间。因此,在引用计数上调用 Rc::clone 可以让开发者一眼就区分开“深度拷贝”与 “增加引用计数” 这两种完全不同的克隆行为。当你需要定位存在性能问题的代码时,就可以忽略 Rc::clone 而只需要审查剩余的深度拷贝克隆行为即可。
RefCell < T > 和内部可变性
内部可变性 (interior mutability)是Rust的设计模式之一,它允许你在只持有不可变引用的前提下对数据进行修改;通常而言,类似的行为会被借用规则所禁止。为了能够改变数据,内部可变性模式在它的数据结构中使用了unsafe(不安全)代码来绕过Rust正常的可变性和借用规则。
RefCell < T >
与 Rc<T> 相似,只能用于单线程场景
RefCell <T> 和 Box<T> 的区别:
RefCell < T > :
- 只会在运行时检查借用规则
- 否则触发 panic
Box < T > :
- 编译阶段 强制代码遵守借用规则
- 否则出现错误
借用规则在不同阶段进行检查的比较:
编译阶段:
- 尽早暴露问题
- 没有任何运行时开销
- 对大多数场景是最佳选择
- 是 Rust 的默认行为
运行时:
- 问题暴露延后,甚至到生产环境
- 因借用计数产生些许性能损失
- 实现某些特定的内存安全场景(不可变环境中修改自身数据)
| Box< T > | Rc< T > | ReCell< T > | |
|---|---|---|---|
| 同一数据的所有者 | 一个 | 多个 | 一个 |
| 可变性、借用检查 | 可变、不可变借用(编译时检查) | 不可变借用(编译时检查) | 可变、不可变借用(运行时检查) |
其中:即便 RefCell<T> 本身不可变,但仍能修改其中存储的值
对于使用一般引用和Box<T>的代码,Rust 会在编译阶段强制代码遵守这些借用规则。而对于使用RefCell<T>的代码,Rust则只会在运行时检查这些规则,并在出现违反借用规则的情况下触发 panic 来提前中止程序。
内部可变性:可变的借用一个不可变的值
借用规则的一个推论是,你无法可变地借用一个不可变的值。例如,下面这段代码就无法通过编译:
fn main() {
let x = 5;
let y = &mut x;
}
然而,在某些特定情况下,我们也会需要一个值在对外保持不可变性的同时能够在方法内部修改自身。除了这个值本身的方法,其余的代码则依然不能修改这个值。使用 RefCell<T> 就是获得这种内部可变性的一种方法。不过,RefCell<T> 并没有完全绕开借用规则:我们虽然使用内部可变性通过了编译阶段的借用检查,但借用检查的工作仅仅是被延后到了运行阶段。如果你违反了借用规则,那么就会得到一个 panic! 而不再只是编译时的错误。
内部可变性的应用场景:模拟对象
测试替代(test double)是一个通用的编程概念,它代表了那些在测试工作中被用作其他类型替代品的类型。而模拟对象(mock object)则指代了测试替代中某些特定的类型,它们会承担起记录测试过程的工作。我们可以利用这些记录来断言测试工作的运行是否正确。
Rust 没有和其他语言中类似的对象概念,也同样没有在标准库中提供模拟对象的测试功能。但是,我们可以自行定义一个结构体来实现与模拟对象相同的功能。
设计的测试场景如下:我们希望开发一个记录并对比当前值与最大值的库,它会基于当前值与最大值之间的接近程度向外传递信息。例如,这个库可以记录用户调用不同API的次数,并将它们与设置的调用限额进行比较。
文件名:src/lib.rs
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: 'a + Messenger> {
// 1.'a 被用作生命周期参数,表示泛型类型 T 的引用或指针的生命周期至少与 'a 相同
// 这意味着,当使用这个泛型类型时,引用或指针的生命周期必须至少与 'a 一样长,否则会导致编译错误
// 2.T: 'a + Messenger:这是一个类型约束,表示泛型T必须实现Messenger trait
// 并且具有与LimitTracker结构体相同的生命周期
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where T: Messenger
{
pub fn new(messenger: &T, max: usize) -> LimitTracker<T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger { sent_messages: RefCell::new(vec![]) }
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
} // borrow_mut():获得内部值的可变引用
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
// borrow():获得内部值的不可变引用
}
}
两个方法(安全接口):
borrow 方法:返回智能指针 Ref<T>,它实现了 Deref
borrow_mut 方法:返回智能指针 RefMut<T> ,它实现了 Deref
RefCell<T> 在运行时记录借用信息
- 每次调用 borrow:不可变借用计数加 1
- 任何一个
Ref<T>的值离开作用域被释放时:不可变借用计数减 1 - 每次调用 borrow_mut:可变借用计数加 1
- 任何一个
RefMut<T>的值离开作用域被释放时:可变借用计数减 1
以此技术来维护借用检查规则:任何一个给定的时间里,只允许拥有多个不可变借用或一个可变借用。
将Rc和RefCell结合使用来实现一个拥有多重所有权的可变数据
将RefCell<T>和Rc<T>结合使用是一种很常见的用法。Rc<T>允许多个所有者持有同一数据,但只能提供针对数据的不可变访问。如果我们Rc<T>内存储了RefCell<T>,那么就可以定义出拥有多个所有者且能够进行修改的值了。
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
use std::cell::RefCell;
fn main() {
/*
首先创建了一个Rc<RefCell<i32>>实例,并将它暂时存入了value变量中以便之后可以直接访问
接着,使用含有value的Cons变体创建一个List类型的a变量
为了确保a和value同时持有内部值5的所有权,这里的代码还克隆了value,而不仅仅只是将value的所有权传递给a,或者让a借用value。
*/
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(6)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(10)), Rc::clone(&a));
/*
为了让随后创建的b和c能够同时指向a,我们将a封装到了Rc<T>中。
创建完a、b、c这3个列表后,我们通过调用borrow_mut来将value指向的值增加10。
注意,这里使用了自动解引用功能来将Rc<T>解引用为RefCell<T>
borrow_mut方法会返回一个RefMut<T>智能指针,我们可以使用解引用运算符来修改其内部值
*/
*value.borrow_mut() += 10;
println!("a after = {:?}", a);
println!("b after = {:?}", b);
println!("c after = {:?}", c);
}
循环引用导致内存泄漏
你可以通过使用Rc<T>和RefCell<T>看到Rust是允许内存泄漏的:我们能够创建出互相引用成环状的实例。由于环中每一个指针的引用计数都不可能减少到 0,所以对应的值也不会被释放丢弃,这就造成了内存泄漏。
防止循环引用,把 Rc< T > 换成 Weak< T >
Rc::clone为Rc<T>实例的strong_count加 1,Rc 的实例只有在strong_count为 0 的时候才会被清理Rc<T>实例通过调用Rc::downgrade方法可以创建值的Weak Reference(弱引用)-
- 返回类型是
Weak<T>(智能指针)
- 返回类型是
-
- 调用
Rc::downgrade会为weak_count加 1
- 调用
Rc<T>使用weak_count来追踪存在多少Weak<T>weak_count不为 0 并不影响Rc<T>实例的清理
String Vs Weak
Strong Reference(强引用)是关于如何分析Rc<T>实例的所有权Weak Reference(弱引用)并不表达上述意思- 使用
Weak Reference并不会创建循环引用: -
- 当
Strong Reference数量为 0 的时候,Weak Reference会自动断开
- 当
- 在使用
Weak<T>前,需要保证它指向的值仍然存在: -
- 在
Weak<T>实例调用upgrade方法,返回Option<Rc<T>>
- 在
16 多线程并发
并发编程(Concurrentprogramming),代表程序的不同部分相互独立地执行,而并行编程(parallel programming)代表程序不同部分同时执行。
使用线程同时运行代码
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| { // spawn 创建线程
for i in 1..10 {
println!("number {} from spawn thread", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("number {} from main thread", i);
thread::sleep(Duration::from_millis(1));
}
// 因为无法保证线程运行的顺序,因此主线程可能比子线程提早结束,因此需要确保子线程在 main 退出前结束运行
// thread::spawn 的返回值类型是 JoinHandle
// JoinHandle 是一个拥有所有权的值,当对其调用 join 方法时,它会等待其线程结束
// 当调用join()时,它会阻塞当前线程,直到被调用的线程执行完毕并退出
handle.join().unwrap(); // main如果执行的快,将会在此发生阻塞
}
将 move 闭包与线程一同使用
use std::thread;
fn main() {
let v = vec![1, 2, 3];
// 闭包使用了 v ,所以闭包会捕获 v 并使其成为闭包环境的一部分,因为 println! 只需要 v 的引用,闭包尝试借用 v
// 为 thread::spawn 在一个新线程中运行这个闭包,所以可以在新线程中访问 v
// 然而这有一个问题:Rust 不知道这个新建线程会执行多久,所以无法知晓对 v 的引用是否一直有效
// 在闭包之前增加 move 关键字,我们强制闭包获取其使用的值的所有权,而不是任由Rust 推断它应该借用值
let handle = thread::spawn(move || {
println!("vector = {:?}", v);
});
handle.join().unwrap();
}
消息传递并发
为了实现消息传递并发,Rust 标准库提供了一个 信道(channel)实现。信道是一个通用编程概念,表示数据从一个线程发送到另一个线程。信道像一条河流,在上有放一个橡皮艇,会顺流而下到下游。信道分发送者和接收者,当发送者或接收者任一被丢弃时可以认为信道被关闭了。
使用 mpsc::channel 函数可以创建一个新的信道;mpsc 是多个生产者,单个消费者(multiple producer, single consumer)的缩写。简而言之,Rust 标准库实现信道的方式意味着一个信道可以有多个产生值的 发送(sending)端,但只能有一个消费这些值的接收(receiving)端。
mpsc::channel 函数返回一个元组:第一个元素是发送者,而第二个元素是接收者。由于历史原因,tx 和 rx 通常作为 发送者(transmitter)和 接收者(receiver)的缩写,所以这就是我们将用来绑定这两端变量的名字。这里使用了一个 let 语句和模式来解构了此元组
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hello");
tx.send(val).unwrap();
});
// 信道的接收者有两个有用的方法:recv 和 try_recv
// try_recv 不会阻塞,相反它立刻返回一个 Result<T, E>
let received = rx.recv().unwrap(); // recv()会阻塞主线程执行直到从信道中接收一个值
// 本例十分简单,阻塞主线程也没有什么问题
println!("{}", received);
}
信道与所有权转移
send 函数获取其参数的所有权并转移给接收者。
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {}", val); // error,value borrowed here after move
});
let received = rx.recv().unwrap();
println!("Got: {}", received);
}
多个生产者一个消费者的实例
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
// 两个生产者发送多个消息
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_millis(1));
}
});
// 直接for循环遍历接收端
for received in rx {
println!("Got: {}", received);
}
}
共享状态并发
另一种处理并发的方式是让多个线程拥有相同的共享数据。
互斥器 Mutex
互斥器一次只允许一个线程访问数据。互斥器(mutex)是 mutual exclusion 的缩写,也就是说,任意时刻,其只允许一个线程访问某些数据。为了访问互斥器中的数据,线程首先需要通过获取互斥器的锁(lock)来表明其希望访问数据。锁是一个作为互斥器一部分的数据结构,它记录谁有数据的排他访问权。
Mutex 提供了内部可变性,具体参考第 19 章 lazy_static! 部分的实例。
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
// 数据5被封装在了mutex内部,访问它需要lock
{
// lock成功返回一个MutexGuard<'_, i32>类型的智能指针
let mut num = m.lock().unwrap();
*num = 6;
}
println!("{:?}", m);
}
原子引用计数 Arc< T >
通过使用智能指针 Rc<T> 来创建引用计数的值,以便拥有多所有者。Rc<T> 并没有使用任何并发原语,来确保改变计数的操作不会被其他线程打断。在计数出错时可能会导致诡异的 bug,比如可能会造成内存泄漏,或在使用结束之前就丢弃一个值。我们所需要的是一个完全类似 Rc<T> ,又以一种线程安全的方式改变引用计数的类型。
所幸 Arc 正是 这么一个类似 Rc 并可以安全的用于并发环境的类型。字母 “a” 代表 原子性(atomic),所以这是一个原子引用计数(atomically reference counted)类型。为了保证线程安全,损失的是性能。
use std::sync::{Mutex, Arc};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("{}", *counter.lock().unwrap());
}
Arc的例子
依赖:
tokio = { version = "1.36.0", features = ["full"] }
rand = "0.8"
定义一个共享的任务队列,一个异步任务向队列中添加数据,一个异步任务取出队列中的任务进行处理。
use std::collections::VecDeque;
use std::sync::{Arc, Mutex};
use tokio::sync::mpsc;
use tokio::time::{sleep, Duration};
#[tokio::main]
async fn main() {
// 定义任务队列类型为 VecDeque<String>
let task_queue: Arc<Mutex<VecDeque<String>>> = Arc::new(Mutex::new(VecDeque::new()));
// 创建通道对比任务队列传输的数据是否正确
let (tx, mut rx) = mpsc::channel::<String>(1024); // 1024 是消息通道容量
// 克隆 task_queue 用于 push_task
let task_queue_clone = Arc::clone(&task_queue);
// 启动异步任务往队列中推送数据
let push_task = tokio::spawn(async move {
loop {
// 模拟产生一些任务数据并推送到队列中
let task_data = format!("Task {}", rand::random::<u32>());
{
let mut queue = task_queue_clone.lock().unwrap();
queue.push_back(task_data.clone());
}
// 发送数据到通道
if let Err(_) = tx.send(task_data).await {
// 发送失败的处理逻辑
println!("Failed to send data to channel");
}
// 暂停一段时间
sleep(Duration::from_secs(1)).await;
}
});
// 启动异步任务处理队列中的数据
let process_task = tokio::spawn(async move {
loop {
// 从通道接收数据
if let Some(data) = rx.recv().await {
// 处理数据,这里可以根据需要进行具体处理
println!("Processing data: {}", data);
}
// 检查并处理队列中的数据
{
let mut queue = task_queue.lock().unwrap();
while let Some(data) = queue.pop_front() {
// 处理数据,这里可以根据需要进行具体处理
println!("Processing data from queue: {}", data);
}
}
}
});
// 等待异步任务结束
push_task.await.unwrap();
process_task.await.unwrap();
}
读取 Arc 中数据的实例
use std::sync::Arc;
use std::thread;
fn main() {
// Arc 封装的元组
let data = Arc::new((
vec![(1.0, 2.0), (3.0, 4.0)],
vec![(5.0, 6.0), (7.0, 8.0)],
));
// 克隆 Arc 以便在不同的上下文中使用
let data_clone = Arc::clone(&data);
// 在新线程中使用 data_clone
thread::spawn(move || {
// 解引用 Arc 以获取元组的引用,但是Arc里的元素是不能转移所有权的
// 因此只能获取其不可变引用,使用模式匹配就可以获得两个vector的不可变引用了
let (points1, points2) = &(*data_clone);
// 打印第一个 Vec 中的元素
for point in points1 {
println!("Point1: x = {}, y = {}", point.0, point.1);
}
// 打印第二个 Vec 中的元素
for point in points2 {
println!("Point2: x = {}, y = {}", point.0, point.1);
}
});
}
使用 Sync 和 Send trait 的可扩展并发
有两个并发概念是内嵌于语言中的:std::marker 中的Sync 和 Send trait
通过 Send 允许在线程间转移所有权
Send trait :实现了 Send 的类型值的所有权可以在线程间传送。几乎所有的 Rust 类型都是 Send 的,任何完全由 Send 的类型组成的类型也会自动被标记为 Send ,有一些例外,包括 Rc<T> 、raw pointer
Sync 允许多线程访问
Sync trait :一个实现了 Sync 的类型,它的值可以安全地被多个线程共享,并且这些线程可以同时拥有对这个值的引用。
类似于 Send 的情况,基本类型是 Sync 的,完全由 Sync 的类型组成的类型也是 Sync 的。
17 面向对象
18 模式匹配
if let 条件表达式
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse(); // _ 用作通配符,编译器会根据上下文推断出合适的类型
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}
while let 条件循环
一个与 if let 结构类似的是 while let 条件循环,它允许只要模式匹配就一直进行 while
循环。
fn main() {
let mut stack = Vec::new();
stack.push(1);
stack.push(2);
stack.push(3);
// 只要 stack.pop() 返回 Some 就打印出其值
while let Some(top) = stack.pop() {
println!("{}", top);
}
}
for 循环
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() { // enumerate是在迭代器上生成索引和值对,即两个值的元组
println!("{} is at index {}", value, index);
}
}
let 语句
let x = 5;
let PATTERN = EXPRESSION;
// 模式解构元组并一次创建三个变量
let (x, y, z) = (1, 2, 3);
模式 x 是一个通配符,可以匹配任何值,并将其赋给变量 x。
函数参数
函数参数也可以是模式
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({}, {})", x, y);
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}
Refutability(可反驳性): 模式是否会匹配失效
模式有两种形式:refutable(可反驳的)和 irrefutable(不可反驳的)。能匹配任何传递的可能值的模式被称为是 不可反驳的(irrefutable)。一个例子就是 let x = 5; 语句中的 x ,因为 x 可以匹配任何值所以不可能会失败。对某些可能的值进行匹配会失败的模式被称为是 可反驳的(refutable)。一个这样的例子便是 if let Some(x) = a_value 表达式中的 Some(x) ;如果变量 a_value 中的值是 None 而不是 Some ,那么 Some(x) 模式不能匹配。
函数参数、let 语句和 for 循环只能接受不可反驳的模式,因为当值不匹配时,程序无法进
行有意义的操作。
为了在不可反驳模式的地方使用可反驳模式,可以修改使用模式的代码:不同于使用 let ,可以使用 if let 。如此,如果模式不匹配,大括号中的代码将被忽略,其余代码保持有效。
fn main() {
let some_option_value: Option<i32> = None;
// let Some(x) = some_option_value; Error
if let Some(x) = some_option_value {
println!("{}", x);
}
}
match 表达式
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"), // 使用 | 语法匹配多个模式
3 => println!("three"),
_ => println!("anything"),
}
let y = 5;
match y {
1..=5 => println!("one through five"), // ..= 语法允许你匹配一个闭区间范围内的值
_ => println!("something else"),
}
let z = 'c';
match z {
'a'..='j' => println!("early ASCII letter"), // 字符形式的区间
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}
使用个 match 语句将 Point 值分成了三种情况:直接位于 x 轴上(此时 y =0 为真)、位于 y 轴上(x = 0 )或不在任何轴上的点。
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p; // 创建变量 a、b 来匹配结构体x、y字段,a = 0, b = 7
let Point { x, y } = p; // 创建变量 x、y匹配, x = 0, y = 7
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
}
解构枚举
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
// 匹配枚举类型中的各种变体
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change the color to red {r}, green {g}, and blue {b}",)
}
}
}
很明显代码输出:Change the color to red 0, green 160, and blue 255
对于像 Message::Quit 这样没有任何数据的枚举成员,不能进一步解构其值。只能匹配其字
面值 Message::Quit ,因此模式中没有任何变量。
对于像 Message::Move 这样的类结构体枚举成员,可以采用类似于匹配结构体的模式。在成
员名称后,使用大括号并列出字段变量以便将其分解以供此分支的代码使用。
对于像 Message::Write 这样的包含一个元素,以及像 Message::ChangeColor 这样包含三个
元素的类元组枚举成员,其模式则类似于解构元组的模式。模式中变量的数量必须与成员
中元素的数量一致。
其实就记住解构时的形式和定义时的一样
解构嵌套的结构体和枚举
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}")
}
_ => (),
}
}
解构结构体和元组
如下是一个复杂结构体的例子,其中结构体和元组嵌套在元组中,并将所有的原始类型解构出来:
fn main() {
struct Point {
x: i32,
y: i32,
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}
使用 _ 忽略值
fn foo(_: i32, y: i32) { // 函数忽略第一个参数
println!("This code only uses the y parameter: {}", y);
}
使用场景:
例如,假设我们实现了一个 trait,其中有一个函数签名定义了多个参数,但在具体的实现中,我们只需要使用其中的部分参数。在这种情况下,为了避免编译器产生未使用参数的警告,我们可以在函数定义中使用下划线 _ 来标记那些我们不需要使用的参数。这样,编译器就不会发出未使用参数的警告。
只使用 _ 和使用以下划线开头的名称有些微妙的不同:比如 _x 仍会将值绑定到变量,而 _ 则完全不会绑定。
用 … 忽略剩余值
对于有多个部分的值,可以使用 .. 语法来只使用特定部分并忽略其它值,同时避免不得不每一个忽略值列出下划线。.. 模式会忽略模式中剩余的任何没有显式匹配的值部分。有一个 Point 结构体存放了三维空间中的坐标。在 match 表达式中,我们希望只操作 x 坐标并忽略 y 和 z 字段的值:
fn main() {
struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {}", x),
}
}
这里用 first 和 last 来匹配第一个和最后一个值。.. 将匹配并忽略中间的所有值
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {first}, {last}");
}
}
}
匹配守卫:match分支后添加额外条件
fn main() {
let num = Some(4);
match num {
Some(x) if x % 2 == 0 => println!("The number {} is even", x),
Some(x) => println!("The number {} is odd", x),
None => (),
}
}
使用运算符 | 来指定多个模式,同时匹配守卫的条件会作用于所有的模式。匹配守卫 if y 作用于 4 、5 和 6
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"), // 匹配 x 值为 4 、5 或 6 同时 y 为 true
_ => println!("no"),
}
}
匹配守卫与模式的优先级关系看起来像这样:(4 | 5 | 6) if y => …
@ 绑定
at 运算符(@)可以将匹配到的值绑定到这个新变量上
fn main() {
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
// 创建了一个新变量id_variable,并绑定值到新变量上
Message::Hello { id: id_variable @ 3..=7 } => {
println!("Found an id in range: {}", id_variable)
}
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
Message::Hello { id } => println!("Found some other id: {}", id),
}
}
19 高级特征
Unsafe
使用 unsafe 关键字来切换到 unsafe Rust,开启一个块,里面放着 unsafe 代码。
Unsafe Rust 里可执行的四个动作(unsafe 超能力):
- 解引用原始指针
- 调用
unsafe函数或方法 - 访问或修改可变的静态变量
- 实现
unsafe trait
unsafe 这个关键字,仅仅是让你可以访问这四种不会被编译器进行内存安全检查的特性。
弹幕中提示还有第五个超能力:调用一个其他语言的静态/动态库(在Rust中这个功能叫 FFI )
注意:
unsafe并没有关闭借用检查或停用其他安全检查措施- 任何内存安全相关的错误必须留在 unsafe 块里
- 尽可能隔离 unsafe 代码,最好将其封装再安全的抽象里,提供安全的 API
解引用原始指针
原始指针:
- 可变的:
*mut T - 不可变的:
*const T,意味着指针在解引用后不能直接对其进行赋值 - 注意,这里的
*并不表示解引用,而是类型名的一部分
19.1节,3:55
宏
宏(Macro)指的是 Rust 中一系列的功能:使用 macro_rules! 的 声明(Declarative)宏,和三种 过程(Procedural)宏:
• 自定义 #[derive] 宏在结构体和枚举上指定通过 derive 属性添加的代码
• 类属性(Attribute-like)宏定义可用于任意项的自定义属性
• 类函数宏看起来像函数不过作用于作为参数传递的 token
自定义宏
需求:
- 创建一个 hello_macro 包,定义一个拥有关联函数 hello_macro 的 HelloMacro trait
- 我们提供一个能自动实现 trait 的过程宏
- 在它们的类型上标注 #[derive(HelloMacro)],进而得到 hello_macro 的默认实现
lazy_static!
lazy_static! 是 Rust 中一个非常有用的宏,它允许你创建全局静态变量,这些变量在首次访问时进行初始化,并在整个程序的生命周期内保持不变。通常情况下,全局变量在 Rust 中是不可变的,但是通过 lazy_static! 宏,你可以创建一个在首次访问时进行初始化的全局静态变量。
使用 lazy_static! 宏创建的全局静态变量,其初始化操作会在首次被访问时执行。这样可以延迟初始化,节省资源,并且只在需要时进行初始化。这对于一些耗时的初始化操作或需要特定上下文才能初始化的情况非常有用。
例子:
这段代码使用了 lazy_static! 宏来定义一个全局共享数据 SHARED_DATA
lazy_static! {
// 定义全局共享数据
static ref SHARED_DATA: Arc<Mutex<HashMap<u64, (Vec<Vec<String>>, Vec<Vec<String>>)>>> = Arc::new(Mutex::new(HashMap::new()));
}
在 Rust 中,Mutex 提供了内部可变性,即使变量本身是不可变的,也可以通过 Mutex 获取其内部的可变引用,然后修改内部数据。在 SHARED_DATA 中,虽然外部看起来是不可变的(因为没有使用 mut 关键字),但是由于其类型是 Mutex,因此可以通过 lock 方法获取一个可变的锁(即 MutexGuard),然后在锁定期间对内部数据进行修改。
具体来说,在使用 SHARED_DATA 进行 insert 操作时,会先获取 Mutex 的锁(通过调用 lock 方法),这会返回一个 MutexGuard,然后通过 MutexGuard 进行数据修改。一旦作用域结束,锁会自动释放,从而避免了数据竞争和并发访问的问题。
因此,尽管 SHARED_DATA 本身是不可变的,但是由于其内部使用了 Mutex 来实现线程安全,所以可以在需要的地方进行插入操作。